NFS v4.1-volymer på Azure NetApp Files för SAP HANA
Azure NetApp Files tillhandahåller interna NFS-resurser som kan användas för /hana/shared, /hana/data och /hana/log-volymer . Användning av ANF-baserade NFS-resurser för volymerna /hana/data och /hana/log kräver användning av NFS-protokollet v4.1. NFS-protokollet v3 stöds inte för användning av /hana/data - och /hana/log-volymer när du baserar resurserna på ANF.
Viktigt!
NFS v3-protokollet som implementeras på Azure NetApp Files stöds inte för att användas för /hana/data och /hana/log. Användningen av NFS 4.1 är obligatorisk för /hana/data - och /hana/loggvolymer ur funktionell synvinkel. För den /hana/delade volymen kan NFS v3 eller NFS v4.1-protokollet användas ur funktionell synvinkel.
Viktigt!
Tänk på följande viktiga överväganden när du överväger Azure NetApp Files för SAP Netweaver och SAP HANA:
Begränsningar för volym- och kapacitetspooler finns i Resursbegränsningar för Azure NetApp Files.
Azure NetApp Files-baserade NFS-resurser och de virtuella datorer som monterar dessa resurser måste finnas i samma virtuella Azure-nätverk eller i peerkopplade virtuella nätverk i samma region.
Det valda virtuella nätverket måste ha ett undernät, delegerat till Azure NetApp Files. För SAP-arbetsbelastningar rekommenderar vi starkt att du konfigurerar ett /25-intervall för undernätet som delegeras till Azure NetApp Files.
Det är viktigt att de virtuella datorerna distribueras tillräckligt nära Azure NetApp-lagringen för lägre svarstid, till exempel på begäran av SAP HANA för att göra om loggskrivningar.
- Azure NetApp Files har under tiden funktioner för att distribuera NFS-volymer till specifika Azure-tillgänglighetszoner. En sådan zonindelad närhet kommer att vara tillräcklig i de flesta fall för att uppnå en svarstid på mindre än 1 millisekunder. Funktionerna finns i offentlig förhandsversion och beskrivs i artikeln Hantera volymplacering i tillgänglighetszonen för Azure NetApp Files. Den här funktionen kräver ingen interaktiv process med Microsoft för att uppnå närhet mellan den virtuella datorn och de NFS-volymer som du allokerar.
- För att uppnå optimal närhet är funktionerna i programvolymgrupper tillgängliga. Den här funktionen letar inte bara efter den mest optimala närheten, utan för den mest optimala placeringen av NFS-volymerna, så att HANA-data och omgjorda loggvolymer hanteras av olika styrenheter. Nackdelen är att den här metoden behöver en interaktiv process med Microsoft för att fästa dina virtuella datorer.
Kontrollera att svarstiden från databasservern till Azure NetApp Files-volymen mäts och under 1 millisekunder
Dataflödet för en Azure NetApp-volym är en funktion av volymkvoten och tjänstnivån, enligt beskrivningen i Tjänstnivå för Azure NetApp Files. När du ändrar storlek på HANA Azure NetApp-volymerna kontrollerar du att det resulterande dataflödet uppfyller HANA-systemkraven. Du kan också överväga att använda en manuell QoS-kapacitetspool där volymkapacitet och dataflöde kan konfigureras och skalas separat (SAP HANA-specifika exempel finns i det här dokumentet
Försök att "konsolidera" volymer för att uppnå mer prestanda i en större volym, till exempel använda en volym för /sapmnt, /usr/sap/trans, ... om möjligt
Azure NetApp Files erbjuder exportprincip: du kan styra de tillåtna klienterna, åtkomsttypen (skrivskyddad och skrivskyddad).
Användar-ID för sidadm och grupp-ID för
sapsyspå de virtuella datorerna måste matcha konfigurationen i Azure NetApp Files.
Viktigt!
Det är viktigt med låg fördröjning för SAP HANA-arbetsbelastningar. Samarbeta med din Microsoft-representant för att säkerställa att de virtuella datorerna och Azure NetApp Files-volymerna distribueras i närheten.
Viktigt!
Om det finns ett matchningsfel mellan användar-ID för sid adm och grupp-ID för sapsys mellan den virtuella datorn och Azure NetApp-konfigurationen visas behörigheterna för filer på Azure NetApp-volymer, monterade på den virtuella datorn, som nobody. Se till att ange rätt användar-ID för sidadm och grupp-ID för sapsys, när du går ombord på ett nytt system till Azure NetApp Files.
NCONNECT-monteringsalternativ
Nconnect är ett monteringsalternativ för NFS-volymer i Azure NetApp Files som gör att NFS-klienten kan öppna flera sessioner mot en enda NFS-volym. NCONNECT med värdet större än 1 utlöser också NFS-klienten att använda mer än en RPC-session på klientsidan (i gästoperativsystemet) för att hantera trafiken mellan gästoperativsystemet och de monterade NFS-volymerna. Användningen av flera sessioner som hanterar trafik på en NFS-volym, men även användningen av flera RPC-sessioner kan hantera prestanda- och dataflödesscenarier som:
- Montera flera Azure NetApp Files-värdbaserade NFS-volymer med olika tjänstnivåer på en virtuell dator
- Det maximala skrivdataflödet för en volym och en enda Linux-session är mellan 1,2 och 1,4 GB/s. Att ha flera sessioner mot en Azure NetApp Files-värdbaserad NFS-volym kan öka dataflödet
För Linux OS-versioner som stöder nconnect som ett monteringsalternativ och några viktiga konfigurationsöverväganden för nconnect, särskilt med olika NFS-serverslutpunkter, läser du dokumentet metodtips för Linux NFS-monteringsalternativ för Azure NetApp Files.
Storleksändring för HANA-databas på Azure NetApp Files
Dataflödet för en Azure NetApp-volym är en funktion av volymstorleken och tjänstnivån, enligt beskrivningen i Tjänstnivåer för Azure NetApp Files.
Viktigt att förstå är prestandarelationens storlek och att det finns fysiska gränser för en lagringsslutpunkt för tjänsten. Varje lagringsslutpunkt matas dynamiskt in i det delegerade undernätet Azure NetApp Files när volymen skapas och får en IP-adress. Azure NetApp Files-volymer kan – beroende på tillgänglig kapacitet och distributionslogik – dela en lagringsslutpunkt
Tabellen nedan visar att det kan vara meningsfullt att skapa en stor "Standard"-volym för lagring av säkerhetskopior och att det inte är meningsfullt att skapa en "Ultra"-volym som är större än 12 TB eftersom den maximala fysiska bandbreddskapaciteten för en enskild volym skulle överskridas.
Om du behöver mer än det maximala skrivdataflödet för din /hana/datavolym än vad en enda Linux-session kan ge, kan du också använda SAP HANA-datavolympartitionering som ett alternativ. SAP HANA-datavolympartitionering streckar I/O-aktiviteten under datainläsningen eller HANA-sparandepunkter över flera HANA-datafiler som finns på flera NFS-resurser. Mer information om BANDNING av HANA-datavolymer finns i följande artiklar:
- HANA-administratörsguiden
- Blogg om SAP HANA – Partitionera datavolymer
- SAP-anteckning #2400005
- SAP-anteckning #2700123
| Storlek | Dataflödesstandard | Dataflödespremie | Dataflöde Ultra |
|---|---|---|---|
| 1 TB | 16 MB/s | 64 MB/s | 128 MB/s |
| 2 TB | 32 MB/s | 128 MB/s | 256 MB/s |
| 4 TB | 64 MB/s | 256 MB/s | 512 MB/s |
| 10 TB | 160 MB/s | 640 MB/s | 1 280 MB/s |
| 15 TB | 240 MB/s | 960 MB/s | 1 400 MB/sek1 |
| 20 TB | 320 MB/s | 1 280 MB/s | 1 400 MB/sek1 |
| 40 TB | 640 MB/s | 1 400 MB/sek1 | 1 400 MB/sek1 |
1: Läsflödesgränser för skriv- eller enskild session (om NFS-monteringsalternativet nconnect inte används)
Det är viktigt att förstå att data skrivs till samma SSD i lagringsserverdelen. Prestandakvoten från kapacitetspoolen skapades för att kunna hantera miljön. KPI:er för lagring är lika för alla HANA-databasstorlekar. I nästan alla fall återspeglar detta antagande inte verkligheten och kundens förväntningar. Storleken på HANA-system innebär inte nödvändigtvis att ett litet system kräver lågt dataflöde för lagring – och ett stort system kräver högt dataflöde för lagring. Men i allmänhet kan vi förvänta oss högre dataflödeskrav för större HANA-databasinstanser. Som ett resultat av SAP:s storleksregler för den underliggande maskinvaran ger sådana större HANA-instanser också fler CPU-resurser och högre parallellitet i uppgifter som att läsa in data efter en omstart av instanser. Därför bör volymstorlekarna anpassas efter kundens förväntningar och krav. Och inte bara drivs av rena kapacitetskrav.
När du utformar infrastrukturen för SAP i Azure bör du känna till vissa minimikrav för lagringsdataflöde (för produktionssystem) av SAP. Dessa krav omvandlas till minsta dataflödesegenskaper för:
| Volymtyp och I/O-typ | Minsta KPI som krävs av SAP | Premium-tjänstnivå | Ultra servicenivå |
|---|---|---|---|
| Loggvolymskrivning | 250 MB/sek. | 4 TB | 2 TB |
| Skrivning av datavolym | 250 MB/sek. | 4 TB | 2 TB |
| Läsa datavolym | 400 MB/s | 6,3 TB | 3,2 TB |
Eftersom alla tre KPI:er krävs måste /hana/datavolymen vara storleksanpassad mot den större kapaciteten för att uppfylla minimikraven för läsning. Om du använder manuella QoS-kapacitetspooler kan volymernas storlek och dataflöde definieras oberoende av varandra. Eftersom både kapacitet och dataflöde hämtas från samma kapacitetspool måste poolens tjänstnivå och storlek vara tillräckligt stor för att leverera den totala prestandan (se exempel här)
För HANA-system, som inte kräver hög bandbredd, kan dataflödet för Azure NetApp Files-volymen sänkas med antingen en mindre volymstorlek eller, med hjälp av manuell QoS, genom att justera dataflödet direkt. Och om ett HANA-system kräver mer dataflöde skulle volymen kunna anpassas genom att ändra storlek på kapaciteten online. Inga KPI:er har definierats för säkerhetskopieringsvolymer. Dataflödet för säkerhetskopieringsvolymen är dock viktigt för en väl fungerande miljö. Logg – och datavolymprestanda måste utformas enligt kundens förväntningar.
Viktigt!
Oberoende av den kapacitet som du distribuerar på en enda NFS-volym förväntas dataflödet platå inom intervallet 1,2–1,4 GB/sek bandbredd som används av en konsument i en enda session. Detta har att göra med den underliggande arkitekturen i Azure NetApp Files-erbjudandet och relaterade Linux-sessionsgränser runt NFS. Prestanda- och dataflödesnumren som beskrivs i artikeln Prestandatestresultat för Azure NetApp Files utfördes mot en delad NFS-volym med flera virtuella klientdatorer och som ett resultat av flera sessioner. Det scenariot skiljer sig från det scenario som vi mäter i SAP där vi mäter dataflöde från en enda virtuell dator mot en NFS-volym som finns på Azure NetApp Files.
För att uppfylla SAP:s minsta dataflödeskrav för data och logg, och enligt riktlinjerna för /hana/shared, skulle de rekommenderade storlekarna se ut så här:
| Volume | Storlek Premium Storage-nivå |
Storlek Ultra Storage-nivå |
NFS-protokoll som stöds |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | v4.1 |
| /hana/delad uppskalning | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | v3 eller v4.1 |
| /hana/delad utskalning | 1 x RAM-minne för arbetsnod per fyra arbetsnoder |
1 x RAM-minne för arbetsnod per fyra arbetsnoder |
v3 eller v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 eller v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 eller v4.1 |
För alla volymer rekommenderas NFS v4.1 starkt.
Granska noggrant övervägandena för storlek /hana/delad, eftersom lämplig storlek /hana/delad volym bidrar till systemets stabilitet.
Storlekarna för säkerhetskopieringsvolymerna är uppskattningar. Exakta krav måste definieras baserat på arbetsbelastnings- och åtgärdsprocesser. För säkerhetskopior kan du konsolidera många volymer för olika SAP HANA-instanser till en (eller två) större volymer, vilket kan ha en lägre tjänstnivå för Azure NetApp Files.
Kommentar
Storleksrekommendationerna för Azure NetApp Files som anges i det här dokumentet riktar sig till de minimikrav som SAP uttrycker mot sina infrastrukturleverantörer. I verkliga kunddistributioner och arbetsbelastningsscenarier kanske det inte räcker. Använd dessa rekommendationer som utgångspunkt och anpassa baserat på kraven för din specifika arbetsbelastning.
Därför kan du överväga att distribuera liknande dataflöde för Azure NetApp Files-volymerna som redan anges för Ultra-disklagring. Tänk också på storlekarna för de storlekar som anges för volymerna för de olika VM-SKU:erna som redan gjorts i Ultra-disktabellerna.
Dricks
Du kan ändra storlek på Azure NetApp Files-volymer dynamiskt, utan att unmount behöva volymerna, stoppa de virtuella datorerna eller stoppa SAP HANA. Det ger flexibilitet att uppfylla både förväntade och oförutsedda dataflödeskrav för ditt program.
Dokumentation om hur du distribuerar en SAP HANA-skalbar konfiguration med väntelägesnod med hjälp av Azure NetApp Files-baserade NFS v4.1-volymer publiceras i SAP HANA-utskalning med väntelägesnod på virtuella Azure-datorer med Azure NetApp Files på SUSE Linux Enterprise Server.
Inställningar för Linux-kernel
För att kunna distribuera SAP HANA på Azure NetApp Files måste inställningarna för Linux-kernel implementeras enligt SAP-3024346.
För system som använder hög tillgänglighet (HA) med pacemaker och Azure Load Balancer måste följande inställningar implementeras i filen /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
System som körs utan pacemaker och Azure Load Balancer bör implementera dessa inställningar i /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Distribution med zonindelad närhet
Om du vill få en zonindelad närhet till dina NFS-volymer och virtuella datorer kan du följa anvisningarna enligt beskrivningen i Hantera volymplacering i tillgänglighetszonen för Azure NetApp Files. Med den här metoden kommer de virtuella datorerna och NFS-volymerna att finnas i samma Azure-tillgänglighetszon. I de flesta Azure-regioner bör den här typen av närhet vara tillräcklig för att uppnå mindre än 1 millisekunders svarstid för de mindre omgjorda loggskrivningarna för SAP HANA. Den här metoden kräver inget interaktivt arbete med Microsoft för att placera och fästa virtuella datorer i ett specifikt datacenter. Därför är du flexibel med ändra VM-storlekar och familjer inom alla typer av virtuella datorer och familjer som erbjuds i tillgänglighetszonen som du distribuerade. Så att du kan reagera flexibelt på chanign-förhållanden eller gå snabbare till mer kostnadseffektiva VM-storlekar eller familjer. Vi rekommenderar den här metoden för icke-produktionssystem och produktionssystem som kan fungera med svarstider för redologgar som är närmare 1 millisekunder. Funktionen är för närvarande i offentlig förhandsversion.
Distribution via Azure NetApp Files-programvolymgrupp för SAP HANA (AVG)
För att distribuera Azure NetApp Files-volymer med närhet till den virtuella datorn utvecklades en ny funktion som kallas Azure NetApp Files-programvolymgrupp för SAP HANA (AVG). Det finns en serie artiklar som dokumenterar funktionerna. Det bästa är att börja med artikeln Förstå azure NetApp Files-programvolymgruppen för SAP HANA. När du läser artiklarna blir det tydligt att användningen av AVG:er även omfattar användning av Närhetsplaceringsgrupper i Azure. Närhetsplaceringsgrupper används av de nya funktionerna för att kopplas till de volymer som skapas. För att säkerställa att de virtuella datorerna inte flyttas från Azure NetApp Files-volymerna under HANA-systemets livslängd rekommenderar vi att du använder en kombination av Avset/PPG för var och en av de zoner som du distribuerar till. Distributionsordningen skulle se ut så här:
- Med hjälp av formuläret måste du begära en fästning av den tomma AvSet till en beräknings-HW för att säkerställa att virtuella datorer inte kommer att flyttas
- Tilldela en PPG till tillgänglighetsuppsättningen och starta en virtuell dator som tilldelats den här tillgänglighetsuppsättningen
- Använda Azure NetApp Files-programvolymgruppen för SAP HANA-funktioner för att distribuera dina HANA-volymer
Konfigurationen av närhetsplaceringsgruppen för användning av AVG:er på ett optimalt sätt skulle se ut så här:
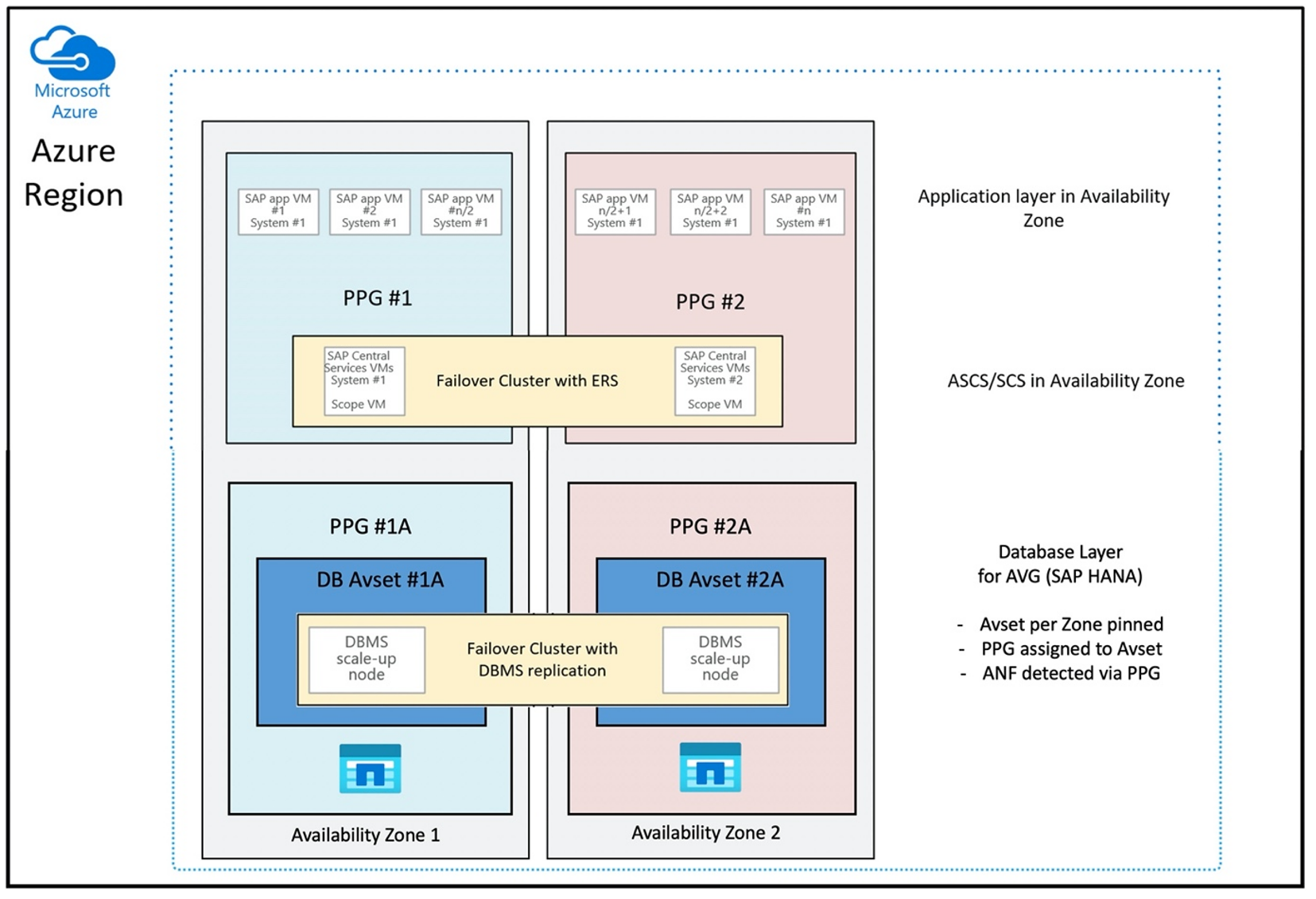
Diagrammet visar att du ska använda en azure-närhetsplaceringsgrupp för DBMS-lagret. Så att den kan användas tillsammans med AVG:er. Det är bäst att bara inkludera de virtuella datorer som kör HANA-instanserna i närhetsplaceringsgruppen. Närhetsplaceringsgruppen är nödvändig, även om endast en virtuell dator med en enda HANA-instans används, för att AVG ska kunna identifiera den närmaste närheten till Azure NetApp Files-maskinvaran. Och för att allokera NFS-volymen på Azure NetApp Files så nära de virtuella datorer som använder NFS-volymerna så nära som möjligt.
Den här metoden genererar de mest optimala resultaten eftersom den relaterar till låg svarstid. Inte bara genom att få NFS-volymerna och de virtuella datorerna så nära varandra som möjligt. Men överväganden för att placera data och göra om loggvolymer mellan olika kontrollanter på NetApp-serverdelen beaktas också. Nackdelen är dock att distributionen av den virtuella datorn är fäst på ett datacenter. Med det förlorar du flexibilitet i föränderliga typer av virtuella datorer och familjer. Därför bör du begränsa den här metoden till de system som absolut kräver så låg lagringsfördröjning. För alla andra system bör du försöka distribuera med en traditionell zonindelad distribution av den virtuella datorn och Azure NetApp Files. I de flesta fall räcker det med låg svarstid. Detta säkerställer också enkelt underhåll och administration av den virtuella datorn och Azure NetApp Files.
Tillgänglighet
ANF-systemuppdateringar och uppgraderingar tillämpas utan att påverka kundmiljön. Det definierade serviceavtalet är 99,99 %.
Volymer, IP-adresser och kapacitetspooler
Med ANF är det viktigt att förstå hur den underliggande infrastrukturen skapas. En kapacitetspool är bara en konstruktion som tillhandahåller en kapacitets- och prestandabudget och faktureringsenhet baserat på kapacitetspoolens tjänstnivå. En kapacitetspool har ingen fysisk relation till den underliggande infrastrukturen. När du skapar en volym på tjänsten skapas en lagringsslutpunkt. En enskild IP-adress tilldelas till den här lagringsslutpunkten för att ge dataåtkomst till volymen. Om du skapar flera volymer distribueras alla volymer i den underliggande bare metal-flottan, som är knuten till den här lagringsslutpunkten. ANF har en logik som automatiskt distribuerar kundarbetsbelastningar när volymerna eller/och kapaciteten för den konfigurerade lagringen når en intern fördefinierad nivå. Du kanske märker sådana fall eftersom en ny lagringsslutpunkt, med en ny IP-adress, skapas automatiskt för att få åtkomst till volymerna. ANF-tjänsten ger inte kundkontroll över den här distributionslogik.
Loggvolym och loggsäkerhetskopieringsvolym
Loggvolymen (/hana/log) används för att skriva om onlineloggen. Det finns därför öppna filer i den här volymen och det är inte meningsfullt att ögonblicksbilden av volymen. Loggfiler för onlineredigering arkiveras eller säkerhetskopieras till loggsäkerhetskopieringsvolymen när loggfilen online är full eller en säkerhetskopia av omloggen körs. För att tillhandahålla rimliga säkerhetskopieringsprestanda kräver loggsäkerhetskopieringsvolymen ett bra dataflöde. För att optimera lagringskostnaderna kan det vara klokt att konsolidera loggsäkerhetskopieringsvolymen för flera HANA-instanser. Så att flera HANA-instanser använder samma volym och skriver sina säkerhetskopior till olika kataloger. Med hjälp av en sådan konsolidering kan du få mer dataflöde med eftersom du behöver göra volymen lite större.
Detsamma gäller för den volym som du använder skriv fullständiga SÄKERHETSKOPior av HANA-databaser till.
Backup
Förutom att strömningssäkerhetskopior och Azure Back Service säkerhetskopierar SAP HANA-databaser enligt beskrivningen i artikeln Säkerhetskopieringsguide för SAP HANA på Azure Virtual Machines, öppnar Azure NetApp Files möjligheten att utföra lagringsbaserade säkerhetskopieringar av ögonblicksbilder.
SAP HANA stöder:
- Stöd för lagringsbaserad säkerhetskopiering av ögonblicksbilder för ett enda containersystem med SAP HANA 1.0 SPS7 och senare
- Stöd för lagringsbaserad säkerhetskopiering av ögonblicksbilder för HANA-miljöer (Multi Database Container) med en enda klientorganisation med SAP HANA 2.0 SPS1 och senare
- Stöd för lagringsbaserad säkerhetskopiering av ögonblicksbilder för HANA-miljöer (Multi Database Container) med flera klienter med SAP HANA 2.0 SPS4 och senare
Att skapa lagringsbaserade säkerhetskopieringar av ögonblicksbilder är en enkel fyrastegsprocedur.
- Skapa en ögonblicksbild av EN HANA-databas (intern) – en aktivitet som du eller verktygen måste utföra
- SAP HANA skriver data till datafilerna för att skapa ett konsekvent tillstånd för lagringen – HANA utför det här steget som ett resultat av att skapa en HANA-ögonblicksbild
- Skapa en ögonblicksbild på /hana/datavolymen på lagringen – ett steg som du eller verktygen måste utföra. Du behöver inte utföra en ögonblicksbild på volymen /hana/log
- Ta bort ögonblicksbilden av HANA-databasen (intern) och återuppta normal åtgärd – ett steg som du eller verktygen måste utföra
Varning
Att missa det sista steget eller misslyckas med att utföra det sista steget har stor inverkan på SAP HANA:s minnesbehov och kan leda till ett stopp för SAP HANA
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Den här säkerhetskopieringsproceduren för ögonblicksbilder kan hanteras på olika sätt med hjälp av olika verktyg. Ett exempel är Python-skriptet "ntaphana_azure.py" som är tillgängligt på GitHub https://github.com/netapp/ntaphana Det här är exempelkod, som tillhandahålls "i nuläget" utan underhåll eller support.
Varning
En ögonblicksbild i sig är inte en skyddad säkerhetskopia eftersom den finns på samma fysiska lagring som den volym som du just tog en ögonblicksbild av. Det är obligatoriskt att "skydda" minst en ögonblicksbild per dag till en annan plats. Detta kan göras i samma miljö, i en fjärransluten Azure-region eller i Azure Blob Storage.
Tillgängliga lösningar för konsekvent säkerhetskopiering av lagringsögonblicksbilder:
- Microsoft What is Azure Application Consistent Snapshot tool är ett kommandoradsverktyg som möjliggör dataskydd för databaser från tredje part. Den hanterar all orkestrering som krävs för att placera databaserna i ett programkonsekvent tillstånd innan du tar en ögonblicksbild av lagringen. När lagringsögonblicksbilden har tagits returnerar verktyget databaserna till ett drifttillstånd. AzAcSnap stöder ögonblicksbildsbaserade säkerhetskopior för HANA Large Instance och Azure NetApp Files. Mer information finns i artikeln What is Azure Application Consistent Snapshot tool (Vad är azure application consistent snapshot tool)
- För användare av Commvault-säkerhetskopieringsprodukter är ett annat alternativ Commvault IntelliSnap V.11.21 och senare. Den här eller senare versionen av Commvault erbjuder stöd för ögonblicksbilder av Azure NetApp Files. Artikeln Commvault IntelliSnap 11.21 innehåller mer information.
Säkerhetskopiera ögonblicksbilden med Azure Blob Storage
Säkerhetskopiera till Azure Blob Storage är en kostnadseffektiv och snabb metod för att spara SÄKERHETSKOPior av ANF-baserade HANA-databaslagringsögonblicksbilder. AzCopy-verktyget rekommenderas för att spara ögonblicksbilderna i Azure Blob Storage. Ladda ned den senaste versionen av det här verktyget och installera det, till exempel i bin-katalogen där Python-skriptet från GitHub är installerat. Ladda ned det senaste AzCopy-verktyget:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
Den mest avancerade funktionen är alternativet SYNC. Om du använder alternativet SYNC behåller azcopy källan och målkatalogen synkroniserade. Användningen av parametern --delete-destination är viktig. Utan den här parametern tar azcopy inte bort filer på målplatsen och utrymmesanvändningen på målsidan skulle öka. Skapa en blockblobcontainer i ditt Azure Storage-konto. Skapa sedan SAS-nyckeln för blobcontainern och synkronisera mappen snapshot till Azure Blob-containern.
Om till exempel en daglig ögonblicksbild ska synkroniseras med Azure Blob-containern för att skydda data. Och bara att en ögonblicksbild ska behållas kan kommandot nedan användas.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Nästa steg
Läs artikeln: