Komma åt data i ett jobb
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
I den här artikeln lär du dig:
- Läsa data från Azure Storage i ett Azure Machine Learning-jobb.
- Så här skriver du data från ditt Azure Machine Learning-jobb till Azure Storage.
- Skillnaden mellan monterings- och nedladdningslägen .
- Så här använder du användaridentitet och hanterad identitet för att komma åt data.
- Monteringsinställningar som är tillgängliga i ett jobb.
- Optimala monteringsinställningar för vanliga scenarier.
- Så här kommer du åt V1-datatillgångar.
Förutsättningar
En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
En Azure Machine Learning-arbetsyta
Snabbstart
Innan du utforskar de detaljerade alternativ som är tillgängliga för dig när du kommer åt data beskriver vi först relevanta kodfragment för dataåtkomst.
Läsa data från Azure Storage i ett Azure Machine Learning-jobb
I det här exemplet skickar du ett Azure Machine Learning-jobb som kommer åt data från ett offentligt bloblagringskonto. Du kan dock anpassa kodfragmentet för att komma åt dina egna data i ett privat Azure Storage-konto. Uppdatera sökvägen enligt beskrivningen här. Azure Machine Learning hanterar sömlöst autentisering till molnlagring med Microsoft Entra-genomströmning. När du skickar ett jobb kan du välja:
- Användaridentitet: Genomströmning av din Microsoft Entra-identitet för att få åtkomst till data
- Hanterad identitet: Använd den hanterade identiteten för beräkningsmålet för att komma åt data
- Ingen: Ange ingen identitet för åtkomst till data. Använd Ingen när du använder autentiseringsbaserade datalager (nyckel-/SAS-token) eller vid åtkomst till offentliga data
Dricks
Om du använder nycklar eller SAS-token för att autentisera rekommenderar vi att du skapar ett Azure Machine Learning-datalager, eftersom körningen automatiskt ansluter till lagringen utan exponering av nyckeln/token.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Skriva data från ditt Azure Machine Learning-jobb till Azure Storage
I det här exemplet skickar du ett Azure Machine Learning-jobb som skriver data till ditt standarddatalager för Azure Machine Learning. Du kan också ange värdet för name din datatillgång för att skapa en datatillgång i utdata.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure Machine Learning-datakörningen
När du skickar ett jobb styr Azure Machine Learning-datakörningen datainläsningen, från lagringsplatsen till beräkningsmålet. Azure Machine Learning-datakörningen är optimerad för hastighet och effektivitet för maskininlärningsuppgifter. De viktigaste fördelarna är:
- Data läses in på Rust-språket, ett språk som är känt för hög hastighet och hög minneseffektivitet. För samtidiga datanedladdningar undviker Rust problem med Python Global Tolklås (GIL)
- Lätt vikt; Rust har inga beroenden för andra tekniker , till exempel JVM. Därför installeras körningen snabbt, och den tömmer inte extra resurser (CPU, minne) på beräkningsmålet
- Datainläsning med flera processer (parallell)
- Förinstallerar data som en bakgrundsaktivitet på processorerna för att möjliggöra bättre användning av GPU:er när du utför djupinlärning
- Sömlös autentiseringshantering till molnlagring
- Innehåller alternativ för att montera data (ström) eller ladda ned alla data. Mer information finns i avsnitten Montering (direktuppspelning) och Ladda ned .
- Sömlös integrering med fsspec – ett enhetligt python-gränssnitt till lokala, fjärranslutna och inbäddade filsystem och bytelagring.
Dricks
Vi rekommenderar att du använder Azure Machine Learning-datakörningen i stället för att skapa din egen monterings-/nedladdningsfunktion i din träningskod (klient). Vi har observerat begränsningar för lagringsdataflöde när klientkoden använder Python för att ladda ned data från lagring, på grund av problem med global tolklåsning (GIL).
Sekvenser
När du anger indata/utdata för ett jobb måste du ange en path parameter som pekar på dataplatsen. Den här tabellen visar de olika dataplatser som Azure Machine Learning stöder och visar path även parameterexempel:
| Plats | Exempel | Indata | Utdata |
|---|---|---|---|
| En sökväg på den lokala datorn | ./home/username/data/my_data |
Y | N |
| En sökväg på en offentlig http-server | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| En sökväg i Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, endast för identitetsbaserad autentisering. | N |
| En sökväg i ett Azure Machine Learning-datalager | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| En sökväg till en datatillgång | azureml:<my_data>:<version> |
Y | N, men du kan använda name och version för att skapa en datatillgång från utdata |
Lägen
När du kör ett jobb med dataindata/utdata kan du välja bland följande lägesalternativ :
ro_mount: Montera lagringsplats som skrivskyddad på beräkningsmålet för den lokala disken (SSD).rw_mount: Montera lagringsplats som skrivskyddad på den lokala diskens (SSD) beräkningsmål.download: Ladda ned data från lagringsplatsen till beräkningsmålet för den lokala disken (SSD).upload: Ladda upp data från beräkningsmålet till lagringsplatsen.eval_mount/eval_download: Dessa lägen är unika för MLTable. I vissa scenarier kan en MLTable ge filer som kan finnas i ett lagringskonto som skiljer sig från lagringskontot som är värd för MLTable-filen. Eller så kan en MLTable dela upp eller blanda data som finns i lagringsresursen. Den vyn av delmängden/shuffle blir bara synlig om Azure Machine Learning-datakörningen faktiskt utvärderar MLTable-filen. Det här diagrammet visar till exempel hur en MLTable som används medeval_mountellereval_downloadkan ta bilder från två olika lagringscontainrar och en anteckningsfil som finns i ett annat lagringskonto och sedan montera/ladda ned till filsystemet för fjärrberäkningsmålet.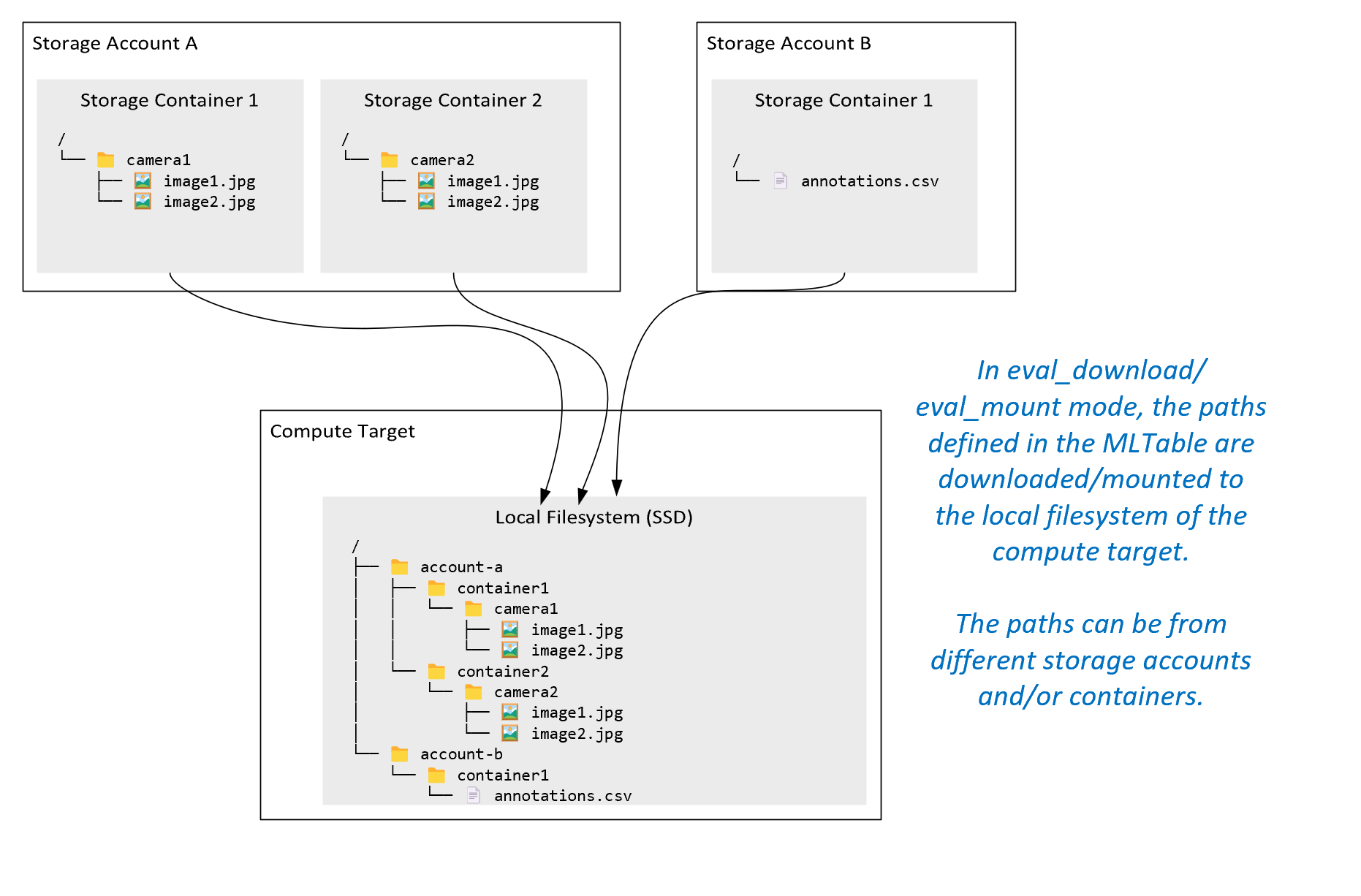
Mappen
camera1,camera2mappen ochannotations.csvfilen är sedan tillgängliga i beräkningsmålets filsystem i mappstrukturen:/INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Du kanske vill läsa data direkt från en URI via andra API:er i stället för att gå igenom Azure Machine Learning-datakörningen. Du kanske till exempel vill komma åt data på en s3-bucket (med en URL i virtuellt värdformat eller sökvägsformathttps) med hjälp av boto s3-klienten. Du kan hämta URI:n för indata som en sträng meddirectläget . Du ser användningen av direktläget i Spark-jobb eftersomspark.read_*()metoderna vet hur URI:erna bearbetas. För icke-Spark-jobb är det ditt ansvar att hantera åtkomstautentiseringsuppgifter. Du måste till exempel uttryckligen använda beräknings-MSI eller på annat sätt asynkron koordinatoråtkomst.

Den här tabellen visar möjliga lägen för olika kombinationer av typ/läge/indata/utdata:
| Typ | Indata/utdata | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Indata | ✓ | ✓ | ✓ | ||||
uri_file |
Indata | ✓ | ✓ | ✓ | ||||
mltable |
Indata | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Utdata | ✓ | ✓ | |||||
uri_file |
Utdata | ✓ | ✓ | |||||
mltable |
Utdata | ✓ | ✓ | ✓ |
Ladda ned
I nedladdningsläge kopieras alla indata till den lokala disken (SSD) för beräkningsmålet. Azure Machine Learning-datakörningen startar användarträningsskriptet när alla data har kopierats. När användarskriptet startar läser det data från den lokala disken, precis som andra filer. När jobbet är klart tas data bort från disken för beräkningsmålet.
| Fördelar | Nackdelar |
|---|---|
| När träningen startar är alla data tillgängliga på den lokala disken (SSD) för beräkningsmålet för träningsskriptet. Ingen Azure Storage-/nätverksinteraktion krävs. | Datamängden måste vara helt anpassad på en beräkningsmåldisk. |
| När användarskriptet har startat finns det inga beroenden för lagring/nätverkstillförlitlighet. | Hela datamängden laddas ned (om träningen bara behöver välja en liten del av data slumpmässigt slösas mycket av nedladdningen bort). |
| Azure Machine Learning-datakörning kan parallellisera nedladdningen (betydande skillnad på många små filer) och maximalt dataflöde för nätverk/lagring. | Jobbet väntar tills alla data laddas ned till den lokala disken för beräkningsmålet. För ett skickat djupinlärningsjobb är GPU:erna inaktiva tills data är klara. |
| Inga oundvikliga omkostnader som läggs till av FUSE-lagret (tur och retur: användarutrymmesanrop i användarskriptet → kernel → daemon för användarutrymmessäkring → kernel → svar på användarskript i användarutrymmet) | Lagringsändringar återspeglas inte i data när nedladdningen är klar. |
När du ska använda nedladdning
- Data är tillräckligt små för att få plats på beräkningsmålets disk utan interferens med annan träning
- Träningen använder de flesta eller alla datamängder
- Utbildningen läser filer från en datauppsättning mer än en gång
- Träningen måste hoppa till slumpmässiga positioner i en stor fil
- Det är ok att vänta tills alla data laddas ned innan träningen startar
Tillgängliga nedladdningsinställningar
Du kan justera nedladdningsinställningarna med dessa miljövariabler i jobbet:
| Miljövariabelns namn | Typ | Standardvärde | beskrivning |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Antal samtidiga trådar som kan laddas ned |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Antal återförsök av enskilda lagrings-/ http begäranden om återställning från tillfälliga fel. |
I ditt jobb kan du ändra standardvärdena ovan genom att ange miljövariablerna, till exempel:
För korthet visar vi bara hur du definierar miljövariablerna i jobbet.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Ladda ned prestandamått
Storleken på den virtuella datorn för beräkningsmålet påverkar nedladdningstiden för dina data. Specifikt:
- Antalet kärnor. Ju fler kärnor som är tillgängliga, desto mer samtidighet och därmed snabbare nedladdningshastighet.
- Den förväntade nätverksbandbredden. Varje virtuell dator i Azure har ett maximalt dataflöde från nätverkskortet (NIC).
Kommentar
För virtuella A100 GPU-datorer kan Azure Machine Learning-datakörningen mätta nätverkskortet (nätverksgränssnittskortet) när data laddas ned till beräkningsmålet (~24 Gbit/s): Det teoretiska största möjliga dataflödet.
Den här tabellen visar nedladdningsprestanda som Azure Machine Learning-datakörningen kan hantera för en fil på 100 GB på en Standard_D15_v2 virtuell dator (20 kärnor, 25 Gbit/s nätverksdataflöde):
| Datastruktur | Ladda endast ned (sek) | Ladda ned och beräkna MD5 (sek) | Uppnått dataflöde (Gbit/s) |
|---|---|---|---|
| 10 x 10 GB filer | 55.74 | 260.97 | 14,35 Gbit/s |
| 100 x 1 GB filer | 58.09 | 259.47 | 13,77 Gbit/s |
| 1 x 100 GB-fil | 96.13 | 300.61 | 8,32 Gbit/s |
Vi kan se att en större fil, uppdelad i mindre filer, kan förbättra nedladdningsprestanda på grund av parallellitet. Vi rekommenderar att du undviker filer som blir för små (mindre än 4 MB) eftersom den tid som krävs för att skicka lagringsbegäran ökar i förhållande till den tid som ägnas åt att ladda ned nyttolasten. Mer information finns i Många problem med små filer.
Montering (direktuppspelning)
I monteringsläge använder Azure Machine Learning-datafunktionen FUNKTIONEN FUSE (filsystem i användarutrymme) Linux för att skapa ett emulerat filsystem. I stället för att ladda ned alla data till den lokala disken (SSD) för beräkningsmålet kan körningen reagera på användarens skriptåtgärder i realtid. Till exempel "open file", "read 2-KB chunk from position X", "list directory content".
| Fördelar | Nackdelar |
|---|---|
| Data som överskrider den lokala diskkapaciteten för beräkningsmål kan användas (inte begränsas av beräkningsmaskinvara) | Mer omkostnader för Linux FUSE-modulen har lagts till. |
| Ingen fördröjning i början av träningen (till skillnad från nedladdningsläge). | Beroende av användarens kodbeteende (om träningskoden som sekventiellt läser små filer i en enda trådmontering även begär data från lagring, kanske den inte maximerar nätverket eller lagringsdataflödet). |
| Fler tillgängliga inställningar för att justera ett användningsscenario. | Inget windows-stöd. |
| Endast data som behövs för träning läse från lagring. |
När montering ska användas
- Data är stora och får inte plats på den lokala disken för beräkningsmål.
- Varje enskild beräkningsnod i ett kluster behöver inte läsa hela datamängden (slumpmässig fil eller rader i csv-filval osv.).
- Fördröjningar som väntar på att alla data ska laddas ned innan träningen startar kan bli ett problem (inaktiv GPU-tid).
Tillgängliga monteringsinställningar
Du kan justera monteringsinställningarna med dessa miljövariabler i jobbet:
| Namn på env-variabel | Typ | Default value | beskrivning |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Inte inställd (cachen upphör aldrig att gälla) | Tid, i millisekunder, som krävs för att behålla anropsresultatet getattr i cacheminnet och för att undvika efterföljande begäranden om den här informationen från lagringen igen. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Avsedd för en systemkonfiguration för att hålla beräkningen felfri. Oavsett vilka värden de andra inställningarna har använder Azure Machine Learning-datakörningen inte de sista RESERVED_FREE_DISK_SPACE byteen med diskutrymme. |
DATASET_MOUNT_CACHE_SIZE |
usize | Obegränsat | Styr hur mycket diskutrymme som kan användas. Ett positivt värde anger absolut värde i byte. Negativt värde anger hur mycket diskutrymme som ska lämnas ledigt. Den här tabellen innehåller fler alternativ för diskcache. Stöder KB, MB och GB modifierare för enkelhetens skull. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Volymmonteringen startar cacherensning när cachen fylls upp till AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Bör vara mellan 0 och 1. Om du ställer in den < 1 utlöses bakgrundscacherensning tidigare. AVAILABLE_CACHE_SIZE är inte en miljövariabel som du kan ändra eller visa direkt. I det här sammanhanget refererar det till "antalet byte som systemet beräknar som tillgängligt för cachelagring". Det här värdet beror på faktorer som diskstorlek, mängden diskutrymme som krävs för systemets hälsotillstånd och konfigurationer som anges i miljövariabler (t.ex DATASET_RESERVED_FREE_DISK_SPACE . och DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Beskärningscachen försöker frigöra minst (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) ett cacheutrymme. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Läsblocksstorlek för direktuppspelning. När filen är tillräckligt stor begär du minst DATASET_MOUNT_READ_BLOCK_SIZE data från lagringen och cacheminnet även när säkringen begärde läsåtgärd för mindre. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Antal block att förinstallera (läsningsblock k utlöser bakgrundsförvalning av block k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Antal bakgrundstrådar som förinstalleras. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | falskt | Aktivera blockbaserad cachelagring. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Gäller endast för blockbaserad cachelagring. Storleken på RAM-blockbaserad cachelagring kan användas. Värdet 0 inaktiverar cachelagring av minne helt. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | true | Gäller endast för blockbaserad cachelagring. När värdet är true använder blockbaserad cachelagring den lokala hårddisken för att cachelagra block. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Gäller endast för blockbaserad cachelagring. Blockbaserad cachelagring skriver cachelagrat block till en lokal disk i en bakgrund. Den här inställningen styr hur mycket minnesmontering som kan användas för att lagra block som väntar på tömning till den lokala diskcachen. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Gäller endast för blockbaserad cachelagring. Antal blockbaserade cachelagringar i bakgrundstrådar som används för att skriva nedladdade block till den lokala disken i beräkningsmålet. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Tid i sekunder för unmount att (smidigt) slutföra alla väntande åtgärder (till exempel tömningsanrop) innan monteringsmeddelandeloopen avslutas med kraft. |
I ditt jobb kan du ändra ovanstående standardvärden genom att ange miljövariablerna, till exempel:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Blockbaserat öppet läge
Blockbaserat öppet läge delar upp varje fil i block med en fördefinierad storlek (förutom det sista blocket). En läsbegäran från en angiven position begär ett motsvarande block från lagringen och returnerar de begärda data omedelbart. En läsning utlöser också bakgrundsprefetching av N nästa block, med hjälp av flera trådar (optimerad för sekventiell läsning). Nedladdade block cachelagras i tvåskiktscachen (RAM-minne och lokal disk).
| Fördelar | Nackdelar |
|---|---|
| Snabb dataleverans till träningsskriptet (mindre blockering för segment som ännu inte har begärts). | Slumpmässiga läsningar kan slösa bort framåtriktade block. |
| Fler arbetslaster till bakgrundstrådar (förinläsning/cachelagring). Träningen kan sedan fortsätta. | Lade till omkostnader för att navigera mellan cacheminnen, jämfört med direkta läsningar från en fil på en lokal diskcache (till exempel i cacheläge för hela filer). |
| Endast begärda data (plus förinläsning) läses från lagringen. | |
| För tillräckligt små data används snabb RAM-baserad cache. |
När du ska använda blockbaserat öppet läge
Rekommenderas för de flesta scenarier förutom när du behöver snabba läsningar från slumpmässiga filplatser. I dessa fall använder du öppna läge för hela filcachen.
Öppet läge för hela filcachen
När en fil under en monteringsmapp öppnas (till exempel f = open(path, args)) i hela filläget blockeras anropet tills hela filen laddas ned till en cachemapp för beräkningsmål på disken. Alla efterföljande läsanrop omdirigeras till den cachelagrade filen, så ingen lagringsinteraktion behövs. Om cacheminnet inte har tillräckligt med ledigt utrymme för att passa den aktuella filen försöker monteringen rensa genom att ta bort den senast använda filen från cachen. Om filen inte får plats på disken (med avseende på cacheinställningar) återgår datakörningen till strömningsläge.
| Fördelar | Nackdelar |
|---|---|
| Ingen lagringstillförlitlighet/dataflödesberoenden efter att filen har öppnats. | Öppet anrop blockeras tills hela filen laddas ned. |
| Snabba slumpmässiga läsningar (läser segment från slumpmässiga platser i filen). | Hela filen läss från lagringen, även om vissa delar av filen kanske inte behövs. |
När du ska använda detta
När slumpmässiga läsningar behövs för relativt stora filer som överstiger 128 MB.
Förbrukning
Ange miljövariabel till DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED false i ditt jobb:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Montering: Visa filer
När du arbetar med miljontals filer bör du undvika en rekursiv lista – till exempel ls -R /mnt/dataset/folder/. En rekursiv lista utlöser många anrop för att visa kataloginnehållet i den överordnade katalogen. Det kräver sedan ett separat rekursivt anrop för varje katalog inuti, på alla underordnade nivåer. Vanligtvis tillåter Azure Storage att endast 5 000 element returneras per enskild listbegäran. Därför kräver 1,000,000 / 5000 + 1,000,000 = 1,000,200 en rekursiv lista över 1M-mappar som innehåller 10 filer var begäranden till lagring. Som jämförelse skulle 1 000 mappar med 10 000 filer bara behöva 1 001 begäranden till lagring för en rekursiv lista.
Azure Machine Learning-monteringen hanterar listan på ett latt sätt. Därför är det bättre att använda ett iterativt klientbiblioteksanrop (till exempel os.scandir() i Python) i stället för ett klientbiblioteksanrop som returnerar den fullständiga listan (till exempel os.listdir() i Python). Ett iterativt klientbiblioteksanrop returnerar en generator, vilket innebär att den inte behöver vänta tills hela listan läses in. Det kan sedan gå snabbare.
I den här tabellen jämförs den tid som krävs för Python os.scandir() och os.listdir() funktionerna för att visa en mapp som innehåller ~4M-filer i en platt struktur:
| Mått | os.scandir() |
os.listdir() |
|---|---|---|
| Dags att hämta första posten (sek) | 0.67 | 553.79 |
| Dags att hämta de första 50 000 posterna (sek) | 9.56 | 562.73 |
| Dags att hämta alla poster (sek) | 558.35 | 582.14 |
Optimala monteringsinställningar för vanliga scenarier
I vissa vanliga scenarier visar vi de optimala monteringsinställningar som du behöver ange i ditt Azure Machine Learning-jobb.
Läser stora filer sekventiellt en gång (bearbetningsrader i csv-fil)
Inkludera dessa monteringsinställningar i environment_variables avsnittet i ditt Azure Machine Learning-jobb:
Kommentar
Om du vill använda serverlös beräkning tar du bort compute="cpu-cluster", i den här koden.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Läsa stor fil en gång från flera trådar (bearbeta partitionerad csv-fil i flera trådar)
Inkludera dessa monteringsinställningar i environment_variables avsnittet i ditt Azure Machine Learning-jobb:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Läsa miljontals små filer (bilder) från flera trådar en gång (enkel epokträning på bilder)
Inkludera dessa monteringsinställningar i environment_variables avsnittet i ditt Azure Machine Learning-jobb:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Läsa miljontals små filer (bilder) från flera trådar flera gånger (flera epoker som tränar på bilder)
Inkludera dessa monteringsinställningar i environment_variables avsnittet i ditt Azure Machine Learning-jobb:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Läsa stor fil med slumpmässiga sökningar (som att hantera fildatabas från monterad mapp)
Inkludera dessa monteringsinställningar i environment_variables avsnittet i ditt Azure Machine Learning-jobb:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Diagnostisera och lösa flaskhalsar vid datainläsning
När ett Azure Machine Learning-jobb körs med data avgör mode indata hur byte läse från lagring och cachelagras på den lokala SSD-disken för beräkningsmål. För nedladdningsläge cachelagrar alla data på disken innan användarkoden startar körningen. Därför kan faktorer som
- antal parallella trådar
- antalet filer
- filstorlek
påverkar maximala nedladdningshastigheter. För montering måste användarkoden börja öppna filer innan data börjar cachelagrad. Olika monteringsinställningar resulterar i olika läs- och cachelagringsbeteenden. Olika faktorer påverkar den hastighet som data läses in från lagring:
- Datalokalitet för beräkning: Dina lagrings- och beräkningsmålplatser bör vara desamma. Om ditt lagrings- och beräkningsmål finns i olika regioner försämras prestandan eftersom data måste överföras mellan regioner. Mer information om hur du ser till att dina data samlokaliseras med beräkning finns i Samlokalisera data med beräkning.
- Beräkningsmålstorleken: Små beräkningar har lägre antal kärnor (mindre parallellitet) och mindre förväntad nätverksbandbredd jämfört med större beräkningsstorlekar – båda faktorerna påverkar datainläsningens prestanda.
- Om du till exempel använder en liten vm-storlek, till exempel
Standard_D2_v2(2 kärnor, 1 500 Mbit/s NIC) och försöker läsa in 50 000 MB (50 GB) data, är den bästa möjliga datainläsningstiden ~270 sekunder (förutsatt att du mättar nätverkskortet vid 187,5 MB/s dataflöde). Däremot skulle enStandard_D5_v2(16 kärnor, 12 000 Mbit/s) läsa in samma data på ~33 sekunder (förutsatt att du mättar nätverkskortet med ett dataflöde på 1 500 MB/s).
- Om du till exempel använder en liten vm-storlek, till exempel
- Lagringsnivå: För de flesta scenarier – inklusive LLM (Large Language Models) – ger standardlagring den bästa kostnads-/prestandaprofilen. Men om du har många små filer erbjuder Premium Storage en bättre kostnads-/prestandaprofil. Mer information finns i Azure Storage-alternativ.
- Lagringsbelastning: Om lagringskontot är under hög belastning – till exempel många GPU-noder i ett kluster som begär data – riskerar du att nå utgående lagringskapacitet. Mer information finns i Lagringsbelastning. Om du har många små filer som behöver åtkomst parallellt kan du nå lagringsgränserna för begäranden. Läs uppdaterad information om gränserna för både utgående kapacitet och lagringsbegäranden i Skalningsmål för standardlagringskonton.
- Dataåtkomstmönster i användarkod: När du använder monteringsläge hämtas data baserat på åtgärderna öppna/läsa i koden. När du till exempel läser slumpmässiga delar av en stor fil kan standardinställningarna för förinläsning av monteringar leda till nedladdningar av block som inte läses. Du kan behöva justera vissa inställningar för att nå maximalt dataflöde. Mer information finns i Optimala monteringsinställningar för vanliga scenarier.
Använda loggar för att diagnostisera problem
Så här kommer du åt loggarna för datakörningen från jobbet:
- Välj fliken Utdata+loggar på jobbsidan.
- Välj mappen system_logs följt av data_capability mapp.
- Du bör se två loggfiler:
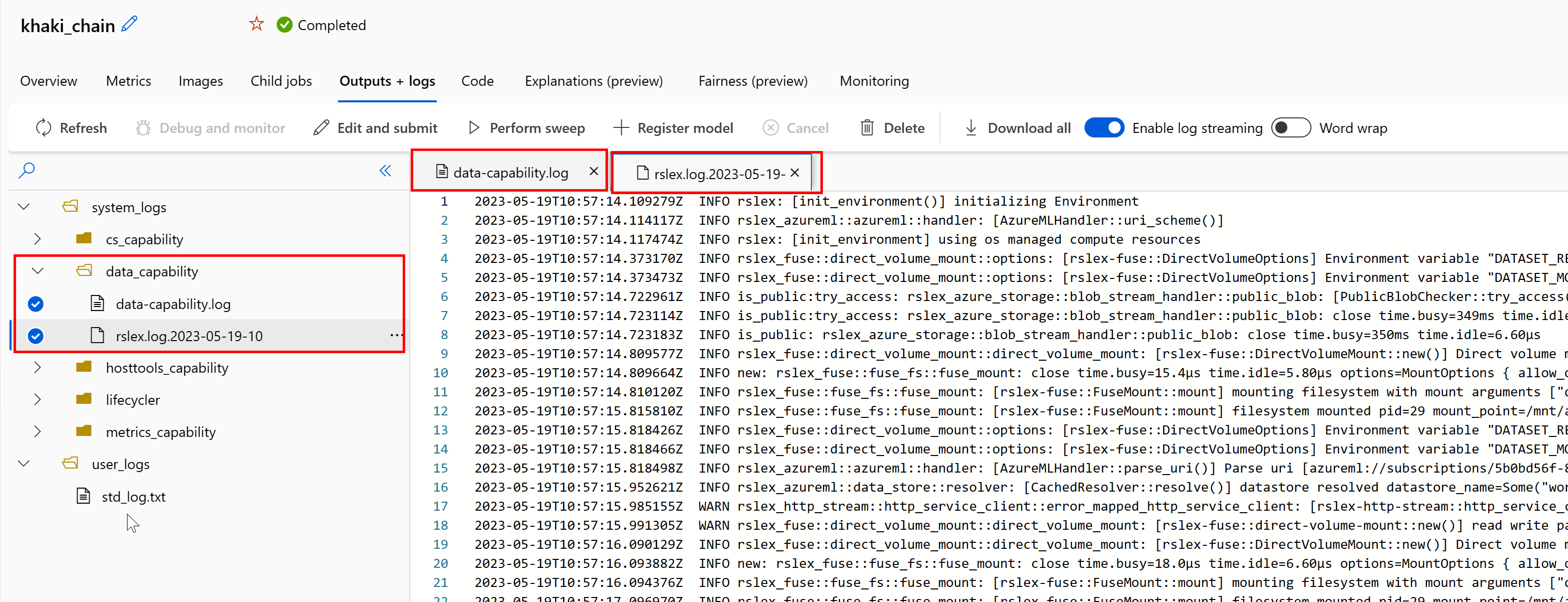

Loggfilen data-capability.log visar information på hög nivå om den tid som ägnas åt viktiga datainläsningsuppgifter. När du till exempel laddar ned data loggar körningen start- och sluttiderna för nedladdningsaktiviteten:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Om dataflödet för nedladdning är en bråkdel av den förväntade nätverksbandbredden för den virtuella datorns storlek kan du granska loggfilen rslex.log.<TIDSSTÄMPEL>. Den här filen innehåller all detaljerad loggning från den Rust-baserade körningen. Till exempel parallellisering:
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
Filen rslex.log innehåller information om all filkopiering, oavsett om du har valt monterings- eller nedladdningslägena. Den beskriver också de inställningar (miljövariabler) som används. Om du vill börja felsöka kontrollerar du om du ställer in optimala monteringsinställningar för vanliga scenarier.
Övervaka Azure Storage
I Azure Portal kan du välja ditt lagringskonto och sedan Mått för att se lagringsmåtten:

Sedan ritar du SuccessE2ELatency med SuccessServerLatency. Om måtten visar hög SuccessE2ELatency och låg SuccessServerLatency, du har begränsade tillgängliga trådar, eller om du har ont om resurser som PROCESSOR, minne eller nätverksbandbredd, bör du:
- Använd övervakningsvyn i Azure Machine Learning-studio för att kontrollera processor- och minnesanvändningen för ditt jobb. Om du har ont om cpu och minne kan du överväga att öka storleken på den virtuella datorn för beräkningsmål.
- Överväg att öka
RSLEX_DOWNLOADER_THREADSom du laddar ned och inte använder processorn och minnet. Om du använder montering bör du ökaDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTför att göra mer förinläsning och ökaDATASET_MOUNT_READ_THREADSför fler lästrådar.
Om måtten visar låg SuccessE2ELatency och låg SuccessServerLatency, men klienten har hög svarstid, har du en fördröjning i lagringsbegäran som når tjänsten. Du bör kontrollera:
- Om antalet trådar som används för montering/nedladdning (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) är för lågt, i förhållande till antalet tillgängliga kärnor i beräkningsmålet. Om inställningen är för låg ökar du antalet trådar. - Om antalet återförsök för nedladdning (
AZUREML_DATASET_HTTP_RETRY_COUNT) har angetts som för högt. I så fall minskar du antalet återförsök.
Övervaka diskanvändning under ett jobb
Från Azure Machine Learning-studio kan du även övervaka beräkningsmåldiskens I/O och användning under jobbkörningen. Gå till jobbet och välj fliken Övervakning . Den här fliken ger insikter om resurserna i ditt jobb, på löpande 30 dagar. Till exempel:

Kommentar
Jobbövervakning stöder endast beräkningsresurser som Hanteras av Azure Machine Learning. Jobb med en körning på mindre än 5 minuter har inte tillräckligt med data för att fylla i den här vyn.
Azure Machine Learning-datakörning använder inte de sista RESERVED_FREE_DISK_SPACE byteen diskutrymme för att hålla beräkningen felfri (standardvärdet är 150MB). Om disken är full skriver koden filer till disken utan att deklarera filerna som utdata. Kontrollera därför koden för att se till att data inte skrivs felaktigt till en tillfällig disk. Om du måste skriva filer till en tillfällig disk och resursen blir full bör du tänka på:
- Öka storleken på den virtuella datorn till en som har en större tillfällig disk
- Ange en TTL för cachelagrade data (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) för att rensa dina data från disken
Samlokalisera data med beräkning
Varning
Om din lagring och beräkning finns i olika regioner försämras prestandan eftersom data måste överföras mellan regioner. Detta ökar kostnaderna. Kontrollera att lagringskontot och beräkningsresurserna finns i samma region.
Om dina data och Azure Machine Learning-arbetsytan lagras i olika regioner rekommenderar vi att du kopierar data till ett lagringskonto i samma region med azcopy-verktyget . AzCopy använder API:er från server till server, så att data kopieras direkt mellan lagringsservrar. Dessa kopieringsåtgärder använder inte datorns nätverksbandbredd. Du kan öka dataflödet för dessa åtgärder med AZCOPY_CONCURRENCY_VALUE miljövariabeln. Mer information finns i Öka samtidighet.
Lagringsbelastning
Ett enda lagringskonto kan begränsas när det kommer under hög belastning, när:
- Jobbet använder många GPU-noder
- Ditt lagringskonto har många samtidiga användare/appar som kommer åt data när du kör jobbet
Det här avsnittet visar beräkningarna för att avgöra om begränsning kan bli ett problem för din arbetsbelastning och hur du närmar dig minskningar av begränsningen.
Beräkna bandbreddsgränser
Ett Azure Storage-konto har en standardgräns på 120 Gbit/s. Virtuella Azure-datorer har olika nätverksbandbredder, vilket påverkar det teoretiska antalet beräkningsnoder som krävs för att nå den maximala standardutgående kapaciteten för lagring:
| Storlek | GPU-kort | vCPU | Minne: GiB | Temporär lagring (SSD) GiB | Antal GPU-kort | GPU-minne: GiB | Förväntad nätverksbandbredd (Gbit/s) | Utgående standardvärde för lagringskonto (Gbit/s)* | Antal noder som når standardutgående kapacitet |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Både A100/V100 SKU:er har en maximal nätverksbandbredd per nod på 24 Gbit/s. Om varje nod som läser data från ett enda konto kan läsas nära det teoretiska maxvärdet på 24 Gbit/s skulle utgående kapacitet ske med fem noder. Användning av sex eller fler beräkningsnoder skulle börja försämra dataflödet över alla noder.
Viktigt!
Om din arbetsbelastning behöver fler än 6 noder av A100/V100, eller om du tror att du kommer att överskrida standardkapaciteten för utgående lagring (120 Gbit/s), kontaktar du supporten (via Azure-portalen) och begär en ökning av gränsen för utgående lagring.
Skala över flera lagringskonton
Du kan överskrida den maximala utgående lagringskapaciteten och/eller så kan du överskrida gränsen för begärandefrekvens. Om dessa problem uppstår rekommenderar vi att du kontaktar supporten först för att öka dessa gränser för lagringskontot.
Om du inte kan öka den maximala utgående kapaciteten eller gränsen för begärandefrekvens bör du överväga att replikera data mellan flera lagringskonton. Kopiera data till flera konton med Azure Data Factory, Azure Storage Explorer eller azcopyoch montera alla konton i ditt träningsjobb. Endast data som nås på en montering laddas ned. Därför kan träningskoden läsa RANK från miljövariabeln för att välja vilken av de flera indatamonteringarna som ska läsas från. Jobbdefinitionen skickas i en lista över lagringskonton:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Python-koden för träning kan sedan användas RANK för att få lagringskontot specifikt för den noden:
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Många problem med små filer
Att läsa filer från lagring handlar om att göra begäranden för varje fil. Antalet begäranden per fil varierar beroende på filstorlekar och inställningarna för programvaran som hanterar filläsningarna.
Filer läses vanligtvis i block med storlek 1–4 MB. Filer som är mindre än ett block läses med en enda begäran (GET file.jpg 0–4 MB) och filer som är större än ett block har en begäran per block (GET file.jpg 0–4 MB, GET file.jpg 4–8 MB). Den här tabellen visar att filer som är mindre än ett block på 4 MB resulterar i fler lagringsbegäranden jämfört med större filer:
| # Filer | Filstorlek | Total datastorlek | Blockstorlek | # Lagringsbegäranden |
|---|---|---|---|---|
| 2,000,000 | 500 KB | 1 TB | 4 MB | 2,000,000 |
| 1 000 | 1 GB | 1 TB | 4 MB | 256,000 |
För små filer handlar svarstidsintervallet främst om att hantera begäranden till lagring i stället för dataöverföringar. Därför erbjuder vi dessa rekommendationer för att öka filstorleken:
- För ostrukturerade data (bilder, text, video osv.) arkiverar du små filer (zip/tar) för att lagra dem som en större fil som kan läsas i flera segment. Dessa större arkiverade filer kan öppnas i beräkningsresursen och PyTorch Archive DataPipes kan extrahera de mindre filerna.
- För strukturerade data (CSV, parquet osv.) undersöker du ETL-processen för att se till att den samlar filer för att öka storleken. Spark har
repartition()ochcoalesce()metoder för att öka filstorlekarna.
Om du inte kan öka filstorlekarna kan du utforska dina Azure Storage-alternativ.
Azure Storage-alternativ
Azure Storage erbjuder två nivåer – standard och premium:
| Storage | Scenario |
|---|---|
| Azure Blob – Standard (HDD) | Dina data är strukturerade i större blobar – bilder, video osv. |
| Azure Blob – Premium (SSD) | Höga transaktionshastigheter, mindre objekt eller konsekvent låga lagringsfördröjningskrav |
Dricks
För "många" små filer (KB-storlek) rekommenderar vi användning av Premium (SSD) eftersom kostnaden för lagring är mindre än kostnaderna för att köra GPU-beräkning.
Läsa V1-datatillgångar
I det här avsnittet beskrivs hur du läser V1 FileDataset - och TabularDataset dataentiteter i ett V2-jobb.
Läsa en FileDataset
I - Input objektet anger du type som AssetTypes.MLTABLE och mode som InputOutputModes.EVAL_MOUNT:
Kommentar
Om du vill använda serverlös beräkning tar du bort compute="cpu-cluster", i den här koden.
Mer information om MLClient-objektet, initieringsalternativ för MLClient-objekt och hur du ansluter till en arbetsyta finns i Anslut till en arbetsyta.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Läsa en TabularDataset
I objektet Input anger du type som AssetTypes.MLTABLE, och mode som InputOutputModes.DIRECT:
Kommentar
Om du vill använda serverlös beräkning tar du bort compute="cpu-cluster", i den här koden.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint