Självstudie: Modellutveckling på en molnarbetsstation
Lär dig hur du utvecklar ett träningsskript med en notebook-fil på en Azure Machine Learning-molnarbetsstation. Den här självstudien beskriver grunderna du behöver för att komma igång:
- Konfigurera och konfigurera molnarbetsstationen. Din molnarbetsstation drivs av en Azure Machine Learning-beräkningsinstans som är förkonfigurerad med miljöer för att stödja dina olika modellutvecklingsbehov.
- Använd molnbaserade utvecklingsmiljöer.
- Använd MLflow för att spåra dina modellmått, allt från en notebook-fil.
Förutsättningar
Om du vill använda Azure Machine Learning behöver du en arbetsyta. Om du inte har någon slutför du Skapa resurser som du behöver för att komma igång med att skapa en arbetsyta och lära dig mer om hur du använder den.
Viktigt!
Om din Azure Machine Learning-arbetsyta har konfigurerats med ett hanterat virtuellt nätverk kan du behöva lägga till regler för utgående trafik för att tillåta åtkomst till de offentliga Python-paketlagringsplatserna. Mer information finns i Scenario: Åtkomst till offentliga maskininlärningspaket.
Börja med beräkning
I avsnittet Beräkning på arbetsytan kan du skapa beräkningsresurser. En beräkningsinstans är en molnbaserad arbetsstation som hanteras helt av Azure Machine Learning. I den här självstudieserien används en beräkningsinstans. Du kan också använda den för att köra din egen kod och för att utveckla och testa modeller.
- Logga in på Azure Machine Learning-studio.
- Välj din arbetsyta om den inte redan är öppen.
- I det vänstra navigeringsfältet väljer du Beräkning.
- Om du inte har någon beräkningsinstans visas Nytt mitt på skärmen. Välj Nytt och fyll i formuläret. Du kan använda alla standardvärden.
- Om du har en beräkningsinstans väljer du den i listan. Om den har stoppats väljer du Start.
Öppna Visual Studio Code (VS Code)
När du har en beräkningsinstans som körs kan du komma åt den på olika sätt. Den här självstudien visar hur du använder beräkningsinstansen från VS Code. VS Code ger dig en fullständig integrerad utvecklingsmiljö (IDE) med kraften i Azure Machine Learning-resurser.
I listan över beräkningsinstanser väljer du länken VS Code (Web) eller VS Code (Desktop) för den beräkningsinstans som du vill använda. Om du väljer VS Code (Desktop) kan du se ett popup-fönster som frågar om du vill öppna programmet.

Den här VS Code-instansen är kopplad till din beräkningsinstans och ditt arbetsytefilsystem. Även om du öppnar den på skrivbordet är filerna du ser filer på din arbetsyta.
Konfigurera en ny miljö för prototyper (valfritt)
För att skriptet ska kunna köras måste du arbeta i en miljö som konfigurerats med de beroenden och bibliotek som koden förväntar sig. Det här avsnittet hjälper dig att skapa en miljö som är anpassad efter din kod. Om du vill skapa den nya Jupyter-kerneln som notebook-filen ansluter till använder du en YAML-fil som definierar beroendena.
Ladda upp en fil.
Filer som du laddar upp lagras i en Azure-filresurs och dessa filer monteras på varje beräkningsinstans och delas på arbetsytan.
Ladda ned den här conda-miljöfilen workstation_env.yml till datorn med hjälp av knappen Ladda ned råfil längst upp till höger.
Dra filen från datorn till VS Code-fönstret. Filen laddas upp till din arbetsyta.
Flytta filen under din användarnamnsmapp.

Välj den här filen för att förhandsgranska den och se vilka beroenden den anger. Du ser innehållet så här:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibSkapa en kernel.
Använd nu terminalen för att skapa en ny Jupyter-kernel, baserat på workstation_env.yml-filen.
På den översta menyraden väljer du Terminal > Ny terminal.
Visa dina aktuella conda-miljöer. Den aktiva miljön är markerad med *.
conda env listcdtill mappen där du laddade upp workstation_env.yml-filen. Om du till exempel har laddat upp den till din användarmapp:cd Users/myusernameKontrollera att workstation_env.yml finns i den här mappen.
lsSkapa miljön baserat på den angivna conda-filen. Det tar några minuter att skapa den här miljön.
conda env create -f workstation_env.ymlAktivera den nya miljön.
conda activate workstation_envKommentar
Om du ser en CommandNotFoundError följer du anvisningarna för att köra
conda init bash, stänga terminalen och öppna en ny. Försök sedan med kommandot igenconda activate workstation_env.Verifiera att rätt miljö är aktiv och leta efter miljön som markerats med *.
conda env listSkapa en ny Jupyter-kernel baserat på din aktiva miljö.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Stäng terminalfönstret.
Nu har du en ny kernel. Därefter öppnar du en notebook-fil och använder den här kerneln.
Skapa en notebook-fil
- På den översta menyraden väljer du Arkiv > Ny fil.
- Ge den nya filen namnet develop-tutorial.ipynb (eller ange önskat namn). Kontrollera att du använder tillägget .ipynb .
Ange kerneln
- Längst upp till höger väljer du Välj kernel.
- Välj Azure ML-beräkningsinstans (computeinstance-name).
- Välj den kernel som du skapade, Tutorial Workstation Env. Om du inte ser det väljer du uppdateringsverktyget längst upp till höger.
Utveckla ett träningsskript
I det här avsnittet utvecklar du ett Python-träningsskript som förutsäger standardbetalningar för kreditkort med hjälp av förberedda test- och träningsdatauppsättningar från UCI-datauppsättningen.
Den här koden används sklearn för träning och MLflow för att logga måtten.
Börja med kod som importerar de paket och bibliotek som du ska använda i träningsskriptet.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitLäs sedan in och bearbeta data för det här experimentet. I den här självstudien läser du data från en fil på Internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Förbered data för träning:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesLägg till kod för att starta automatisk loggning med
MLflow, så att du kan spåra mått och resultat. Med den iterativa karaktären hos modellutvecklingMLflowkan du logga modellparametrar och resultat. Gå tillbaka till dessa körningar för att jämföra och förstå hur din modell presterar. Loggarna ger också kontext för när du är redo att gå från utvecklingsfasen till träningsfasen för dina arbetsflöden i Azure Machine Learning.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Träna en modell.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Kommentar
Du kan ignorera mlflow-varningarna. Du får fortfarande alla resultat som du behöver spåra.
Upprepa
Nu när du har modellresultat kanske du vill ändra något och försöka igen. Prova till exempel en annan klassificerarteknik:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Kommentar
Du kan ignorera mlflow-varningarna. Du får fortfarande alla resultat som du behöver spåra.
Granska resultat
Nu när du har provat två olika modeller använder du de resultat som spåras av MLFfow för att avgöra vilken modell som är bättre. Du kan referera till mått som noggrannhet eller andra indikatorer som är viktigast för dina scenarier. Du kan gå in närmare på dessa resultat genom att titta på jobben som skapats av MLflow.
Gå tillbaka till din arbetsyta i Azure Machine Learning-studio.
I det vänstra navigeringsfältet väljer du Jobb.
Välj länken för självstudien Utveckla i molnet.
Det finns två olika jobb som visas, ett för var och en av de modeller som du provade. Dessa namn genereras automatiskt. När du hovra över ett namn använder du pennverktyget bredvid namnet om du vill byta namn på det.
Välj länken för det första jobbet. Namnet visas överst. Du kan också byta namn på det här med pennverktyget.
Sidan visar information om jobbet, till exempel egenskaper, utdata, taggar och parametrar. Under Taggar visas estimator_name, som beskriver typen av modell.
Välj fliken Mått för att visa de mått som loggades av
MLflow. (Förvänta dig att dina resultat skiljer sig åt eftersom du har en annan träningsuppsättning.)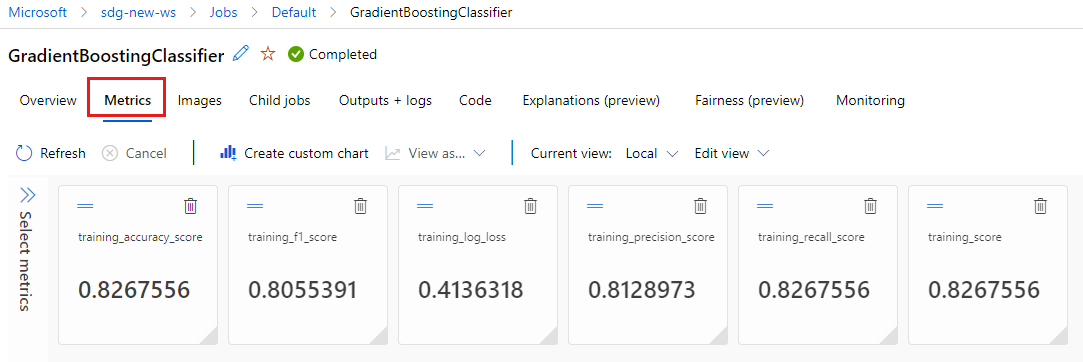
Välj fliken Bilder för att visa de bilder som genereras av
MLflow.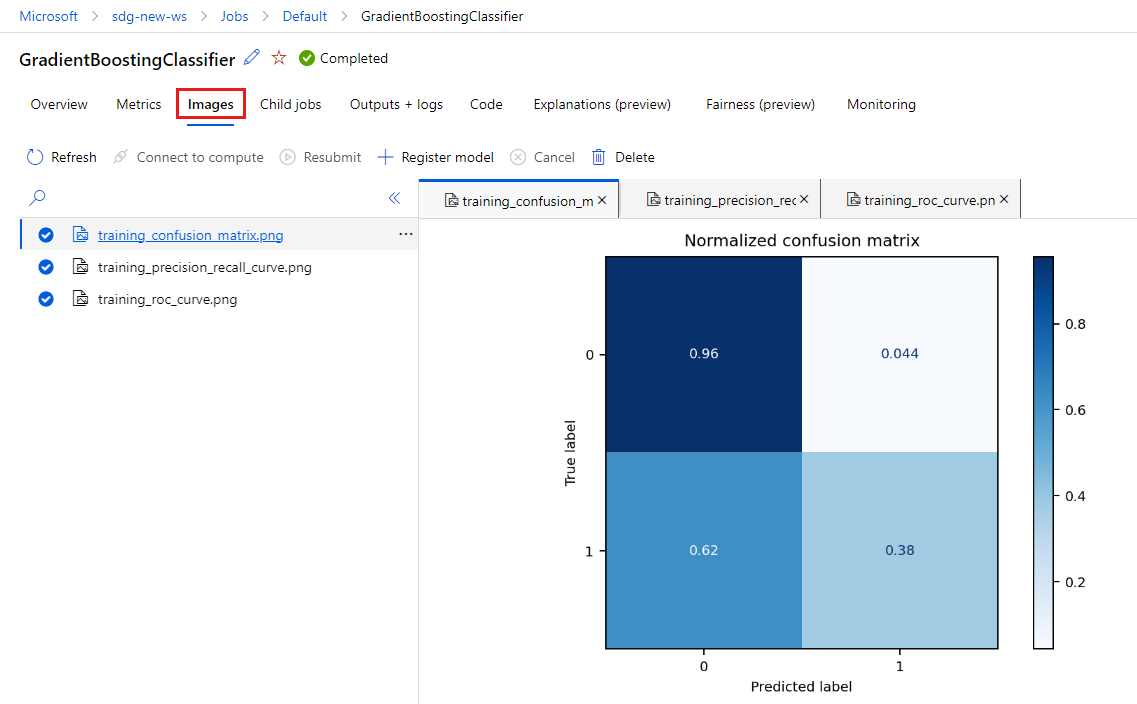
Gå tillbaka och granska mått och bilder för den andra modellen.
Skapa ett Python-skript
Skapa nu ett Python-skript från anteckningsboken för modellträning.
I VS Code-fönstret högerklickar du på filnamnet för notebook-filen och väljer Importera notebook-fil till skript.
Använd menyn Spara fil > för att spara den nya skriptfilen. Kalla det train.py.
Titta igenom den här filen och ta bort den kod som du inte vill använda i träningsskriptet. Behåll till exempel koden för den modell som du vill använda och ta bort kod för den modell som du inte vill använda.
- Se till att du behåller koden som startar automatisk loggning (
mlflow.sklearn.autolog()). - När du kör Python-skriptet interaktivt (som du gör här) kan du behålla den rad som definierar experimentnamnet (
mlflow.set_experiment("Develop on cloud tutorial")). Eller till och med ge det ett annat namn för att se det som en annan post i avsnittet Jobb . Men när du förbereder skriptet för ett träningsjobb gäller inte den raden och bör utelämnas – jobbdefinitionen innehåller experimentnamnet. - När du tränar en enskild modell är linjerna för att starta och avsluta en körning (
mlflow.start_run()ochmlflow.end_run()) inte heller nödvändiga (de har ingen effekt), men kan lämnas kvar om du vill.
- Se till att du behåller koden som startar automatisk loggning (
Spara filen när du är klar med dina redigeringar.
Nu har du ett Python-skript som du kan använda för att träna önskad modell.
Kör Python-skriptet
För tillfället kör du den här koden på din beräkningsinstans, som är din Azure Machine Learning-utvecklingsmiljö. Självstudie: Träna en modell visar hur du kör ett träningsskript på ett mer skalbart sätt på mer kraftfulla beräkningsresurser.
Välj den miljö som du skapade tidigare i den här självstudien som din Python-version (workstations_env). I det nedre högra hörnet i anteckningsboken visas miljönamnet. Välj den och välj sedan miljön mitt på skärmen.

Kör nu Python-skriptet. Använd verktyget Kör Python-fil längst upp till höger.

Kommentar
Du kan ignorera mlflow-varningarna. Du får fortfarande alla mått och bilder från automatisk loggning.
Granska skriptresultat
Gå tillbaka till Jobb på din arbetsyta i Azure Machine Learning-studio för att se resultatet av ditt träningsskript. Tänk på att träningsdata ändras med varje delning, så resultaten skiljer sig också mellan körningarna.
Rensa resurser
Om du planerar att fortsätta nu till andra självstudier går du vidare till Nästa steg.
Stoppa beräkningsinstans
Om du inte ska använda den nu stoppar du beräkningsinstansen:
- Välj Beräkning i det vänstra navigeringsområdet i studion.
- På de översta flikarna väljer du Beräkningsinstanser
- Välj beräkningsinstansen i listan.
- I det övre verktygsfältet väljer du Stoppa.
Ta bort alla resurser
Viktigt!
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter:
I Azure Portal i sökrutan anger du Resursgrupper och väljer dem i resultatet.
I listan väljer du den resursgrupp som du skapade.
På sidan Översikt väljer du Ta bort resursgrupp.
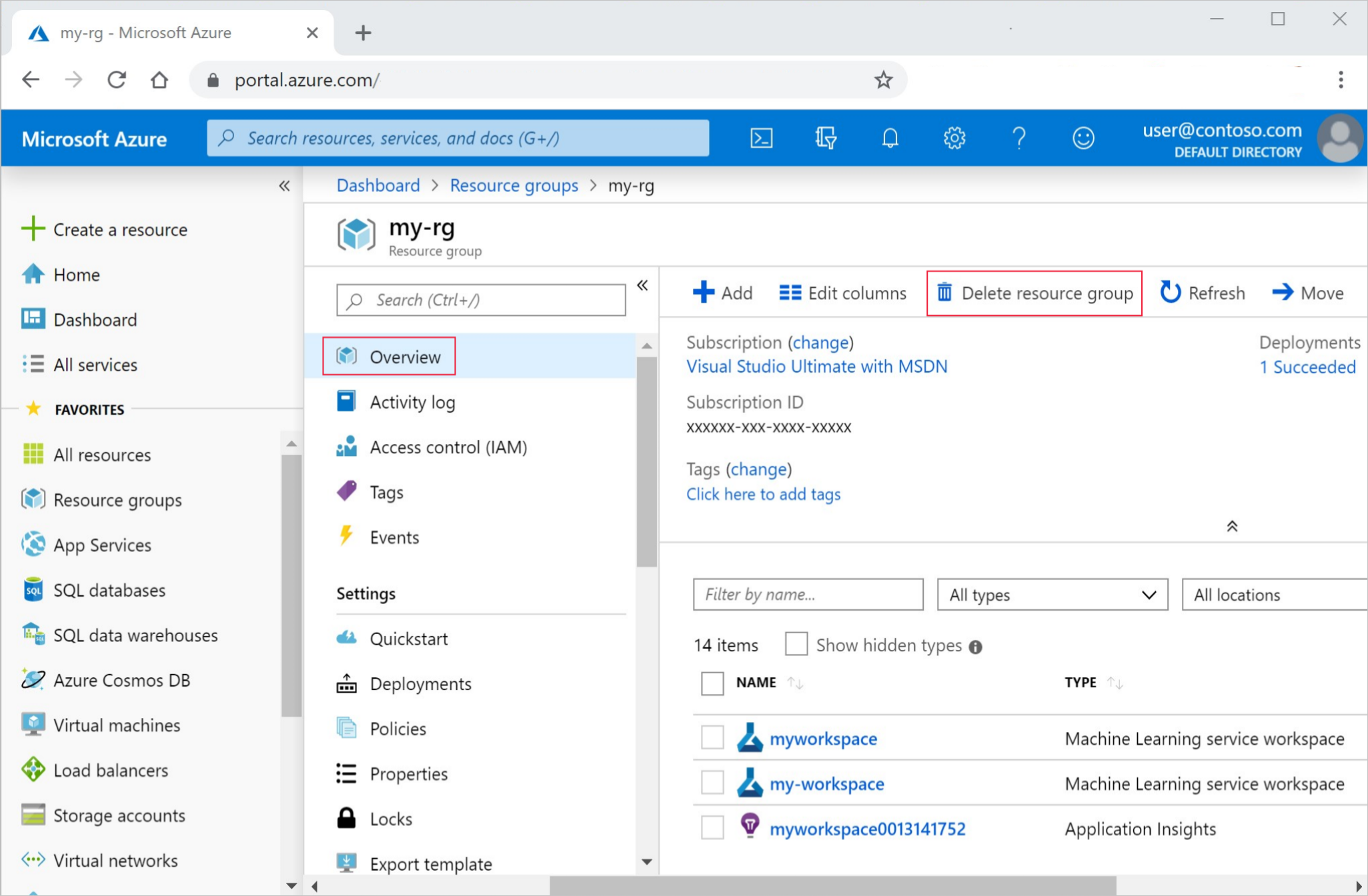
Ange resursgruppsnamnet. Välj sedan ta bort.
Nästa steg
Läs mer om:
- Från artefakter till modeller i MLflow
- Använda Git med Azure Machine Learning
- Köra Jupyter Notebooks på din arbetsyta
- Arbeta med en beräkningsinstansterminal på din arbetsyta
- Hantera notebook- och terminalsessioner
Den här självstudien visade de tidiga stegen för att skapa en modell, prototyper på samma dator där koden finns. För produktionsträningen lär du dig hur du använder träningsskriptet på mer kraftfulla fjärrberäkningsresurser: