Skapa och utforska Azure Mašinsko učenje datauppsättning med etiketter
I den här artikeln får du lära dig hur du exporterar dataetiketterna från ett Azure-Mašinsko učenje dataetikettprojekt och läser in dem i populära format som en Pandas-dataram för datautforskning.
Vad är datauppsättningar med etiketter?
Azure Mašinsko učenje datauppsättningar med etiketter kallas etiketterade datauppsättningar. Dessa specifika datauppsättningar är TabularDatasets med en dedikerad etikettkolumn och skapas endast som utdata från Azure Mašinsko učenje dataetikettprojekt. Skapa ett dataetikettprojekt för bildetiketter eller textetiketter. Mašinsko učenje stöder dataetiketteringsprojekt för bildklassificering, antingen flera etiketter eller flera klasser, och objektidentifiering tillsammans med avgränsade rutor.
Förutsättningar
- En Azure-prenumeration. Om du inte har en Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
- Azure Mašinsko učenje SDK för Python eller åtkomst till Azure Mašinsko učenje Studio.
- En Mašinsko učenje arbetsyta. Se Skapa arbetsyteresurser.
- Åtkomst till ett Azure Mašinsko učenje dataetikettprojekt. Om du inte har något etikettprojekt skapar du först ett för bildetiketter eller textetiketter.
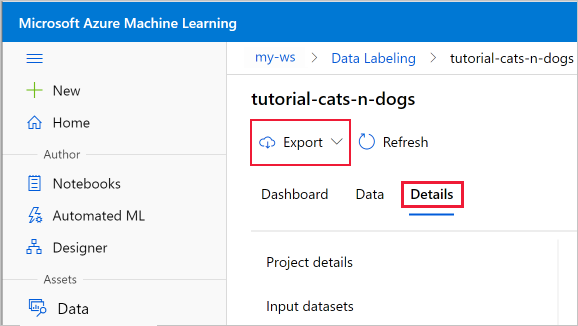
Exportera dataetiketter
När du har slutfört ett dataetikettprojekt kan du exportera etikettdata från ett etikettprojekt. På så sätt kan du samla in både referensen till data och dess etiketter och exportera dem i COCO-format eller som en Azure-Mašinsko učenje datauppsättning.
Använd knappen Exportera på sidan Projektinformation för ditt etikettprojekt.
COCO
COCO-filen skapas i standardbloblagret för Azure Mašinsko učenje-arbetsytan i en mapp inom export/coco.
Kommentar
I objektidentifieringsprojekt normaliseras de exporterade "bbox-värdena": [x,y,width,height]" i COCO-filen. De skalas till 1. Exempel: en avgränsningsruta på (10, 10) plats med bredden 30 bildpunkter , 60 bildpunkters höjd, i en bild på 640 x 480 bildpunkter kommenteras som (0,015625. 0,02083, 0,046875, 0,125). Eftersom koordinaterna normaliseras visas det som "0.0" som "bredd" och "höjd" för alla bilder. Den faktiska bredden och höjden kan hämtas med hjälp av Python-biblioteket som OpenCV eller Pillow(PIL).
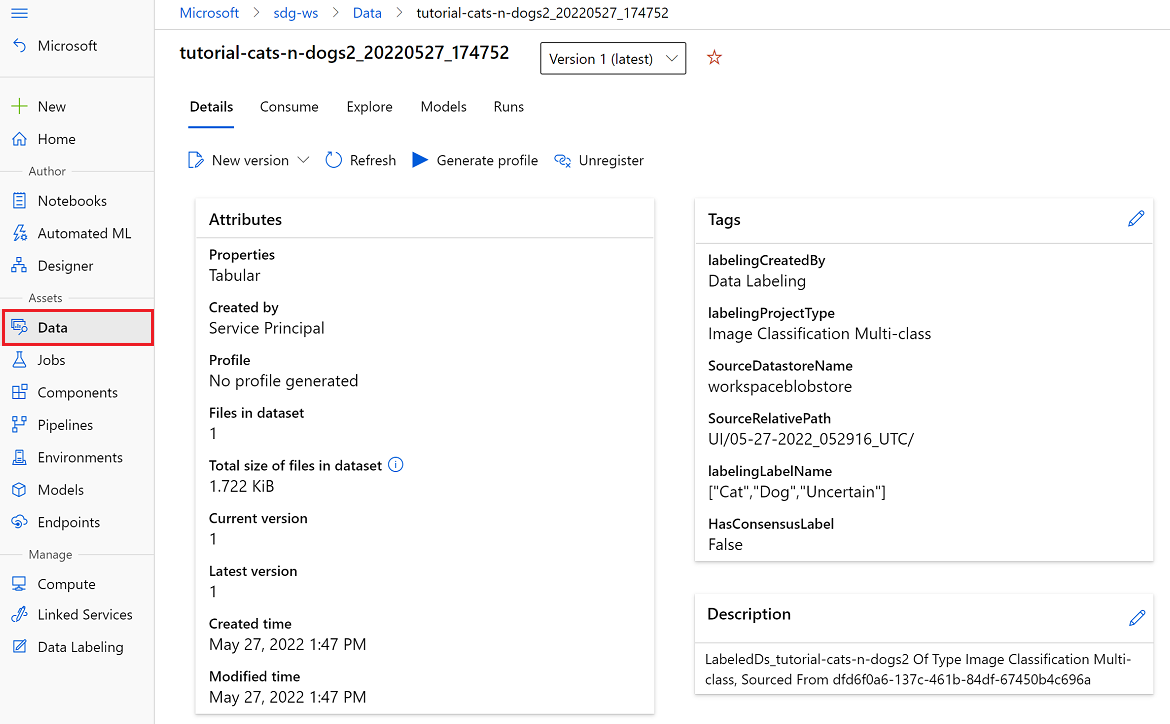
Azure Mašinsko učenje-datauppsättning
Du kan komma åt den exporterade Azure Mašinsko učenje-datauppsättningen i avsnittet Datauppsättningar i azure Mašinsko učenje studio. Sidan Information om datauppsättning innehåller även exempelkod för att komma åt etiketterna från Python.
Dricks
När du har exporterat dina märkta data till en Azure-Mašinsko učenje datauppsättning kan du använda AutoML för att skapa modeller för visuellt innehåll som tränats på dina märkta data. Läs mer i Konfigurera AutoML för att träna modeller för visuellt innehåll med Python
Utforska etiketterade datauppsättningar via Pandas-dataram
Läs in dina märkta datauppsättningar i en Pandas-dataram för att använda populära bibliotek med öppen källkod för datautforskning med to_pandas_dataframe() metoden från azureml-dataprep klassen.
Installera klassen med följande gränssnittskommando:
pip install azureml-dataprep
I följande kod är datauppsättningen animal_labels utdata från ett etikettprojekt som tidigare sparats på arbetsytan.
Den exporterade datamängden är en TabularDataset.
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
import azureml.core
from azureml.core import Dataset, Workspace
# get animal_labels dataset from the workspace
animal_labels = Dataset.get_by_name(workspace, 'animal_labels')
animal_pd = animal_labels.to_pandas_dataframe()
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#read images from dataset
img = mpimg.imread(animal_pd['image_url'].iloc(0).open())
imgplot = plt.imshow(img)
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för