Så här använder du grundmodeller med öppen källkod som har kurerats av Azure Machine Learning
I den här artikeln får du lära dig hur du finjusterar, utvärderar och distribuerar grundmodeller i modellkatalogen.
Du kan snabbt testa valfri förtränad modell med hjälp av exempelinferensformuläret på modellkortet, vilket ger dina egna exempelindata för att testa resultatet. Dessutom innehåller modellkortet för varje modell en kort beskrivning av modellen och länkar till exempel för kodbaserad slutsatsdragning, finjustering och utvärdering av modellen.
Så här utvärderar du grundmodeller med hjälp av dina egna testdata
Du kan utvärdera en foundation-modell mot din testdatauppsättning, antingen med hjälp av formuläret Utvärdera användargränssnitt eller med hjälp av kodbaserade exempel som är länkade från modellkortet.
Utvärdera med hjälp av studio
Du kan anropa formuläret Utvärdera modell genom att välja knappen Utvärdera på modellkortet för valfri grundmodell.
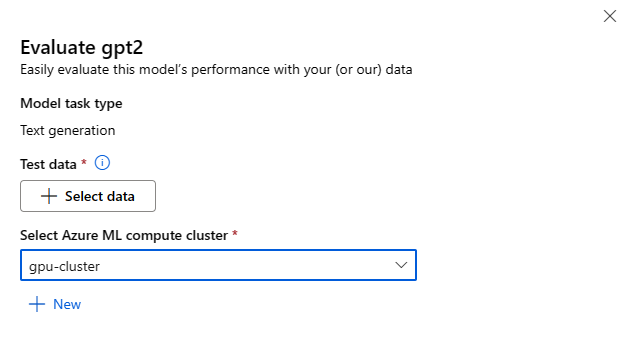
Varje modell kan utvärderas för den specifika slutsatsdragningsuppgift som modellen ska användas för.
Testdata:
- Skicka in de testdata som du vill använda för att utvärdera din modell. Du kan välja att antingen ladda upp en lokal fil (i JSONL-format) eller välja en befintlig registrerad datauppsättning från din arbetsyta.
- När du har valt datauppsättningen måste du mappa kolumnerna från dina indata baserat på det schema som krävs för uppgiften. Mappa till exempel kolumnnamnen som motsvarar nycklarna "mening" och "etikett" för textklassificering

Compute:
Ange det Azure Machine Learning Compute-kluster som du vill använda för att finjustera modellen. Utvärderingen måste köras på GPU-beräkning. Se till att du har tillräcklig beräkningskvot för de beräknings-SKU:er som du vill använda.
Välj Slutför i formuläret Utvärdera för att skicka utvärderingsjobbet. När jobbet är klart kan du visa utvärderingsmått för modellen. Baserat på utvärderingsmåtten kan du bestämma om du vill finjustera modellen med dina egna träningsdata. Dessutom kan du bestämma om du vill registrera modellen och distribuera den till en slutpunkt.
Utvärdera med hjälp av kodbaserade exempel
För att göra det möjligt för användare att komma igång med modellutvärdering har vi publicerat exempel (både Python-notebook-filer och CLI-exempel) iutvärderingsexempel i azureml-examples. Varje modellkort länkar också till utvärderingsexempel för motsvarande uppgifter
Finjustera grundmodeller med hjälp av dina egna träningsdata
Om du vill förbättra modellprestandan i din arbetsbelastning kanske du vill finjustera en grundmodell med dina egna träningsdata. Du kan enkelt finjustera dessa grundmodeller genom att antingen finjustera inställningarna i studion eller med hjälp av kodbaserade exempel som är länkade från modellkortet.
Finjustera med studio
Du kan anropa formuläret för finjustera inställningar genom att välja knappen Finjustera på modellkortet för valfri grundmodell.
Finjustera inställningar:
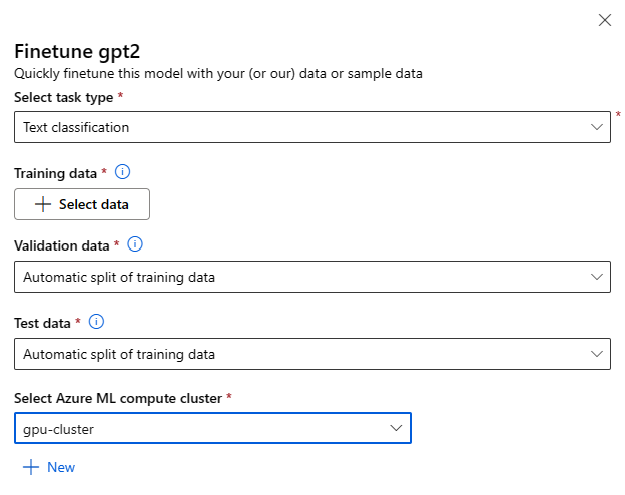
Finjustering av aktivitetstyp
- Varje förtränad modell från modellkatalogen kan finjusteras för en specifik uppsättning uppgifter (till exempel textklassificering, tokenklassificering, frågesvar). Välj den uppgift som du vill använda i listrutan.
Träningsdata
Skicka in de träningsdata som du vill använda för att finjustera din modell. Du kan välja att antingen ladda upp en lokal fil (i JSONL-, CSV- eller TSV-format) eller välja en befintlig registrerad datauppsättning från din arbetsyta.
När du har valt datauppsättningen måste du mappa kolumnerna från dina indata baserat på det schema som krävs för uppgiften. Till exempel: mappa kolumnnamnen som motsvarar nycklarna "mening" och "etikett" för textklassificering

- Valideringsdata: Skicka in de data som du vill använda för att verifiera din modell. Om du väljer Automatisk delning reserveras en automatisk uppdelning av träningsdata för validering. Du kan också ange en annan valideringsdatauppsättning.
- Testdata: Skicka in de testdata som du vill använda för att utvärdera din finjusterade modell. Om du väljer Automatisk delning reserveras en automatisk uppdelning av träningsdata för testning.
- Beräkning: Ange det Azure Machine Learning Compute-kluster som du vill använda för att finjustera modellen. Finjustering måste köras på GPU-beräkning. Vi rekommenderar att du använder beräknings-SKU:er med A100/V100 GPU:er vid finjustering. Se till att du har tillräcklig beräkningskvot för de beräknings-SKU:er som du vill använda.
- Välj Slutför i finjusteringsformuläret för att skicka ditt finjusteringsjobb. När jobbet är klart kan du visa utvärderingsmått för den finjusterade modellen. Du kan sedan registrera de finjusterade modellutdata från finjusteringsjobbet och distribuera den här modellen till en slutpunkt för slutsatsdragning.
Finjustera med hjälp av kodbaserade exempel
För närvarande har Azure Machine Learning stöd för finjusteringsmodeller för följande språkuppgifter:
- Textklassificering
- Tokenklassificering
- Frågor och svar
- Summering
- Översättning
För att göra det möjligt för användare att snabbt komma igång med finjustering har vi publicerat exempel (både Python-notebook-filer och CLI-exempel) för varje uppgift i git-lagringsplatsen Azureml-examples Finetune-exempel. Varje modellkort länkar också till finjusteringsexempel för finjusterande uppgifter som stöds.
Distribuera grundmodeller till slutpunkter för slutsatsdragning
Du kan distribuera grundmodeller (både förtränade modeller från modellkatalogen och finjusterade modeller när de har registrerats på din arbetsyta) till en slutpunkt som sedan kan användas för slutsatsdragning. Distribution till både serverlösa API:er och hanterad beräkning stöds. Du kan distribuera dessa modeller med hjälp av guiden Distribuera användargränssnitt eller med hjälp av kodbaserade exempel som är länkade från modellkortet.
Distribuera med studio
Du kan anropa formuläret Distribuera användargränssnitt genom att välja knappen Distribuera på modellkortet för valfri grundmodell och välja antingen Serverlöst API med Azure AI Content Safety eller Hanterad beräkning utan Azure AI Content Safety

Distributionsinställningar
Eftersom bedömningsskriptet och miljön automatiskt ingår i grundmodellen behöver du bara ange den SKU för virtuell dator som ska användas, antalet instanser och slutpunktsnamnet som ska användas för distributionen.
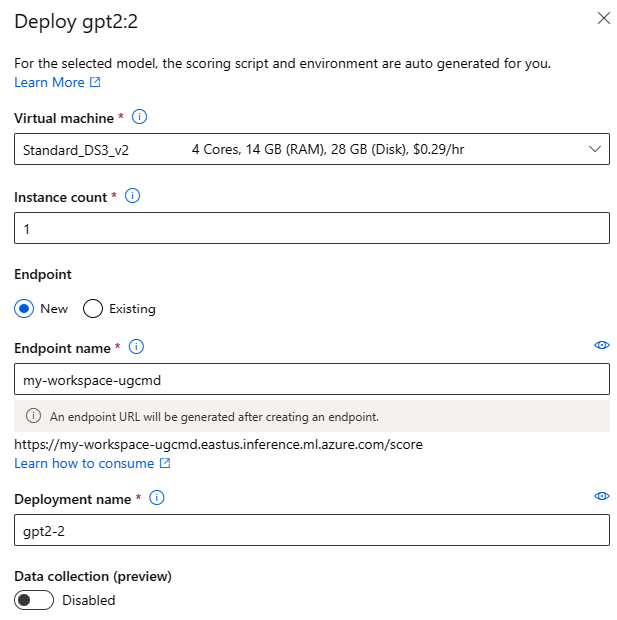
Delad kvot
Om du distribuerar en Llama-2-, Phi-, Nemotron-, Mistral-, Dolly- eller Deci-DeciLM-modell från modellkatalogen men inte har tillräckligt med kvot för distributionen kan du använda kvoter från en delad kvotpool under en begränsad tid. Mer information om delade kvot finns i Delade kvoter för Azure Machine Learning.

Distribuera med kodbaserade exempel
För att göra det möjligt för användare att snabbt komma igång med distribution och slutsatsdragning har vi publicerat exempel i inferensexemplen på git-lagringsplatsen azureml-examples. De publicerade exemplen innehåller Python-notebook-filer och CLI-exempel. Varje modellkort länkar också till slutsatsdragningsexempel för realtids- och Batch-slutsatsdragning.
Importera grundmodeller
Om du vill använda en modell med öppen källkod som inte ingår i modellkatalogen kan du importera modellen från Hugging Face till din Azure Machine Learning-arbetsyta. Hugging Face är ett bibliotek med öppen källkod för bearbetning av språkteknologi (NLP) som tillhandahåller förtränade modeller för populära NLP-uppgifter. För närvarande har modellimport stöd för import av modeller för följande uppgifter, så länge modellen uppfyller kraven som anges i modellimport-notbooken:
- fyllningsmask
- tokenklassificering
- frågesvar
- summering
- textgenerering
- textklassificering
- översättning
- bildklassificering
- text till bild
Kommentar
Modeller från Hugging Face omfattas av licensvillkor från tredje part som är tillgängliga på sidan Hugging Face-modellinformation. Det är ditt ansvar att följa modellens licensvillkor.
Du kan välja knappen Importera längst upp till höger i modellkatalogen för att använda modellimportanteckningsboken.
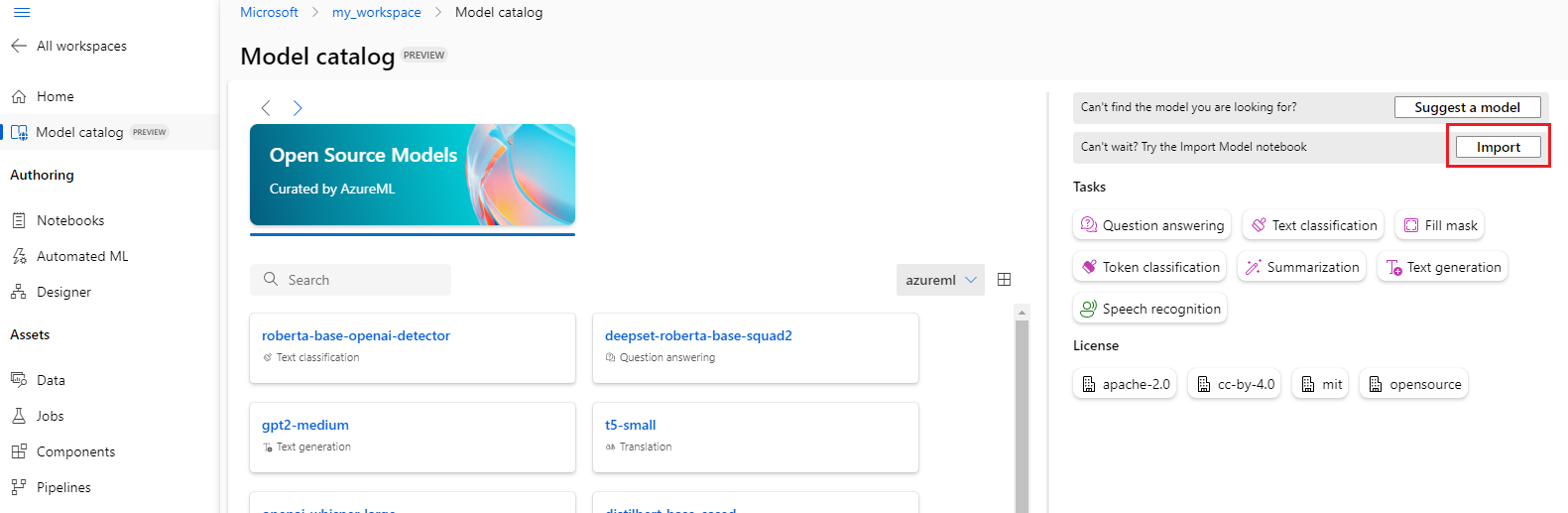
Notebook-filen för modellimport ingår också i git-lagringsplatsen azureml-examples här.
För att kunna importera modellen måste du skicka in den MODEL_ID modell som du vill importera från Hugging Face. Bläddra bland modeller på Hugging Face Hub och identifiera modellen som ska importeras. Kontrollera att modellens aktivitetstyp finns bland de aktivitetstyper som stöds. Kopiera modell-ID:t, som är tillgängligt i sidans URI eller kan kopieras med kopieringsikonen bredvid modellnamnet. Tilldela den till variabeln "MODEL_ID" i notebook-filen för modellimport. Till exempel:
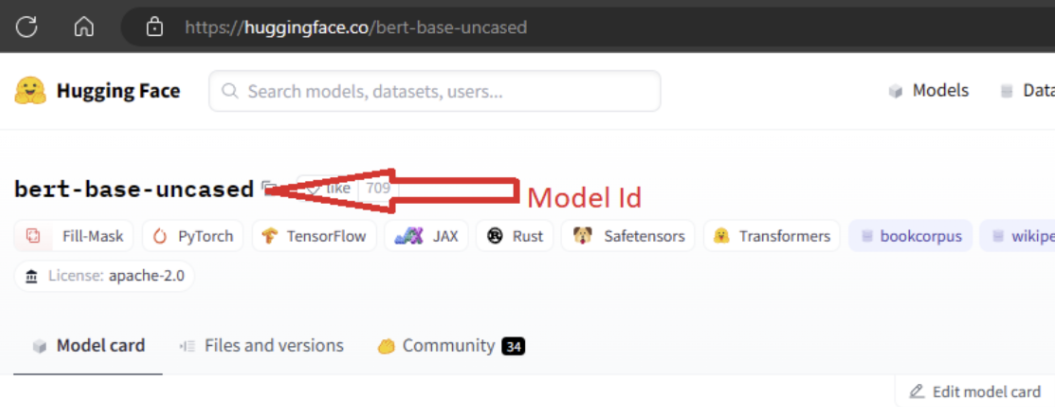
Du måste ange beräkning för att modellimporten ska köras. Om du kör modellimporten importeras den angivna modellen från Hugging Face och registreras på din Azure Machine Learning-arbetsyta. Du kan sedan finjustera den här modellen eller distribuera den till en slutpunkt för slutsatsdragning.
Läs mer
- Utforska modellkatalogen i Azure Machine Learning-studio. Du behöver en Azure Machine Learning-arbetsyta för att utforska katalogen.
- Utforska modellkatalogen och samlingar