Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Kommentar
En självstudiekurs som använder SDK v1 för att skapa en pipeline finns i Självstudie: Skapa en Azure Machine Learning-pipeline för bildklassificering.
En maskininlärningspipeline delar upp en fullständig maskininlärningsuppgift i ett arbetsflöde med flera steg. Varje steg är en hanterbar komponent som du kan utveckla, optimera, konfigurera och automatisera individuellt. Väldefinierade gränssnitt ansluter processsteg. Azure Machine Learning-pipelinetjänsten samordnar alla beroenden mellan pipelinestegen.
Fördelarna med att använda en pipeline är standardiserad MLOps-praxis, skalbart teamsamarbete, träningseffektivitet och kostnadsminskning. Mer information om fördelarna med pipelines finns i Vad är Azure Machine Learning-pipelines?
I den här självstudien använder du Azure Machine Learning för att skapa ett produktionsklart maskininlärningsprojekt med Hjälp av Azure Machine Learning Python SDK v2. Efter den här självstudien kan du använda Azure Machine Learning Python SDK för att:
- Få ett handtag till din Azure Machine Learning-arbetsyta
- Skapa Azure Machine Learning-datatillgångar
- Skapa återanvändbara Azure Machine Learning-komponenter
- Skapa, verifiera och köra Azure Machine Learning-pipelines
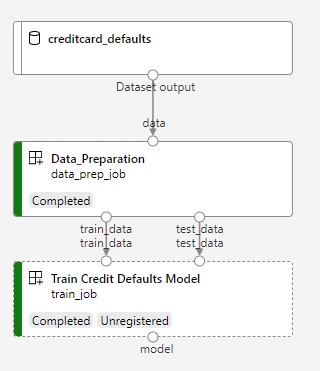
Under den här självstudien skapar du en Azure Machine Learning-pipeline för att träna en modell för kreditstandardförutsägelse. Pipelinen hanterar två steg:
- Dataförberedelse
- Träna och registrera den tränade modellen
Nästa bild visar en enkel pipeline som du ser i Azure Studio när du har skickat den.
De två stegen är förberedelse och träning av data.
Den här videon visar hur du kommer igång i Azure Machine Learning-studio så att du kan följa stegen i självstudien. Videon visar hur du skapar en notebook-fil, skapar en beräkningsinstans och klonar notebook-filen. I följande avsnitt beskrivs även de här stegen.
Förutsättningar
-
Om du vill använda Azure Machine Learning behöver du en arbetsyta. Om du inte har någon slutför du Skapa resurser som du behöver för att komma igång med att skapa en arbetsyta och lära dig mer om hur du använder den.
Viktigt!
Om din Azure Machine Learning-arbetsyta har konfigurerats med ett hanterat virtuellt nätverk kan du behöva lägga till regler för utgående trafik för att tillåta åtkomst till de offentliga Python-paketlagringsplatserna. Mer information finns i Scenario: Åtkomst till offentliga maskininlärningspaket.
-
Logga in i studion och välj din arbetsyta om den inte redan är öppen.
Slutför självstudien Ladda upp, få åtkomst till och utforska dina data för att skapa den datatillgång du behöver i den här självstudien. Se till att du kör all kod för att skapa den första datatillgången. Du kan utforska data och ändra dem om du vill, men du behöver bara inledande data för den här handledningen.
-
Öppna eller skapa en notebook-fil på din arbetsyta:
- Om du vill kopiera och klistra in kod i celler skapar du en ny notebook-fil.
- Eller öppna självstudier/komma igång-notebooks/pipeline.ipynb från avsnittet Exempel i Studio. Välj sedan Klona för att lägga till anteckningsboken i dina filer. Information om hur du hittar exempelanteckningsböcker finns i Learn from sample notebooks (Lär dig från exempelanteckningsböcker).
Ange kerneln och öppna i Visual Studio Code (VS Code)
I det övre fältet ovanför den öppnade notebook-filen skapar du en beräkningsinstans om du inte redan har en.

Om beräkningsinstansen har stoppats väljer du Starta beräkning och väntar tills den körs.

Vänta tills beräkningsinstansen körs. Kontrollera sedan att kerneln, som finns längst upp till höger, är
Python 3.10 - SDK v2. Annars använder du listrutan för att välja den här kerneln.
Om du inte ser den här kerneln kontrollerar du att beräkningsinstansen körs. I så fall väljer du knappen Uppdatera längst upp till höger i anteckningsboken.
Om du ser en banderoll som säger att du måste autentiseras väljer du Autentisera.
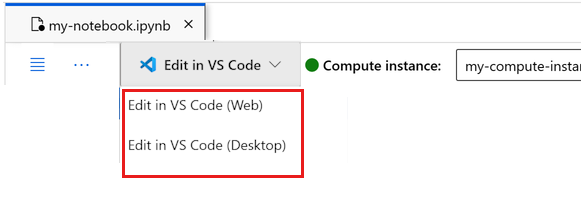
Du kan köra notebook-filen här eller öppna den i VS Code för en fullständig integrerad utvecklingsmiljö (IDE) med kraften i Azure Machine Learning-resurser. Välj Öppna i VS Code och välj sedan antingen webb- eller skrivbordsalternativet. När du startar på det här sättet kopplas VS Code till beräkningsinstansen, kerneln och arbetsytans filsystem.




Viktigt!
Resten av den här självstudien innehåller celler i notebook-filen för självstudien. Kopiera och klistra in dem i den nya anteckningsboken eller växla till anteckningsboken nu om du klonade den.
Konfigurera pipelineresurserna
Du kan använda Azure Machine Learning-ramverket från Azure CLI, Python SDK eller studiogränssnittet. I det här exemplet använder du Azure Machine Learning Python SDK v2 för att skapa en pipeline.
Innan du skapar pipelinen behöver du följande resurser:
- Datatillgången för träning
- Programvarumiljön för att köra pipelinen
- En beräkningsresurs där jobbet körs
Skapa handtag till arbetsyta
Innan du använder koden behöver du ett sätt att referera till din arbetsyta. Skapa ml_client som ett handtag till arbetsytan. Du använder ml_client sedan för att hantera resurser och jobb.
I nästa cell anger du ditt prenumerations-ID, resursgruppsnamn och arbetsytenamn. Så här hittar du följande värden:
- I det övre högra Azure Machine Learning-studio verktygsfältet väljer du namnet på arbetsytan.
- Kopiera värdet för arbetsyta, resursgrupp och prenumerations-ID till koden. Du måste kopiera ett värde, stänga området och klistra in och sedan returnera för nästa värde.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
SDK-referens:
Kommentar
Skapandet av MLClient innebär inte anslutning till arbetsytan. Klientinitiering är lat. Den väntar tills det första gången den behöver göra ett anrop. Initieringen sker i nästa kodcell.
Verifiera anslutningen genom att ringa ett anrop till ml_client. Eftersom det här anropet är första gången du anropar arbetsytan kan du bli ombedd att autentisera.
# Verify that the handle works correctly.
# If you get an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
SDK-referens:
Få åtkomst till den registrerade datatillgången
Börja med att hämta de data som du tidigare registrerade i Självstudie: Ladda upp, komma åt och utforska dina data i Azure Machine Learning.
Kommentar
Azure Machine Learning använder ett Data objekt för att registrera en återanvändbar definition av data och använda data i en pipeline.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
SDK-referens:
Skapa en jobbmiljö för pipelinesteg
Hittills har du skapat en utvecklingsmiljö på beräkningsinstansen, utvecklingsdatorn. Du behöver också en miljö att använda för varje steg i pipelinen. Varje steg kan ha en egen miljö, eller så kan du använda några vanliga miljöer för flera steg.
I det här exemplet skapar du en conda-miljö för dina jobb med hjälp av en conda yaml-fil. Skapa först en katalog som filen ska lagras i.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Skapa nu filen i katalogen beroenden.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.10
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
Specifikationen innehåller några vanliga paket som du använder i din pipeline (numpy, pip), tillsammans med några Azure Machine Learning-specifika paket (azureml-mlflow).
Azure Machine Learning-paketen krävs inte för att köra Azure Machine Learning-jobb. Genom att lägga till dessa paket kan du interagera med Azure Machine Learning för att logga mått och registrera modeller, allt i Azure Machine Learning-jobbet. Du använder dem i träningsskriptet senare i den här självstudien.
Använd yaml-filen för att skapa och registrera den här anpassade miljön på din arbetsyta:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
SDK-referens:
Skapa träningspipelinen
Nu när du har alla tillgångar som krävs för att köra pipelinen är det dags att skapa själva pipelinen.
Azure Machine Learning-pipelines är återanvändbara ML-arbetsflöden som vanligtvis består av flera komponenter. Den typiska livscykeln för en komponent är:
- Skriv YAML-specifikationen för komponenten eller skapa den programmatiskt med hjälp
ComponentMethodav . - Du kan också registrera komponenten med ett namn och en version på din arbetsyta för att göra den återanvändbar och delbar.
- Läs in komponenten från pipelinekoden.
- Implementera pipelinen med hjälp av komponentens indata, utdata och parametrar.
- Skicka pipelinen.
Du kan skapa en komponent på två sätt: programmatisk definition och YAML-definition. De kommande två avsnitten beskriver hur du skapar en komponent åt båda hållen. Du kan antingen skapa de två komponenterna genom att prova båda alternativen eller välja önskad metod.
Kommentar
I den här självstudien använder du för enkelhetens skull samma beräkning för alla komponenter. Du kan dock ange olika beräkningar för varje komponent. Du kan till exempel lägga till en rad som train_step.compute = "cpu-cluster". Ett exempel på hur du skapar en pipeline med olika beräkningar för varje komponent finns i avsnittet Grundläggande pipelinejobb i självstudien om cifar-10-pipeline.
Skapa komponent 1: dataförberedelse (med programmeringsdefinition)
Börja med att skapa den första komponenten. Den här komponenten hanterar förbearbetningen av data. Förbearbetningsuppgiften utförs i data_prep.py Python-filen.
Skapa först en källmapp för komponenten data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Det här skriptet utför den enkla uppgiften att dela upp data i tränings- och testdatauppsättningar. Azure Machine Learning monterar datauppsättningar som mappar till beräkningarna. Du har skapat en extra select_first_file funktion för att komma åt datafilen i den monterade indatamappen.
MLFlow används för att logga parametrarna och måtten under pipelinekörningen.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Nu när du har ett skript som kan utföra den önskade uppgiften skapar du en Azure Machine Learning-komponent från den.
Använd det allmänna syftet CommandComponent som kan köra kommandoradsåtgärder. Den här kommandoradsåtgärden kan anropa systemkommandon direkt eller köra ett skript. Indata och utdata anges på kommandoraden med hjälp av notationen ${{ ... }} .
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
SDK-referens:
Du kan också registrera komponenten på arbetsytan för framtida återanvändning.
# Now register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create and register the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
SDK-referens:
Skapa komponent 2: träning (med yaml-definition)
Den andra komponenten som du skapar använder tränings- och testdata, tränar en trädbaserad modell och returnerar utdatamodellen. Använd Azure Machine Learning-loggningsfunktioner för att registrera och visualisera inlärningsframvägen.
Du använde CommandComponent klassen för att skapa din första komponent. Den här gången använder du yaml-definitionen för att definiera den andra komponenten. Varje metod har sina egna fördelar. En yaml-definition kan checkas in längs koden och ger läsbar historikspårning. Den programmatiska metoden som använder CommandComponent kan vara enklare med inbyggd klassdokumentation och kodkomplettering.
Skapa katalogen för den här komponenten:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Skapa träningsskriptet i katalogen:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Som du ser i det här träningsskriptet sparas modellfilen och registreras på arbetsytan när modellen har tränats. Nu kan du använda den registrerade modellen i slutsatsdragningsslutpunkter.
För miljön i det här steget använder du en av de inbyggda (utvalda) Azure Machine Learning-miljöerna. Taggen azureml instruerar systemet att söka efter namnet i utvalda miljöer.
Skapa först yaml-filen som beskriver komponenten:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Skapa och registrera komponenten nu. Genom att registrera den kan du återanvända den i andra pipelines. Alla andra som har åtkomst till din arbetsyta kan också använda den registrerade komponenten.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create and register the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
SDK-referens:
Skapa pipelinen från komponenter
När du har definierat och registrerat dina komponenter börjar du implementera pipelinen.
Python-funktioner som load_component() returnerar fungerar som alla vanliga Python-funktioner. Använd dem i en pipeline för att anropa varje etapp.
Om du vill koda pipelinen använder du en specifik @dsl.pipeline dekoratör som identifierar Azure Machine Learning-pipelines. I dekoratören anger du pipelinebeskrivningen och standardresurser som beräkning och lagring. Precis som en Python-funktion kan pipelines ha indata. Du kan skapa flera instanser av en enda pipeline med olika indata.
I följande exempel använder du indata, delat förhållande och registrerat modellnamn som indatavariabler. Anropa sedan komponenterna och anslut dem med hjälp av deras indata och utdataidentifierare. Få åtkomst till utdata för varje steg med hjälp av .outputs-egenskapen.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
SDK-referens:
Använd nu din pipelinedefinition för att instansiera en pipeline med din datauppsättning, delningshastighet och det namn som du valde för din modell.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
SDK-referens:
Skicka jobbet
Skicka nu jobbet som ska köras i Azure Machine Learning. Använd den här gången create_or_update på ml_client.jobs.
Ange ett experimentnamn. Ett experiment är en container för alla iterationer man gör i ett visst projekt. Alla jobb som skickas under samma experimentnamn visas bredvid varandra i Azure Machine Learning Studio.
När den är klar registrerar pipelinen en modell på din arbetsyta som ett resultat av träningen.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
SDK-referens:
Du kan spåra förloppet för din pipeline med hjälp av länken som genererades i föregående cell. När du först klickar på den här länken kan du se att pipelinen fortfarande körs. När den är klar kan du undersöka varje komponents resultat.
Dubbelklicka på komponenten Träna kreditstandardmodell .
Två viktiga resultat som du vill se om träning:
Visa loggarna:
- Välj fliken Utdata+loggar .
- Öppna mapparna i
user_logs>std_log.txtDet här avsnittet visar skriptkörningen stdout.
Visa dina mått: Välj fliken Mått . Det här avsnittet visar olika loggade mått. I det här exemplet loggar mlflow
autologgingautomatiskt träningsmåtten.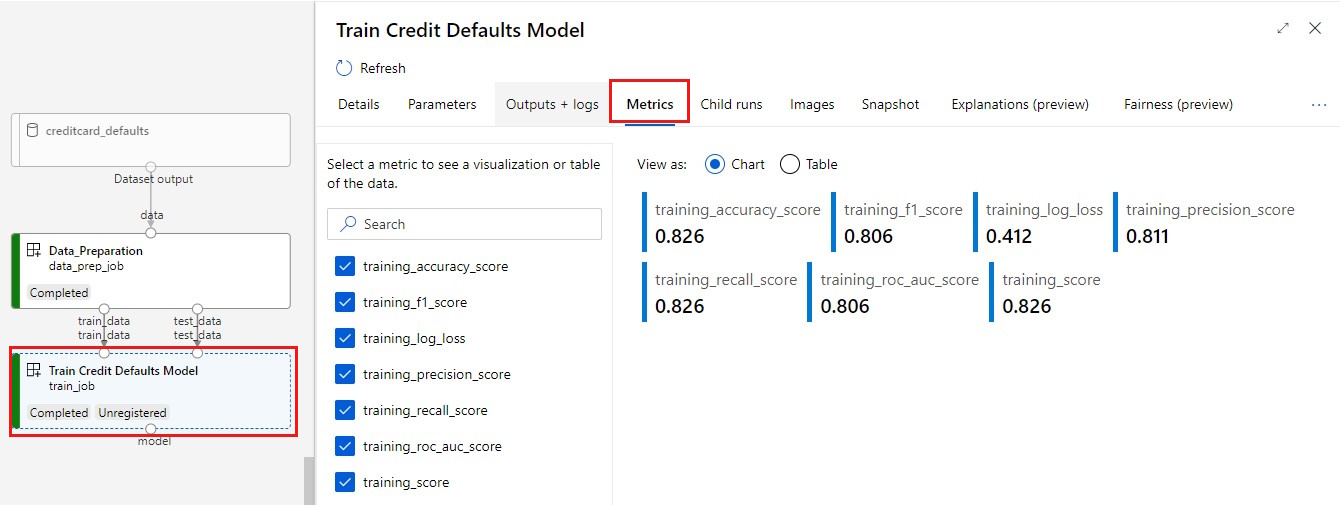


Distribuera modellen som en onlineslutpunkt
Mer information om hur du distribuerar din modell till en onlineslutpunkt finns i Självstudien Distribuera en modell som en onlineslutpunkt.
Rensa resurser
Om du planerar att fortsätta med andra handledningar, gå vidare till Nästa steg.
Stoppa beräkningsinstans
Om du inte ska använda beräkningsinstansen nu stoppar du den:
- I studiofönstret till vänster väljer du Beräkning.
- På de översta flikarna väljer du Beräkningsinstanser.
- Välj beräkningsinstansen i listan.
- I det övre verktygsfältet väljer du Stoppa.
Ta bort alla resurser
Viktigt!
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter:
I Azure Portal i sökrutan anger du Resursgrupper och väljer dem i resultatet.
I listan väljer du den resursgrupp som du skapade.
På sidan Översikt väljer du Ta bort resursgrupp.
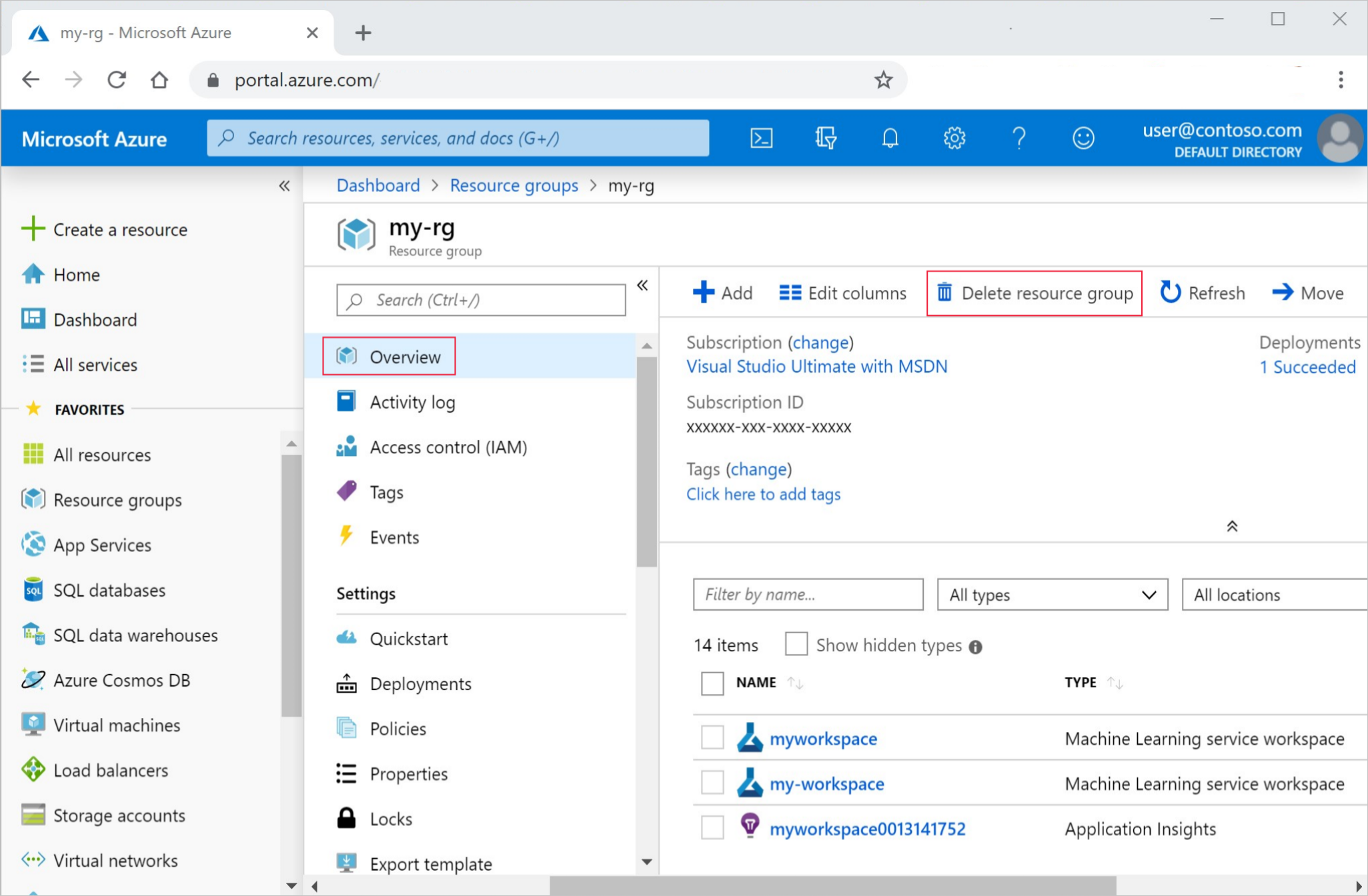
Ange resursgruppsnamnet. Välj sedan ta bort.