Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Lär dig hur du distribuerar en modell till en onlineslutpunkt med Hjälp av Azure Machine Learning Python SDK v2.
I den här självstudien distribuerar och använder du en modell som förutsäger sannolikheten för att en kund försummar en kreditkortsbetalning.
De steg du utför är:
- Registrera din modell
- Skapa en slutpunkt och en första distribution
- Distribuera en utvärderingskörning
- Skicka testdata manuellt till distributionen
- Hämta information om distributionen
- Skapa en andra distribution
- Skala den andra distributionen manuellt
- Uppdatera allokering av produktionstrafik mellan båda distributionerna
- Få information om den andra distributionen
- Distribuera den nya distributionen och ta bort den första
Den här videon visar hur du kommer igång i Azure Machine Learning Studio så att du kan följa stegen i självstudien. Videon visar hur du skapar en notebook-fil, skapar en beräkningsinstans och klonar notebook-filen. Stegen beskrivs också i följande avsnitt.
Förutsättningar
-
Om du vill använda Azure Machine Learning behöver du en arbetsyta. Om du inte har någon slutför du Skapa resurser som du behöver för att komma igång med att skapa en arbetsyta och lära dig mer om hur du använder den.
Viktigt!
Om din Azure Machine Learning-arbetsyta har konfigurerats med ett hanterat virtuellt nätverk kan du behöva lägga till regler för utgående trafik för att tillåta åtkomst till de offentliga Python-paketlagringsplatserna. Mer information finns i Scenario: Åtkomst till offentliga maskininlärningspaket.
-
Logga in i studion och välj din arbetsyta om den inte redan är öppen.
-
Öppna eller skapa en notebook-fil på din arbetsyta:
- Om du vill kopiera och klistra in kod i celler skapar du en ny notebook-fil.
- Eller öppna självstudier/komma igång-notebooks/deploy-model.ipynb från avsnittet Exempel i studion. Välj sedan Klona för att lägga till anteckningsboken i dina filer. Information om hur du hittar exempelanteckningsböcker finns i Learn from sample notebooks (Lär dig från exempelanteckningsböcker).
Visa din VM-kvot och se till att du har tillräckligt med kvot för att skapa onlinedistributioner. I den här självstudien behöver du minst 8 kärnor av
STANDARD_DS3_v2och 12 kärnor iSTANDARD_F4s_v2. Information om hur du visar din användning av vm-kvoter och ökningar av begärandekvoter finns i Hantera resurskvoter.
Ange kerneln och öppna i Visual Studio Code (VS Code)
I det övre fältet ovanför den öppnade notebook-filen skapar du en beräkningsinstans om du inte redan har en.

Om beräkningsinstansen har stoppats väljer du Starta beräkning och väntar tills den körs.

Vänta tills beräkningsinstansen körs. Kontrollera sedan att kerneln, som finns längst upp till höger, är
Python 3.10 - SDK v2. Annars använder du listrutan för att välja den här kerneln.
Om du inte ser den här kerneln kontrollerar du att beräkningsinstansen körs. I så fall väljer du knappen Uppdatera längst upp till höger i anteckningsboken.
Om du ser en banderoll som säger att du måste autentiseras väljer du Autentisera.
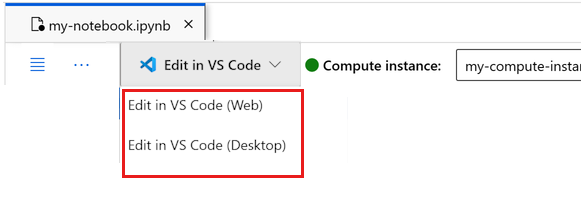
Du kan köra notebook-filen här eller öppna den i VS Code för en fullständig integrerad utvecklingsmiljö (IDE) med kraften i Azure Machine Learning-resurser. Välj Öppna i VS Code och välj sedan antingen webb- eller skrivbordsalternativet. När du startar på det här sättet kopplas VS Code till beräkningsinstansen, kerneln och arbetsytans filsystem.




Viktigt!
Resten av den här självstudien innehåller celler i notebook-filen för självstudien. Kopiera och klistra in dem i den nya anteckningsboken eller växla till anteckningsboken nu om du klonade den.
Kommentar
Serverlös Spark Compute har Python 3.10 - SDK v2 inte installerats som standard. Vi rekommenderar att du skapar en beräkningsinstans och väljer den innan du fortsätter med självstudien.
Skapa handtag till arbetsyta
Innan du går in på koden behöver du ett sätt att referera till din arbetsyta. Skapa ml_client för en referens till arbetsytan och använd ml_client för att hantera resurser och jobb.
I nästa cell anger du ditt prenumerations-ID, resursgruppsnamn och arbetsytenamn. Så här hittar du följande värden:
- I det övre högra Azure Machine Learning-studio verktygsfältet väljer du namnet på arbetsytan.
- Kopiera värdet för arbetsyta, resursgrupp och prenumerations-ID till koden.
- Du måste kopiera ett värde, stänga området, klistra in och sedan komma tillbaka för nästa.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Kommentar
Att skapa MLClient ansluter inte till arbetsytan. Klientinitiering är lat och väntar för första gången den behöver göra ett anrop (detta händer i nästa kodcell).
Registrera modellen
Om du redan har slutfört den tidigare utbildningskursen, Träna en modell, har du registrerat en MLflow-modell som en del av träningsskriptet och kan gå vidare till nästa avsnitt.
Om du inte har slutfört träningsguiden måste du registrera modellen. Att registrera din modell före distributionen är en rekommenderad metod.
Följande kod anger ( path var du laddar upp filer från) infogade. Om du klonade mappen tutorials kör du följande kod as-is. Annars laddar du ned filer och metadata för modellen från mappen credit_defaults_model. Spara filerna som du laddade ned till en lokal version av mappen credit_defaults_model på datorn och uppdatera sökvägen i följande kod till platsen för de nedladdade filerna.
SDK:et laddar automatiskt upp filerna och registrerar modellen.
Mer information om hur du registrerar din modell som en tillgång finns i Registrera din modell som en tillgång i Machine Learning med hjälp av SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Bekräfta att modellen är registrerad
Du kan kontrollera sidan Modeller i Azure Machine Learning-studio för att identifiera den senaste versionen av den registrerade modellen.
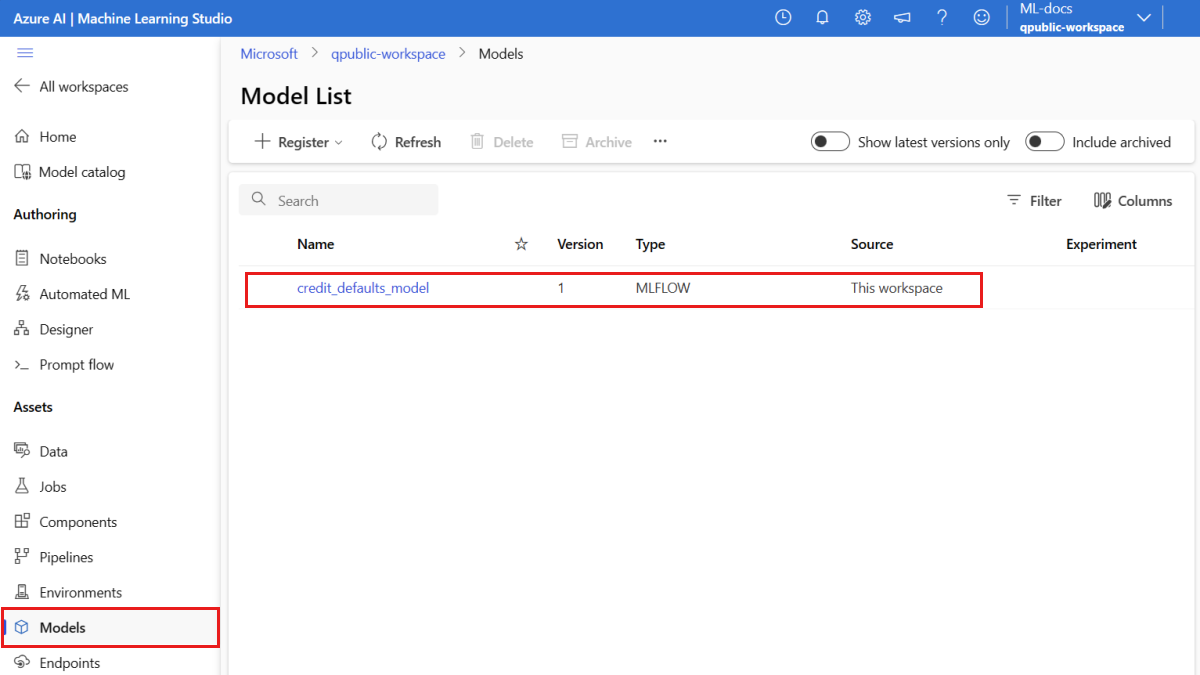
Alternativt hämtar följande kod det senaste versionsnumret som du kan använda.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Nu när du har en registrerad modell kan du skapa en slutpunkt och distribution. I nästa avsnitt beskrivs kortfattat några viktiga detaljer om dessa ämnen.
Slutpunkter och distributioner
När du har tränat en maskininlärningsmodell måste du distribuera den så att andra kan använda den för slutsatsdragning. I det här syftet kan du med Azure Machine Learning skapa slutpunkter och lägga till distributioner till dem.
En slutpunkt i den här kontexten är en HTTPS-sökväg som tillhandahåller ett gränssnitt för klienter för att skicka begäranden (indata) till en tränad modell och ta emot resultatet av inferensen (bedömning) från modellen. En slutpunkt innehåller:
- Autentisering med hjälp av "nyckel- eller tokenbaserad autentisering"
- TLS-avslutning (SSL)
- En stabil bedömnings-URI (endpoint-name.region.inference.ml.azure.com)
En distribution är en uppsättning resurser som krävs för att vara värd för den modell som utför den faktiska inferensen.
En enskild slutpunkt kan innehålla flera distributioner. Slutpunkter och distributioner är oberoende Azure Resource Manager-resurser som visas i Azure Portal.
Med Azure Machine Learning kan du implementera onlineslutpunkter för realtidsinferens för klientdata och batchslutpunkter för slutsatsdragning av stora datavolymer under en tidsperiod.
I den här självstudien går du igenom stegen för att implementera en hanterad onlineslutpunkt. Hanterade onlineslutpunkter fungerar med kraftfulla PROCESSOR- och GPU-datorer i Azure på ett skalbart, fullständigt hanterat sätt som frigör dig från kostnaderna för att konfigurera och hantera den underliggande distributionsinfrastrukturen.
Skapa en onlineslutpunkt
Nu när du har en registrerad modell är det dags att skapa din onlineslutpunkt. Slutpunktsnamnet måste vara unikt i hela Azure-regionen. I den här självstudien skapar du ett unikt namn med hjälp av en universellt unik identifierare UUID. Mer information om namngivningsregler för slutpunkter finns i slutpunktsgränser.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Definiera först slutpunkten med hjälp av ManagedOnlineEndpoint klassen .
Dricks
auth_mode: Användskeyför nyckelbaserad autentisering. Användsaml_tokenför tokenbaserad autentisering i Azure Machine Learning. Akeyupphör inte att gälla, menaml_tokenupphör att gälla. Mer information om autentisering finns i Autentisera klienter för onlineslutpunkter.Du kan också lägga till en beskrivning och taggar i slutpunkten.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Skapa slutpunkten på arbetsytan med hjälp av den MLClient som skapades tidigare. Det här kommandot startar skapandet av slutpunkten och returnerar ett bekräftelsesvar medan skapandet av slutpunkten fortsätter.
Kommentar
Förvänta dig att det tar cirka 2 minuter att skapa slutpunkten.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
När du har skapat slutpunkten kan du hämta den på följande sätt:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Förstå onlinedistributioner
De viktigaste aspekterna av en distribution är:
-
name- Namnet på distributionen. -
endpoint_name– Namnet på slutpunkten som ska innehålla distributionen. -
model– Den modell som ska användas för distributionen. Det här värdet kan antingen vara en referens till en befintlig version av modellen på arbetsytan eller en infogad modellspecifikation. -
environment– Den miljö som ska användas för distributionen (eller för att köra modellen). Det här värdet kan antingen vara en referens till en befintlig version av miljön på arbetsytan eller en infogad miljöspecifikation. Miljön kan vara en Docker-avbildning med Conda-beroenden eller en Dockerfile. -
code_configuration– Konfigurationen för källkoden och bedömningsskriptet.-
path– Sökväg till källkodskatalogen för bedömning av modellen. -
scoring_script– Relativ sökväg till bedömningsfilen i källkodskatalogen. Det här skriptet kör modellen på en angiven indatabegäran. Ett exempel på ett bedömningsskript finns i Förstå bedömningsskriptet i artikeln "Distribuera en ML-modell med en onlineslutpunkt".
-
-
instance_type– Den VM-storlek som ska användas för distributionen. Listan över storlekar som stöds finns i SKU-listan för hanterade onlineslutpunkter. -
instance_count– Antalet instanser som ska användas för distributionen.
Distribution med en MLflow-modell
Azure Machine Learning stöder distribution utan kod för en modell som skapats och loggats med MLflow. Det innebär att du inte behöver ange ett bedömningsskript eller en miljö under modelldistributionen, eftersom bedömningsskriptet och miljön genereras automatiskt när du tränar en MLflow-modell. Om du använder en anpassad modell måste du dock ange miljön och bedömningsskriptet under distributionen.
Viktigt!
Om du vanligtvis distribuerar modeller med hjälp av bedömningsskript och anpassade miljöer och vill uppnå samma funktioner med hjälp av MLflow-modeller rekommenderar vi att du läser Riktlinjer för distribution av MLflow-modeller.
Distribuera modellen till slutpunkten
Börja med att skapa en enda distribution som hanterar 100 % av den inkommande trafiken. Välj ett godtyckligt färgnamn (blått) för distributionen. Använd klassen för att skapa distributionen för slutpunkten ManagedOnlineDeployment .
Kommentar
Du behöver inte ange en miljö eller ett bedömningsskript eftersom modellen som ska distribueras är en MLflow-modell.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Skapa distributionen på arbetsytan med hjälp av det MLClient som skapades tidigare. Det här kommandot startar distributionen och returnerar ett bekräftelsesvar medan distributionsskapandet fortsätter.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Kontrollera slutpunktens status
Du kan kontrollera slutpunktens status för att se om modellen distribuerades utan fel:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Testa slutpunkten med exempeldata
Nu när modellen har distribuerats till slutpunkten kan du köra slutsatsdragning med den. Börja med att skapa en exempelbegärandefil som följer den design som förväntas i körningsmetoden som finns i bedömningsskriptet.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Skapa nu filen i distributionskatalogen. I följande kodcell används IPython-magi för att skriva filen till den katalog som du skapade.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Använd det som skapades MLClient tidigare och hämta ett handtag till slutpunkten. Du kan anropa slutpunkten med hjälp invoke av kommandot med följande parametrar:
-
endpoint_name– Slutpunktens namn -
request_file– Fil med begärandedata -
deployment_name– Namnet på den specifika distribution som ska testas i en slutpunkt
Testa den blå distributionen med exempeldata.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Hämta loggar för distributionen
Kontrollera loggarna för att se om slutpunkten eller deploymenten har anropats framgångsrikt. Om du får fel läser du Felsöka distribution av onlineslutpunkter.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Skapa en andra distribution
Distribuera modellen som en andra distribution med namnet green. I praktiken kan du skapa flera distributioner och jämföra deras prestanda. Dessa distributioner kan använda en annan version av samma modell, en annan modell eller en kraftfullare beräkningsinstans.
I det här exemplet distribuerar du samma modellversion med hjälp av en kraftfullare beräkningsinstans som potentiellt kan förbättra prestandan.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Skala distribution för att hantera mer trafik
Med hjälp av det som skapades MLClient tidigare kan du få en referens till distributionen green . Du kan sedan skala den genom att öka eller minska instance_count.
I följande kod ökar du den virtuella datorinstansen manuellt. Det är dock också möjligt att autoskala onlineslutpunkter. Med autoskalning körs automatiskt rätt mängd resurser för att hantera arbetsbelastningen i appen. Hanterade onlineslutpunkter stöder automatisk skalning genom integrering med autoskalningsfunktionen i Azure Monitor. Information om hur du konfigurerar autoskalning finns i Autoskalning av onlineslutpunkter.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Uppdatera trafikallokering för distributioner
Du kan dela upp produktionstrafik mellan distributioner. Du kanske först vill testa distributionen green med exempeldata, precis som du gjorde för distributionen blue . När du har testat den gröna distributionen allokerar du en liten procentandel trafik till den.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Testa trafikallokering genom att anropa slutpunkten flera gånger:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Visa loggar från distributionen green för att kontrollera att det fanns inkommande begäranden och att modellen har poängsatts.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Visa mått med Hjälp av Azure Monitor
Du kan visa olika mått (begärandenummer, svarstid för begäranden, nätverksbyte, cpu/GPU/disk/minne med mera) för en onlineslutpunkt och dess distributioner genom att följa länkarna från sidan Information i slutpunkten i studion. Om du följer någon av dessa länkar kommer du till den exakta måttsidan i Azure Portal för slutpunkten eller distributionen.

Om du öppnar måtten för onlineslutpunkten kan du konfigurera sidan så att den ser mått som den genomsnittliga svarstiden för begäran enligt följande bild.

Mer information om hur du visar slutpunktsmått online finns i Övervaka onlineslutpunkter.
Skicka all trafik till den nya distributionen
När du är helt nöjd med distributionen green växlar du all trafik till den.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Ta bort den gamla distributionen
Ta bort den gamla (blå) distributionen:
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Rensa resurser
Om du inte ska använda slutpunkten och distributionen när du har slutfört den här självstudien bör du ta bort dem.
Kommentar
Förvänta dig att den fullständiga borttagningen tar cirka 20 minuter.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Ta bort allt
Använd de här stegen för att ta bort din Azure Machine Learning-arbetsyta och alla beräkningsresurser.
Viktigt!
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter:
I Azure Portal i sökrutan anger du Resursgrupper och väljer dem i resultatet.
I listan väljer du den resursgrupp som du skapade.
På sidan Översikt väljer du Ta bort resursgrupp.
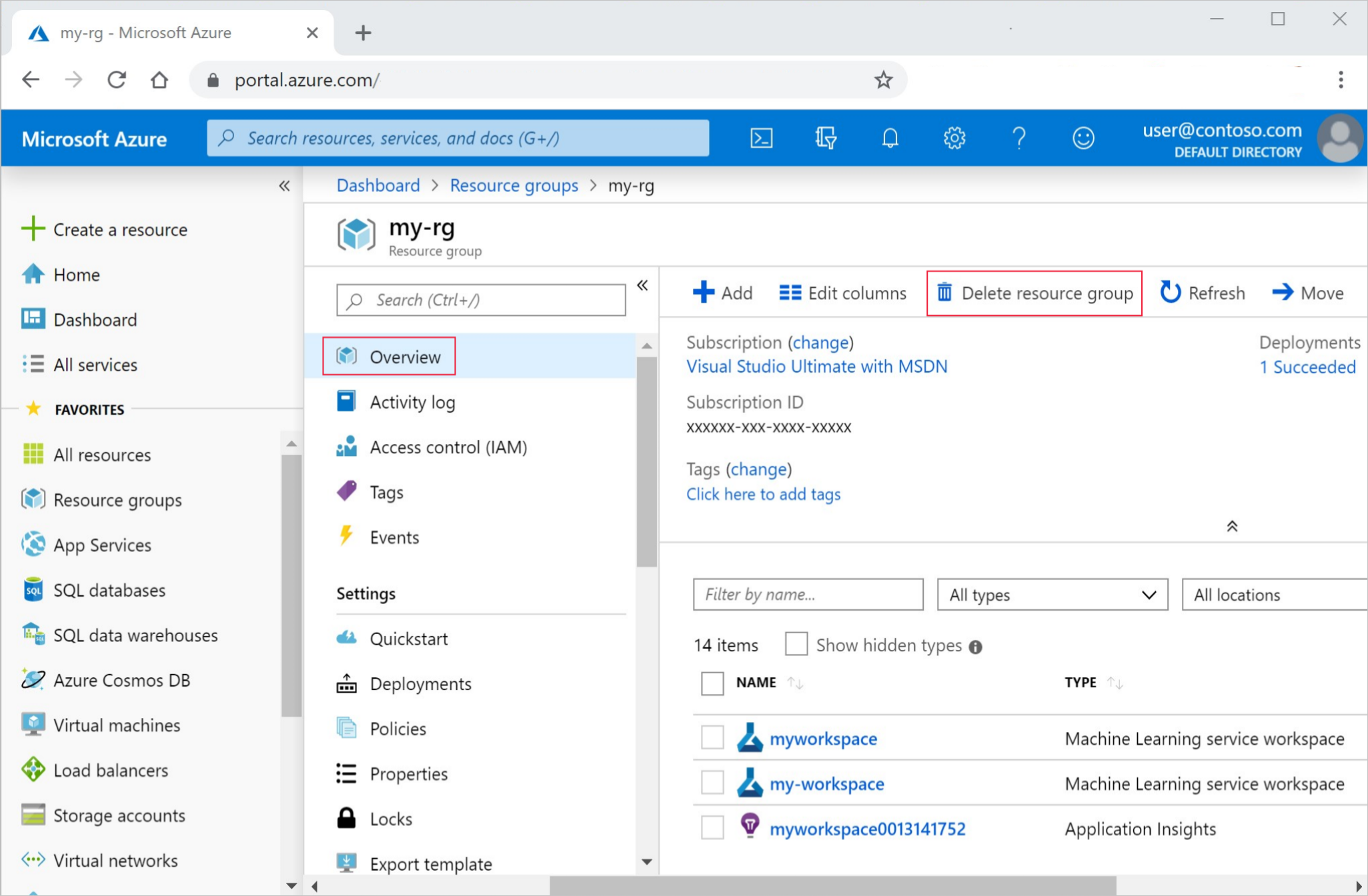
Ange resursgruppsnamnet. Välj sedan ta bort.