Hantera och öka kvoter och gränser för resurser med Azure Machine Learning
Azure använder kvoter och gränser för att förhindra budgetöverskridanden på grund av bedrägerier och för att uppfylla Begränsningar för Azure-kapacitet. Överväg dessa begränsningar när du skalar för produktionsarbetsbelastningar. I den här artikeln lär du dig mer om:
- Standardgränser för Azure-resurser som är relaterade till Azure Machine Learning.
- Skapa kvoter på arbetsytenivå.
- Visa dina kvoter och gränser.
- Begär kvotökningar.
Tillsammans med att hantera kvoter och gränser kan du lära dig hur du planerar och hanterar kostnader för Azure Machine Learning eller lär dig mer om tjänstgränserna i Azure Machine Learning.
Särskilda beaktanden
Kvoter tillämpas på varje prenumeration i ditt konto. Om du har flera prenumerationer måste du begära en kvotökning för varje prenumeration.
En kvot är en kreditgräns för Azure-resurser, inte en kapacitetsgaranti. Om du behöver mycket kapacitet kan du kontakta Azure-supporten för att öka kvoten.
Kvoten delas mellan alla tjänster i dina prenumerationer, inklusive Azure Machine Learning. Beräkna användningen för alla tjänster när du utvärderar kapacitet.
Kommentar
Azure Machine Learning-beräkning är ett undantag. Den har en kvot som är separat från kärnkvoten för beräkning.
Standardgränserna varierar beroende på typ av erbjudandekategori, till exempel kostnadsfri utvärderingsversion, serie med betala per användning och virtuell dator (VM) (till exempel Dv2, F och G).
Standardresurskvoter och -gränser
I det här avsnittet får du lära dig mer om standardkvoter och högsta kvoter och gränser för följande resurser:
- Azure Machine Learning-tillgångar
- Azure Machine Learning-beräkningar (inklusive serverlös Spark)
- Delad kvot för Azure Machine Learning
- Azure Machine Learning-slutpunkter online (både hanterade och Kubernetes) och batchslutpunkter
- Azure Machine Learning-pipelines
- Azure Machine Learning-integrering med Synapse
- Virtuella datorer
- Azure Container Instances
- Azure Storage
Viktigt!
Gränser kan komma att ändras. Den senaste informationen finns i Tjänstbegränsningar i Azure Machine Learning.
Azure Machine Learning-tillgångar
Följande begränsningar för tillgångar gäller per arbetsyta .
| Resurs | Övre gräns |
|---|---|
| Datauppsättningar | 10 miljoner |
| Körningar | 10 miljoner |
| Modeller | 10 miljoner |
| Komponent | 10 miljoner |
| Artifacts | 10 miljoner |
Dessutom är den maximala körningstiden 30 dagar och det maximala antalet mått som loggas per körning är 1 miljon.
Azure Machine Learning-beräkning
Azure Machine Learning Compute har en standardkvotgräns för både antalet kärnor och antalet unika beräkningsresurser som tillåts per region i en prenumeration.
Kommentar
- Kvoten för antalet kärnor delas upp av varje VM-familj och kumulativa totala kärnor.
- Kvoten för antalet unika beräkningsresurser per region är separat från den virtuella datorns kärnkvot, eftersom den endast gäller för de hanterade beräkningsresurserna i Azure Machine Learning.
Om du vill höja gränserna för följande objekt begär du en kvotökning:
- Kärnkvoter för vm-familjen. Mer information om vilken VM-familj du vill begära en kvotökning för finns i storlekar för virtuella datorer i Azure. Till exempel börjar GPU VM-familjer med ett "N" i sitt familjenamn (till exempel NCv3-serien).
- Totalt antal kärnkvoter för prenumeration
- Klusterkvot
- Andra resurser i det här avsnittet
Tillgängliga resurser:
Dedikerade kärnor per region har en standardgräns på 24 till 300, beroende på vilken typ av prenumerationserbjudande du har. Du kan öka antalet dedikerade kärnor per prenumeration för varje VM-familj. Specialiserade VM-familjer som NCv2, NCv3 eller ND-serien börjar med ett standardvärde på noll kärnor. Även GPU:er har som standard noll kärnor.
Lågprioritetskärnor per region har en standardgräns på 100 till 3 000, beroende på vilken typ av prenumerationserbjudande du har. Antalet lågprioritetskärnor per prenumeration kan ökas och är ett enskilt värde för VM-familjer.
Den totala beräkningsgränsen per region har en standardgräns på 500 per region inom en viss prenumeration och kan ökas till ett maximalt värde på 2 500 per region. Den här gränsen delas mellan träningskluster, beräkningsinstanser och hanterade online-slutpunktsdistributioner. En beräkningsinstans anses vara ett kluster med en nod i kvotsyfte.
I följande tabell visas fler gränser på plattformen. Kontakta Produktteamet för Azure Machine Learning via en teknisk supportbegäran för att begära ett undantag.
| Resurs eller åtgärd | Övre gräns |
|---|---|
| Arbetsytor per resursgrupp | 800 |
| Noder i ett enda Azure Machine Learning-beräkningskluster (AmlCompute) som konfigurerats som en icke-kommunikationsaktiverad pool (det vill: kan inte köra MPI-jobb) | 100 noder men kan konfigureras upp till 65 000 noder |
| Noder i ett enda parallellt körningssteg körs på ett Azure Machine Learning-beräkningskluster (AmlCompute) | 100 noder men kan konfigureras upp till 65 000 noder om klustret har konfigurerats för skalning som nämnts tidigare |
| Noder i ett enda Azure Machine Learning-beräkningskluster (AmlCompute) som konfigurerats som en kommunikationsaktiverad pool | 300 noder men kan konfigureras upp till 4 000 noder |
| Noder i ett enda Azure Machine Learning-beräkningskluster (AmlCompute) som konfigurerats som en kommunikationsaktiverad pool i en RDMA-aktiverad VM-familj | 100 noder |
| Noder i en enda MPI-körning i ett Azure Machine Learning-beräkningskluster (AmlCompute) | 100 noder |
| Jobblivslängd | 21 dagar1 |
| Jobblivslängd på en nod med låg prioritet | 7 dagar2 |
| Parameterservrar per nod | 1 |
1 Maximal livslängd är varaktigheten mellan när ett jobb startar och när det har slutförts. Slutförda jobb behålls på obestämd tid. Data för jobb som inte har slutförts inom den maximala livslängden är inte tillgängliga.
2 Jobb på en nod med låg prioritet kan föregripas när det finns en kapacitetsbegränsning. Vi rekommenderar att du implementerar kontrollpunkter i ditt jobb.
Delad kvot för Azure Machine Learning
Azure Machine Learning tillhandahåller en delad kvotpool från vilken användare i olika regioner kan komma åt kvoten för att utföra testning under en begränsad tid, beroende på tillgänglighet. Den specifika tidsperioden beror på användningsfallet. Genom att tillfälligt använda kvoten från kvotpoolen behöver du inte längre skicka in ett supportärende för en kortsiktig kvotökning eller vänta tills din kvotbegäran har godkänts innan du kan fortsätta med din arbetsbelastning.
Användning av den delade kvotpoolen är tillgänglig för att köra Spark-jobb och för testning av slutsatsdragning för Llama-2-, Phi-, Nemotron-, Mistral-, Dolly- och Deci-DeciLM-modeller från modellkatalogen under en kort tid. Innan du kan distribuera dessa modeller via den delade kvoten måste du ha en företagsavtal prenumeration. Mer information om hur du använder den delade kvoten för distribution av onlineslutpunkter finns i Distribuera grundmodeller med hjälp av studion.
Du bör endast använda den delade kvoten för att skapa tillfälliga testslutpunkter, inte produktionsslutpunkter. För slutpunkter i produktion bör du begära dedikerad kvot genom att skicka in ett supportärende. Fakturering för delad kvot är användningsbaserad, precis som fakturering för dedikerade virtuella datorfamiljer. Om du vill välja bort delad kvot för Spark-jobb fyller du i avanmälningsformuläret för delad kapacitet i Azure Machine Learning.
Azure Machine Learning-slutpunkter och batchslutpunkter online
Azure Machine Learning-slutpunkter och batchslutpunkter har resursgränser som beskrivs i följande tabell.
Viktigt!
Dessa gränser är regionala, vilket innebär att du kan använda upp till dessa gränser per region som du använder. Om din aktuella gräns för antalet slutpunkter per prenumeration till exempel är 100 kan du skapa 100 slutpunkter i regionen USA, östra, 100 slutpunkter i regionen USA, västra och 100 slutpunkter i var och en av de andra regioner som stöds i en enda prenumeration. Samma princip gäller för alla andra gränser.
Om du vill fastställa den aktuella användningen för en slutpunkt kan du visa måtten.
Om du vill begära ett undantag från Azure Machine Learning-produktteamet använder du stegen i ökningarna av slutpunktsgränsen.
| Resurs | Gräns 1 | Tillåter undantag | Gäller för |
|---|---|---|---|
| Slutpunktnamn | Slutpunktsnamn måste |
- | Alla typer av slutpunkter 3 |
| Distributionsnamnet | Distributionsnamn måste |
- | Alla typer av slutpunkter 3 |
| Antal slutpunkter per prenumeration | 100 | Ja | Alla typer av slutpunkter 3 |
| Antal slutpunkter per kluster | 60 | - | Kubernetes onlineslutpunkt |
| Antal distributioner per prenumeration | 500 | Ja | Alla typer av slutpunkter 3 |
| Antal distributioner per slutpunkt | 20 | Ja | Alla typer av slutpunkter 3 |
| Antal distributioner per kluster | 100 | - | Kubernetes onlineslutpunkt |
| Antal instanser per distribution | 50 4 | Ja | Hanterad onlineslutpunkt |
| Maximal tidsgräns för begäranden på slutpunktsnivå | 180 sekunder | - | Hanterad onlineslutpunkt |
| Maximal tidsgräns för begäranden på slutpunktsnivå | 300 sekunder | - | Kubernetes onlineslutpunkt |
| Totalt antal begäranden per sekund på slutpunktsnivå för alla distributioner | 500 5 | Ja | Hanterad onlineslutpunkt |
| Totalt antal anslutningar per sekund på slutpunktsnivå för alla distributioner | 500 5 | Ja | Hanterad onlineslutpunkt |
| Totalt antal anslutningar aktiva på slutpunktsnivå för alla distributioner | 500 5 | Ja | Hanterad onlineslutpunkt |
| Total bandbredd på slutpunktsnivå för alla distributioner | 5 MBPS 5 | Ja | Hanterad onlineslutpunkt |
1 Detta är en regional gräns. Om den aktuella gränsen för antalet slutpunkter till exempel är 100 kan du skapa 100 slutpunkter i regionen USA, östra, 100 slutpunkter i regionen USA, västra och 100 slutpunkter i var och en av de andra regioner som stöds i en enda prenumeration. Samma princip gäller för alla andra gränser.
2 Enkla bindestreck som , my-endpoint-nameaccepteras i slutpunkts- och distributionsnamn.
3 slutpunkter och distributioner kan vara av olika typer, men gränser gäller för summan av alla typer. Till exempel får summan av hanterade onlineslutpunkter, Kubernetes onlineslutpunkt och batchslutpunkt under varje prenumeration inte överstiga 100 per region som standard. På samma sätt kan summan av hanterade onlinedistributioner, Kubernetes onlinedistributioner och batchdistributioner under varje prenumeration inte överstiga 500 per region som standard.
4 Vi reserverar 20 % extra beräkningsresurser för att utföra uppgraderingar. Om du till exempel begär 10 instanser i en distribution måste du ha en kvot på 12. Annars får du ett fel. Det finns vissa VM-SKU:er som är undantagna från extra kvot. Mer information om kvotallokering finns i kvotallokering för virtuella datorer för distribution.
5 begäranden per sekund, anslutningar, bandbredd osv. är relaterade. Om du begär att öka någon av dessa gränser ska du se till att du beräknar/beräknar andra relaterade gränser tillsammans.
Kvotallokering för virtuell dator för distribution
För hanterade onlineslutpunkter reserverar Azure Machine Learning 20 % av dina beräkningsresurser för att utföra uppgraderingar på vissa VM-SKU:er. Om du begär ett visst antal instanser för de virtuella dator-SKU:erna i en distribution måste du ha en kvot för tillgänglig för ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU att undvika ett fel. Om du till exempel begär 10 instanser av en Standard_DS3_v2 virtuell dator (som levereras med fyra kärnor) i en distribution bör du ha en kvot för 48 kärnor (12 instances * 4 cores) tillgänglig. Den här extra kvoten är reserverad för systeminitierade åtgärder, till exempel OS-uppgraderingar och återställning av virtuella datorer, och den medför inte kostnader om inte sådana åtgärder körs.
Det finns vissa VM-SKU:er som är undantagna från extra kvotreservation. Om du vill visa den fullständiga listan kan du läsa SKU-listan hanterade onlineslutpunkter. Information om hur du visar ökningar av användnings- och begärandekvoter finns i Visa din användning och dina kvoter i Azure Portal. Information om hur du visar kostnaden för att köra en hanterad onlineslutpunkt finns i Visa kostnader för en hanterad onlineslutpunkt.
Azure Machine Learning-pipelines
Azure Machine Learning-pipelines har följande gränser.
| Resurs | Gräns |
|---|---|
| Steg i en pipeline | 30,000 |
| Arbetsytor per resursgrupp | 800 |
Azure Machine Learning-integrering med Synapse
Azure Machine Learning serverlös Spark ger enkel åtkomst till distribuerad databehandlingsfunktion för skalning av Apache Spark-jobb. Serverlös Spark använder samma dedikerade kvot som Azure Machine Learning Compute. Kvotgränser kan ökas genom att skicka ett supportärende och begära kvot- och gränsökning för ESv3-serien under kategorin "Machine Learning Service: Virtual Machine Quota".
Om du vill visa kvotanvändningen går du till Machine Learning Studio och väljer det prenumerationsnamn som du vill se användning för. Välj "Kvot" i den vänstra panelen.

Virtuella datorer
Varje Azure-prenumeration har en gräns för antalet virtuella datorer i alla tjänster. Virtuella datorkärnor har en regional total gräns och en regional gräns per storleksserie. Båda gränserna tillämpas separat.
Anta till exempel att en prenumeration i regionen USA, östra har en gräns för totalt antal VM-kärnor på 30, en gräns för antal kärnor i A-serien på 30 och en gräns för antal kärnor i D-serien på 30. Den här prenumerationen skulle tillåtas distribuera 30 virtuella A1-datorer eller 30 virtuella D1-datorer, eller en kombination av de två som inte överstiger totalt 30 kärnor.
Du kan inte höja gränserna för virtuella datorer över de värden som visas i följande tabell.
| Resurs | Gräns |
|---|---|
| Azure-prenumerationer som är associerade med en Microsoft Entra-klientorganisation | Obegränsat |
| Coadministratorer per prenumeration | Obegränsat |
| Resursgrupper per prenumeration | 980 |
| Storlek på Azure Resource Manager API-begäran | 4 194 304 byte |
| Taggar per prenumeration1 | 50 |
| Unika taggberäkningar per prenumeration2 | 80 000 |
| Distributioner på prenumerationsnivå per plats | 8003 |
| Platser för distributioner på prenumerationsnivå | 10 |
1Du kan tillämpa upp till 50 taggar direkt på en prenumeration. I prenumerationen är varje resurs eller resursgrupp också begränsad till 50 taggar. Prenumerationen kan dock innehålla ett obegränsat antal taggar som är spridda över resurser och resursgrupper.
2Resource Manager returnerar en lista med taggnamn och värden i prenumerationen endast när antalet unika taggar är 80 000 eller mindre. En unik tagg definieras av kombinationen av resurs-ID, taggnamn och taggvärde. Till exempel beräknas två resurser med samma taggnamn och värde som två unika taggar. Du kan fortfarande hitta en resurs efter tagg när antalet överskrider 80 000.
3Distributioner tas automatiskt bort från historiken när du närmar dig gränsen. Mer information finns i Automatiska borttagningar från distributionshistoriken.
Container Instances
Mer information finns i Begränsningar för containerinstanser.
Storage
Azure Storage har en gräns på 250 lagringskonton per region, per prenumeration. Den här gränsen omfattar både Standard- och Premium-lagringskonton.
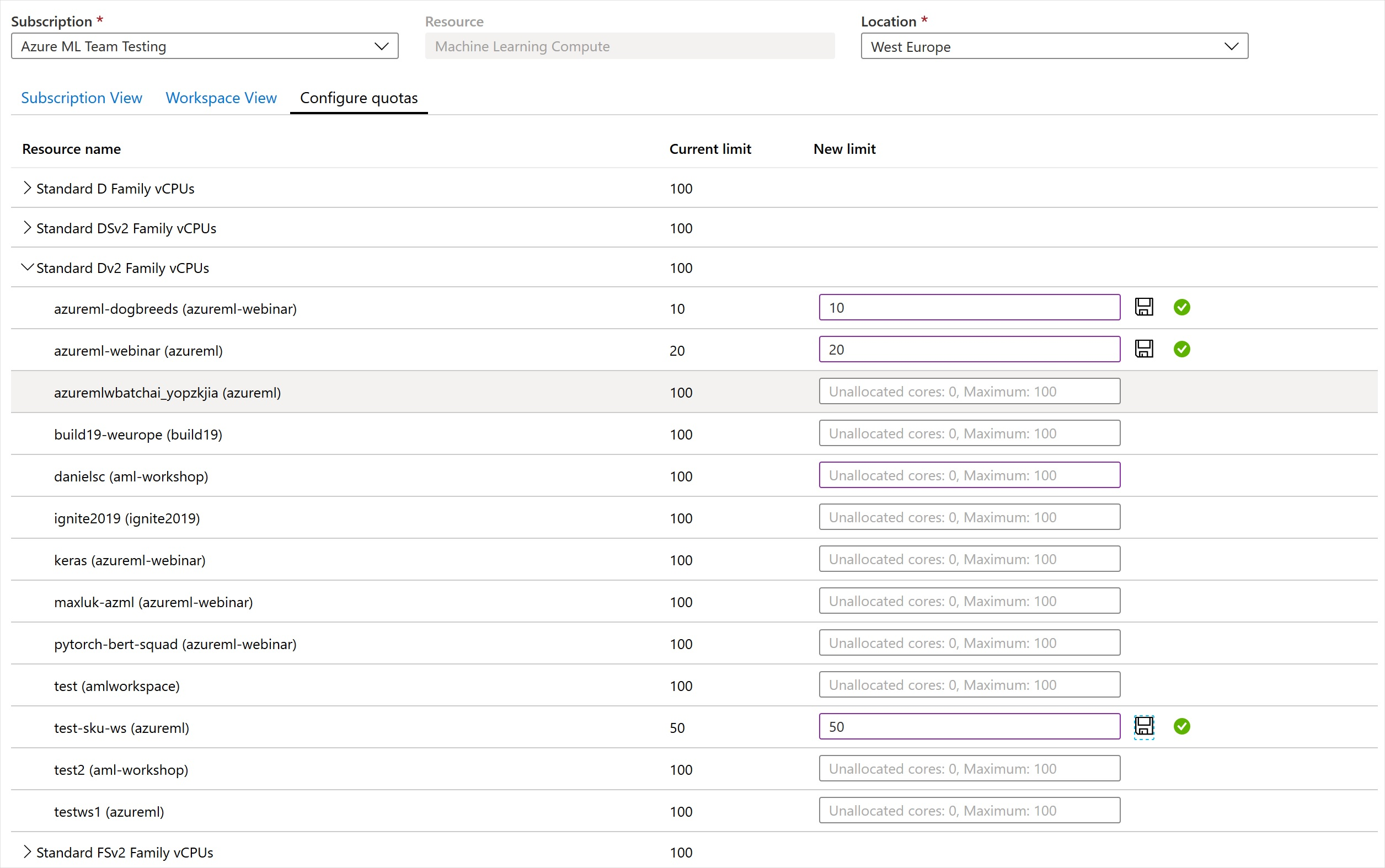
Kvoter på arbetsyta
Använd arbetsytornas nivåkvoter för att hantera Azure Machine Learning-beräkningsmålallokering mellan flera arbetsytor i samma prenumeration.
Som standard delar alla arbetsytor samma kvot som kvoten på prenumerationsnivå för VM-familjer. Men du kan ange en högsta kvot för enskilda VM-familjer för arbetsytor i en prenumeration. Med kvoter för enskilda VM-familjer kan du dela kapacitet och undvika problem med resurskonkurrering.
- Gå till valfri arbetsyta i din prenumeration.
- I det vänstra fönstret väljer du Användning och kvoter.
- Välj fliken Konfigurera kvoter för att visa kvoterna.
- Expandera en VM-familj.
- Ange en kvotgräns för alla arbetsytor som visas under VM-familjen.
Du kan inte ange ett negativt värde eller ett värde som är högre än kvoten på prenumerationsnivå.
Kommentar
Du behöver behörigheter på prenumerationsnivå för att ange en kvot på arbetsytans nivå.
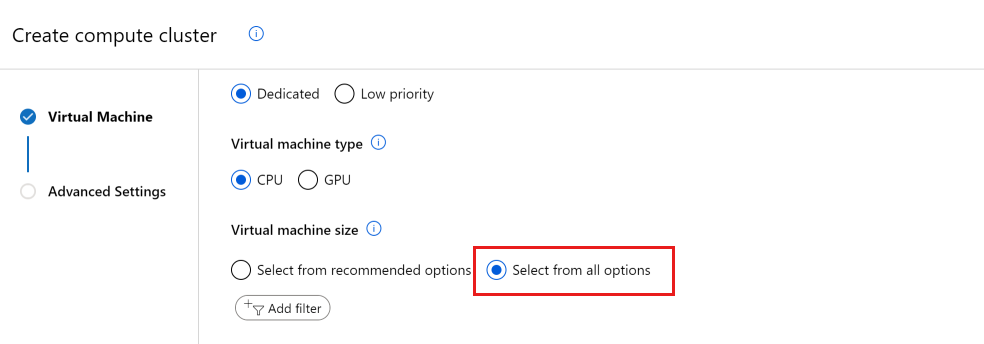
Visa kvoter i studion
När du skapar en ny beräkningsresurs ser du som standard endast VM-storlekar som du redan har kvot att använda. Växla vyn till Välj bland alla alternativ.
Rulla nedåt tills du ser listan över VM-storlekar som du inte har kvot för.
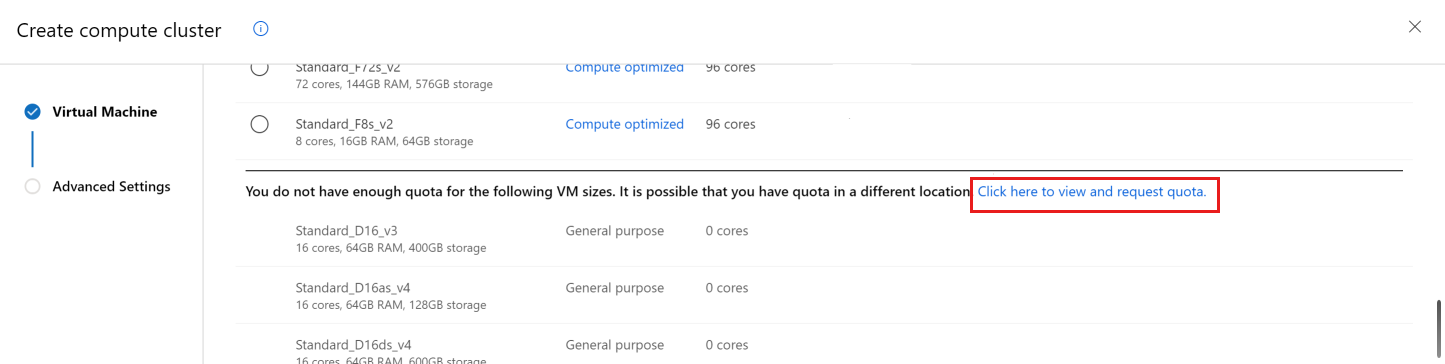
Använd länken för att gå direkt till kundsupportbegäran online för mer kvot.
Visa din användning och dina kvoter i Azure Portal
Om du vill visa din kvot för olika Azure-resurser som virtuella datorer, lagring eller nätverk använder du Azure Portal:
I den vänstra rutan väljer du Alla tjänster och sedan Prenumerationer under kategorin Allmänt .
I listan med prenumerationer väljer du den prenumeration vars kvot du letar efter.
Välj Användning + kvoter för att visa dina aktuella kvotgränser och din användning. Använd filtren för att välja provider och platser.
Du hanterar Azure Machine Learning-beräkningskvoten för din prenumeration separat från andra Azure-kvoter:
Gå till din Azure Machine Learning-arbetsyta i Azure Portal.
I den vänstra rutan i avsnittet Support + felsökning väljer du Användning + kvoter för att visa dina aktuella kvotgränser och din användning.
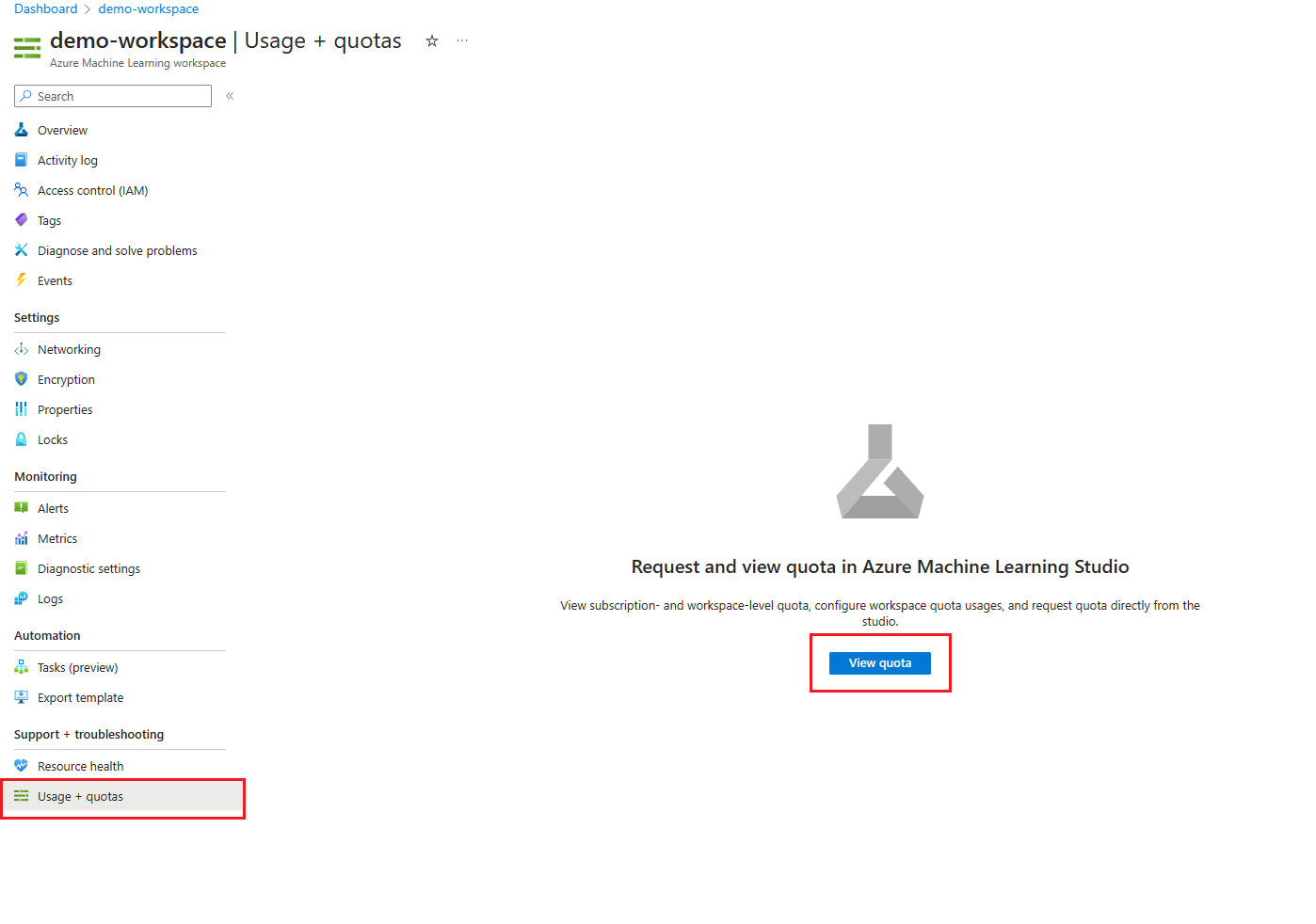
Välj en prenumeration för att visa kvotgränserna. Filtrera efter den region som du är intresserad av.
Du kan växla mellan en vy på prenumerationsnivå och en vy på arbetsytenivå.
Begär kvot och begränsa höjningar
En ökning av VM-kvoten är att öka antalet kärnor per VM-familj per region. Ökning av slutpunktsgräns är att öka slutpunktsspecifika gränser per prenumeration per region. Se till att välja rätt kategori när du skickar begäran om kvotökning enligt beskrivningen i nästa avsnitt.
VM-kvoten ökar
Om du vill höja gränsen för Azure Machine Learning VM-kvoten över standardgränsen kan du begära en kvotökning från vyn Användning + kvoter ovan eller skicka en begäran om kvotökning från Azure Machine Learning-studio.
Gå till sidan Användning + kvoter genom att följa anvisningarna. Visa de aktuella kvotgränserna. Välj den SKU som du vill begära en ökning för.
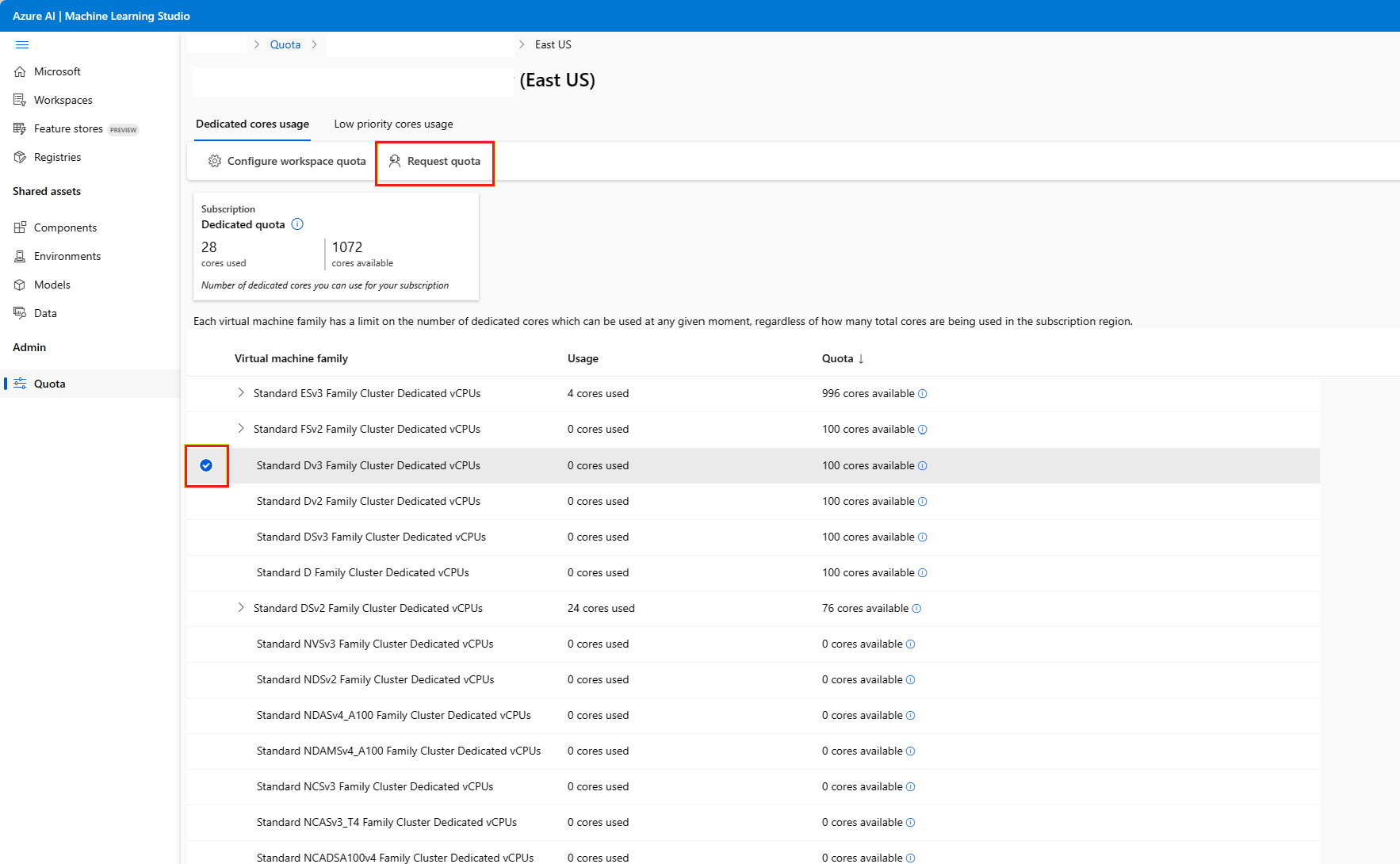
Ange den kvot som du vill öka och det nya gränsvärdet. Välj slutligen Skicka för att fortsätta.
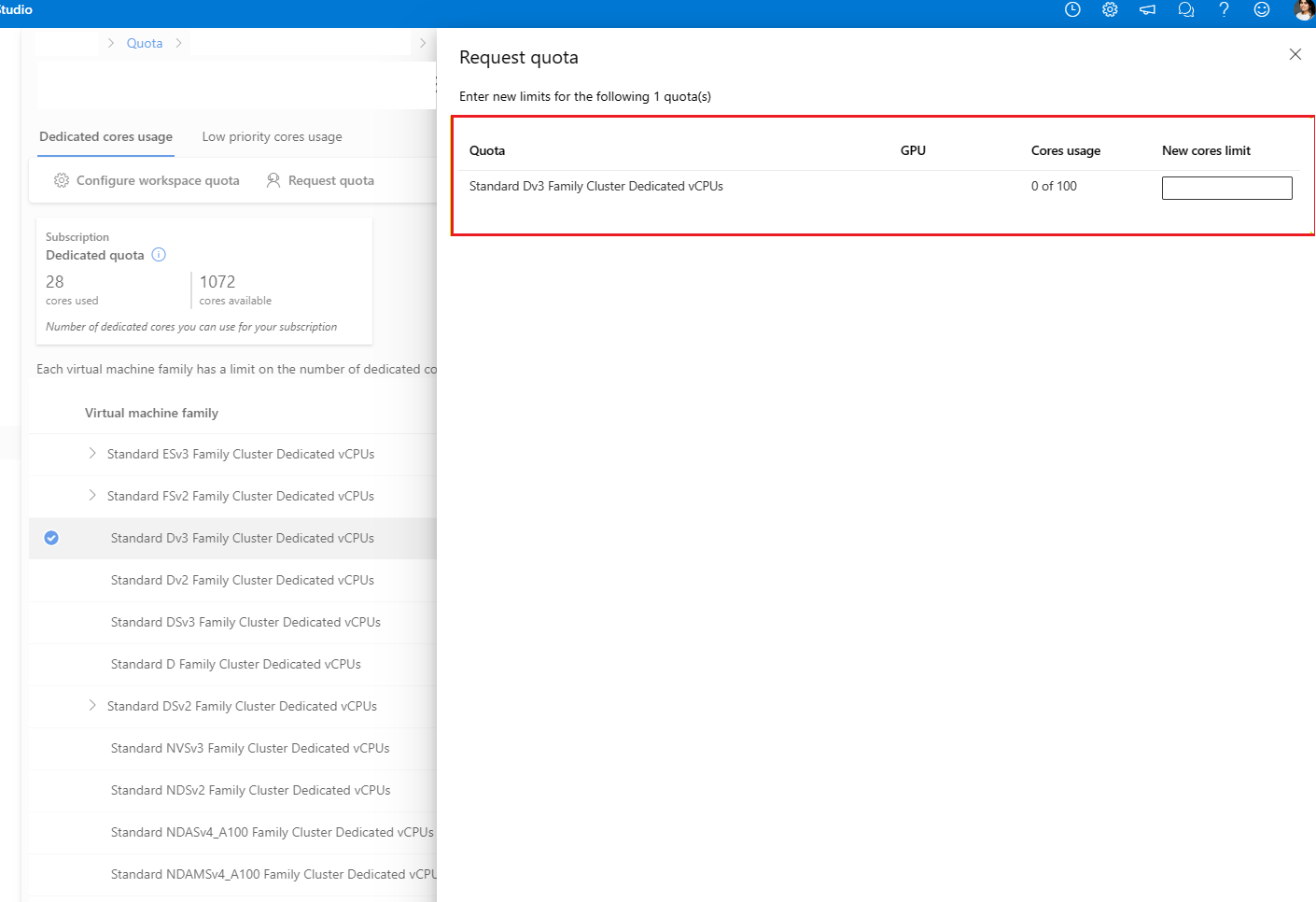
Slutpunktsgränsen ökar
Om du vill höja slutpunktsgränsen, öppna en kundsupportbegäran online. När du begär en ökning av slutpunktsgränsen anger du följande information:
När du öppnar supportbegäran väljer du Tjänst- och prenumerationsgränser (kvoter) som problemtyper.
Välj valfri prenumeration.
Välj Machine Learning Service: Slutpunktsgränser som Kvottyp.
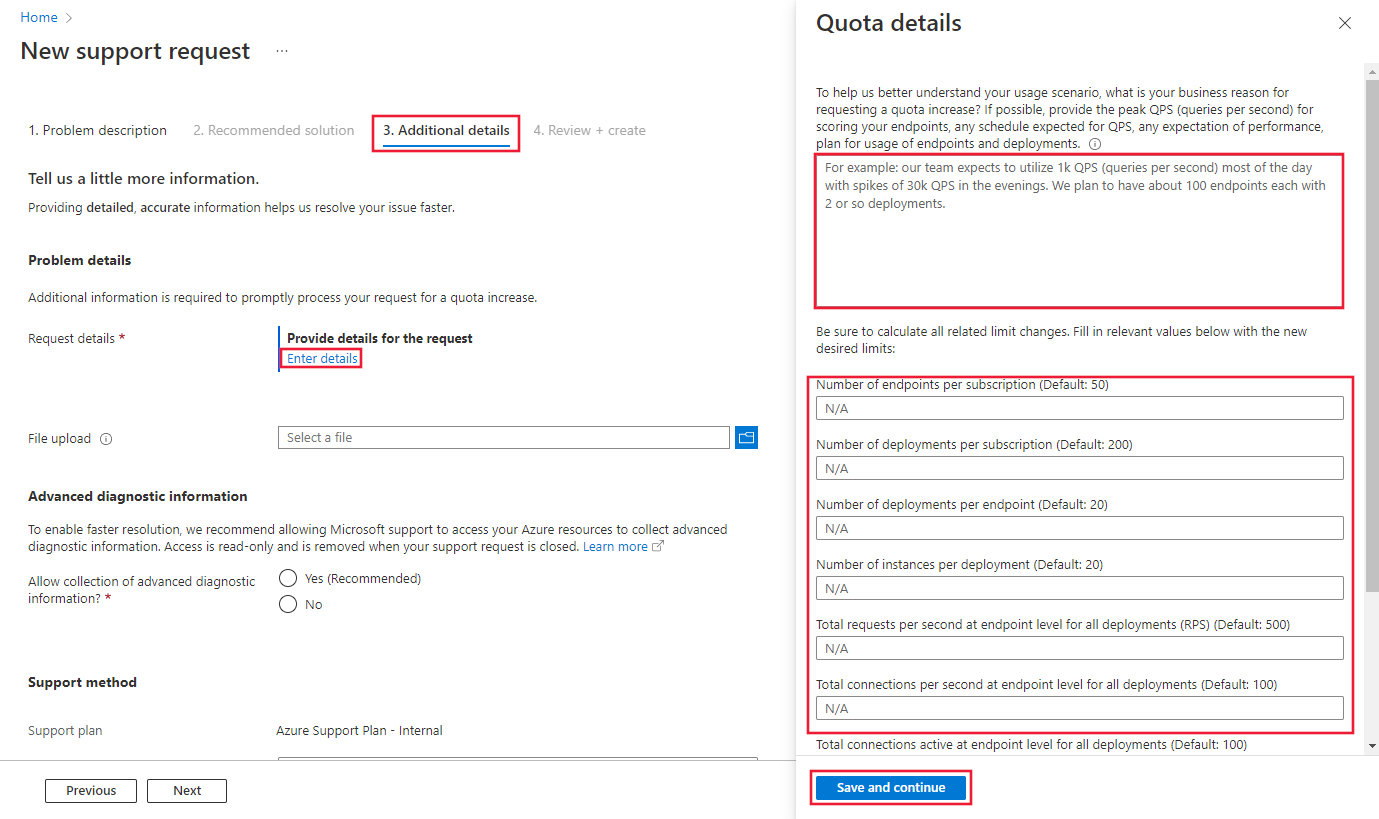
På fliken Ytterligare information måste du ange detaljerade orsaker till gränsökningen för att din begäran ska kunna bearbetas. Välj Ange information och ange sedan den kvot du vill öka och det nya värdet för varje kvot, orsaken till kvotökningsbegäran och de platser där du behöver öka kvoten. Se till att lägga till följande information i orsaken till gränsökningen:
- Beskrivning av ditt scenario och din arbetsbelastning (till exempel text, bild och så vidare).
- Motivering för den begärda ökningen.
- Ange måldataflödet och dess mönster (genomsnittlig/högsta QPS, samtidiga användare).
- Ange målfördröjningen i stor skala och den aktuella svarstiden som du ser med en enda instans.
- Ange vilken VM SKU och antal instanser som totalt ska stödja måldataflödet och svarstiden. Ange hur många slutpunkter/distributioner/instanser som du planerar att använda i varje region.
- Bekräfta om du har ett prestandatest som visar att vald VM-SKU och antalet instanser kommer att uppfylla dina krav på dataflöde och svarstid.
- Ange typen av nyttolast och storleken på en enda nyttolast. Nätverkets bandbredd bör anpassas efter nyttolastens storlek och begäranden per sekund.
- Ange planerad tidsplan (genom att när du behöver ökade gränser – ange stegvis plan om möjligt) och bekräfta om (1) kostnaden för att köra den i den skalan återspeglas i din budget och (2) om mål-VM-SKU:erna godkänns.
Välj slutligen Spara och fortsätt för att fortsätta.
Kommentar
Den här begäran om ökning av slutpunktsgräns skiljer sig från begäran om ökning av VM-kvoter. Om din begäran gäller ökning av VM-kvoten följer du anvisningarna i avsnittet om ökningar av VM-kvoten.
Beräkningsgränsen ökar
För att öka den totala beräkningsgränsen öppnar du en kundsupportbegäran online. Tillhandahåll följande information:
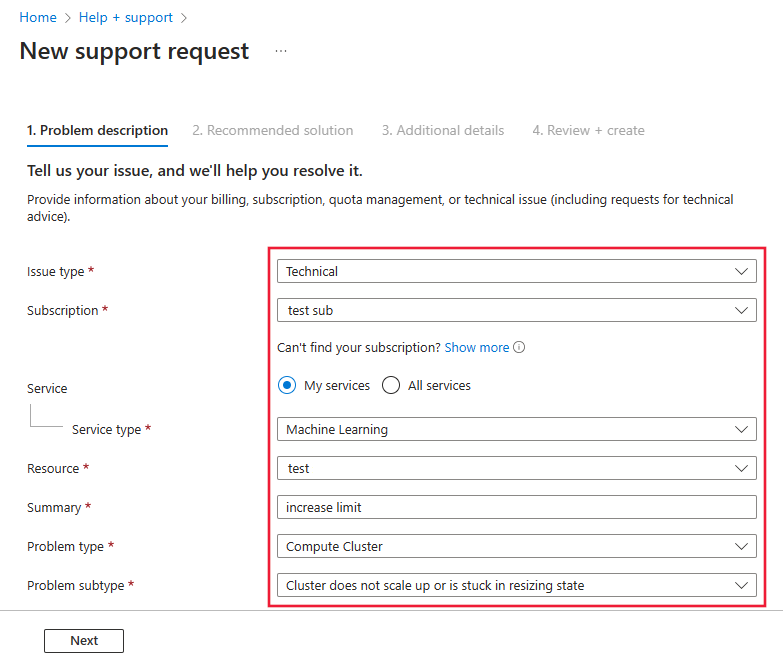
När du öppnar supportbegäran väljer du Teknisk som typ av problem.
Välj valfri prenumeration
Välj maskininlärning som tjänsten.
Välj valfri resurs
I sammanfattningen nämner du ”Öka de totala beräkningsgränserna"
Välj Beräkningskluster som problemtyp och Klustret skalas inte upp eller har fastnat i storleksändringen som undertypenProblem.
På fliken Ytterligare information anger du prenumerations-ID, region, ny gräns (mellan 500 och 2 500) och affärsmotivering om du vill öka de totala beräkningsgränserna i den här regionen.
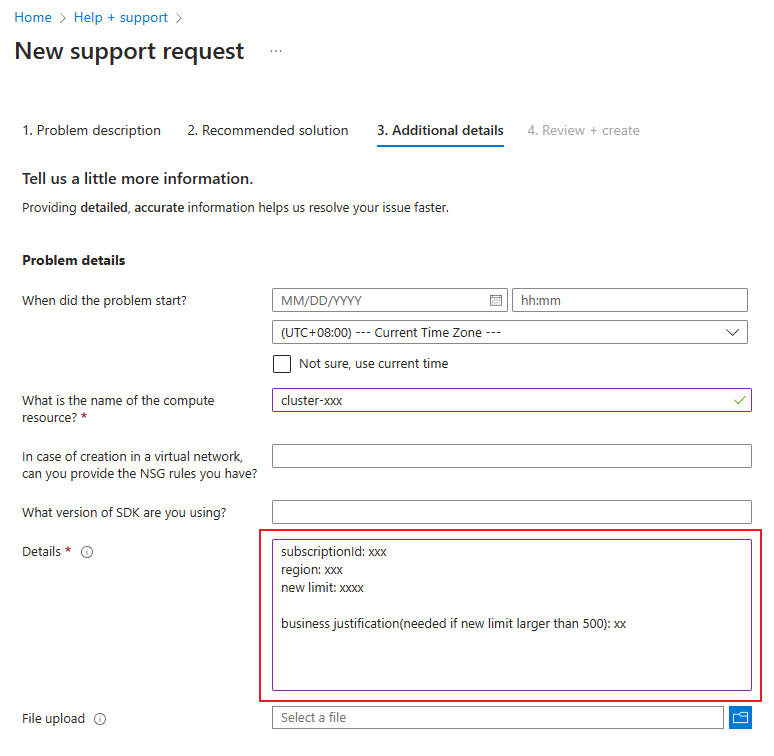
Välj slutligen Skapa för att skapa en supportbegäran.