Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här självstudieserien visar hur funktioner sömlöst integrerar alla faser i maskininlärningslivscykeln: prototyper, utbildning och operationalisering.
Du kan använda Azure Machine Learning hanterad funktionsbutik för att identifiera, skapa och operationalisera funktioner. Livscykeln för maskininlärning innehåller en prototypfas där du experimenterar med olika funktioner. Det omfattar också en driftsättningsfas, där modeller distribueras och slutsatsdragningssteg söker upp funktionsdata. Funktioner fungerar som bindväv i maskininlärningslivscykeln. Mer information om grundläggande begrepp för hanterad funktionsbutik finns i Vad är hanterad funktionsbutik? och Förstå entiteter på toppnivå i hanterad funktionsbutik resurser.
I den här självstudien beskrivs hur du skapar en funktionsuppsättningsspecifikation med anpassade transformeringar. Den använder sedan den funktionsuppsättningen för att generera träningsdata, aktivera materialisering och utföra en återfyllnad. Materialisering beräknar funktionsvärdena för ett funktionsfönster och lagrar sedan dessa värden i ett materialiseringslager. Alla funktionsfrågor kan sedan använda dessa värden från materialiseringsarkivet.
Utan materialisering tillämpar en funktionsuppsättningsfråga transformeringarna på källan i farten för att beräkna funktionerna innan den returnerar värdena. Den här processen fungerar bra för prototypfasen. För utbildning och slutsatsdragningsåtgärder i en produktionsmiljö rekommenderar vi dock att du materialiserar funktionerna för bättre tillförlitlighet och tillgänglighet.
Den här handledningen är den första delen i den hanterade funktionstjänst-självstudieserien. Här får du lära dig hur du:
- Skapa en ny, minimal funktionslagringsresurs.
- Utveckla och lokalt testa en funktionsuppsättning med funktioner för funktionstransformering.
- Registrera en funktionsenhet i funktionslagret.
- Registrera den funktionsuppsättning som du utvecklade med funktionsbiblioteket.
- Generera ett exempel på en dataram för träning med hjälp av de funktioner som du skapade.
- Aktivera materialisering offline på funktionsuppsättningarna och fyll på funktionsdata igen.
Den här självstudieserien har två spår:
- Endast SDK-spåret använder endast Python-SDK:er. Välj det här spåret för ren, Python-baserad utveckling och distribution.
- SDK- och CLI-spåret använder Endast Python SDK för utveckling och testning av funktionsuppsättningar och använder CLI för CRUD-åtgärder (skapa, läsa, uppdatera och ta bort). Det här spåret är användbart i scenarier med kontinuerlig integrering och kontinuerlig leverans (CI/CD) eller GitOps, där CLI/YAML föredras.
Förutsättningar
Innan du fortsätter med den här handledningen ska du se till att täcka dessa förutsättningar:
En Azure Machine Learning-arbetsyta. Mer information om hur du skapar arbetsytor finns i Snabbstart: Skapa arbetsyteresurser.
På ditt användarkonto behöver du rollen Ägare för resursgruppen där funktionsarkivet skapas.
Om du väljer att använda en ny resursgrupp för den här självstudien kan du enkelt ta bort alla resurser genom att ta bort resursgruppen.
Förbereda notebook-miljön
I den här självstudien används en Azure Machine Learning Spark-notebook för utveckling.
I miljön för Azure Machine Learning-studio väljer du Notebooks i det vänstra fönstret och väljer sedan fliken Exempel.
Bläddra till katalogen featurestore_sample (välj Exempel>) och välj >
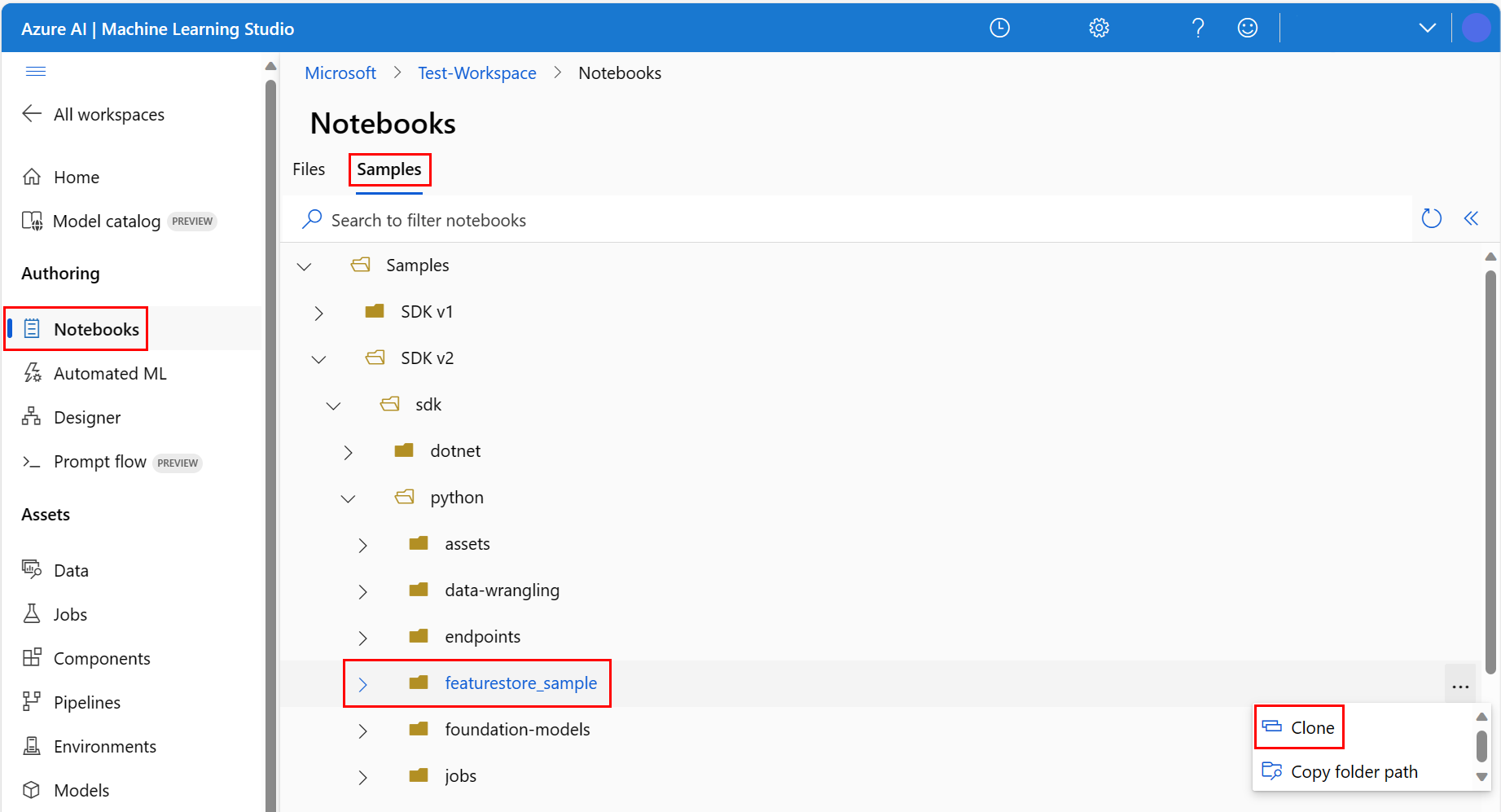
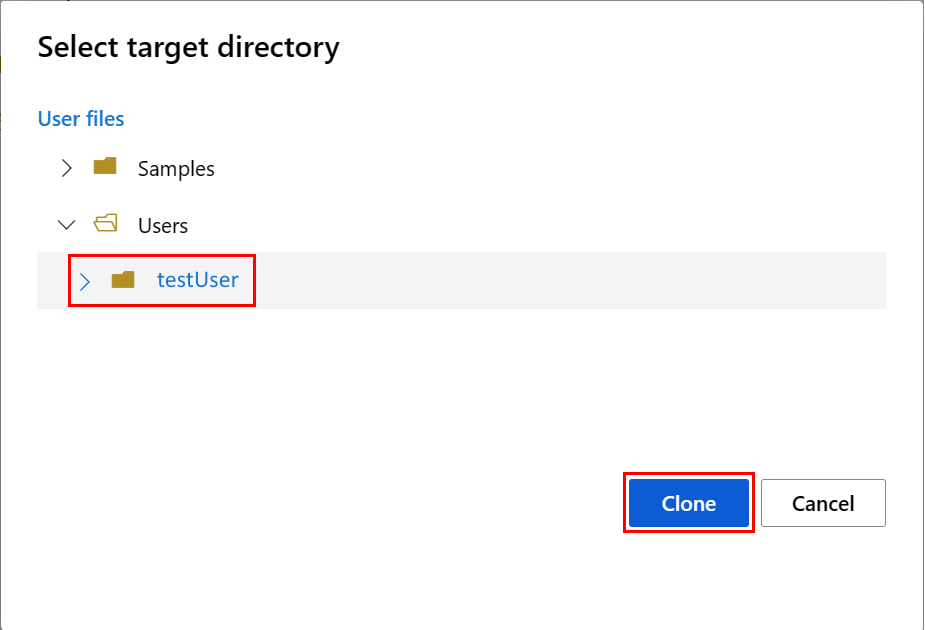
Panelen Välj målkatalog öppnas. Välj katalogen Användare, välj sedan ditt användarnamn och välj slutligen Klona.
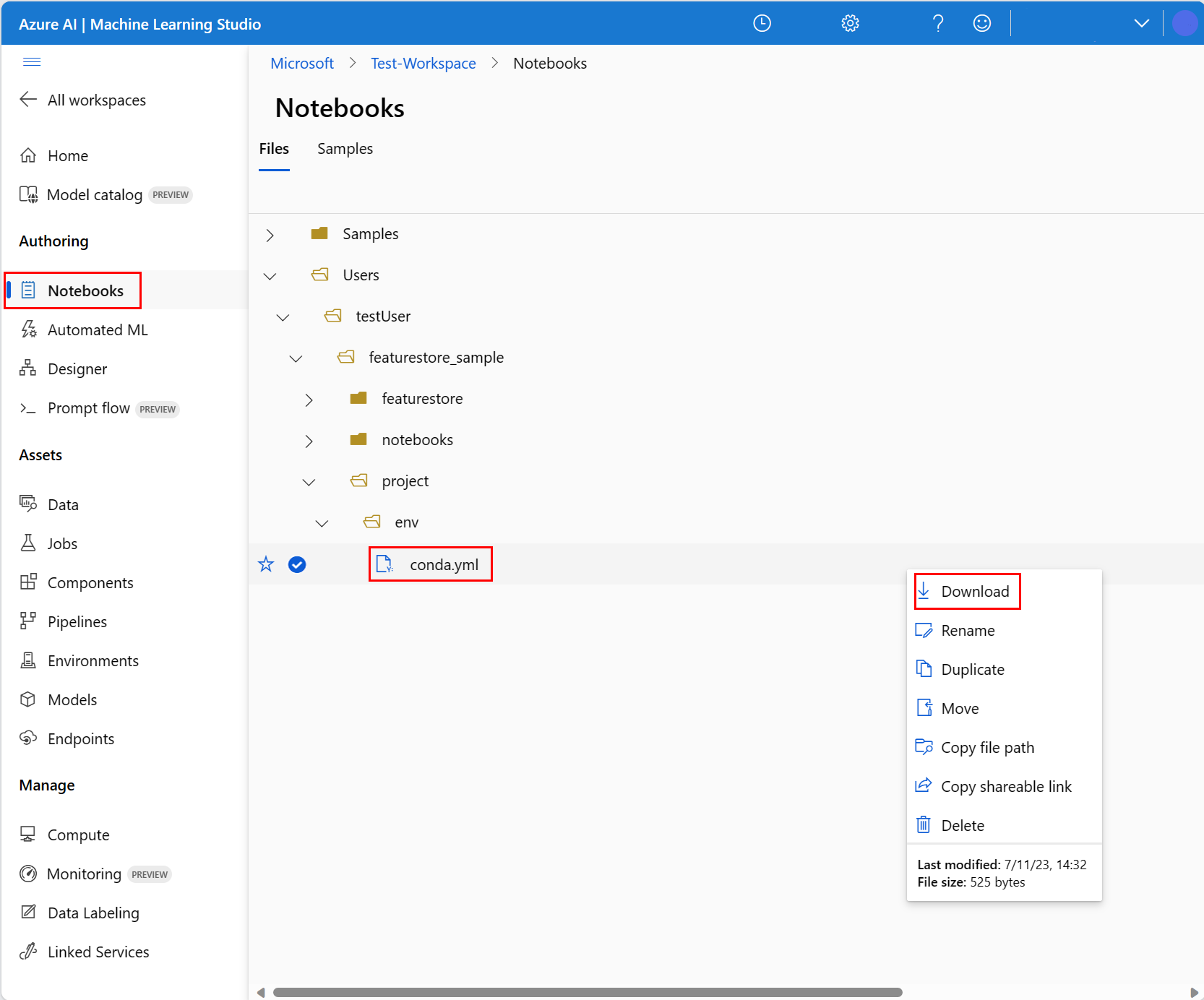
Om du vill konfigurera notebook-miljön måste du ladda upp conda.yml-filen:
- Välj Anteckningsböcker i det vänstra fönstret och välj därefter fliken Filer.
- Bläddra till katalogen env (välj >featurestore_sample>project>env) och välj >
- Välj Hämta.
- Välj Serverlös Spark Compute i den översta navigeringsrutan Beräkning . Den här åtgärden kan ta en till två minuter. Vänta tills ett statusfält längst upp visar Konfigurera session.
- Välj Konfigurera session i det översta statusfältet.
- Välj Python-paket.
- Välj Ladda upp conda-filer.
- Välj den
conda.ymlfil som du laddade ned på den lokala enheten. - (Valfritt) Öka tidsgränsen för sessionen (inaktiv tid i minuter) för att minska starttiden för serverlösa spark-kluster.
Öppna notebook-filen i Azure Machine Learning-miljön och välj sedan Konfigurera session.

I panelen Konfigurera session väljer du Python-paket.
Ladda upp Conda-filen:
- På fliken Python-paket väljer du Ladda upp Conda-fil.
- Bläddra till katalogen som är värd för Conda-filen.
- Välj conda.yml och välj sedan Öppna.

Välj Använd.







Starta Spark-sessionen
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")Konfigurera rotkatalogen för exemplen
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")Konfigurera CLI
Ej tillämpbart.
Anmärkning
Du använder ett funktionsarkiv för att återanvända funktioner i olika projekt. Du använder en projektarbetsyta (en Azure Machine Learning-arbetsyta) för att träna slutsatsdragningsmodeller genom att dra nytta av funktioner från funktionslager. Många projektarbetsytor kan dela och återanvända samma funktionsarkiv.
I den här självstudien används två SDK:er:
CRUD SDK för funktionlager
Du använder samma
MLClient(paketnamnazure-ai-ml) SDK som du använder med Azure Machine Learning-arbetsytan. Ett feature store implementeras som en typ av arbetsyta. Därför används denna SDK för CRUD-åtgärder för funktionslager, funktionsuppsättningar och funktionslagerentiteter.Feature Store Core-SDK
Denna SDK (
azureml-featurestore) är avsedd för utveckling och förbrukning av funktionsuppsättningar. Senare steg i den här självstudien beskriver följande åtgärder:- Utveckla en funktionsuppsättningsspecifikation.
- Hämta funktionsdata.
- Visa en lista över eller hämta en registrerad funktionsuppsättning.
- Generera och lösa specifikationer för funktionshämtning.
- Generera tränings- och slutsatsdragningsdata med hjälp av punkt-i-tid-kopplingar.
Den här självstudien kräver inte explicit installation av dessa SDK:er, eftersom de tidigare conda.yml instruktionerna omfattar det här steget.
Skapa ett minimalt funktionslager
Ange parametrar för funktionsarkiv, inklusive namn, plats och andra värden.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Skapa funktionlagret.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Initiera en SDK-klient för en funktionslagerkärna för Azure Machine Learning.
Som vi beskrev tidigare i den här självstudien används SDK-kärnklienten i funktionsarkivet för att utveckla och använda funktioner.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Tilldela rollen "Azure Machine Learning Dataforskare" i funktionlagret till din användaridentitet. Hämta ditt Microsoft Entra-objekt-ID från Azure Portal enligt beskrivningen i Hitta användarobjektets ID.
Tilldela Rollen AzureML-Dataforskare till din användaridentitet så att den kan skapa resurser i funktionslagringsarbetsytan. Behörigheterna kan behöva lite tid för att spridas.
Mer information om åtkomstkontroll finns i Hantera åtkomstkontroll för hanterad funktionsbutik resurs.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Prototyp och utveckla en funktionsuppsättning
I de här stegen skapar du en funktionsuppsättning med namnet transactions som har aggregeringsbaserade funktioner för rullande fönster:
transactionsUtforska källdata.Den här notebook-filen använder exempeldata som finns i en offentligt tillgänglig blobcontainer. Den kan endast läsas in i Spark via en
wasbsdrivrutin. När du skapar funktionsuppsättningar med dina egna källdata ska du vara värd för dem i ett Azure Data Lake Storage Gen2-konto och använda enabfssdrivrutin i datasökvägen.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueUtveckla funktionsuppsättningen lokalt.
En funktionsuppsättningsspecifikation är en fristående definition av en funktionsuppsättning som du kan utveckla och testa lokalt. Här skapar du de här mängdfunktionerna för rullande fönster:
transactions three-day counttransactions amount three-day avgtransactions amount three-day sumtransactions seven-day counttransactions amount seven-day avgtransactions amount seven-day sum
Granska kodfilen för funktionstransformering: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Observera den löpande aggregering som definierats för funktionerna. Det här är en Spark-transformator.
Mer information om funktionsuppsättningar och transformeringar finns i resursen Vad är hanterad funktionsbutik?
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Exportera som en funktionsuppsättningsspecifikation.
Om du vill registrera funktionsuppsättningsspecifikationen med funktionsarkivet måste du spara specifikationen i ett visst format.
Granska specifikationen för den genererade funktionsuppsättningen
transactions. Öppna den här filen från filträdet för att se specifikationen featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml .Specifikationen innehåller följande element:
-
source: En referens till en lagringsresurs. I det här fallet är det en parquetfil i en bloblagringsresurs. -
features: En lista över funktioner och deras datatyper. Om du anger transformeringskod måste koden returnera en DataFrame som mappar till funktionerna och datatyperna. -
index_columns: Anslutningsnycklarna som krävs för att komma åt värden från funktionsuppsättningen.
Om du vill veta mer om specifikationen, besök Förstå entiteter på toppnivå i hanterad funktionsbutik och CLI (v2) funktionsuppsättningens YAML-schemaresurser.
Om du bevarar specifikationen för funktionsuppsättningen finns det en annan fördel: funktionsuppsättningsspecifikationen stöder källkontroll.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)-
Registrera en funktionslagerentitet
Som bästa praxis hjälper entiteter till att framtvinga användning av samma kopplingsnyckeldefinition över funktionsuppsättningar som använder samma logiska entiteter. Exempel på entiteter är konton och kunder. Entiteter skapas vanligtvis en gång och återanvänds sedan i flera funktionsuppsättningar. Mer information finns i Förstå entiteter på toppnivå i hanterad funktionsbutik.
Initiera CRUD-klienten för funktionsarkivet.
Som vi beskrev tidigare i den här självstudien
MLClientanvänds för att skapa, läsa, uppdatera och ta bort en funktionslagertillgång. Exemplet på notebook-kodcellen som visas här söker efter funktionsarkivet som du skapade i ett tidigare steg. Här kan du inte återanvända sammaml_clientvärde som du använde tidigare i den här självstudien eftersom det värdet är begränsat på resursgruppsnivå. Korrekt omfång är en förutsättning för att skapa funktionsarkivet.I det här kodexemplet är klienten begränsad på funktionslagringsnivå.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Registrera entiteten
accountmed funktionsarkivet.Skapa en entitet
accountsom har kopplingsnyckelnaccountIDav typenstring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
Registrera uppsättningen av transaktionsfunktioner med funktionlagret
Använd den här koden för att registrera en tillgång i funktionlagret. Du kan sedan återanvända den tillgången och enkelt dela den. Registrering av en funktionsuppsättning tillhandahåller hanterade funktioner, inklusive versionshantering och materialisering. Senare steg i den här självstudieserien beskriver hanterade funktioner.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Utforska användargränssnittet för funktionbutiken
Skapande och uppdateringar av funktionsarkivets tillgångar kan endast ske via SDK och CLI. Du kan använda användargränssnittet för att söka eller bläddra i funktionsarkivet:
- Öppna den globala landningssidan för Azure Machine Learning.
- Välj Feature stores i det vänstra fönstret.
- I listan över tillgängliga funktionslager väljer du det funktionslager som du skapade tidigare i denna handledning.
Bevilja rollen Storage Blob Data Reader tillgång till ditt användarkonto i offline-lagret.
Rollen Storage Blob Data Reader måste tilldelas till ditt användarkonto i offlinearkivet. Detta säkerställer att användarkontot kan läsa materialiserade egenskapsdata från materialiseringslagret offline.
Hämta ditt Microsoft Entra-objekt-ID från Azure Portal enligt beskrivningen i Hitta användarobjektets ID.
Hämta information om offline-lagret från Feature Store Översikt-sidan i användargränssnittet för Feature Store. Du hittar värdena för lagringskontots prenumerations-ID, resursgruppsnamn för lagringskonto och lagringskontonamn för Offline materialiseringsbutik i Offline materialiseringsbutik-kortet.

Mer information om åtkomstkontroll finns i Hantera åtkomstkontroll för hanterad funktionsbutik resurs.
Kör den här kodcellen för rolltilldelning. Behörigheterna kan behöva lite tid för att spridas.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Generera en dataram för träning med hjälp av den registrerade funktionsuppsättningen
Läs in observationsdata.
Observationsdata omfattar vanligtvis de kärndata som används för träning och slutsatsdragning. Dessa data kopplas till funktionsdata för att skapa den fullständiga träningsdataresursen.
Observationsdata är data som samlas in under själva händelsen. Här finns grundläggande transaktionsdata, inklusive transaktions-ID, konto-ID och transaktionsbeloppsvärden. Eftersom du använder den för träning har den också en bifogad målvariabel (is_fraud).
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueHämta den registrerade funktionsuppsättningen och visa en lista över dess funktioner.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Välj de funktioner som blir en del av träningsdata. Använd sedan SDK:et för feature store för att generera träningsdata.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueEn tidsbaserad sammanfogning sammanfogar funktioner med träningsdata.
Aktivera offlinematerialisering på funktionsuppsättningen transactions
När materialisering av funktionsuppsättningar har aktiverats kan du utföra en återfyllnad. Du kan också schemalägga återkommande materialiseringsjobb. Mer information finns i den tredje lektionen i serien.
Ange spark.sql.shuffle.partitions i yaml-filen enligt funktionens datastorlek
Spark-konfigurationen spark.sql.shuffle.partitions är en VALFRI parameter som kan påverka antalet parquet-filer som genereras (per dag) när funktionsuppsättningen materialiseras i offline-lagret. Standardvärdet för den här parametern är 200. Som bästa praxis bör du undvika att generera många små parquetfiler. Om hämtningen av offlinefunktioner blir långsam efter materialisering av funktionsuppsättningar går du till motsvarande mapp i offlinearkivet för att kontrollera om problemet omfattar för många små parquet-filer (per dag) och justerar värdet för den här parametern i enlighet med detta.
Anmärkning
Exempeldata som används i den här notebook-filen är små. Därför är den här parametern inställd på 1 i filen featureset_asset_offline_enabled.yaml.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())Du kan också spara funktionstillgångsuppsättningen som en YAML-resurs.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Återfyllnadsdata för funktionssetet transactions
Som vi förklarade tidigare beräknar materialiseringen funktionsvärdena för ett funktionsfönster och lagrar dessa beräknade värden i ett materialiseringslager. Funktionsmaterialisering ökar tillförlitligheten och tillgängligheten för de beräknade värdena. Alla funktionsförfrågningar använder nu värdena från materialiseringslagret. Det här steget utför en engångsåterfyllnad för ett funktionsfönster på 18 månader.
Anmärkning
Du kan behöva fastställa ett ifyllningsdatafönstervärde. Fönstret måste matcha fönstret för dina träningsdata. Om du till exempel vill använda 18 månaders data för träning måste du hämta funktioner i 18 månader. Det innebär att du bör fylla på igen för ett 18-månadersfönster.
Den här kodcellen materialiserar data efter aktuell status Ingen eller Ofullständig för det definierade funktionsfönstret.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Dricks
- Kolumnen
timestampbör följayyyy-MM-ddTHH:mm:ss.fffZformatet. - Kornigheten
feature_window_start_timeochfeature_window_end_timeär begränsad till sekunder. Alla millisekunder som anges idatetimeobjektet ignoreras. - Ett materialiseringsjobb skickas endast om data i funktionsfönstret matchar det
data_statussom definieras när du skickar återfyllnadsjobbet.
Skriv ut exempeldata från funktionsuppsättningen. Utdatainformationen visar att data hämtades från materialiseringslagret. Metoden get_offline_features() hämtade tränings- och slutsatsdragningsdata. Den använder också materialiseringsarkivet som standard.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Utforska ytterligare materialisering av offlinefunktioner
Du kan utforska funktionsmaterialiseringsstatus för en funktionsuppsättning i användargränssnittet för materialiseringsjobb .
Öppna den globala landningssidan för Azure Machine Learning.
Välj Feature stores i det vänstra fönstret.
I listan över tillgängliga funktionslager väljer du det funktionsarkiv som du utförde återfyllnad för.
Välj fliken Materialiseringsjobb .
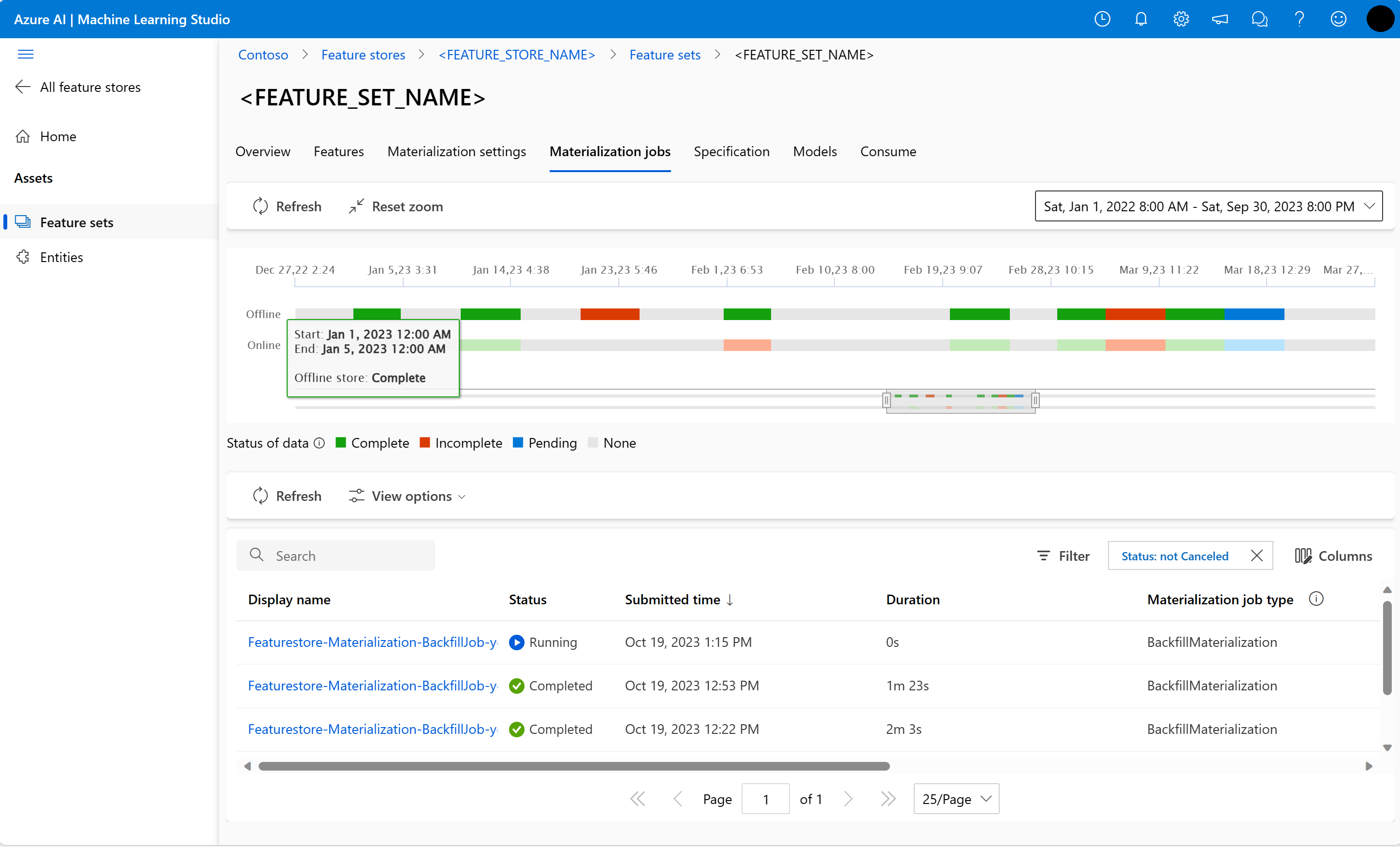

Datamaterialiseringsstatus kan vara
- Komplett (grön)
- Ofullständig (röd)
- Väntar (blå)
- Ingen (grå)
Ett dataintervall representerar en sammanhängande del av data med samma datamaterialiseringsstatus. Den tidigare ögonblicksbilden har till exempel 16 dataintervall i offline-materialiseringsarkivet.
Data kan ha högst 2 000 dataintervall. Om dina data innehåller mer än 2 000 dataintervall skapar du en ny funktionsuppsättningsversion.
Du kan ange en lista över fler än en datastatus (till exempel
["None", "Incomplete"]) i ett enda återfyllnadsjobb.Under återfyllnad skickas ett nytt materialiseringsjobb för varje dataintervall som ingår i det definierade funktionsfönstret.
Om ett materialiseringsjobb väntar, eller om jobbet körs för ett dataintervall som ännu inte har återfyllts, så skickas inget nytt jobb för det dataintervall.
Du kan köra om ett materialiseringsjobb som misslyckats.
Anmärkning
Så här hämtar du jobb-ID för ett misslyckat materialiseringsjobb:
- Gå till funktionsuppsättningen Användargränssnitt för materialiseringsjobb .
- Välj visningsnamnet för ett specifikt jobb med statusenMisslyckades.
- Leta upp jobb-ID:t under egenskapen Namn på sidan Översikt för jobbet. Det börjar med
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Uppdatering av offline-materialiseringslagring
- Om en lagringsplats för materialisering offline måste uppdateras på funktionslagernivå bör alla funktionsuppsättningar i funktionslagret ha offline-materialisering avaktiverad.
- Om offlinematerialisering inaktiveras för en funktionsuppsättning återställs statusen för materialiseringen av data som redan har materialiserats i offlinematerialiseringslagret. Återställningen gör data som redan är materialiserade oanvändbar. Du måste skicka materialiseringsjobb igen när offline-materialisering har aktiverats.
I den här självstudien skapades träningsdata med funktioner från funktionsarkivet, aktiverade materialisering till ett offline-funktionsarkiv och utförde en tillbakafyllning. Nu ska du köra modellträning med hjälp av de här funktionerna.
Rensa
Den femte handledningen i serien beskriver hur du tar bort resurserna.
Nästa steg
- Se nästa självstudie i serien: Experimentera och träna modeller med hjälp av funktioner.
- Lär dig mer om koncept för funktionell datalagring och primära entiteter i hanterad funktionell datalagring.
- Läs mer om identitets- och åtkomstkontroll för hanterad funktionstjänst.
- Visa felsökningsguiden för hanterad funktionstjänst.
- Visa YAML-referensen.