Tillförlitlighet i Azure Event Grid och Event Grid-namnområdet
Den här artikeln innehåller detaljerad information om regional återhämtning för Event Grid- och Event Grid-namnområden med tillgänglighetszoner och haveriberedskap mellan regioner och affärskontinuitet.
En arkitekturöversikt över tillförlitlighet i Azure finns i Azures tillförlitlighet.
Stöd för tillgänglighetszon
Azure-tillgänglighetszoner är minst tre fysiskt separata grupper av datacenter i varje Azure-region. Datacenter i varje zon är utrustade med oberoende infrastruktur för ström, kylning och nätverk. Om det uppstår ett fel i den lokala zonen är tillgänglighetszoner utformade så att regionala tjänster, kapacitet och hög tillgänglighet stöds av de återstående två zonerna om den ena zonen påverkas.
Fel kan vara allt från programvaru- och maskinvarufel till händelser som jordbävningar, översvämningar och bränder. Tolerans mot fel uppnås med redundans och logisk isolering av Azure-tjänster. Mer detaljerad information om tillgänglighetszoner i Azure finns i Regioner och tillgänglighetszoner.
Azure-tillgänglighetszoner-aktiverade tjänster är utformade för att ge rätt nivå av tillförlitlighet och flexibilitet. De kan konfigureras på två sätt. De kan vara antingen zonredundanta, med automatisk replikering mellan zoner eller zoninstanser, med instanser fästa på en specifik zon. Du kan också kombinera dessa metoder. Mer information om zon- och zonredundant arkitektur finns i Rekommendationer för användning av tillgänglighetszoner och regioner.
Event Grid-resursdefinitioner för ämnen, systemämnen, domäner och händelseprenumerationer och händelsedata replikeras automatiskt mellan tre tillgänglighetszoner. När det uppstår ett regionalt fel i någon av tillgänglighetszonerna redundansväxlar Event Grid-resurser automatiskt till en annan tillgänglighetszon utan mänsklig inblandning. För närvarande är det inte möjligt för dig att styra (aktivera eller inaktivera) den här funktionen. När en befintlig region börjar stödja tillgänglighetszoner redväxeras befintliga Event Grid-resurser automatiskt för att dra nytta av den här funktionen. Ingen kundåtgärd krävs.
Azure Event Grid-namnområdet ger också hög tillgänglighet inom regionen med hjälp av tillgänglighetszoner.
Förutsättningar
För stöd för tillgänglighetszoner måste dina Event Grid-resurser finnas i en region som stöder tillgänglighetszoner. Information om vilka regioner som stöder tillgänglighetszoner finns i listan över regioner som stöds.
Prissättning
Eftersom Event Grid stöder tillgänglighetszoner automatiskt i regioner som stöder tillgänglighetszoner finns det inga ändringar i priset.
Skapa en resurs med tillgänglighetszoner aktiverade
Eftersom Event Grid stöder tillgänglighetszoner automatiskt i regioner som stöder tillgänglighetszoner finns det ingen nödvändig konfigurationskonfiguration.
Migrera till stöd för tillgänglighetszoner
Om du flyttar dina Event Grid-resurser till en region som stöder tillgänglighetszoner får du automatiskt stöd för tillgänglighetszoner. Information om hur du flyttar dina resurser till en annan region som stöder tillgänglighetszoner finns i följande:
- Flytta Azure Event Grid-systemämnen till en annan region
- Flytta anpassade ämnen för Azure Event Grid till en annan region
- Flytta Azure Event Grid-domäner till en annan region
Haveriberedskap och affärskontinuitet mellan regioner
Haveriberedskap handlar om att återställa från händelser med hög påverkan, till exempel naturkatastrofer eller misslyckade distributioner som resulterar i driftstopp och dataförlust. Oavsett orsak är den bästa lösningen för en katastrof en väldefinierad och testad DR-plan och en programdesign som aktivt stöder DR. Innan du börjar fundera på att skapa en haveriberedskapsplan kan du läsa Rekommendationer för att utforma en strategi för haveriberedskap.
När det gäller dr använder Microsoft modellen för delat ansvar. I en modell med delat ansvar ser Microsoft till att baslinjeinfrastrukturen och plattformstjänsterna är tillgängliga. Samtidigt replikerar många Azure-tjänster inte automatiskt data eller återgår från en misslyckad region för att korsreparera till en annan aktiverad region. För dessa tjänster ansvarar du för att konfigurera en haveriberedskapsplan som fungerar för din arbetsbelastning. De flesta tjänster som körs på PaaS-erbjudanden (Plattform som en tjänst) i Azure ger funktioner och vägledning för att stödja DR och du kan använda tjänstspecifika funktioner för att stödja snabb återställning för att utveckla din DR-plan.
Haveriberedskap innebär vanligtvis att du skapar en säkerhetskopieringsresurs för att förhindra avbrott när en region blir skadad. Under den här processen behövs en primär och sekundär region med Azure Event Grid-resurser i din arbetsbelastning.
Det finns olika sätt att återställa från en allvarlig förlust av programfunktioner. I det här avsnittet beskriver vi checklistan som du måste följa för att förbereda klienten för att återställa från ett fel på grund av en resurs eller region som inte är felfri.
Event Grid stöder både manuell och automatisk geo-haveriberedskap (GeoDR) på serversidan. Du kan fortfarande implementera haveriberedskapslogik på klientsidan om du vill ha en större kontroll över redundansväxlingsprocessen. Mer information om automatisk GeoDR finns i Geo-haveriberedskap på serversidan i Azure Event Grid. Mer information om hur du implementerar haveriberedskappå klientsidan finns i Implementering av redundans på klientsidan i Azure Event Grid.
I följande tabell visas stöd för redundans på klientsidan och geo-haveriberedskap i Event Grid.
| Event Grid-resurs | Stöd för redundans på klientsidan | Geo-haveriberedskapsstöd (GeoDR) |
|---|---|---|
| Anpassade ämnen | Stöds | Cross-Geo/Regional |
| Systemämnen | Stöds inte | Aktiverad automatiskt |
| Domäner | Stöds | Cross-Geo/Regional |
| Partnernamnområden | Stöds | Stöds inte |
| Namnrymder | Stöds | Stöds inte |
Event Grid-namnområde
Event Grid-namnrymden stöder inte dr-fel mellan regioner. Du kan dock uppnå hög tillgänglighet mellan regioner genom implementering av redundans på klientsidan genom att skapa primära och sekundära namnområden.
Med en redundansimplementering på klientsidan kan du:
Implementera en anpassad (manuell eller automatiserad) process för att replikera namnrymd, klientidentiteter och andra konfigurationer** inklusive CA-certifikat, klientgrupper, ämnesutrymmen, behörighetsbindningar, routning, mellan primära och sekundära regioner.
Implementera en concierge-tjänst som ger klienter primära och sekundära slutpunkter genom att utföra en hälsokontroll på slutpunkter. Concierge-tjänsten kan vara ett webbprogram som replikeras och hålls nåbart med hjälp av DNS-omdirigeringstekniker, till exempel med Hjälp av Azure Traffic Manager.
Uppnå en Aktiv-Aktiv DR-lösning genom att replikera metadata och balansera belastningen över namnrymderna. En aktiv-passiv DR-lösning kan uppnås genom att replikera metadata för att hålla det sekundära namnområdet redo så att trafiken kan dirigeras till sekundärt namnområde när det primära namnområdet inte är tillgängligt.
Konfigurera haveriberedskap
För regioner som är kopplade erbjuder Event Grid en möjlighet att redundansväxla publiceringstrafiken till den kopplade regionen för anpassade ämnen, systemämnen och domäner. I bakgrunden synkroniserar Event Grid automatiskt resursdefinitioner av ämnen, systemämnen, domäner och händelseprenumerationer till den kopplade regionen. Händelsedata replikeras dock inte till den kopplade regionen. I det normala tillståndet lagras händelser i den region som du valde för den resursen. När det uppstår ett regionavbrott och Microsoft initierar redundansväxlingen börjar nya händelser flöda till den geo-kopplade regionen och skickas därifrån utan några åtgärder från dig. Händelser som publicerats och godkänts i den ursprungliga regionen skickas därifrån efter att avbrottet har åtgärdats.
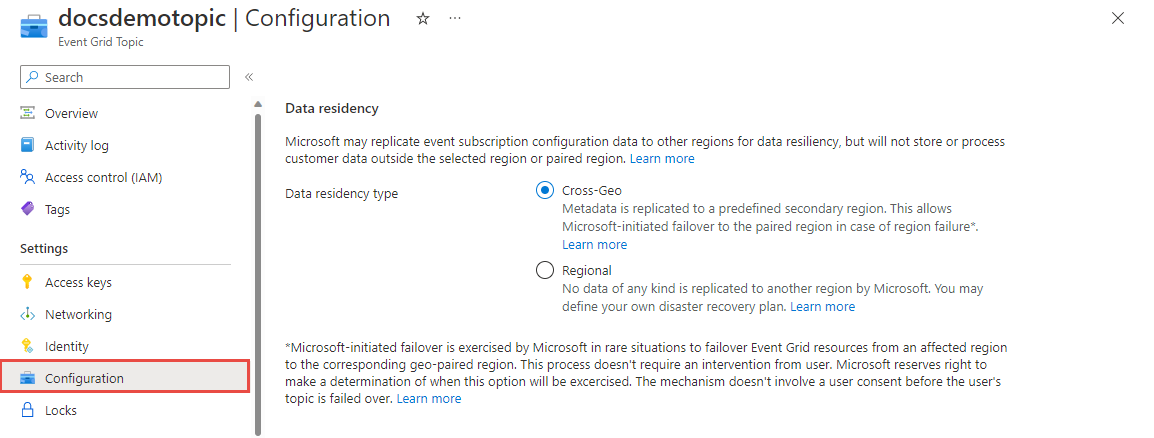
Du kan välja mellan två redundansalternativ, Microsoft-initierad redundans och kundinitierad. Detaljerade anvisningar om hur du konfigurerar båda dessa inställningar finns i Konfigurera datahemvist.
Microsoft-initierad redundans används av Microsoft i sällsynta fall för att redundansväxla Event Grid-resurser från en berörd region till motsvarande geo-kopplade region. Microsoft förbehåller sig rätten att avgöra när det här alternativet ska användas. Den här mekanismen omfattar inte ett användarmedgivande innan användarens trafik red redoveras.
Aktivera den här funktionen genom att uppdatera konfigurationen för ditt ämne eller din domän. Välj Cross-Geo (standard) för att aktivera Microsoft-initierad redundans.
Kundinitierad redundans definieras av din anpassade haveriberedskapsplan för Azure Event Grid-ämnen och domäner. Inga data av något slag replikeras till en annan region av Microsoft. Även om det här redundansalternativet kräver lite mer arbete möjliggör det snabbare redundans och du har kontroll över att välja sekundära regioner. Om du vill implementera haveriberedskap på klientsidan för Azure Event Grid-ämnen kan du läsa Mer information om att skapa en egen haveriberedskap på klientsidan för Azure Event Grid.
Det finns några orsaker till varför du kanske vill inaktivera den Microsoft-initierade redundansfunktionen:
- Microsoft-initierad redundans utförs på bästa sätt.
- Vissa geo-par uppfyller inte organisationens krav på datahemvist.
Aktivera den här funktionen genom att uppdatera konfigurationen för ditt ämne eller din domän. Välj Regional.
Haveriberedskap vid redundans
Haveriberedskap mäts med två mått: Mål för återställningspunkt (RPO) och mål för återställningstid (RTO).
Event Grids automatiska redundansväxling har olika RRPOs och RTO:er för dina metadata (ämnen, domäner, händelseprenumerationer) och data (händelser). Om du behöver en annan specifikation än följande kan du fortfarande implementera din egen redundans på klientsidan med hjälp av ämnets hälso-API:er.
Mål för återställningspunkt (RPO)
RPO för metadata: noll minuter. När en resurs skapas/uppdateras/tas bort för tillämpliga resurser replikeras resursdefinitionen synkront till geo-paret. När en redundansväxling inträffar går inga metadata förlorade.
Data-RPO: När en redundansväxling inträffar bearbetas nya data från den kopplade regionen. Så snart avbrottet har åtgärdats för den berörda regionen skickas de obearbetade händelserna därifrån. Om regionåterställningen krävde längre tid än det time-to-live-värde som angetts för händelser kan data tas bort. För att minska dataförlusten rekommenderar vi att du konfigurerar ett mål med obeställbara meddelanden för en händelseprenumeration. Om den berörda regionen går förlorad och inte går att återställa kommer det att uppstå viss dataförlust. I bästa fall håller prenumeranten jämna steg med publiceringsfrekvensen och bara några sekunders data går förlorade. Det värsta scenariot skulle vara när prenumeranten inte aktivt bearbetar händelser och med en maxtid på 24 timmar kan dataförlusten vara upp till 24 timmar.
Mål för återställningstid (RTO)
RTO för metadata: Beslutsfattande vid redundans baseras på faktorer som tillgänglig kapacitet i en parad region och kan pågå i intervallet 60 minuter eller mer. När redundansväxlingen har initierats börjar Event Grid inom 5 minuter att acceptera anrop för att skapa/uppdatera/ta bort ämnen och prenumerationer.
Data-RTO: Samma som ovanstående information.
Viktigt!
- Vid haveriberedskap på serversidan kan Event Grid inte initiera redundans om den kopplade regionen inte har någon extra kapacitet att ta på sig ytterligare trafik. Återställningen görs på bästa sätt.
- Du debiteras inte för att använda den här funktionen.
- Geo-haveriberedskap stöds inte för partnernamnområden och partnerämnen.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för