Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
I Azure Machine Learning kan du använda modellövervakning för att kontinuerligt spåra prestanda för maskininlärningsmodeller i produktion. Modellövervakning ger dig en bred vy över övervakningssignaler. Du får också en avisering om potentiella problem. När du övervakar signaler och prestandamått för modeller i produktion kan du kritiskt utvärdera de inneboende riskerna med dina modeller. Du kan också identifiera blinda fläckar som kan påverka din verksamhet negativt.
I den här artikeln ser du hur du utför följande uppgifter:
- Konfigurera inbyggda och avancerade övervakningar för modeller som distribueras till Azure Machine Learning-slutpunkter online
- Övervaka prestandamått för modeller i produktion
- Övervaka modeller som distribueras utanför Azure Machine Learning eller distribueras till Azure Machine Learning-batchslutpunkter
- Konfigurera anpassade signaler och mått som ska användas i modellövervakning
- Tolka övervakningsresultat
- Integrera Azure Machine Learning-modellövervakning med Azure Event Grid
Förutsättningar
Azure CLI och
mltillägget till Azure CLI har installerats och konfigurerats. Mer information finns i Installera och konfigurera CLI (v2).Ett Bash-gränssnitt eller ett kompatibelt gränssnitt, till exempel ett gränssnitt på ett Linux-system eller Windows-undersystem för Linux. Azure CLI-exemplen i den här artikeln förutsätter att du använder den här typen av gränssnitt.
En Azure Machine Learning-arbetsyta. Anvisningar för hur du skapar en arbetsyta finns i Konfigurera.
Ett användarkonto som har minst en av följande rollbaserade åtkomstkontrollroller i Azure (Azure RBAC):
- En ägarroll för Azure Machine Learning-arbetsytan
- En deltagarroll för Azure Machine Learning-arbetsytan
- En anpassad roll som har
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*behörigheter
Mer information finns i Hantera åtkomst till Azure Machine Learning-arbetsytor.
För övervakning av en Azure Machine Learning-hanterad onlineslutpunkt eller Kubernetes onlineslutpunkt:
En modell som distribueras till Azure Machine Learning-slutpunkten online. Hanterade onlineslutpunkter och Kubernetes onlineslutpunkter stöds. Anvisningar för hur du distribuerar en modell till en Azure Machine Learning-slutpunkt online finns i Distribuera och poängsätta en maskininlärningsmodell med hjälp av en onlineslutpunkt.
Datainsamling är aktiverad för modellimplementeringen. Du kan aktivera datainsamling under distributionssteget för Azure Machine Learning-slutpunkter online. Mer information finns i Samla in produktionsdata från modeller som distribuerats för inferens i realtid.
För övervakning av en modell som distribueras till en Azure Machine Learning-batchslutpunkt eller distribueras utanför Azure Machine Learning:
- Ett sätt att samla in produktionsdata och registrera dem som en Azure Machine Learning-datatillgång
- Ett sätt att kontinuerligt uppdatera den registrerade datatillgången för modellövervakning
- (Rekommenderas) Registrering av modellen på en Azure Machine Learning-arbetsyta för ursprungsspårning
Konfigurera en serverlös Spark-beräkningspool
Modellövervakningsjobb är schemalagda att köras på serverlösa Spark-beräkningspooler. Följande typer av Azure Virtual Machines-instanser stöds:
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standard_E64s_v3
Utför följande steg för att ange en typ av virtuell datorinstans när du följer procedurerna i den här artikeln:
När du använder Azure CLI för att skapa en övervakare använder du en YAML-konfigurationsfil. I filen anger du värdet create_monitor.compute.instance_type till den typ som du vill använda.
Konfigurera övervakning av färdiga modeller
Tänk dig ett scenario där du distribuerar din modell till produktion i en Azure Machine Learning-slutpunkt online och aktiverar datainsamling vid distributionstillfället. I det här fallet samlar Azure Machine Learning in produktionsinferensdata och lagrar dem automatiskt i Azure Blob Storage. Du kan använda Azure Machine Learning-modellövervakning för att kontinuerligt övervaka dessa produktionsinferensdata.
Du kan använda Azure CLI, Python SDK eller studio för en inbyggd konfiguration av modellövervakning. Den färdiga modellövervakningskonfigurationen innehåller följande övervakningsfunktioner:
- Azure Machine Learning identifierar automatiskt den datatillgång för produktionsinferens som är associerad med en Azure Machine Learning-onlinedistribution och använder datatillgången för modellövervakning.
- Jämförelsereferensdatatillgången anges som den senaste, tidigare datatillgången för produktionsinferens.
- Övervakningskonfigurationen innehåller och spårar automatiskt följande inbyggda övervakningssignaler: dataavvikelse, förutsägelseavvikelse och datakvalitet. För varje övervakningssignal använder Azure Machine Learning:
- Den senaste datatillgången för tidigare produktionsinferens som jämförelsereferensdatatillgång.
- Smarta standardvärden för mått och tröskelvärden.
- Ett övervakningsjobb är konfigurerat att köras enligt ett regelbundet schema. Det jobbet hämtar övervakningssignaler och utvärderar varje måttresultat mot motsvarande tröskelvärde. När ett tröskelvärde överskrids skickar Azure Machine Learning som standard ett e-postmeddelande till den användare som har konfigurerat övervakaren.
Utför följande steg för att konfigurera övervakning av färdiga modeller.
I Azure CLI använder az ml schedule du för att schemalägga ett övervakningsjobb.
Skapa en övervakningsdefinition i en YAML-fil. En exempeldefinition finns i följande YAML-kod, som också är tillgänglig på lagringsplatsen azureml-examples.
Innan du använder den här definitionen justerar du värdena så att de passar din miljö. För
endpoint_deployment_idanvänder du ett värde i formatetazureml:<endpoint-name>:<deployment-name>.# out-of-box-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: credit_default_model_monitoring display_name: Credit default model monitoring description: Credit default model monitoring setup with minimal configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: # specify a spark compute for monitoring job instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification # model task type: [classification, regression, question_answering] endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id alert_notification: # emails to get alerts emails: - abc@example.com - def@example.comKör följande kommando för att skapa modellen:
az ml schedule create -f ./out-of-box-monitoring.yaml


Konfigurera avancerad modellövervakning
Azure Machine Learning har många funktioner för kontinuerlig modellövervakning. En omfattande lista över den här funktionen finns i Funktioner för modellövervakning. I många fall måste du konfigurera modellövervakning som stöder avancerade övervakningsuppgifter. Följande avsnitt innehåller några exempel på avancerad övervakning:
- Användning av flera övervakningssignaler för en bred vy
- Användning av historiska modellträningsdata eller valideringsdata som jämförelsereferensdatatillgång
- Övervakning av N viktigaste funktionerna och enskilda funktioner
Konfigurera funktionsvikt
Funktionsvikt representerar den relativa betydelsen av varje indatafunktion för en modells utdata. Temperatur kan till exempel vara viktigare för en modells förutsägelse än förhöjning. När du aktiverar funktionsviktning kan du ge insyn i vilka funktioner du inte vill ska driva eller ha problem med datakvaliteten i produktionen.
Om du vill aktivera funktionsviktning för någon av dina signaler, till exempel dataavvikelse eller datakvalitet, måste du ange:
- Din träningsdatatillgång som
reference_datadatatillgång. - Egenskapen
reference_data.data_column_names.target_column, som är namnet på modellens utdatakolumn eller prognoskolumn.
När du har aktiverat funktionsvikt visas en funktionsvikt för varje funktion som du övervakar i Azure Machine Learning Studio.
Du kan aktivera eller inaktivera aviseringar för varje signal genom att ange alert_enabled egenskapen när du använder Python SDK eller Azure CLI.
Du kan använda Azure CLI, Python SDK eller studio för att konfigurera avancerad modellövervakning.
Skapa en övervakningsdefinition i en YAML-fil. En avancerad exempeldefinition finns i följande YAML-kod, som också är tillgänglig på lagringsplatsen azureml-examples.
Innan du använder den här definitionen justerar du följande inställningar och andra för att uppfylla behoven i din miljö:
- För
endpoint_deployment_idanvänder du ett värde i formatetazureml:<endpoint-name>:<deployment-name>. - Använd ett värde i formatet
pathförazureml:<reference-data-asset-name>:<version>i referensindataavsnitt. - För
target_columnanvänder du namnet på den utdatakolumn som innehåller värden som modellen förutsäger, till exempelDEFAULT_NEXT_MONTH. - För
featureslistar du funktioner somSEX,EDUCATIONochAGEsom du vill använda i en avancerad datakvalitetssignal. - Under
emailslistar du de e-postadresser som du vill använda för meddelanden.
# advanced-model-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with advanced configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:credit-default:main monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 # use training data as comparison reference dataset type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH features: top_n_feature_importance: 10 # monitor drift for top 10 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_data_quality: type: data_quality # reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training features: # monitor data quality for 3 individual features only - SEX - EDUCATION alert_enabled: true metric_thresholds: numerical: null_value_rate: 0.05 categorical: out_of_bounds_rate: 0.03 feature_attribution_drift_signal: type: feature_attribution_drift # production_data: is not required input here # Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data # Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH alert_enabled: true metric_thresholds: normalized_discounted_cumulative_gain: 0.9 alert_notification: emails: - abc@example.com - def@example.com- För
Kör följande kommando för att skapa modellen:
az ml schedule create -f ./advanced-model-monitoring.yaml






Konfigurera prestandaövervakning av modeller
När du använder Azure Machine Learning-modellövervakning kan du spåra prestanda för dina modeller i produktion genom att beräkna deras prestandamått. Följande modellprestandamått stöds för närvarande:
- För klassificeringsmodeller:
- Noggrannhet
- Noggrannhet
- Återkalla
- För regressionsmodeller:
- Genomsnittligt absolut fel (MAE)
- Genomsnittligt kvadratfel (MSE)
- RMSE (Root Mean Squared Error)
Krav för övervakning av modellprestanda
Utdata för produktionsmodellen (modellens förutsägelser) med ett unikt ID för varje rad. Om du använder Azure Machine Learning-datainsamlaren för att samla in produktionsdata tillhandahålls ett korrelations-ID för varje slutsatsdragningsbegäran åt dig. Datainsamlaren erbjuder också möjligheten att logga ditt eget unika ID från ditt program.
Kommentar
För prestandaövervakning av Azure Machine Learning-modeller rekommenderar vi att du använder Azure Machine Learning-datainsamlaren för att logga ditt unika ID i en egen kolumn.
Jorda sanningsdata (faktiska) med ett unikt ID för varje rad. Det unika ID:t för en viss rad ska matcha det unika ID:t för modellens utdata för den specifika slutsatsdragningsbegäran. Det här unika ID:t används för att koppla din grundsanningsdatatillgång till modellens utdata.
Om du inte har grundsanningsdata kan du inte utföra prestandaövervakning av modeller. Grund sanningsdata påträffas på programnivå, så det är ditt ansvar att samla in dem när de blir tillgängliga. Du bör också underhålla en datatillgång i Azure Machine Learning som innehåller dessa grundläggande sanningsdata.
(Valfritt) En föransluten tabelldatatillgång med modellutdata och marksanningsdata som redan är sammansatta.
Krav för övervakning av modellprestanda när du använder datainsamlaren
Azure Machine Learning genererar ett korrelations-ID åt dig när du uppfyller följande kriterier:
- Du använder Azure Machine Learning-datainsamlaren för att samla in data om produktionsinferens.
- Du anger inte ditt eget unika ID för varje rad som en separat kolumn.
Det genererade korrelations-ID:t ingår i det loggade JSON-objektet. Datainsamlaren batchar dock rader som skickas inom korta tidsintervall för varandra. Batchade rader hamnar inom samma JSON-objekt. I varje objekt har alla rader samma korrelations-ID.
För att skilja mellan raderna i ett JSON-objekt använder Prestandaövervakning i Azure Machine Learning-modellen indexering för att fastställa ordningen på raderna i objektet. Om en batch till exempel innehåller tre rader och korrelations-ID:t är testhar den första raden ett ID test_0för , den andra raden har ett ID test_1för och den tredje raden har ett ID för test_2. För att matcha de unika ID:erna för din grunddata med ID:erna för det insamlade data från produktionsmodellen för inferens, använd ett index för varje korrelations-ID på rätt sätt. Om ditt loggade JSON-objekt bara har en rad använder du correlationid_0 som correlationid värde.
För att undvika att använda den här indexeringen rekommenderar vi att du loggar ditt unika ID i en egen kolumn. Placera kolumnen i pandas-dataramen som Azure Machine Learning-datainsamlaren loggar. I modellövervakningskonfigurationen kan du sedan ange namnet på den här kolumnen för att koppla dina modellutdata till dina grundsanningsdata. Så länge ID:na för varje rad i båda datatillgångarna är desamma kan Azure Machine Learning-modellövervakning utföra modellprestandaövervakning.
Exempelarbetsflöde för övervakning av modellprestanda
Tänk på följande exempelarbetsflöde för att förstå de begrepp som är associerade med övervakning av modellprestanda. Det gäller för ett scenario där du distribuerar en modell för att förutsäga om kreditkortstransaktioner är bedrägliga:
- Konfigurera distributionen så att datainsamlaren används för att samla in modellens produktionsinferensdata (indata och utdata). Lagra utdata i en kolumn med namnet
is_fraud. - För varje rad i insamlade slutsatsdragningsdata loggar du ett unikt ID. Det unika ID:t kan komma från ditt program, eller så kan du använda värdet
correlationidsom Azure Machine Learning unikt genererar för varje loggat JSON-objekt. - När markinformationen (eller faktiska)
is_frauddata är tillgänglig loggar och mappar du varje rad till samma unika ID som loggas för motsvarande rad i modellens utdata. - Registrera en datatillgång i Azure Machine Learning och använd den för att samla in och underhålla grundsanningsdata
is_fraud. - Skapa en modellprestandaövervakningssignal som använder de unika ID-kolumnerna för att koppla modellens produktionsinferens och verkliga datatillgångar.
- Beräkna modellens prestandamått.
När du uppfyller kraven för övervakning av modellprestanda utför du följande steg för att konfigurera modellövervakning:
Skapa en övervakningsdefinition i en YAML-fil. Följande exempelspecifikation definierar modellövervakning med produktionsinferensdata. Innan du använder den här definitionen justerar du följande inställningar och andra för att uppfylla behoven i din miljö:
- För
endpoint_deployment_idanvänder du ett värde i formatetazureml:<endpoint-name>:<deployment-name>. - För varje
pathvärde i ett avsnitt med indata använder du ett värde i formatetazureml:<data-asset-name>:<version>. - För värdet
predictionanvänder du namnet på den utdatakolumn som innehåller värden som modellen förutsäger. - För värdet
actualanvänder du namnet på kolumnen ground truth som innehåller de faktiska värden som modellen försöker förutsäga. -
correlation_idFör värdena använder du namnen på de kolumner som används för att koppla utdata och grundsanningsdata. - Under
emailslistar du de e-postadresser som du vill använda för meddelanden.
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.3" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com- För
Kör följande kommando för att skapa modellen:
az ml schedule create -f ./model-performance-monitoring.yaml





Konfigurera modellövervakning av produktionsdata
Du kan också övervaka modeller som du distribuerar till Azure Machine Learning-batchslutpunkter eller som du distribuerar utanför Azure Machine Learning. Om du inte har någon distribution men har produktionsdata kan du använda data för att utföra kontinuerlig modellövervakning. Om du vill övervaka dessa modeller måste du kunna:
- Samla in produktionsinferensdata från modeller som distribuerats i produktion.
- Registrera produktionsinferensdata som en Azure Machine Learning-datatillgång och se till att data uppdateras kontinuerligt.
- Ange en komponent för förbearbetning av anpassade data och registrera den som en Azure Machine Learning-komponent om du inte använder datainsamlaren för att samla in data. Utan den här komponenten för förbearbetning av anpassade data kan azure Machine Learning-modellövervakningssystemet inte bearbeta dina data till ett tabellformulär som stöder tidsfönster.
Din anpassade förbearbetningskomponent måste ha följande signaturer för in- och utdata:
| Indata eller utdata | Signaturnamn | Typ | Beskrivning | Exempelvärde |
|---|---|---|---|---|
| indata | data_window_start |
literal, sträng | Starttiden för datafönstret i ISO8601 format | 2023-05-01T04:31:57.012Z |
| indata | data_window_end |
literal, sträng | Datafönstrets sluttid i ISO8601 format | 2023-05-01T04:31:57.012Z |
| indata | input_data |
uri_folder | Insamlade produktionsinferensdata, som är registrerade som en Azure Machine Learning-datatillgång | azureml:myproduction_inference_data:1 |
| utdata | preprocessed_data |
mltable | En tabelldatatillgång som matchar en delmängd av referensdataschemat |
Ett exempel på en komponent för förbearbetning av anpassade data finns i custom_preprocessing i GitHub-lagringsplatsen azuremml-examples.
Anvisningar för hur du registrerar en Azure Machine Learning-komponent finns i Registrera komponenten på din arbetsyta.
När du har registrerat dina produktionsdata och förbearbetningskomponenten kan du konfigurera modellövervakning.
Skapa en YAML-fil för övervakningsdefinition som liknar följande. Innan du använder den här definitionen justerar du följande inställningar och andra för att uppfylla behoven i din miljö:
- För
endpoint_deployment_idanvänder du ett värde i formatetazureml:<endpoint-name>:<deployment-name>. - För
pre_processing_componentanvänder du ett värde i formatetazureml:<component-name>:<component-version>. Ange den exakta versionen, till exempel1.0.0, inte1. - För varje
pathanvänder du ett värde i formatetazureml:<data-asset-name>:<version>. - För värdet
target_columnanvänder du namnet på den utdatakolumn som innehåller värden som modellen förutsäger. - Under
emailslistar du de e-postadresser som du vill använda för meddelanden.
# model-monitoring-with-collected-data.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with your own production data trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_inputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_training_data:1 # use training data as comparison baseline type: mltable data_context: training data_column_names: target_column: is_fraud features: top_n_feature_importance: 20 # monitor drift for top 20 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_prediction_drift: # monitoring signal name, any user defined name works type: prediction_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_outputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset type: mltable data_context: validation alert_enabled: true metric_thresholds: categorical: pearsons_chi_squared_test: 0.02 alert_notification: emails: - abc@example.com - def@example.com- För
Kör följande kommando för att skapa modellen.
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Konfigurera modellövervakning med anpassade signaler och mått
När du använder Azure Machine Learning-modellövervakning kan du definiera en anpassad signal och implementera valfritt mått för att övervaka din modell. Du kan registrera din anpassade signal som en Azure Machine Learning-komponent. När modellövervakningsjobbet körs enligt det angivna schemat beräknas de mått som definieras i din anpassade signal, precis som för de fördefinierade signalerna för dataavvikelse, förutsägelseavvikelse och datakvalitet.
Om du vill konfigurera en anpassad signal som ska användas för modellövervakning måste du först definiera den anpassade signalen och registrera den som en Azure Machine Learning-komponent. Azure Machine Learning-komponenten måste ha följande signaturer för in- och utdata.
Signatur för komponentindata
Indataramen för komponenten bör innehålla följande objekt:
- En
mltablestruktur som innehåller bearbetade data från förbearbetningskomponenten. - Valfritt antal literaler, som var och en representerar ett implementerat mått som en del av den anpassade signalkomponenten. Om du till exempel implementerar måttet
std_deviationbehöver du indata förstd_deviation_threshold. Generellt sett bör det finnas en inmatning med namnet<metric-name>_thresholdför varje mått.
| Signaturnamn | Typ | Beskrivning | Exempelvärde |
|---|---|---|---|
production_data |
mltable | En tabelldatatillgång som matchar en delmängd av referensdataschemat | |
std_deviation_threshold |
literal, sträng | Respektive tröskelvärde för det implementerade måttet | 2 |
Signatur för komponentutdata
Komponentens utdataport bör ha följande signatur:
| Signaturnamn | Typ | Beskrivning |
|---|---|---|
signal_metrics |
mltable | Mltable-strukturen som innehåller de beräknade måtten. Schemat för den här signaturen finns i nästa avsnitt signal_metrics schema. |
signalmetrikschema
Komponentens utdataram ska innehålla fyra kolumner: group, metric_name, metric_valueoch threshold_value.
| Signaturnamn | Typ | Beskrivning | Exempelvärde |
|---|---|---|---|
group |
literal, sträng | Den logiska grupperingen på den översta nivån som ska tillämpas på det anpassade måttet | Transaktionsbelopp |
metric_name |
literal, sträng | Namnet på det anpassade måttet | standardavvikelse |
metric_value |
numerisk | Värdet för det anpassade måttet | 44,896.082 |
threshold_value |
numerisk | Tröskelvärdet för det anpassade måttet | 2 |
I följande tabell visas exempelutdata från en anpassad signalkomponent som beräknar måttet std_deviation :
| grupp | värde för måttenhet | metriknamn | tröskelvärde |
|---|---|---|---|
| Transaktionsbelopp | 44,896.082 | standardavvikelse | 2 |
| LOCALHOUR | 3.983 | standardavvikelse | 2 |
| TRANSAKTIONSBELOPPUSD | 54 004,902 | standardavvikelse | 2 |
| DIGITALITEMCOUNT | 7.238 | standardavvikelse | 2 |
| PHYSICALITEMCOUNT | 5.509 | standardavvikelse | 2 |
Ett exempel på en anpassad signalkomponentdefinition och måttberäkningskod finns i custom_signal i lagringsplatsen azureml-examples.
Anvisningar för hur du registrerar en Azure Machine Learning-komponent finns i Registrera komponenten på din arbetsyta.
När du har skapat och registrerat din anpassade signalkomponent i Azure Machine Learning utför du följande steg för att konfigurera modellövervakning:
Skapa en övervakningsdefinition i en YAML-fil som liknar följande. Innan du använder den här definitionen justerar du följande inställningar och andra för att uppfylla behoven i din miljö:
- För
component_idanvänder du ett värde i formatetazureml:<custom-signal-name>:1.0.0. - I avsnittet indata
pathanvänder du ett värde i formatetazureml:<production-data-asset-name>:<version>. - För
pre_processing_component:- Om du använder datainsamlaren för att samla in dina data kan du utelämna egenskapen
pre_processing_component. - Om du inte använder datainsamlaren och vill använda en komponent för att förbearbeta produktionsdata använder du ett värde i formatet
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>.
- Om du använder datainsamlaren för att samla in dina data kan du utelämna egenskapen
- Under
emailslistar du de e-postadresser som du vill använda för meddelanden.
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com- För
Kör följande kommando för att skapa modellen:
az ml schedule create -f ./custom-monitoring.yaml
Tolka övervakningsresultat
När du har konfigurerat modellövervakaren och den första körningen är klar kan du visa resultatet i Azure Machine Learning Studio.
I studion går du till Hantera och väljer Övervakning. På sidan Övervakning väljer du namnet på modellövervakaren för att se dess översiktssida. Den här sidan visar övervakningsmodellen, slutpunkten och distributionen. Den innehåller också detaljerad information om konfigurerade signaler. Följande bild visar en övervakningsöversiktssida som innehåller dataavvikelser och datakvalitetssignaler.
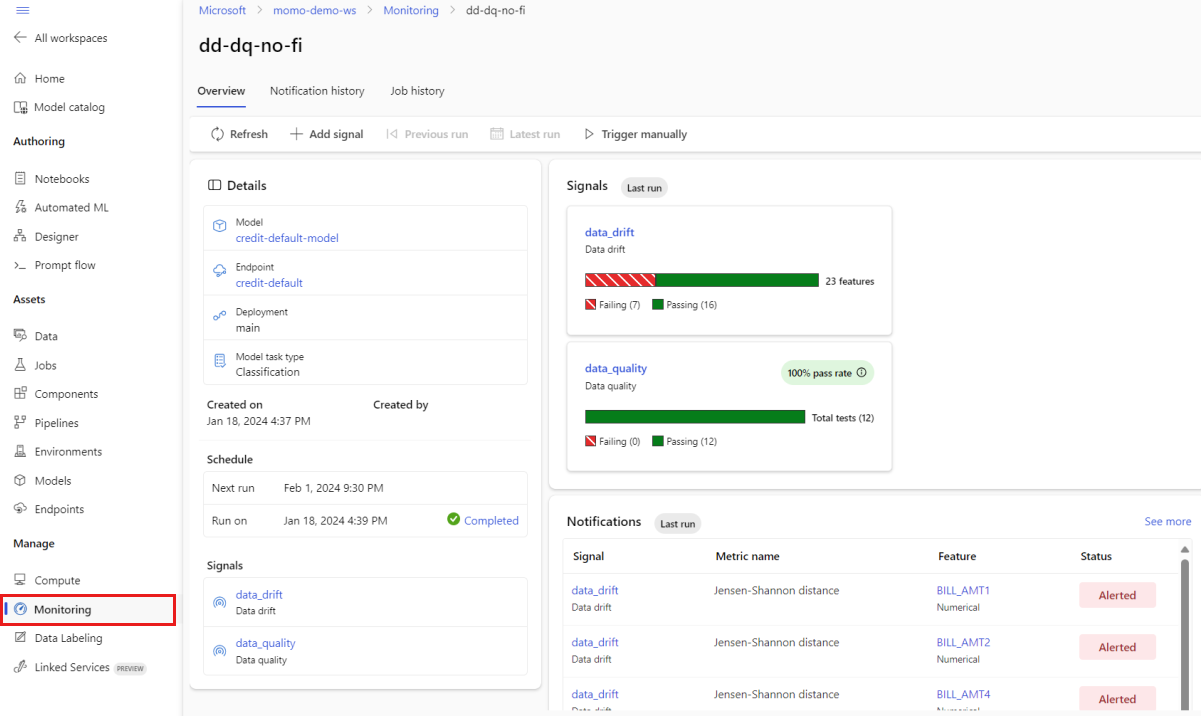
Titta i avsnittet Meddelanden på översiktssidan. I det här avsnittet kan du se funktionen för varje signal som bryter mot det konfigurerade tröskelvärdet för respektive mått.
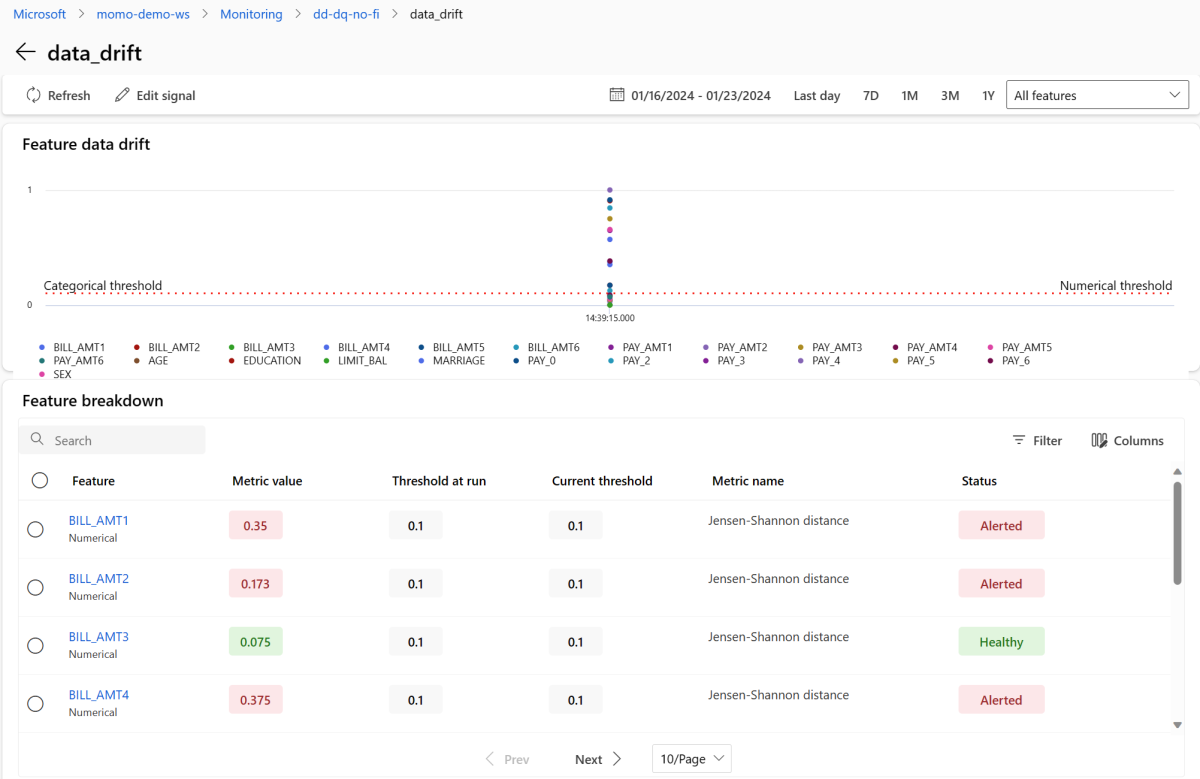
I avsnittet Signaler väljer du data_drift för att se detaljerad information om dataavvikelsesignalen. På informationssidan kan du se måttvärdet för dataavvikelser för varje numerisk och kategorisk funktion som din övervakningskonfiguration innehåller. Om din övervakning har fler än en mätning, visas en trendlinje för varje funktion.
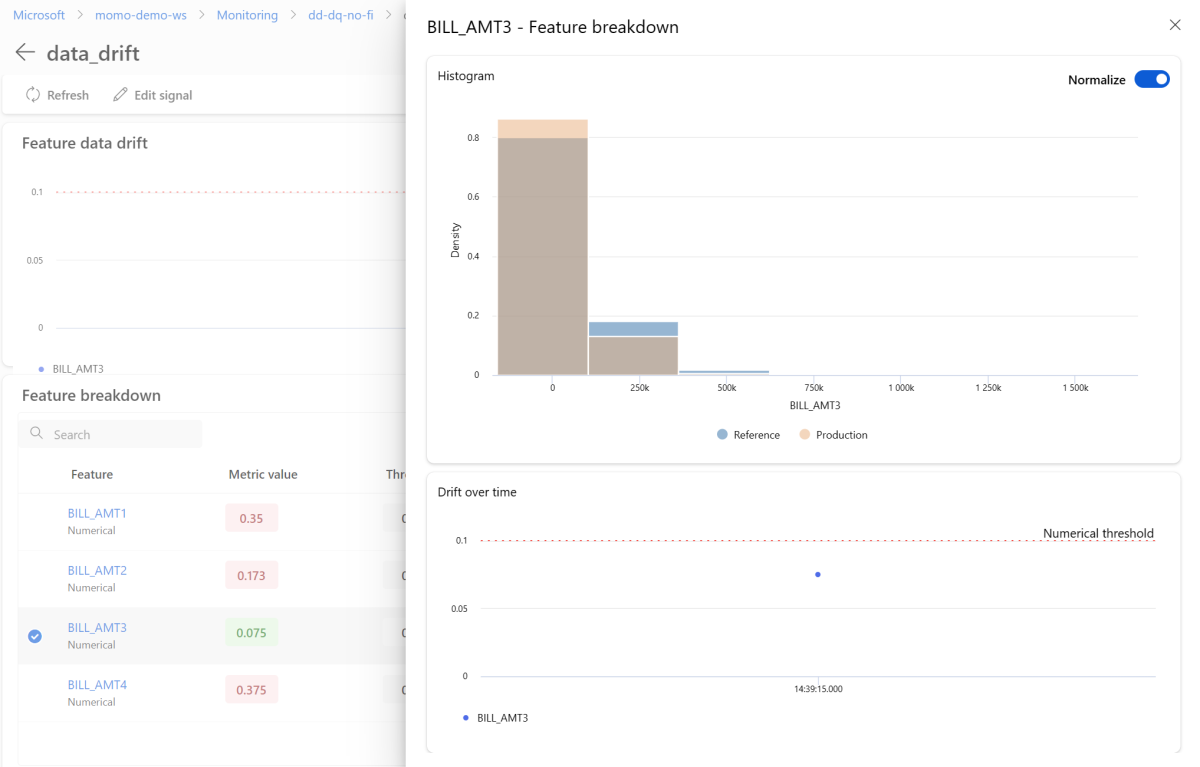
På informationssidan väljer du namnet på en enskild funktion. En detaljerad vy öppnas som visar produktionsdistributionen jämfört med referensdistributionen. Du kan också använda den här vyn för att spåra drift över tid för funktionen.
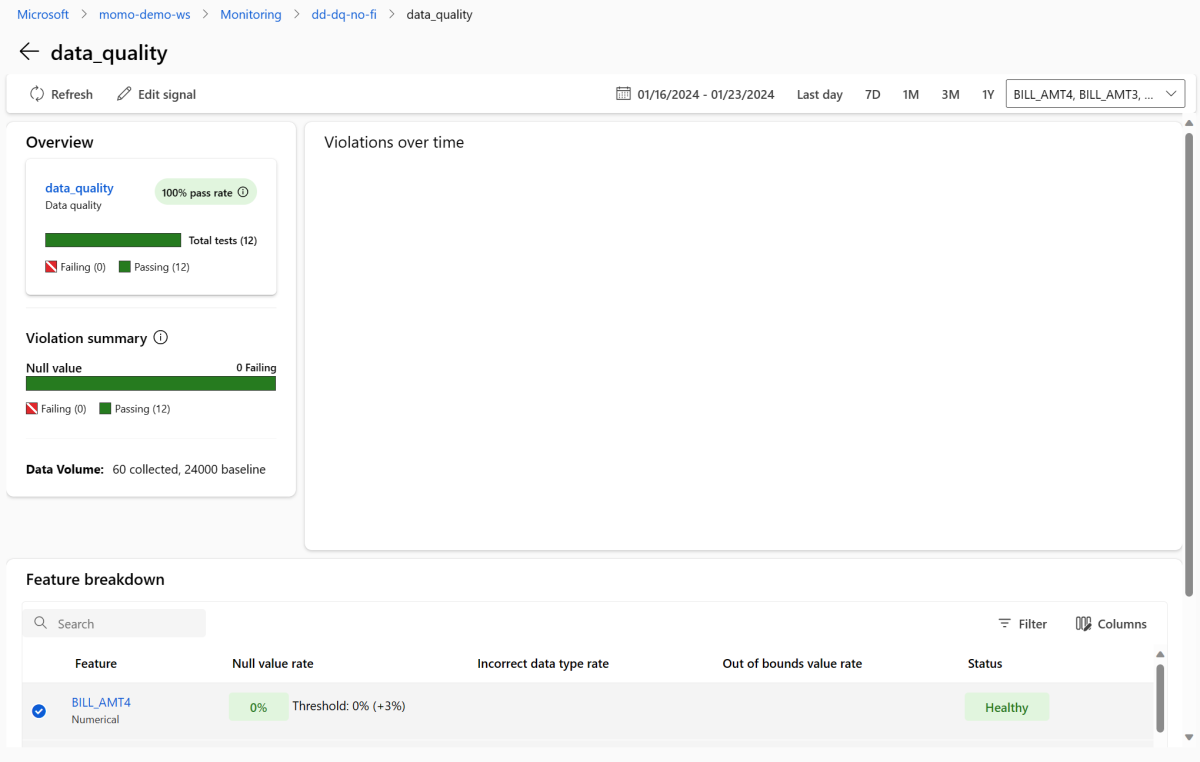
Gå tillbaka till övervakningsöversiktssidan. I avsnittet Signaler väljer du data_quality för att visa detaljerad information om den här signalen. På den här sidan kan du se frekvenser av null-värde, gränsöverskridande frekvenser och datatypfel-frekvenser för varje egenskap som du övervakar.




Modellövervakning är en kontinuerlig process. När du använder Azure Machine Learning-modellövervakning kan du konfigurera flera övervakningssignaler för att få en bred överblick över prestanda för dina modeller i produktion.
Integrera Azure Machine Learning-modellövervakning med Event Grid
När du använder Event Grid kan du konfigurera händelser som genereras av Azure Machine Learning-modellövervakning för att utlösa program, processer och CI/CD-arbetsflöden. Du kan använda händelser via olika händelsehanterare, till exempel Azure Event Hubs, Azure Functions och Azure Logic Apps. När dina övervakare identifierar drift kan du vidta åtgärder programmatiskt, till exempel genom att köra en maskininlärningspipeline för att träna om en modell och distribuera om den.
Utför stegen i följande avsnitt för att integrera azure machine learning-modellövervakning med Event Grid.
Skapa ett systemämne
Om du inte har ett Event Grid-systemämne att använda för övervakning skapar du ett. Anvisningar finns i Avsnittet om att skapa, visa och hantera Event Grid-system i Azure-portalen.
Skapa en händelseprenumeration
I Azure-portalen går du till din Azure Machine Learning-arbetsyta.
Välj Händelser och välj sedan Händelseprenumeration.

Bredvid Namn anger du ett namn för din händelseprenumeration, till exempel MonitoringEvent.
Under Händelsetyper väljer du endast Kör status ändrad.
Varning
Välj endast Körstatus ändrad för händelsetypen. Välj inte Identifierad datauppsättningsdrift, vilket gäller för dataavvikelse v1, inte för övervakning av Azure Machine Learning-modeller.
Välj fliken Filter . Under Avancerade filter väljer du Lägg till nytt filter och anger sedan följande värden:
- Under Nyckel anger du data.RunTags.azureml_modelmonitor_threshold_breached.
- Under Operator väljer du Sträng innehåller.
- Under Värde, ange har misslyckats på grund av att en eller flera funktioner bryter mot metrikktrösklar.

När du använder det här filtret genereras händelser när körningsstatusen för alla övervakare på din Azure Machine Learning-arbetsyta ändras. Körningsstatusen kan ändras från slutförd till misslyckad eller från misslyckad till slutförd.
Om du vill filtrera på övervakningsnivå väljer du Lägg till nytt filter igen och anger sedan följande värden:
- Under Nyckel anger du data.RunTags.azureml_modelmonitor_threshold_breached.
- Under Operator väljer du Sträng innehåller.
- Under Värde anger du namnet på en övervakningssignal som du vill filtrera händelser för, till exempel credit_card_fraud_monitor_data_drift. Namnet som du anger måste matcha namnet på din övervakningssignal. Alla signaler som du använder i filtreringen ska ha ett namn i formatet
<monitor-name>_<signal-description>som innehåller namnet på monitorn och en beskrivning av signalen.
Välj fliken Grundläggande . Konfigurera den slutpunkt som du vill fungera som händelsehanterare, till exempel Event Hubs.
Välj Skapa för att skapa händelseprenumerationen.

Visa händelser
När du har avbildat händelser kan du visa dem på sidan för händelsehanterarens slutpunkt:

Du kan också visa händelser på fliken Azure Monitor Metrics :
