Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR:  Azure Database for PostgreSQL – flexibel server
Azure Database for PostgreSQL – flexibel server
Azure Database for PostgreSQL – flexibel server ger möjlighet att utöka funktionerna i databasen med hjälp av tillägg. Tillägg paket flera relaterade SQL-objekt i ett enda paket som kan läsas in eller tas bort från databasen med ett kommando. När tilläggen har lästs in i databasen fungerar de som inbyggda funktioner.
Använda PostgreSQL-tillägg
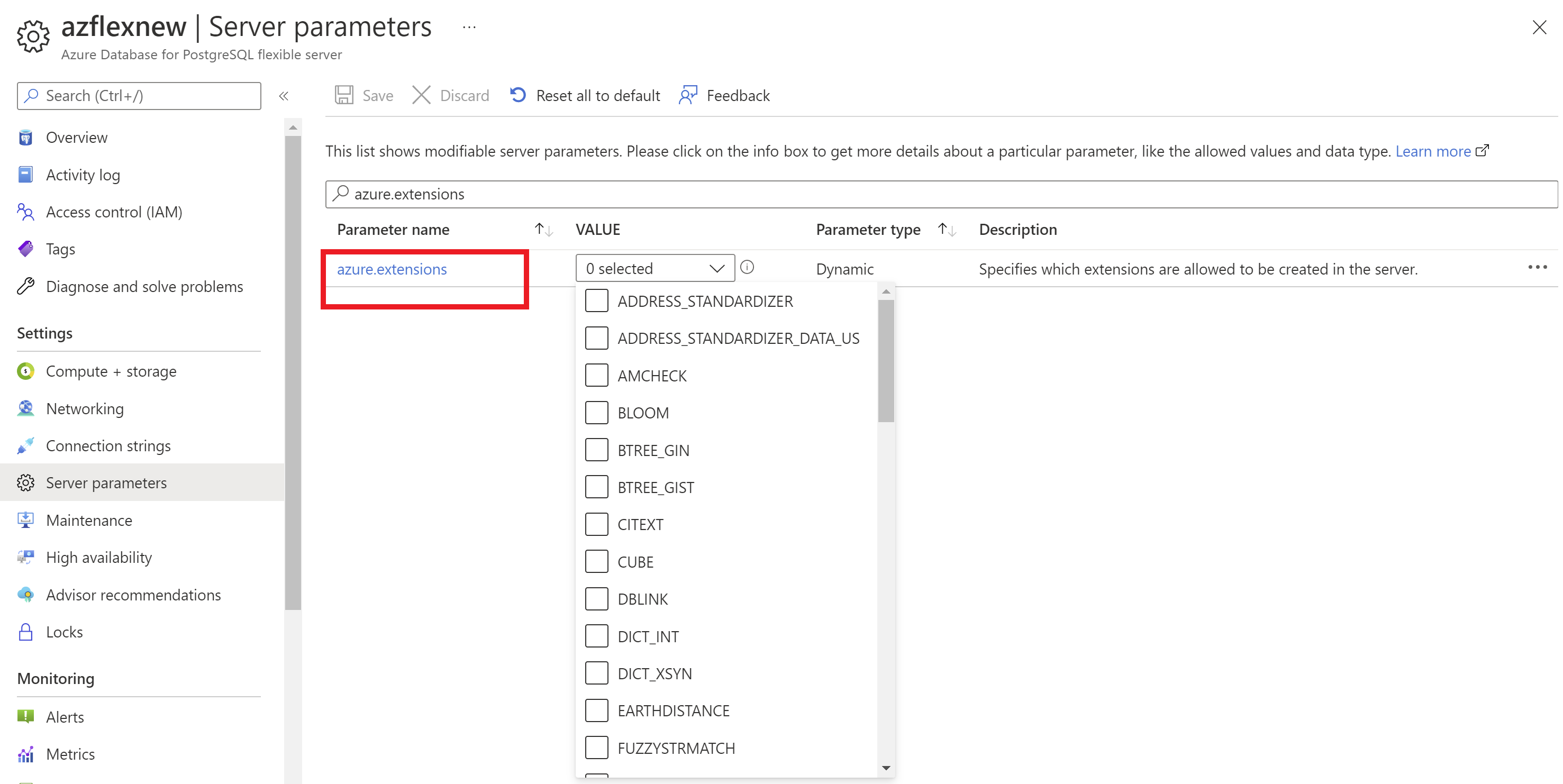
Innan du installerar tillägg i Azure Database for PostgreSQL – flexibel server måste du tillåta att dessa tillägg används.
- Välj din azure database for PostgreSQL– flexibel serverinstans.
- På resursmenyn går du till avsnittet Inställningar och väljer Serverparametrar.
- Sök efter parametern
azure.extensions. - Välj de tillägg som du vill tillåtalista.

Använda Azure CLI:
Du kan tillåtalistetillägg via cli-parameteruppsättningskommandot.
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name azure.extensions --value <extension_name>,<extension_name>
Använda ARM-mall: I följande exempel tillåts dblinktillägg , , pg_buffercache dict_xsynpå en server vars namn är postgres-test-server:
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"flexibleServers_name": {
"defaultValue": "postgres-test-server",
"type": "String"
},
"azure_extensions_set_value": {
"defaultValue": " dblink,dict_xsyn,pg_buffercache",
"type": "String"
}
},
"variables": {},
"resources": [
{
"type": "Microsoft.DBforPostgreSQL/flexibleServers/configurations",
"apiVersion": "2021-06-01",
"name": "[concat(parameters('flexibleServers_name'), '/azure.extensions')]",
"properties": {
"value": "[parameters('azure_extensions_set_value')]",
"source": "user-override"
}
}
]
}
shared_preload_libraries är en serverkonfigurationsparameter som avgör vilka bibliotek som måste läsas in när Azure Database for PostgreSQL – flexibel server startar. Alla bibliotek som använder delat minne måste läsas in via den här parametern. Följ dessa steg om tillägget behöver läggas till i delade förinläsningsbibliotek:
- Välj din azure database for PostgreSQL– flexibel serverinstans.
- På resursmenyn går du till avsnittet Inställningar och väljer Serverparametrar.
- Sök efter parametern
shared_preload_libraries. - Välj de bibliotek som du vill lägga till.
:::image type="content" source="./media/concepts-extensions/shared-libraries.png" alt-text="Screenshot showing Azure Database for PostgreSQL -setting shared preload libraries parameter setting for extensions installation." lightbox="./media/concepts-extensions/shared-libraries.png":::
```Using [Azure CLI](/cli/azure/):
You can set `shared_preload_libraries` via CLI [parameter set](/cli/azure/postgres/flexible-server/parameter?view=azure-cli-latest&preserve-view=true) command.
```azurecli
az postgres flexible-server parameter set --resource-group <resource_group> --server-name <server> --subscription <subscription_id> --name shared_preload_libraries --value <extension_name>,<extension_name>
Skapa tillägg
När tilläggen är tillåtna och inlästa måste de installeras i varje databas där du planerar att använda dem.
- En användare måste vara medlem i
azure_pg_adminrollen för att kunna skapa ett tillägg. En medlem iazure_pg_adminrollen kan ge andra användare behörighet att skapa tillägg. - Om du vill installera ett visst tillägg bör du köra kommandot CREATE EXTENSION . Det här kommandot läser in de paketerade objekten i databasen.
Kommentar
Tillägg från tredje part som erbjuds i Azure Database for PostgreSQL – flexibel server är öppen källkod licensierad kod. För närvarande erbjuder vi inga tillägg eller tilläggsversioner från tredje part med premium- eller proprietära licensieringsmodeller.
Azure Database for PostgreSQL– flexibel serverinstans stöder en delmängd av viktiga PostgreSQL-tillägg enligt listan i följande tabell. Den här informationen är också tillgänglig genom att köra SHOW azure.extensions;. Tillägg som inte visas i det här dokumentet stöds inte på azure database for PostgreSQL – flexibel server. Du kan inte skapa eller läsa in ditt eget tillägg i Azure Database for PostgreSQL – flexibel server.
Tilläggsversioner
Följande tillägg är tillgängliga i Azure Database for PostgreSQL – flexibel server:
Kommentar
Tillägg i följande tabell med märket ✔️ kräver att deras motsvarande bibliotek aktiveras i shared_preload_libraries serverparametern.
| Tilläggsnamn | Beskrivning | PostgreSQL 17 | PostgreSQL 16 | PostgreSQL 15 | PostgreSQL 14 | PostgreSQL 13 | PostgreSQL 12 | PostgreSQL 11 |
|---|---|---|---|---|---|---|---|---|
| address_standardizer | Används för att parsa en adress i element. Används vanligtvis för att stödja normaliseringssteget för geokodningsadresser. | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| address_standardizer_data_us | Exempel på datamängden Address Standardizer US | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| ålder (förhandsversion) | Tillhandahåller grafdatabasfunktioner | Ej tillämpligt | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | 1.5.0 ✔️ | Saknas | Saknas |
| amcheck | Funktioner för att verifiera relationsintegritet | 1.4 | 1.3 | 1.3 | 1.3 | 1.2 | 1.2 | 1,1 |
| anon (förhandsversion) | Verktyg för dataidentifiering | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ | 1.3.2 ✔️ |
| azure_ai | Azure AI- och ML Services-integrering för PostgreSQL | Ej tillämpligt | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | 1.1.0 | Ej tillämpligt |
| azure_storage | Azure-integrering för PostgreSQL | Ej tillämpligt | 1,5 ✔️ | 1,5 ✔️ | 1,5 ✔️ | 1,5 ✔️ | 1,5 ✔️ | Ej tillämpligt |
| blomma | Bloom-åtkomstmetod – signaturfilbaserat index | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| btree_gin | Stöd för indexering av vanliga datatyper i GIN | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| btree_gist | Stöd för indexering av vanliga datatyper i GiST | 1,7 | 1,7 | 1,7 | 1.6 | 1.5 | 1.5 | 1.5 |
| citext | Datatyp för skiftlägesokänsliga teckensträngar | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 |
| kub | Datatyp för flerdimensionella kuber | 1.5 | 1.5 | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 |
| dblink | Ansluta till andra PostgreSQL-databaser från en databas | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| dict_int | Ordlistemall för textsökning för heltal | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| dict_xsyn | Ordlistemall för textsökning för utökad synonymbearbetning | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| earthdistance | Beräkna stora cirkelavstånd på jordens yta | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| fuzzystrmatch | Fastställa likheter och avstånd mellan strängar | 1.2 | 1.2 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| hstore | Datatyp för lagring av uppsättningar med (nyckel, värde) par | 1.8 | 1.8 | 1.8 | 1.8 | 1,7 | 1.6 | 1.5 |
| hypopg | Hypotetiska index för PostgreSQL | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 | 1.4.0 |
| intagg | Heltalsaggregator och uppräknare (föråldrad) | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| intarray | Funktioner, operatorer och indexstöd för 1D-matriser med heltal | 1.5 | 1.5 | 1.5 | 1.5 | 1.3 | 1.2 | 1.2 |
| Isn | Datatyper för internationella produktnumreringsstandarder | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| Lo | Underhåll av stora objekt | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| login_hook | Login_hook – hook för att köra login_hook.login() vid inloggning | 1.5 | 1.5 | 1.4 | 1.4 | 1.4 | 1.4 | 1.4 |
| ltree | Datatyp för hierarkiska trädliknande strukturer | 1.3 | 1.2 | 1.2 | 1.2 | 1.2 | 1,1 | 1,1 |
| oracle_fdw | Sekundär dataomslutning för Oracle-databaser | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | Ej tillämpligt |
| orafce | Funktioner och operatorer som emulerar en delmängd funktioner och paket från Oracle RDBMS | 4,9 | 4.4 | 3.24 | 3,18 | 3,18 | 3,18 | 3.7 |
| pageinspect | Granska innehållet på databassidor på en låg nivå | 1.12 | 1.12 | 1.11 | 1,9 | 1.8 | 1,7 | 1,7 |
| pgaudit | Tillhandahåller granskningsfunktioner | 16.0 ✔️ | 16.0 ✔️ | 1.7 ✔️ | 1.6.2 ✔️ | 1,5 ✔️ | 1.4.3 ✔️ | 1.3.2 ✔️ |
| pg_buffercache | Granska den delade buffertcachen | 1.5 | 1.4 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_cron | Jobbschemaläggare för PostgreSQL | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1.4-1 ✔️ |
| pgcrypto | Kryptografiska funktioner | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 | 1.3 |
| pg_freespacemap | Granska kartan över ledigt utrymme (FSM) | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_hint_plan | Gör det möjligt att justera PostgreSQL-körningsplaner med hjälp av så kallade tips i SQL-kommentarer. | 1.7.0 ✔️ | 1.6.0 ✔️ | 1,5 ✔️ | 1.4 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ | 1.3.7 ✔️ |
| pglogical | Logisk postgreSQL-replikering | 2.4.5 ✔️ | 2.4.4 ✔️ | 2.4.2 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ | 2.4.1 ✔️ |
| pg_partman | Tillägg för att hantera partitionerade tabeller efter tid eller ID | 5.0.1 ✔️ | 5.0.1 ✔️ | 4.7.1 ✔️ | 4.6.1 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ | 4.5.0 ✔️ |
| pg_prewarm | Prewarm-relationsdata | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ | 1.2 ✔️ |
| pg_repack | Omorganisera tabeller i PostgreSQL-databaser med minimala lås | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 | 1.4.7 |
| pgrouting | PgRouting-tillägg | Saknas | Saknas | 3.5.0 | 3.3.0 | 3.3.0 | 3.3.0 | 3.3.0 |
| pgrowlocks | Visa information om låsning på radnivå | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| pg_squeeze | Ett verktyg för att ta bort oanvänt utrymme från en relation. | 1.7 ✔️ | 1.6 ✔️ | 1.6 ✔️ | 1,5 ✔️ | 1,5 ✔️ | 1,5 ✔️ | 1,5 ✔️ |
| pg_stat_statements | Spåra körningsstatistik för alla SQL-instruktioner som körs | 1.11 ✔️ | 1.10 ✔️ | 1.10 ✔️ | 1.9 ✔️ | 1,8 ✔️ | 1.7 ✔️ | 1.6 ✔️ |
| pgstattuple | Visa statistik på tuppelns nivå | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 | 1.5 |
| pg_trgm | Mätning av textlikhet och indexsökning baserat på trigram | 1.6 | 1.6 | 1.6 | 1.6 | 1.5 | 1.4 | 1.4 |
| pg_visibility | Granska synlighetskartan (VM) och synlighetsinformationen på sidnivå | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| plpgsql | PL/pgSQL procedurellt språk | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| plv8 | PL/JavaScript (v8) betrott procedurspråk | 3.1.7 | 3.1.7 | 3.1.7 | 3.0.0 | 3.0.0 | 3.0.0 | 3.0.0 |
| postgis | PostGIS-geometri och geografiska rumsliga typer och funktioner | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_raster | PostGIS rastertyper och funktioner | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_sfcgal | PostGIS SFCGAL-funktioner | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_tiger_geocoder | PostGIS tiger geocoder och omvänd geocoder | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgis_topology | PostGIS-topologi spatiala typer och funktioner | 3.5.0 | 3.3.3 | 3.3.1 | 3.2.3 | 3.2.3 | 3.2.3 | 3.2.3 |
| postgres_fdw | Extern dataomslutning för fjärranslutna PostgreSQL-servrar | 1,1 | 1,1 | 1,1 | 1,1 | 1.0 | 1.0 | 1.0 |
| postgres_protobuf | Protokollbuffertar för PostgreSQL | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | Ej tillämpligt |
| semver | Datatyp för semantisk version | 0.32.1 | 0.32.1 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 | 0.32.0 |
| session_variable | Session_variable – registrering och manipulering av sessionsvariabler och konstanter | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 | 3.3 |
| sslinfo | Information om SSL-certifikat | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 | 1.2 |
| tablefunc | Funktioner som manipulerar hela tabeller, inklusive korsflik | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tds_fdw | Sekundär dataomslutning för att fråga en TDS-databas (Sybase eller Microsoft SQL Server) | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 | 2.0.3 |
| timescaledb | Aktiverar skalbara infogningar och komplexa frågor för tidsseriedata | Ej tillämpligt | 2.13.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 2.10.0 ✔️ | 1.7.4 ✔️ |
| tsm_system_rows | TABLESAMPLE-metod som accepterar antalet rader som en gräns | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| tsm_system_time | TABLESAMPLE-metod som accepterar tid i millisekunder som en gräns | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| Unaccent | Ordlista för textsökning som tar bort accenter | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| uuid-ossp | Generera universellt unika identifierare (UUID) | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 | 1,1 |
| vektor | Vektordatatyp och ivfflat- och hnsw-åtkomstmetoder | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.7.0 | 0.5.1 |
Uppgradera PostgreSQL-tillägg
Uppgraderingar på plats av databastillägg tillåts via ett enkelt kommando. Med den här funktionen kan kunder automatiskt uppdatera sina tillägg från tredje part till de senaste versionerna och underhålla aktuella och säkra system utan manuella ansträngningar.
Uppdatera tillägg
Om du vill uppdatera ett installerat tillägg till den senaste tillgängliga versionen som stöds av Azure använder du följande SQL-kommando:
ALTER EXTENSION <extension_name> UPDATE;
Det här kommandot förenklar hanteringen av databastillägg genom att tillåta användare att manuellt uppgradera till den senaste versionen som godkänts av Azure, vilket förbättrar både kompatibiliteten och säkerheten.
Begränsningar
Det är enkelt att uppdatera tillägg, men det finns vissa begränsningar:
- Val av en specifik version: Kommandot stöder inte uppdatering till mellanliggande versioner av ett tillägg. Den uppdateras alltid till den senaste tillgängliga versionen.
- Nedgradering: Stöder inte nedgradering av ett tillägg till en tidigare version. Om en nedgradering krävs kan det kräva supporthjälp och beror på tillgängligheten för den tidigare versionen.
Installerade tillägg
Om du vill visa en lista över de tillägg som för närvarande är installerade i databasen använder du följande SQL-kommando:
SELECT * FROM pg_extension;
Tillgängliga tillägg och deras versioner
Om du vill kontrollera vilka versioner av ett tillägg som är tillgängliga för den aktuella databasinstallationen pg_available_extensions frågar du systemkatalogvyn. Om du till exempel vill fastställa vilken version som är tillgänglig för azure_aitillägget kör du:
SELECT * FROM pg_available_extensions WHERE name = 'azure_ai';
Dessa kommandon ger nödvändiga insikter om databasens tilläggskonfigurationer, vilket hjälper dig att underhålla dina system effektivt och säkert. Genom att aktivera enkla uppdateringar av de senaste tilläggsversionerna fortsätter Azure Database for PostgreSQL att stödja robust, säker och effektiv hantering av dina databasprogram.
Överväganden som är specifika för flexibel Azure Database for PostgreSQL-server
Följande är en lista över tillägg som stöds och som kräver vissa specifika överväganden när de används i azure database for PostgreSQL– flexibel servertjänst. Listan sorteras alfabetiskt.
dblink
med dblink kan du ansluta från en flexibel Azure Database for PostgreSQL-serverinstans till en annan eller till en annan databas på samma server. Azure Database for PostgreSQL – flexibel server stöder både inkommande och utgående anslutningar till valfri PostgreSQL-server. Den sändande servern måste tillåta utgående anslutningar till den mottagande servern. På samma sätt måste den mottagande servern tillåta anslutningar från den sändande servern.
Vi rekommenderar att du distribuerar dina servrar med integrering av virtuella nätverk om du planerar att använda det här tillägget. Som standard tillåter integrering av virtuella nätverk anslutningar mellan servrar i det virtuella nätverket. Du kan också välja att använda säkerhetsgrupper för virtuella nätverk för att anpassa åtkomsten.
pg_buffercache
pg_buffercache kan användas för att studera innehållet i shared_buffers. Med det här tillägget kan du se om en viss relation cachelagras eller inte (i shared_buffers). Det här tillägget kan hjälpa dig att felsöka prestandaproblem (cachelagringsrelaterade prestandaproblem).
Det här tillägget är integrerat med kärninstallationen av PostgreSQL, och det är enkelt att installera.
CREATE EXTENSION pg_buffercache;
pg_cron
pg_cron är en enkel, cron-baserad jobbschemaläggare för PostgreSQL som körs i databasen som ett tillägg. Tillägget pg_cron kan användas för att köra schemalagda underhållsaktiviteter i en PostgreSQL-databas. Du kan till exempel köra periodiskt vakuum för en tabell eller ta bort gamla datajobb.
pg_cron kan köra flera jobb parallellt, men körs som mest en instans av ett jobb i taget. Om en andra körning ska starta innan den första slutförs placeras den andra körningen i kö och startas så snart den första körningen är klar. På så sätt säkerställs att jobb körs exakt lika många gånger som schemalagt och inte körs samtidigt med sig själva.
Några exempel:
För att ta bort gamla data på lördag klockan 03:30 (GMT).
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Så här kör du vakuum varje dag klockan 10:00 (GMT) i standarddatabasen postgres.
SELECT cron.schedule('0 10 * * *', 'VACUUM');
Så här avbokar du alla aktiviteter från pg_cron.
SELECT cron.unschedule(jobid) FROM cron.job;
Om du vill se alla jobb som för närvarande är schemalagda med pg_cron.
SELECT * FROM cron.job;
För att köra vakuum varje dag klockan 10:00 (GMT) i databasen "testcron" under azure_pg_admin rollkonto.
SELECT cron.schedule_in_database('VACUUM','0 10 * * * ','VACUUM','testcron',null,TRUE);
Kommentar
pg_cron tillägget är förinläst shared_preload_libraries för varje flexibel Azure Database for PostgreSQL-serverinstans i postgres-databasen för att ge dig möjlighet att schemalägga jobb att köras i andra databaser i azure database for PostgreSQL– flexibel server DB-instans utan att äventyra säkerheten. Av säkerhetsskäl måste du dock fortfarande tillåta listtillägg pg_cron och installera det med kommandot CREATE EXTENSION .
Från och med pg_cron version 1.4 kan du använda cron.schedule_in_database funktionerna och cron.alter_job för att schemalägga jobbet i en specifik databas och uppdatera ett befintligt schema.
Några exempel:
Ta bort gamla data på lördag klockan 03:30 (GMT) på databasen DBName.
SELECT cron.schedule_in_database('JobName', '30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$,'DBName');
Kommentar
cron_schedule_in_database -funktionen tillåter användarnamn som valfri parameter. Om du ställer in användarnamnet på ett värde som inte är null krävs postgreSQL-superanvändarbehörighet och stöds inte i Azure Database for PostgreSQL – flexibel server. Föregående exempel visar körning av den här funktionen med valfria användarnamnsparametern utelämnad eller inställd på null, som kör jobbet i samband med att användaren schemalägger jobbet, vilket bör ha azure_pg_admin rollbehörigheter.
För att uppdatera eller ändra databasnamnet för det befintliga schemat
SELECT cron.alter_job(job_id:=MyJobID,database:='NewDBName');
pg_failover_slots
Tillägget PG-redundansfack förbättrar Azure Database for PostgreSQL– flexibel server när du arbetar med både logisk replikering och servrar med hög tillgänglighet. Den hanterar effektivt utmaningen i PostgreSQL-standardmotorn som inte bevarar logiska replikeringsplatser efter en redundansväxling. Att underhålla dessa platser är viktigt för att förhindra replikeringspauser eller datamatchningar under ändringar av primär serverrollen, vilket säkerställer driftkontinuitet och dataintegritet.
Tillägget effektiviserar redundansväxlingen genom att hantera nödvändig överföring, rensning och synkronisering av replikeringsplatser, vilket ger en sömlös övergång under ändringar i serverrollen. Tillägget stöds för PostgreSQL-versionerna 11 till 16.
Du hittar mer information och hur du använder tillägget PG-redundansfack på github-sidan.
Aktivera pg_failover_slots
Om du vill aktivera PG-tillägget för redundansfack för din flexibla Serverinstans för Azure Database for PostgreSQL måste du ändra serverns konfiguration genom att inkludera tillägget i serverns delade förinläsningsbibliotek och justera en specifik serverparameter. Så här gör du:
- Lägg till
pg_failover_slotsi serverns delade förinläsningsbibliotek genom att uppdatera parameternshared_preload_libraries. - Ändra serverparametern
hot_standby_feedbacktillon.
Ändringar i parametern shared_preload_libraries kräver att en omstart av servern börjar gälla.
- Välj din azure database for PostgreSQL– flexibel serverinstans.
- På resursmenyn går du till avsnittet Inställningar och väljer Serverparametrar.
- Sök efter parametern
shared_preload_librariesoch redigera dess värde så att den innehållerpg_failover_slots. - Sök efter parametern
hot_standby_feedbackoch ange dess värde tillon. - Välj spara ändringarna genom att välja Spara . Nu har du möjlighet att spara och starta om. Välj det här alternativet för att se till att ändringarna börjar gälla, eftersom ändringar
shared_preload_librarieskräver en omstart av servern.
Genom att välja Spara och starta om startar servern automatiskt om och tillämpar de ändringar som just har gjorts. När servern är online igen aktiveras tillägget PG-redundansfack och används på din primära azure database for PostgreSQL-flexibel serverinstans, redo att hantera logiska replikeringsplatser under redundansväxlingar.
pg_hint_plan
pg_hint_plan gör det möjligt att justera PostgreSQL-körningsplaner med hjälp av så kallade "tips" i SQL-kommentarer, till exempel:
/*+ SeqScan(a) */
pg_hint_plan läser tipsfraser i en kommentar av särskilt format som ges med SQL-mål-instruktionen. Specialformuläret börjar med teckensekvensen "/*+" och slutar med "*/". Tipsfraser består av tipsnamn och följande parametrar som omges av parenteser och avgränsas av blanksteg. Nya rader för läsbarhet kan avgränsa varje tipsfras.
Exempel:
/*+
HashJoin(a b)
SeqScan(a)
*/
SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts an ON b.bid = a.bid
ORDER BY a.aid;
Det föregående exemplet gör att planeraren använder resultatet av en seq scan i tabellen a för att kombineras med tabell b som en hash join.
Om du vill installera pg_hint_plan för att kunna visa den, som du ser i hur du använder PostgreSQL-tillägg, måste du inkludera det i serverns delade förinläsningsbibliotek. En ändring av Postgres shared_preload_libraries parameter kräver att en omstart av servern börjar gälla. Du kan ändra parametrar med hjälp av Azure Portal eller Azure CLI.
- Välj din azure database for PostgreSQL– flexibel serverinstans.
- På resursmenyn går du till avsnittet Inställningar och väljer Serverparametrar.
- Sök efter parametern
shared_preload_librariesoch redigera dess värde så att den innehållerpg_hint_plan. - Välj spara ändringarna genom att välja Spara . Nu har du möjlighet att spara och starta om. Välj det här alternativet för att se till att ändringarna börjar gälla, eftersom ändringar
shared_preload_librarieskräver en omstart av servern. Nu kan du aktivera pg_hint_plan din flexibla serverdatabas i Azure Database for PostgreSQL. Anslut till databasen och utfärda följande kommando:
CREATE EXTENSION pg_hint_plan;
pg_prewarm
Tillägget pg_prewarm läser in relationsdata i cacheminnet. Att förvärma dina cacheminnen innebär att dina frågor har bättre svarstider vid den första körningen efter en omstart. Funktionen auto-prewarm är för närvarande inte tillgänglig i Azure Database for PostgreSQL – flexibel server.
pg_repack
En typisk fråga som användarna ställer när de först försöker använda det här tillägget är: Kan pg_repack ett tillägg eller en körbar fil på klientsidan som psql eller pg_dump?
Svaret på detta är att det faktiskt är både och. pg_repack/lib innehåller koden för tillägget, inklusive schemat och SQL-artefakterna som skapas, och C-biblioteket som implementerar koden för flera av dessa funktioner. Å andra sidan behåller pg_repack/bin koden för klientprogrammet, som vet hur man interagerar med de programmerbarhetsartefakter som skapas av tillägget. Det här klientprogrammet syftar till att underlätta komplexiteten i att interagera med de olika gränssnitt som visas i tillägget på serversidan, genom att erbjuda användaren vissa kommandoradsalternativ som är lättare att förstå. Klientprogrammet utan tillägget som skapas på databasen som det pekas på är värdelöst. Tillägget på serversidan är helt funktionellt, men kräver att användaren förstår ett komplicerat interaktionsmönster som består av att köra frågor för att hämta data som används som indata till funktioner som implementeras av tillägget.
Behörighet nekad för schemaompaketering
Från och med nu, på grund av det sätt på vilket vi beviljar behörigheter till ompaketeringsschemat som skapats av det här tillägget, stöds det bara för att köra pg_repack funktioner från kontexten azure_pg_adminför .
Du kanske märker att om ägaren till en tabell, som inte azure_pg_adminär , försöker köra pg_repack får de ett felmeddelande som liknar följande:
NOTICE: Setting up workers.conns
ERROR: pg_repack failed with error: ERROR: permission denied for schema repack
LINE 1: select repack.version(), repack.version_sql()
För att undvika det felet kontrollerar du att du kör pg_repack från kontexten azure_pg_adminför .
pg_stat_statements
Tillägget pg_stat_statements ger dig en vy över alla frågor som har körts i databasen. Det är användbart för att få en förståelse för hur din frågearbetsbelastningsprestanda ser ut i ett produktionssystem.
Tillägget pg_stat_statements är förinläst på shared_preload_libraries varje flexibel Azure Database for PostgreSQL-serverinstans för att ge dig ett sätt att spåra körningsstatistik för SQL-instruktioner.
Av säkerhetsskäl måste du dock fortfarande tillåtalistningpg_stat_statements-tillägget och installera det med kommandot CREATE EXTENSION.
Inställningen pg_stat_statements.track, som styr vilka instruktioner som räknas av tillägget, är standardvärdet , vilket innebär att topalla instruktioner som utfärdas direkt av klienter spåras. De två andra spårningsnivåerna är none och all. Den här inställningen kan konfigureras som en serverparameter.
Det gäller att hitta en balans mellan frågekörningsinformationen som pg_stat_statements tillhandahåller och påverkan på serverprestanda eftersom den loggar varje SQL-instruktion. Om du inte aktivt använder pg_stat_statements tillägget rekommenderar vi att du anger pg_stat_statements.track till none. Vissa övervakningstjänster från tredje part kan förlita sig på pg_stat_statements för att leverera insikter om frågeprestanda, så bekräfta om så är fallet för dig eller inte.
postgres_fdw
postgres_fdw kan du ansluta från en flexibel Azure Database for PostgreSQL-serverinstans till en annan eller till en annan databas på samma server. Azure Database for PostgreSQL – flexibel server stöder både inkommande och utgående anslutningar till valfri PostgreSQL-server. Den sändande servern måste tillåta utgående anslutningar till den mottagande servern. På samma sätt måste den mottagande servern tillåta anslutningar från den sändande servern.
Vi rekommenderar att du distribuerar dina servrar med integrering av virtuella nätverk om du planerar att använda det här tillägget. Som standard tillåter integrering av virtuella nätverk anslutningar mellan servrar i det virtuella nätverket. Du kan också välja att använda säkerhetsgrupper för virtuella nätverk för att anpassa åtkomsten.
pgstattuple
När du använder tillägget "pgstattuple" för att försöka hämta tuppelns statistik från objekt som lagras i pg_toast schemat i versioner av Postgres 11 till 13 får du felet "behörighet nekad för schema pg_toast".
Behörighet nekad för schema pg_toast
Kunder som använder PostgreSQL version 11 till och med 13 på Azure Database for Flexible Server kan inte använda pgstattuple tillägget på objekt i pg_toast schemat.
I PostgreSQL 16 och 17 beviljas rollen automatiskt till azure_pg_admin, vilket gör pgstattuple att den pg_read_all_data kan fungera korrekt. I PostgreSQL 14 och 15 kan kunderna manuellt ge pg_read_all_data rollen för att azure_pg_admin uppnå samma resultat. Men i PostgreSQL 11 till 13 pg_read_all_data finns inte rollen.
Kunder kan inte bevilja nödvändiga behörigheter direkt. Om du behöver kunna köra för att komma pgstattuple åt objekt under pg_toast schemat kan du fortsätta med att skapa en Azure Support begäran.
TidsskalaDB
TimescaleDB är en tidsseriedatabas som paketeras som ett tillägg för PostgreSQL. TimescaleDB tillhandahåller tidsorienterade analysfunktioner, optimeringar och skalar Postgres för tidsseriearbetsbelastningar. Läs mer om TimescaleDB, ett registrerat varumärke som tillhör Timescale, Inc. Azure Database for PostgreSQL – flexibel server tillhandahåller TimescaleDB Apache-2-utgåvan.
Installera TimescaleDB
Om du vill installera TimescaleDB måste du dessutom inkludera det i serverns delade förinläsningsbibliotek för att tillåta att det visas, som du ser ovan. En ändring av Postgres shared_preload_libraries parameter kräver att en omstart av servern börjar gälla. Du kan ändra parametrar med hjälp av Azure Portal eller Azure CLI.
- Välj din azure database for PostgreSQL– flexibel serverinstans.
- På resursmenyn går du till avsnittet Inställningar och väljer Serverparametrar.
- Sök efter parametern
shared_preload_librariesoch redigera dess värde så att den innehållerTimescaleDB. - Välj spara ändringarna genom att välja Spara . Nu har du möjlighet att spara och starta om. Välj det här alternativet för att se till att ändringarna börjar gälla, eftersom ändringar
shared_preload_librarieskräver en omstart av servern. Nu kan du aktivera TimescaleDB i azure database for PostgreSQL– flexibel serverdatabas. Anslut till databasen och utfärda följande kommando:
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Dricks
Om du ser ett fel kontrollerar du att du har startat om servern när du har sparat shared_preload_libraries.
Nu kan du skapa en TimescaleDB-hypertabell från grunden eller migrera befintliga tidsseriedata i PostgreSQL.
Återställa en tidsskala-databas med hjälp av pg_dump och pg_restore
Om du vill återställa en tidsskala-databas med hjälp av pg_dump och pg_restore måste du köra två hjälpprocedurer i måldatabasen: timescaledb_pre_restore() och timescaledb_post restore().
Förbered först måldatabasen:
--create the new database where you want to perform the restore
CREATE DATABASE tutorial;
\c tutorial --connect to the database
CREATE EXTENSION timescaledb;
SELECT timescaledb_pre_restore();
Nu kan du köra pg_dump på den ursprungliga databasen och sedan göra pg_restore. Efter återställningen ska du köra följande kommando i den återställda databasen:
SELECT timescaledb_post_restore();
Mer information om återställningsmetod med timescale-aktiverad databas finns i Dokumentation om tidsskala.
Återställa en tidsskala-databas med hjälp av tidsberäknadb-säkerhetskopiering
När du kör SELECT timescaledb_post_restore() proceduren ovan kan du få behörigheter som nekas fel vid uppdatering av flaggan timescaledb.restoring. Detta beror på begränsad ALTER DATABASE-behörighet i Cloud PaaS-databastjänster. I det här fallet kan du utföra en alternativ metod med hjälp av timescaledb-backup verktyget för att säkerhetskopiera och återställa en tidsskala-databas. Timescaledb-backup är ett program för att göra dumpning och återställning av en TimescaleDB-databas enklare, mindre felbenägen och mer högpresterande.
För att göra det bör du göra följande
- Installera verktyg enligt beskrivningen här
- Skapa en Azure Database for PostgreSQL-målinstans och databas för flexibel server
- Aktivera tidsskaletillägg som visas ovan
- Bevilja
azure_pg_adminrollen till användare som ska användas av ts-restore - Kör ts-restore för att återställa databasen
Mer information om dessa verktyg finns här.
Tillägg och högre versionsuppgradering
Azure Database for PostgreSQL – flexibel server har introducerat en huvudversionsuppgraderingsfunktion på plats som utför en uppgradering på plats av azure database for PostgreSQL flexibel serverinstans med bara ett klick. Uppgradering av större versioner på plats förenklar uppgraderingsprocessen för Azure Database for PostgreSQL– flexibel server, vilket minimerar störningarna för användare och program som kommer åt servern. Huvudversionsuppgradering på plats stöder inte specifika tillägg och det finns vissa begränsningar för att uppgradera vissa tillägg. Tilläggen anon, Apache AGE, dblink, orafce, pgaudit, postgres_fdw och Timescaledb stöds inte för alla flexibla Azure Database for PostgreSQL-serverversioner när du använder huvudversionsuppdateringsfunktionen på plats.