Självstudie: Ladda upp data och träna en modell (SDK v1, del 3 av 3)
GÄLLER FÖR: Python SDK azureml v1
Python SDK azureml v1
Den här självstudien visar hur du laddar upp och använder dina egna data för att träna maskininlärningsmodeller i Azure Machine Learning. Den här självstudien är del 3 i en självstudieserie i tre delar.
I del 2: Träna en modell tränade du en modell i molnet med hjälp av exempeldata från PyTorch. Du har också laddat ned dessa data via torchvision.datasets.CIFAR10 metoden i PyTorch-API:et. I den här självstudien använder du nedladdade data för att lära dig arbetsflödet för att arbeta med dina egna data i Azure Machine Learning.
I den här kursen får du:
- Ladda upp data till Azure.
- Skapa ett kontrollskript.
- Förstå de nya Azure Machine Learning-begreppen (skicka parametrar, datauppsättningar, datalager).
- Skicka och kör träningsskriptet.
- Visa dina kodutdata i molnet.
Förutsättningar
Du behöver de data som laddades ned i föregående självstudie. Kontrollera att du har slutfört följande steg:
Justera träningsskriptet
Nu har du ditt träningsskript (get-started/src/train.py) som körs i Azure Machine Learning och du kan övervaka modellens prestanda. Nu ska vi parametrisera träningsskriptet genom att introducera argument. Med argument kan du enkelt jämföra olika hyperparametrar.
Vårt träningsskript är för närvarande inställt på att ladda ned CIFAR10-datauppsättningen vid varje körning. Följande Python-kod har justerats för att läsa data från en katalog.
Anteckning
Användningen av argparse parameteriserar skriptet.
Öppna train.py och ersätt den med den här koden:
import os import argparse import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run run = Run.get_context() if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_path', type=str, help='Path to the training data' ) parser.add_argument( '--learning_rate', type=float, default=0.001, help='Learning rate for SGD' ) parser.add_argument( '--momentum', type=float, default=0.9, help='Momentum for SGD' ) args = parser.parse_args() print("===== DATA =====") print("DATA PATH: " + args.data_path) print("LIST FILES IN DATA PATH...") print(os.listdir(args.data_path)) print("================") # prepare DataLoader for CIFAR10 data transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) trainset = torchvision.datasets.CIFAR10( root=args.data_path, train=True, download=False, transform=transform, ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD( net.parameters(), lr=args.learning_rate, momentum=args.momentum, ) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 run.log('loss', loss) # log loss metric to AML print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Spara filen. Stäng fliken om du vill.
Förstå kodändringarna
Koden i train.py har använt argparse biblioteket för att konfigurera data_path, learning_rateoch momentum.
# .... other code
parser = argparse.ArgumentParser()
parser.add_argument('--data_path', type=str, help='Path to the training data')
parser.add_argument('--learning_rate', type=float, default=0.001, help='Learning rate for SGD')
parser.add_argument('--momentum', type=float, default=0.9, help='Momentum for SGD')
args = parser.parse_args()
# ... other code
Skriptet train.py har också anpassats för att uppdatera optimeringen så att den använder de användardefinierade parametrarna:
optimizer = optim.SGD(
net.parameters(),
lr=args.learning_rate, # get learning rate from command-line argument
momentum=args.momentum, # get momentum from command-line argument
)
Ladda upp data till Azure
Om du vill köra det här skriptet i Azure Machine Learning måste du göra dina träningsdata tillgängliga i Azure. Din Azure Machine Learning-arbetsyta är utrustad med ett standarddatalager . Det här är ett Azure Blob Storage konto där du kan lagra dina träningsdata.
Anteckning
Med Azure Machine Learning kan du ansluta andra molnbaserade datalager som lagrar dina data. Mer information finns i dokumentationen om datalager.
Skapa ett nytt Python-kontrollskript i kom igång-mappen (kontrollera att det är i komma igång, inte i mappen /src ). Namnge skriptet upload-data.py och kopiera koden till filen:
# upload-data.py from azureml.core import Workspace from azureml.core import Dataset from azureml.data.datapath import DataPath ws = Workspace.from_config() datastore = ws.get_default_datastore() Dataset.File.upload_directory(src_dir='data', target=DataPath(datastore, "datasets/cifar10") )Värdet
target_pathanger sökvägen till det datalager där CIFAR10-data ska laddas upp.Tips
När du använder Azure Machine Learning för att ladda upp data kan du använda Azure Storage Explorer för att ladda upp ad hoc-filer. Om du behöver ett ETL-verktyg kan du använda Azure Data Factory för att mata in dina data i Azure.
Välj Spara och kör skript i terminalen för att köra upload-data.py skriptet.
Du bör se följande standardutdata:
Uploading ./data\cifar-10-batches-py\data_batch_2 Uploaded ./data\cifar-10-batches-py\data_batch_2, 4 files out of an estimated total of 9 . . Uploading ./data\cifar-10-batches-py\data_batch_5 Uploaded ./data\cifar-10-batches-py\data_batch_5, 9 files out of an estimated total of 9 Uploaded 9 files
Skapa ett kontrollskript
Som du har gjort tidigare skapar du ett nytt Python-kontrollskript med namnet run-pytorch-data.py i mappen Komma igång:
# run-pytorch-data.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
from azureml.core import Dataset
if __name__ == "__main__":
ws = Workspace.from_config()
datastore = ws.get_default_datastore()
dataset = Dataset.File.from_files(path=(datastore, 'datasets/cifar10'))
experiment = Experiment(workspace=ws, name='day1-experiment-data')
config = ScriptRunConfig(
source_directory='./src',
script='train.py',
compute_target='cpu-cluster',
arguments=[
'--data_path', dataset.as_named_input('input').as_mount(),
'--learning_rate', 0.003,
'--momentum', 0.92],
)
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print("Submitted to compute cluster. Click link below")
print("")
print(aml_url)
Tips
Om du använde ett annat namn när du skapade beräkningsklustret måste du även justera namnet i koden compute_target='cpu-cluster' .
Förstå kodändringarna
Kontrollskriptet liknar det från del 3 i den här serien med följande nya rader:
dataset = Dataset.File.from_files( ... )
En datauppsättning används för att referera till de data som du laddade upp till Azure Blob Storage. Datauppsättningar är ett abstraktionslager ovanpå dina data som är utformade för att förbättra tillförlitligheten och pålitligheten.
config = ScriptRunConfig(...)
ScriptRunConfig ändras så att den innehåller en lista med argument som ska skickas till train.py. Argumentet dataset.as_named_input('input').as_mount() innebär att den angivna katalogen monteras på beräkningsmålet.
Skicka körningen till Azure Machine Learning
Välj Spara och kör skript i terminalen för att köra run-pytorch-data.py skriptet. Den här körningen tränar modellen i beräkningsklustret med hjälp av de data som du laddade upp.
Den här koden skriver ut en URL till experimentet i Azure Machine Learning-studio. Om du går till den länken kan du se att koden körs.
Anteckning
Du kan se några varningar som börjar med Fel vid inläsning av azureml_run_type_providers.... Du kan ignorera dessa varningar. Använd länken längst ned i dessa varningar för att visa dina utdata.
Granska loggfilen
I studion går du till experimentjobbet (genom att välja föregående URL-utdata) följt av Utdata + loggar. std_log.txt Välj filen. Rulla nedåt i loggfilen tills du ser följande utdata:
Processing 'input'.
Processing dataset FileDataset
{
"source": [
"('workspaceblobstore', 'datasets/cifar10')"
],
"definition": [
"GetDatastoreFiles"
],
"registration": {
"id": "XXXXX",
"name": null,
"version": null,
"workspace": "Workspace.create(name='XXXX', subscription_id='XXXX', resource_group='X')"
}
}
Mounting input to /tmp/tmp9kituvp3.
Mounted input to /tmp/tmp9kituvp3 as folder.
Exit __enter__ of DatasetContextManager
Entering Job History Context Manager.
Current directory: /mnt/batch/tasks/shared/LS_root/jobs/dsvm-aml/azureml/tutorial-session-3_1600171983_763c5381/mounts/workspaceblobstore/azureml/tutorial-session-3_1600171983_763c5381
Preparing to call script [ train.py ] with arguments: ['--data_path', '$input', '--learning_rate', '0.003', '--momentum', '0.92']
After variable expansion, calling script [ train.py ] with arguments: ['--data_path', '/tmp/tmp9kituvp3', '--learning_rate', '0.003', '--momentum', '0.92']
Script type = None
===== DATA =====
DATA PATH: /tmp/tmp9kituvp3
LIST FILES IN DATA PATH...
['cifar-10-batches-py', 'cifar-10-python.tar.gz']
Obs!
- Azure Machine Learning har monterat Blob Storage till beräkningsklustret automatiskt åt dig.
- Det
dataset.as_named_input('input').as_mount()som används i kontrollskriptet matchar monteringspunkten.
Rensa resurser
Om du planerar att fortsätta nu till en annan självstudie eller starta egna träningsjobb går du vidare till Nästa steg.
Stoppa beräkningsinstans
Om du inte ska använda den nu stoppar du beräkningsinstansen:
- Välj Beräkning till vänster i studion.
- På de översta flikarna väljer du Beräkningsinstanser
- Välj beräkningsinstansen i listan.
- I det övre verktygsfältet väljer du Stoppa.
Ta bort alla resurser
Viktigt
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du skapade tar du bort dem så att du inte debiteras några avgifter:
I Azure-portalen väljer du Resursgrupper längst till vänster.
Välj resursgruppen som du skapade från listan.
Välj Ta bort resursgrupp.
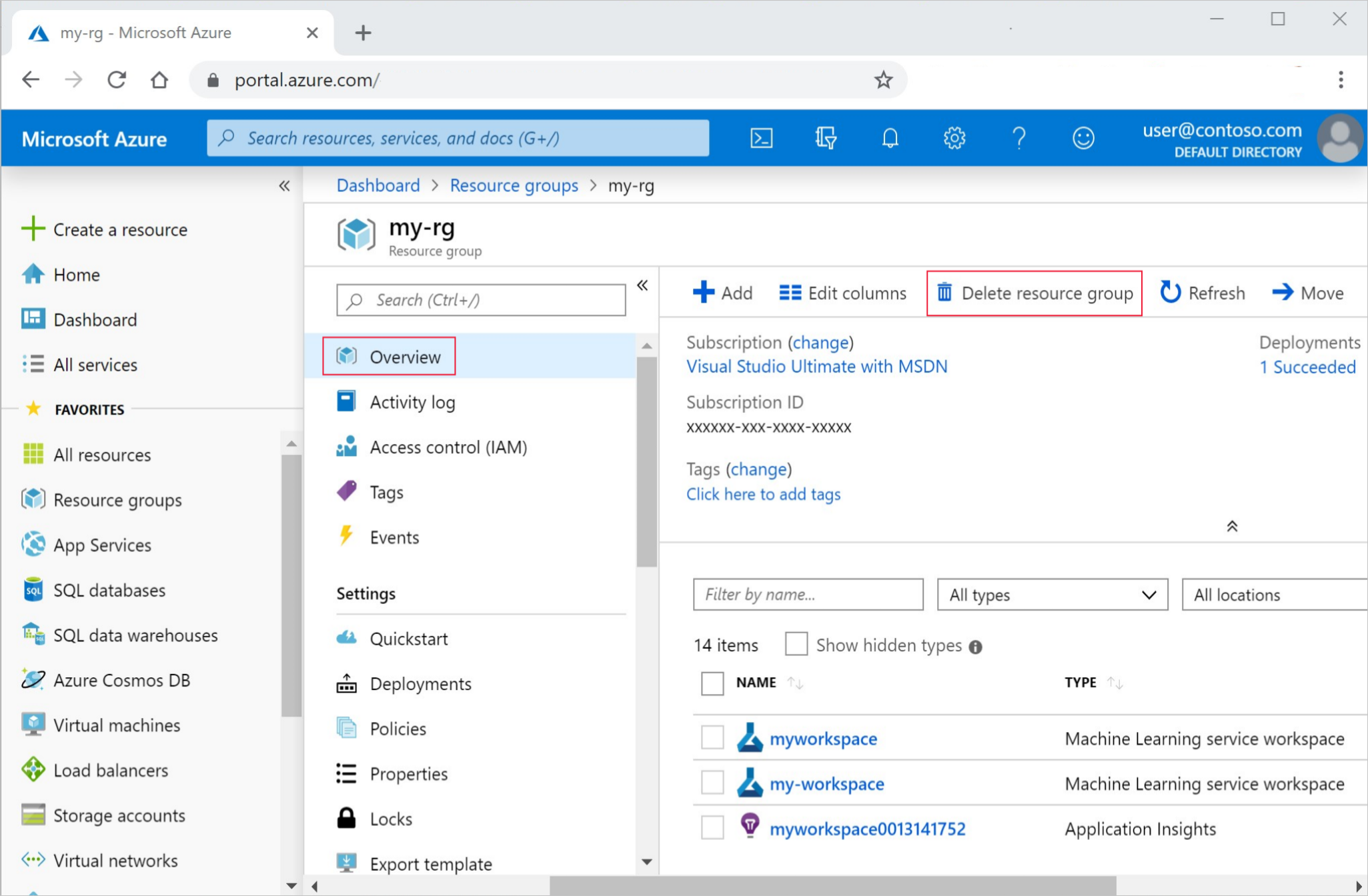
Ange resursgruppsnamnet. Välj sedan Ta bort.
Du kan också behålla resursgruppen men ta bort en enstaka arbetsyta. Visa arbetsytans egenskaper och välj Ta bort.
Nästa steg
I den här självstudien såg vi hur du laddar upp data till Azure med hjälp Datastoreav . Datalagret fungerade som molnlagring för din arbetsyta, vilket ger dig en beständig och flexibel plats för att behålla dina data.
Du såg hur du ändrar träningsskriptet för att acceptera en datasökväg via kommandoraden. Med hjälp av Datasetkunde du montera en katalog till fjärrjobbet.
Nu när du har en modell kan du lära dig: