Använda pipelineparametrar för att träna om modeller i designern
I den här instruktionsartikeln får du lära dig hur du använder Azure Machine Learning Designer för att träna om en maskininlärningsmodell med hjälp av pipelineparametrar. Du använder publicerade pipelines för att automatisera arbetsflödet och ange parametrar för att träna din modell på nya data. Med pipelineparametrar kan du återanvända befintliga pipelines för olika jobb.
I den här artikeln kan du se hur du:
- Träna en maskininlärningsmodell.
- Skapa en pipelineparameter.
- Publicera din träningspipeline.
- Träna om din modell med nya parametrar.
Förutsättningar
- En Azure Machine Learning-arbetsyta
- Slutför del 1 av den här instruktioner-serien, Transformera data i designern
Viktigt!
Om du inte ser grafiska element som nämns i det här dokumentet, till exempel knappar i studio eller designer, kanske du inte har rätt behörighetsnivå för arbetsytan. Kontakta azure-prenumerationsadministratören för att kontrollera att du har beviljats rätt åtkomstnivå. Mer information finns i Hantera användare och roller.
Den här artikeln förutsätter också att du har viss kunskap om att skapa pipelines i designern. För en guidad introduktion, slutför du självstudien.
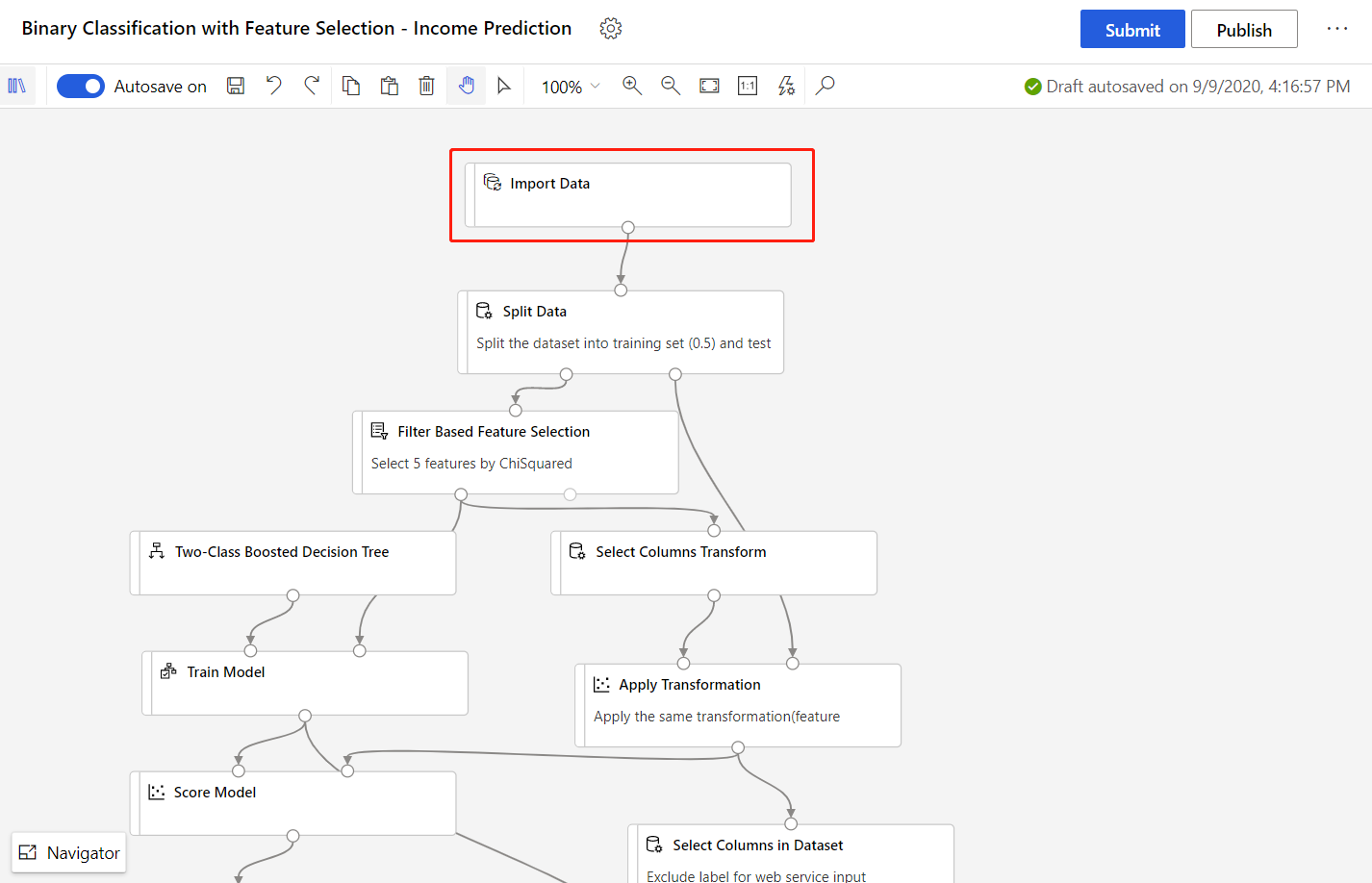
Exempelpipeline
Pipelinen som används i den här artikeln är en ändrad version av en exempelpipeline Inkomstförutsägelse på designerns startsida. Pipelinen använder komponenten Importera data i stället för exempeldatauppsättningen för att visa hur du tränar modeller med dina egna data.
Skapa en pipelineparameter
Pipelineparametrar används för att skapa mångsidiga pipelines som kan skickas på nytt senare med varierande parametervärden. Några vanliga scenarier är uppdatering av datauppsättningar eller några hyperparametrar för omträning. Skapa pipelineparametrar för att dynamiskt ange variabler vid körning.
Pipelineparametrar kan läggas till i datakällan eller komponentparametrarna i en pipeline. När pipelinen skickas på nytt kan värdena för dessa parametrar anges.
I det här exemplet ändrar du utbildningsdatasökvägen från ett fast värde till en parameter, så att du kan träna om din modell på olika data. Du kan också lägga till andra komponentparametrar som pipelineparametrar enligt ditt användningsfall.
Välj komponenten Importera data .
Kommentar
I det här exemplet används komponenten Importera data för att komma åt data i ett registrerat datalager. Du kan dock följa liknande steg om du använder alternativa dataåtkomstmönster.
Välj din datakälla till höger om arbetsytan i detaljfönstret för komponenten.
Ange sökvägen till dina data. Du kan också välja Bläddra sökväg för att bläddra i filträdet.
Musen över fältet Sökväg och välj ellipserna ovanför fältet Sökväg som visas.
Välj Lägg till i pipelineparameter.
Ange ett parameternamn och ett standardvärde.
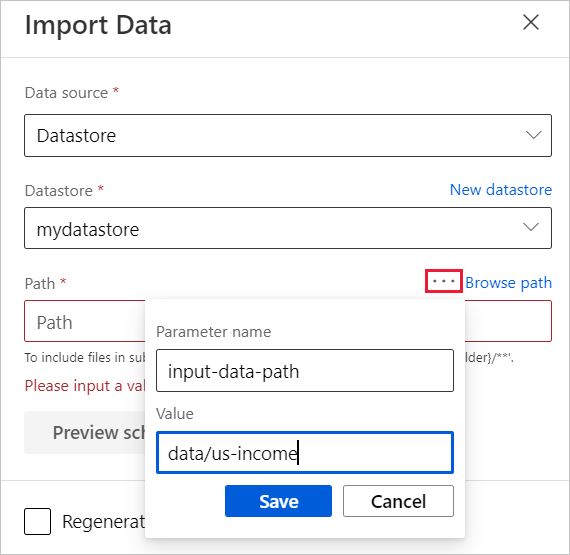
Välj Spara.
Kommentar
Du kan också koppla från en komponentparameter från pipelineparametern i komponentinformationsfönstret, ungefär som när du lägger till pipelineparametrar.
Du kan inspektera och redigera dina pipelineparametrar genom att välja kugghjulsikonen Inställningar bredvid rubriken på pipelineutkastet.
- När du har tagit bort den kan du ta bort pipelineparametern i fönstret Uppsättningar .
- Du kan också lägga till en pipelineparameter i fönstret Inställningar och sedan tillämpa den på någon komponentparameter.
Skicka pipelinejobbet.
Publicera en träningspipeline
Publicera en pipeline till en pipelineslutpunkt för att enkelt återanvända dina pipelines i framtiden. En pipelineslutpunkt skapar en REST-slutpunkt för att anropa pipeline i framtiden. I det här exemplet kan du använda pipelineslutpunkten för att återanvända din pipeline för att träna om en modell på olika data.
Välj Publicera ovanför designerarbetsytan.
Välj eller skapa en pipelineslutpunkt.
Kommentar
Du kan publicera flera pipelines till en enda slutpunkt. Varje pipeline i en viss slutpunkt får ett versionsnummer som du kan ange när du anropar pipelineslutpunkten.
Välj Publicera.
Träna om din modell
Nu när du har en publicerad träningspipeline kan du använda den för att träna om din modell på nya data. Du kan skicka jobb från en pipelineslutpunkt från studioarbetsytan eller programmatiskt.
Skicka jobb med studioportalen
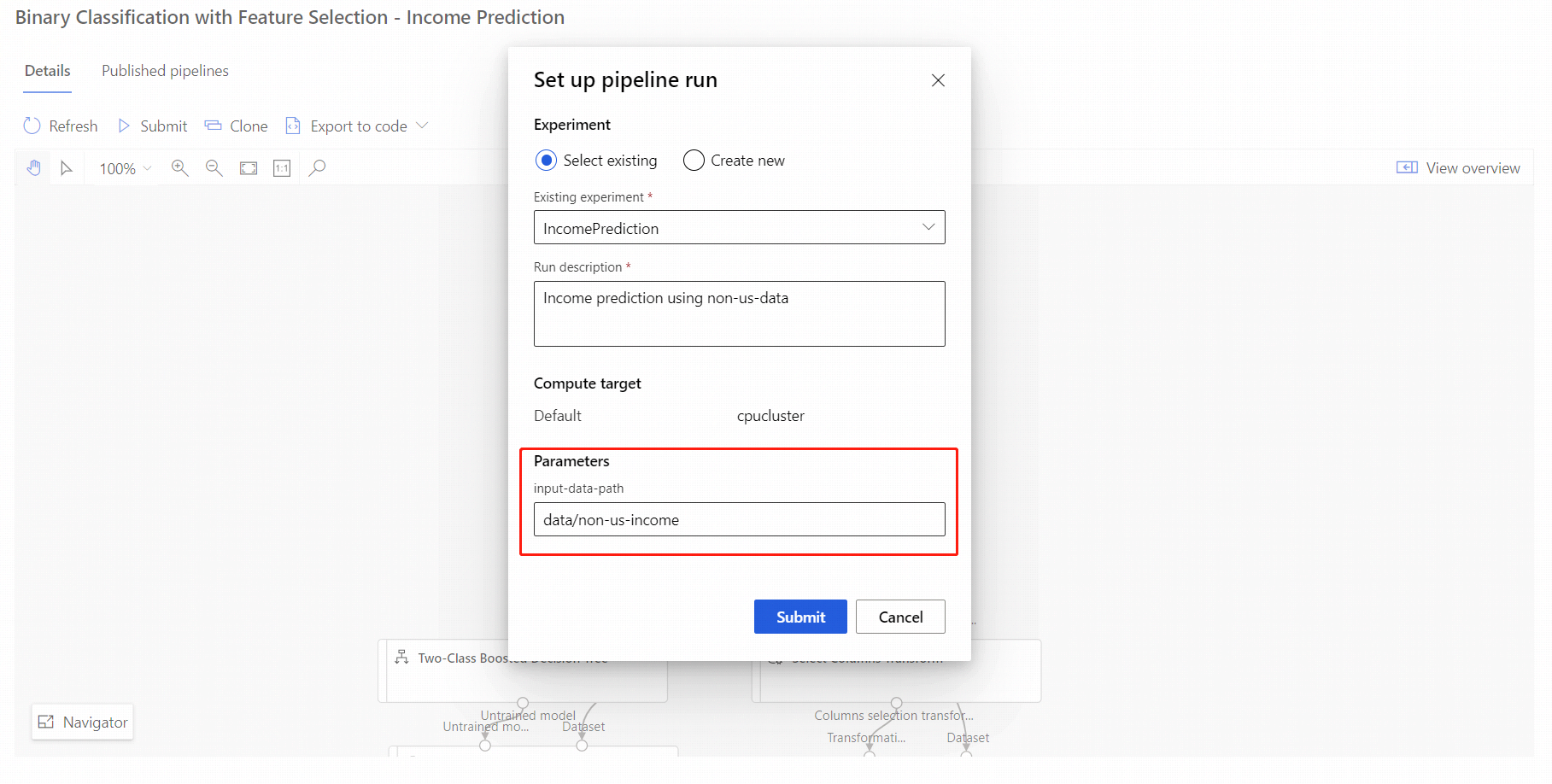
Använd följande steg för att skicka ett parameteriserat pipelineslutpunktsjobb från studioportalen:
- Gå till sidan Slutpunkter i studioarbetsytan.
- Välj fliken Pipelineslutpunkter . Välj sedan pipelineslutpunkten.
- Välj fliken Publicerade pipelines . Välj sedan den pipelineversion som du vill köra.
- Välj Skicka.
- I installationsdialogrutan kan du ange parametervärdena för jobbet. I det här exemplet uppdaterar du datasökvägen för att träna din modell med hjälp av en datauppsättning som inte kommer från USA.
Skicka jobb med hjälp av kod
Du hittar REST-slutpunkten för en publicerad pipeline i översiktspanelen. Genom att anropa slutpunkten kan du träna om den publicerade pipelinen.
För att göra ett REST-anrop behöver du ett autentiseringshuvud av typen OAuth 2.0-ägartyp. Information om hur du konfigurerar autentisering till din arbetsyta och gör ett parametriserat REST-anrop finns i Använda REST för att hantera resurser.
Nästa steg
I den här artikeln har du lärt dig hur du skapar en slutpunkt för en parametriserad träningspipeline med hjälp av designern.
En fullständig genomgång av hur du kan distribuera en modell för att göra förutsägelser finns i designguiden för att träna och distribuera en regressionsmodell.
Information om hur du publicerar och skickar ett jobb till pipelineslutpunkten med hjälp av SDK v1 finns i Publicera pipelines.