SAP-arbetsbelastning på en virtuell Azure-dator – scenarier som stöds
När du utformar SAP NetWeaver-, Hybris Business One- eller S/4HANA-systemarkitekturen i Azure öppnas många olika möjligheter för olika arkitekturer och verktyg att använda för att komma till en skalbar, effektiv och mycket tillgänglig distribution. Även om det är beroende av vilket operativsystem eller DBMS som används finns det begränsningar. Dessutom stöds inte alla scenarier som stöds lokalt på samma sätt i Azure. Det här dokumentet leder till konfigurationer som stöds och konfigurationer och arkitekturer med hög tillgänglighet som endast använder virtuella Azure-datorer.
Kommentar
HANA Large Instance-tjänsten är i solnedgångsläge och accepterar inte nya kunder längre. Det är fortfarande möjligt att tillhandahålla enheter för befintliga HANA Large Instance-kunder. Alternativ finns i erbjudandena för HANA-certifierade virtuella Azure-datorer i HANA Hardware Directory. För scenarier som stöds och fortfarande stöds för befintliga HANA Large Instance-kunder med STORA HANA-instanser, kan du läsa artikeln Scenarier som stöds för STORA HANA-instanser.
Allmänna plattformsbegränsningar
Azure har olika plattformar förutom så kallade interna virtuella Azure-datorer som erbjuds som förstapartstjänst. HANA Large Instances, som är i solnedgångsläge, är en av dessa plattformar. Azure VMware Services är en annan av dessa tjänster från första part. Azure VMware Services stöds i allmänhet inte av SAP för att vara värd för SAP-arbetsbelastningar. Se SAP-supportanteckning #2138865 – SAP-program i VMware Cloud: Produkter och VM-konfigurationer som stöds för mer information om VMware-stöd på olika plattformar.
Förutom lokal Active Directory erbjuder Azure en hanterad Active Directory SaaS-tjänst med Microsoft Entra Domain Services (traditionell AD som hanteras av Microsoft) och Microsoft Entra ID. SAP-komponenter som finns i Windows OS förlitar sig ofta på användningen av Windows Active Directory. I det här fallet den traditionella Active Directory som den finns lokalt av dig, eller Microsoft Entra Domain Services (fortfarande i testning). Men dessa SAP-komponenter kan inte fungera med det interna Microsoft Entra-ID:t. Orsaken är att det fortfarande finns större funktionsluckor mellan Active Directory i dess lokala form eller dess SaaS-formulär (Microsoft Entra Domain Services) och det interna Microsoft Entra-ID:t. Det här beroendet är anledningen till att Microsoft Entra-konton inte stöds för program som baseras på SAP NetWeaver och S/4 HANA i Windows OS. Traditionella Active Directory-konton måste användas i sådana scenarier.
| AD-tjänsten | Program som stöds baserat på SAP NetWeaver och S/4 HANA i Windows OS |
|---|---|
| Lokal Windows Active Directory | Stöds |
| Microsoft Entra Domain Services | Stöds |
| Microsoft Entra ID | Stöds inte |
Ovanstående påverkar inte användningen av Microsoft Entra-konton för scenarier med enkel inloggning (SSO) med SAP-program.
Konfiguration på två nivåer
En SAP-konfiguration på 2 nivåer anses vara uppbyggd av ett kombinerat lager av SAP DBMS och programskiktet som körs på samma server- eller VM-enhet. Den andra nivån anses vara användargränssnittsskiktet. För en konfiguration på 2 nivåer delar DBMS- och SAP-programlagret resurserna för den virtuella Azure-datorn. Därför måste du konfigurera de olika komponenterna på ett sätt som gör att dessa komponenter inte konkurrerar om resurser. Du måste också vara noga med att inte överprenumerera resurserna för den virtuella datorn. En sådan konfiguration ger ingen hög tillgänglighet utöver Azure Service Level-avtalen för de olika Azure-komponenterna.
En grafisk representation av en sådan konfiguration kan se ut så här:

Sådana konfigurationer stöds med Windows, Red Hat, SUSE och Oracle Linux för DBMS-systemen i SQL Server, Oracle, Db2, maxDB och SAP ASE för produktions- och icke-produktionsfall. För SAP HANA som DBMS stöder SAP ett sådant scenario som anges i SAP-kommentaren #1953429. Hittills har ingen av Linux-distributionerna tillhandahållit tillräcklig ha-dokumentation för att konfigurera och använda ett Pacemaker-kluster i en sådan konfiguration. Därför stöds sådana typer av konfigurationer endast i Azure för icke-produktionsfall som inte kräver ett redundanskluster med hög tillgänglighet.
För alla OS/DBMS-kombinationer som stöds i Azure stöds den här typen av konfiguration. Det är dock obligatoriskt att du ställer in konfigurationen av DBMS- och SAP-komponenterna på ett sätt som DBMS- och SAP-komponenterna inte konkurrerar om minne och CPU-resurser och som överskrider de fysiska tillgängliga resurserna. Detta måste göras genom att begränsa det minne som DBMS kan allokera. Du måste också begränsa SAP Extended Memory på programinstanser. Du måste också övervaka CPU-förbrukningen för den virtuella datorn överlag för att se till att komponenterna inte maximerar CPU-resurserna.
Kommentar
För SAP-produktionssystem rekommenderar vi ytterligare konfigurationer för hög tillgänglighet och eventuell haveriberedskap enligt beskrivningen senare i det här dokumentet
Konfiguration på 3 nivåer
I sådana konfigurationer separerar du SAP-programskiktet och DBMS-lagret i olika virtuella datorer. Du brukar göra det för större system och av skäl som beror på att du är mer flexibel när det gäller resurserna i SAP-programskiktet. I den enklaste konfigurationen finns det ingen hög tillgänglighet utöver Azure Service Level-avtalen för de olika Azure-komponenterna.
Den grafiska representationen ser ut så här:

Den här typen av konfiguration stöds i Windows, Red Hat, SUSE och Oracle Linux för DBMS-systemen i SQL Server, Oracle, Db2, SAP HANA, maxDB och SAP ASE för produktions- och icke-produktionsfall. För förenklingen gjorde vi ingen skillnad mellan SAP Central Services- och SAP-dialoginstanser i SAP-programlagret. I den här enkla konfigurationen på 3 nivåer skulle det inte finnas något skydd för hög tillgänglighet för SAP Central Services.
Kommentar
För SAP-produktionssystem rekommenderar vi ytterligare konfigurationer för hög tillgänglighet och eventuell haveriberedskap enligt beskrivningen senare i det här dokumentet
Flera DBMS-instanser per virtuell dator
I den här konfigurationstypen är du värd för flera DBMS-instanser per virtuell Azure-dator. Motivationen kan vara att ha färre operativsystem att underhålla och med de minskade kostnaderna. Andra skäl är att ha mer flexibilitet och större effektivitet genom att dela resurser i en större virtuell dator eller HANA Large Instance-enhet mellan flera DBMS-instanser. Hittills har dessa konfigurationer främst visat sig för icke-produktionssystem.
En konfiguration som den kan se ut så här:

Den här typen av DBMS-distribution stöds för:
- SQL Server på Windows
- IBM Db2. Hitta information i artikeln Flera instanser (Linux, UNIX)
- För Oracle. Mer information finns i SAP-supportanteckning #1778431 och relaterade SAP-anteckningar
- För SAP HANA stöds flera instanser på en virtuell dator, SAP anropar den här distributionsmetoden MCOS. Mer information finns i SAP-artikeln Flera SAP HANA-system på en värd (MCOS)
Om du kör flera databasinstanser på en värd måste du se till att de olika instanserna inte konkurrerar om resurser och därmed överskrider den virtuella datorns fysiska resursgränser. Detta gäller särskilt för minne där du behöver begränsa minnet som alla av de instanser som delar den virtuella datorn kan allokera. Det kan också gälla för de CPU-resurser som de olika databasinstanserna kan använda. Alla databassystem som nämns har konfigurationer som tillåter begränsning av minnesallokering och CPU-resurser på instansnivå. För att kunna ha stöd för en sådan konfiguration för virtuella Azure-datorer förväntas de diskar eller volymer som används för data och logg-/omloggfiler för de databaser som hanteras av de olika instanserna vara separata. Eller med andra ord ska data eller logg-/omloggfiler för databaser som hanteras av olika DBMS-instanser inte dela samma diskar eller volymer.
Kommentar
För SAP-produktionssystem rekommenderar vi ytterligare konfigurationer för hög tillgänglighet och eventuell haveriberedskap enligt beskrivningen senare i det här dokumentet. Virtuella datorer med flera DBMS-instanser stöds inte med konfigurationer med hög tillgänglighet som beskrivs senare i det här dokumentet.
Flera SAP Dialog-instanser på en virtuell dator
I många fall distribuerades flera dialoginstanser på servrar utan operativsystem eller till och med på virtuella datorer som körs i privata moln. Orsaken till sådana konfigurationer var att skräddarsy vissa SAP-dialoginstanser till vissa typer av arbetsbelastningar, affärsfunktioner eller arbetsbelastningar. Orsaken till att dessa instanser inte isoleras till separata virtuella datorer var operativsystemets underhåll och åtgärder. Eller i många fall kostnaderna om den virtuella datorns värd eller operatör begär en månatlig avgift per virtuell dator som drivs och administreras. I Azure, ett scenario där vi är värdar för flera SAP-dialoginstanser i en enda virtuell dator som vi har stöd för i produktions- och icke-produktionssyfte på operativsystemen i Windows, Red Hat, SUSE och Oracle Linux. SAP-kernelparametern PHYS_MEMSIZE, som finns i Windows och moderna Linux-kernels, bör anges om flera SAP Application Server-instanser körs på en enda virtuell dator. Vi rekommenderar också att du begränsar expansionen av SAP Extended Memory på operativsystem, till exempel Windows där automatisk tillväxt av det utökade SAP-minnet implementeras. Detta kan göras med SAP-profilparametern em/max_size_MB.
Vid konfiguration på 3 nivåer där flera SAP-dialoginstanser körs på virtuella Azure-datorer kan det se ut så här:
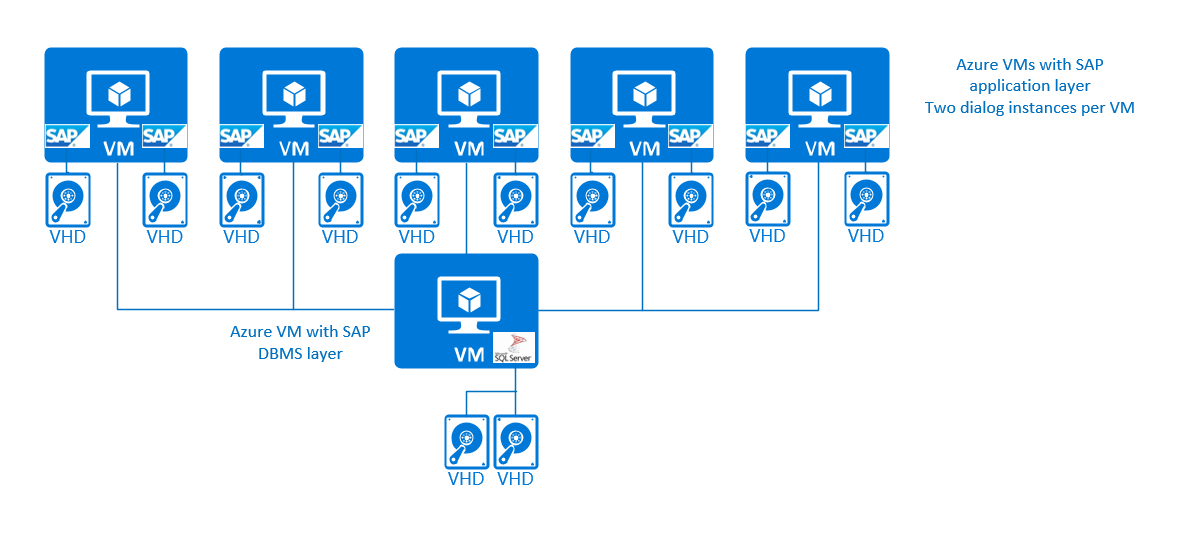
För förenklingen gjorde vi ingen skillnad mellan SAP Central Services- och SAP-dialoginstanser i SAP-programlagret. I den här enkla konfigurationen på 3 nivåer skulle det inte finnas något skydd för hög tillgänglighet för SAP Central Services. För produktionssystem rekommenderas det inte att lämna SAP Central Services oskyddat. Mer information om så kallade multi-SID-konfigurationer kring SAP Central Instances och hög tillgänglighet för sådana fler-SID-konfigurationer finns i senare avsnitt i det här dokumentet.
Skydd med hög tillgänglighet för SAP DBMS-lagret
När du vill distribuera SAP-produktionssystem måste du överväga frekvent standby-typ av konfigurationer med hög tillgänglighet. Särskilt med SAP HANA, där data måste läsas in i minnet innan du kan få tillbaka fullständig prestanda och skalbarhet, är Azure-tjänståterställning inte ett idealiskt mått för hög tillgänglighet.
I allmänhet stöder Microsoft endast konfigurationer och programvarupaket med hög tillgänglighet som beskrivs i SAP-arbetsbelastningsscenarierna. Du kan läsa samma instruktion i SAP-kommentaren #1928533. Microsoft tillhandahåller inte stöd för andra programvaruramverk från tredje part med hög tillgänglighet som inte dokumenteras av Microsoft med SAP-arbetsbelastning. I sådana fall är tredjepartsleverantören av ramverket för hög tillgänglighet den stödjande parten för konfigurationen med hög tillgänglighet som måste engageras av dig som kund i supportprocessen. Undantag kommer att nämnas i den här artikeln.
I allmänhet har Microsoft stöd för en begränsad uppsättning konfigurationer med hög tillgänglighet på virtuella Azure-datorer eller HANA-enheter för stora instanser.
För virtuella Azure-datorer stöds följande konfigurationer med hög tillgänglighet på DBMS-nivå:
- SAP HANA System Replication baserat på Linux Pacemaker på SUSE och Red Hat. Se de detaljerade artiklarna:
- SAP HANA-skalbara n+m-konfigurationer med Hjälp av Azure NetApp Files på SUSE och Red Hat. Information finns i följande artiklar:
- Distribuera ett SAP HANA-utskalningssystem med väntelägesnod på virtuella Azure-datorer med hjälp av Azure NetApp Files på SUSE Linux Enterprise Server}
- Distribuera ett SAP HANA-utskalningssystem med väntelägesnod på virtuella Azure-datorer med hjälp av Azure NetApp Files på Red Hat Enterprise Linux
- SQL Server-redundanskluster baserade på Windows Scale-Out File Services. Rekommendationen för produktionssystem är dock att använda SQL Server AlwaysOn i stället för klustring. SQL Server AlwaysOn ger bättre tillgänglighet med hjälp av separat lagring. Information beskrivs i den här artikeln:
- SQL Server AlwaysOn stöds med Windows-operativsystemet för SQL Server i Azure. Den här konfigurationen är standardrekommenderingen för SQL Server-produktionsinstanser i Azure. Information beskrivs i följande artiklar:
- Oracle Data Guard för Windows och Oracle Linux. Information om Oracle Linux finns i den här artikeln:
- IBM Db2 HADR på SUSE och RHEL Detaljerad dokumentation för SUSE och RHEL med pacemaker finns här:
- SAP ASE- och SAP maxDB-konfiguration enligt beskrivningen i följande dokument:
- Scenarier med hög tillgänglighet för HANA-instanser beskrivs i:
Viktigt!
För inget av de scenarier som beskrivs ovan stöder vi konfigurationer av flera DBMS-instanser på en virtuell dator. Innebär att i vart och ett av fallen kan endast en databasinstans distribueras per virtuell dator och skyddas med de beskrivna metoderna för hög tillgänglighet. Skydd av flera DBMS-instanser under samma Windows- eller Pacemaker-redundanskluster stöds INTE just nu. Oracle Data Guard stöds endast för enskilda instanser per vm-distributionsfall.
Olika databassystem gör det möjligt att vara värd för flera databaser under en DBMS-instans. Precis som med SAP HANA kan flera databaser finnas i flera databascontainrar (MDC). För fall där dessa konfigurationer för flera databaser fungerar inom en redundansklusterresurs stöds dessa konfigurationer. Konfigurationer som inte stöds är fall där flera klusterresurser skulle krävas. När det gäller konfigurationer där du skulle definiera flera SQL Server-tillgänglighetsgrupper under en SQL Server-instans.

Beroende på DBMS an/eller operativsystem kan komponenter som Azure-lastbalanserare behövas eller kanske inte krävs som en del av lösningsarkitekturen.
Specifikt för maxDB måste lagringskonfigurationen vara annorlunda. Med maxDB måste data och loggfiler finnas på delad lagring för konfigurationer med hög tillgänglighet. Endast för maxDB stöds delad lagring för hög tillgänglighet. För alla andra DBMS är separata lagringsstackar per nod de enda diskkonfigurationer som stöds.
Andra ramverk för hög tillgänglighet är kända för att finnas och är kända för att köras även på Microsoft Azure. Microsoft testade dock inte dessa ramverk. Om du vill skapa konfigurationen för hög tillgänglighet med dessa ramverk måste du arbeta med leverantören av programvaran för att:
- Utveckla en distributionsarkitektur
- Distribution av arkitekturen
- Stöd för arkitekturen
Viktigt!
Microsoft Azure Marketplace erbjuder en mängd olika mjuka apparater som tillhandahåller lagringslösningar ovanpå azure-intern lagring. Dessa mjuka installationer kan även användas för att skapa NFS-resurser som teoretiskt sett kan användas i SAP HANA-utskalningsdistributionerna där en väntelägesnod krävs. På grund av olika orsaker stöds ingen av dessa mjuka lagringsenheter för någon av DBMS-distributionerna av Microsoft och SAP i Azure. Distributioner av DBMS på SMB-resurser stöds inte alls just nu. Distributioner av DBMS på NFS-resurser är begränsade till NFS 4.1-resurser på Azure NetApp Files.
Hög tillgänglighet för SAP Central Service
SAP Central Services är en andra felpunkt i SAP-konfigurationen. Därför skulle du också behöva skydda dessa centraltjänstprocesser. Erbjudandet som stöds och dokumenteras för SAP-arbetsbelastningar lyder som:
- Windows Redundansklusterserver med Windows Scale-out File Services för sapmnt och global transportkatalog. Information beskrivs i artikeln:
- Windows Redundansklusterserver med SMB-resurs baserat på Azure NetApp Files för sapmnt och global transportkatalog. Information finns i artikeln:
- Windows Redundansklusterserver baserad på SIOS
Datakeeper. Även om det dokumenteras av Microsoft behöver du en supportrelation med SIOS, så att du kan kontakta SIOS-supporten när du använder den här lösningen. Information beskrivs i artikeln: - Pacemaker på SUSE-operativsystemet med att skapa en NFS-resurs med hög tillgänglighet med hjälp av två virtuella SUSE-datorer och
drdbför filreplikering. Information finns dokumenterad i artikeln - Pacemaker SUSE-operativsystem med hjälp av NFS-resurser som tillhandahålls av Azure NetApp Files. Information dokumenteras i
- Pacemaker på Red Hat-operativsystemet med NFS-resurs i ett
glusterfskluster. Information finns i artiklarna - Pacemaker på Red Hat-operativsystemet med NFS-resursen värdhanterad på Azure NetApp Files. Information beskrivs i artikeln
Av de listade lösningarna behöver du en supportrelation med SIOS för att stödja Datakeeper produkten och kontakta SIOS direkt om problem uppstår. Beroende på hur du har licensierat Windows, Red Hat och/eller SUSE-operativsystemet kan du också behöva ha ett supportavtal med din OS-leverantör för att ha fullt stöd för de angivna konfigurationerna med hög tillgänglighet.
Konfigurationen kan också visas som:

Till höger om grafiken visas sap Central Services med hög tillgänglighet. Förutom att ha SAP Central-tjänsterna skyddade med ett ramverk för redundanskluster som kan redundansväxla i felscenarier. Det finns en nödvändighet för en NFS- eller SMB-resurs med hög tillgänglighet eller en delad Windows-disk för att se till att sapmnt- och global transportkatalogen är tillgängliga oberoende av förekomsten av en enda virtuell dator. Ytterligare några av lösningarna, till exempel Windows Redundansklusterserver och Pacemaker, kommer att kräva en Azure-lastbalanserare för att dirigera eller omdirigera trafik till en felfri nod.
I listan som visas nämns inget om Oracle Linux-operativsystemet. Oracle Linux stöder inte Pacemaker som ett klusterramverk. Om du vill distribuera DITT SAP-system på Oracle Linux och du behöver ett ramverk för hög tillgänglighet för Oracle Linux måste du arbeta med tredjepartsleverantörer. En av leverantörerna är SIOS med sin Protection Suite för Linux som stöds av SAP på Azure. Mer information finns i SAP-kommentar #1662610 – Supportinformation för SIOS Protection Suite för Linux för mer information.
Lagring som stöds med SAP Central Services-scenarier som anges ovan
Eftersom endast en delmängd av Azure-lagringstyper ger högtillgängliga NFS- eller SMB-resurser den kvaliteten för användningen i våra SAP Central Services-klusterscenarier en lista över lagringstyper som stöds
- Windows Redundansklusterserver med Windows Scale-out File Server kan distribueras på alla inbyggda Azure-lagringstyper, förutom Azure NetApp Files. Rekommendationen är dock att använda Premium Storage på grund av överlägsna serviceavtal i dataflöde och IOPS.
- Windows Redundansklusterserver med SMB på Azure NetApp Files stöds på Azure NetApp Files. SMB-resurser som finns i Azure Premium-filtjänster stöds även för det här scenariot. Azure Standard Files stöds inte
- Windows Redundansklusterserver med delad Windows-disk baserat på SIOS
Datakeeperkan distribueras på alla inbyggda Azure-lagringstyper, förutom Azure NetApp Files. Rekommendationen är dock att använda Premium Storage på grund av överlägsna serviceavtal i dataflöde och IOPS. - SUSE eller Red Hat Pacemaker med NFS-resurser på Azure NetApp Files stöds.
- SUSE eller Red Hat Pacemaker med hjälp av NFS-resurser på Azure Premium Files med hjälp av LRS eller ZRS som stöds. Azure Standard Files stöds inte
- SUSE Pacemaker med hjälp av en
drdbkonfiguration mellan två virtuella datorer stöds med inbyggda Azure-lagringstyper, förutom Azure NetApp Files. Vi rekommenderar dock att du använder en av tjänsterna från första part med Azure Premium Files eller Azure NetApp Files. - Red Hat Pacemaker som använder
glusterfsför att tillhandahålla NFS-resurs stöds med hjälp av interna Azure-lagringstyper, förutom Azure NetApp Files. Vi rekommenderar dock att du använder en av tjänsterna från första part med Azure Premium Files eller Azure NetApp Files.
Viktigt!
Microsoft Azure Marketplace erbjuder en mängd olika mjuka apparater som tillhandahåller lagringslösningar ovanpå azure-intern lagring. Dessa mjuka lagringsenheter kan användas för att skapa NFS- eller SMB-resurser samt som teoretiskt sett kan användas i de redundansklustrade SAP Central Services också. Dessa lösningar stöds inte direkt för SAP-arbetsbelastningar av Microsoft. Om du bestämmer dig för att använda en sådan lösning för att skapa din NFS- eller SMB-resurs måste stöd för SAP Central Service-konfigurationen tillhandahållas av den tredje part som äger programvaran i den mjuka lagringsinstallationen.
Redundanskluster för SAP Central Services med flera SID
För att minska antalet virtuella datorer som behövs i stora SAP-landskap tillåter SAP körning av SAP Central Services-instanser av flera olika SAP-system i konfiguration av redundanskluster. Tänk dig fall där du har 30 eller fler NetWeaver- eller S/4HANA-produktionssystem. Utan kluster med flera SID skulle dessa konfigurationer kräva 60 eller fler virtuella datorer i 30 eller fler konfigurationer av Windows- eller Pacemaker-redundanskluster. Om du distribuerar flera centrala SAP-tjänster över två noder i en redundansklusterkonfiguration kan du minska antalet virtuella datorer avsevärt. Men att distribuera flera SAP Central-tjänstinstanser på en enda klusterkonfiguration med två noder har också vissa nackdelar. Problem med en enskild virtuell dator i klusterkonfigurationen gäller för flera SAP-system. Underhåll av gästoperativsystemet som körs i klusterkonfigurationen kräver mer samordning eftersom flera SAP-produktionssystem påverkas. Verktyg som SAP LaMa stöder inte klustring med flera SID i deras systemkloningsprocess.
I Azure stöds en klusterkonfiguration med flera SID för Windows-operativsystemet med ENSA1 och ENSA2. Rekommendationen är inte att kombinera den äldre Enqueue Replication Service-arkitekturen (ENSA1) med den nya arkitekturen (ENSA2) på ett kluster med flera SID. Information om en sådan arkitektur finns dokumenterad i artiklarna
- Hög tillgänglighet för SAP ASCS/SCS-instans med flera SID med Windows Server-redundansklustring och delad disk i Azure
- SAP ASCS/SCS-instans med hög tillgänglighet för flera SID med Windows Server-redundanskluster och filresurs i Azure
För SUSE stöds även ett multi-SID-kluster baserat på Pacemaker. Hittills stöds konfigurationen för:
- Högst fem SAP ASCS/SCS-instanser
- Den gamla köreplikeringsserverns isarkitektur (ENSA1)
- Konfigurationer av pacemakerkluster med två noder
Konfigurationen dokumenteras i guide för hög tillgänglighet för SAP NetWeaver på virtuella Azure-datorer på SUSE Linux Enterprise Server för SAP-program med flera SID
Ett multi-SID-kluster med Enqueue Replication-servern ser schematiskt ut som

SAP HANA-utskalningsscenarier
SAP HANA-utskalningsscenarier stöds för en delmängd av de HANA-certifierade virtuella Azure-datorerna enligt listan i SAP HANA-maskinvarukatalogen. Alla virtuella datorer som har markerats med "Ja" i kolumnen "Klustring" kan användas för antingen OLAP- eller S/4HANA-utskalning. Konfigurationer utan vänteläge stöds med Azure Storage-typerna av:
- Azure Premium Storage v1, inklusive Azure Write-acceleratorn för volymen /hana/log
- Azure Premium Storage v2
- Ultradisk
- Azure NetApp Files
SAP HANA-utskalningskonfigurationer för OLAP eller S/4HANA med väntelägesnoder stöds exklusivt med NFS som delas på Azure NetApp Files.
Mer information om exakta lagringskonfigurationer med eller utan väntelägesnod finns i artiklarna:
- Lagringskonfigurationer för virtuella SAP HANA Azure-datorer
- Distribuera ett SAP HANA-utskalningssystem med väntelägesnod på virtuella Azure-datorer med hjälp av Azure NetApp Files på SUSE Linux Enterprise Server
- Distribuera ett SAP HANA-utskalningssystem med väntelägesnod på virtuella Azure-datorer med hjälp av Azure NetApp Files på Red Hat Enterprise Linux
- SAP-supportanteckning #2080991
Scenario för haveriberedskap
Det finns en mängd olika scenarier för haveriberedskap som stöds. Vi definierar katastrofarkitekturer som arkitekturer, vilket bör kompensera för att en fullständig Azure-region hamnar utanför rutnätet. Det innebär att vi behöver haveriberedskapsmålet för att vara en annan Azure-region som mål för att köra ditt SAP-landskap. Vi separerar metoder och konfigurationer i DBMS-lagret och icke-DBMS-lagret.
DBMS-lager
För DBMS-lagret stöds konfigurationer som använder dbms-inbyggda replikeringsmekanismer som Always On, Oracle Data Guard, Db2 HADR, SAP ASE Always-On eller HANA System Replication. Det är obligatoriskt att replikeringsströmmen i sådana fall är asynkron, i stället för synkron som i vanliga scenarier med hög tillgänglighet som distribueras i en enda Azure-region. Ett typiskt exempel på en sådan dbms-haveriberedskapskonfiguration som stöds beskrivs i artikeln SAP HANA-tillgänglighet i Azure-regioner. Den andra bilden i det avsnittet beskriver ett scenario med HANA som ett exempel. De huvuddatabaser som stöds för SAP-program kan alla distribueras i ett sådant scenario.
Det stöds att använda en mindre virtuell dator som målinstans i haveriberedskapsregionen eftersom den virtuella datorn inte upplever den fullständiga arbetsbelastningstrafiken. När du gör det måste du tänka på följande:
- Mindre typer av virtuella datorer tillåter inte att många anslutna diskar än mindre virtuella datorer
- Mindre virtuella datorer har mindre dataflöde för nätverk och lagring
- Storleksändring mellan vm-familjer kan vara ett problem när de olika virtuella datorerna samlas in i en Azure-tillgänglighetsuppsättning eller när storleksändringen ska ske mellan M-seriens familj och Mv2-serien med virtuella datorer
- Processor- och minnesförbrukning för databasinstansen kan ta emot dataströmmen med minimal fördröjning och tillräckligt med processor- och minnesresurser för att tillämpa dessa ändringar med minimal fördröjning på data
Mer information om begränsningar för olika VM-storlekar finns på sidan VM-storlekar
En annan metod som stöds för att distribuera ett DR-mål är att ha en andra DBMS-instans installerad på en virtuell dator som kör en icke-produktionsbaserad DBMS-instans av en SAP-instans som inte är produktion. Detta kan vara lite mer utmanande eftersom du måste ta reda på vad som krävs för minne, CPU-resurser, nätverksbandbredd och lagringsbandbredd för de specifika målinstanser som ska fungera som huvudinstans i DR-scenariot. Särskilt i HANA rekommenderar vi starkt att du konfigurerar den instans som fungerar som DR-mål på en delad värd så att data inte förinstalleras i DR-målinstansen.
Kommentar
Användningen av Azure Site Recovery har inte testats för DBMS-distributioner under SAP-arbetsbelastning. Därför stöds det inte för DBMS-lagret av SAP-system just nu. Andra replikeringsmetoder från Microsoft och SAP som inte visas stöds inte. Användning av programvara från tredje part för replikering av DBMS-lagret av SAP-system mellan olika Azure-regioner måste stödjas av leverantören av programvaran och kommer inte att stödjas via Microsofts och SAP-supportkanaler.
Icke-DBMS-lager
För SAP-programskiktet och eventuella resurser eller lagringsplatser som behövs används de två huvudscenarierna av kunderna:
- Målen för haveriberedskap i den andra Azure-regionen används inte i produktions- eller icke-produktionssyfte. I det här scenariot distribueras inte de virtuella datorer som fungerar som haveriberedskapsmål och avbildningen och ändringarna i avbildningarna av SAP-programlagret för produktion replikeras till haveriberedskapsregionen. En funktion som kan utföra en sådan uppgift är Azure Site Recovery. Azure Site Recovery stöder ett azure-till-Azure-replikeringsscenario som det här.
- Målen för haveriberedskap är virtuella datorer som faktiskt används av icke-produktionssystem. Hela SAP-landskapet är fördelat över två olika Azure-regioner med produktionssystem vanligtvis i en region och icke-produktionssystem i en annan region. I många kunddistributioner har kunden ett icke-produktionssystem som motsvarar ett produktionssystem. Kunden har produktionsprograminstanser förinstallerade på programnivåns icke-produktionssystem. I en redundanshändelse skulle icke-produktionsinstanserna stängas av, de virtuella namnen på de virtuella produktionsdatorerna flyttas till de virtuella datorerna som inte är produktionsbaserade (efter att nya IP-adresser har tilldelats i DNS) och de förinstallerade produktionsinstanserna kommer igång
SAP Central Services-kluster
SAP Central Services-kluster som använder delade diskar (Windows), SMB-resurser (Windows) eller NFS-resurser är lite svårare att replikera. På Windows-sidan är Windows Storage Replication en möjlig lösning. I Linux är rsync en fungerande lösning. Replikering mellan regioner av Azure NetApp Files är också en fungerande lösning.
Scenario som inte stöds
Det finns en lista över scenarier som inte stöds för SAP-arbetsbelastningar i Azure-arkitekturer. Stöds inte innebär att SAP och Microsoft inte kan leverera stöd för dessa konfigurationer och måste skjuta upp till en eventuell berörd tredje part som tillhandahöll programvara för att upprätta sådana arkitekturer. Två av kategorierna är:
- Lagring mjuka apparater: Det finns olika lagring mjuka apparater på marknaden. Vissa leverantörer erbjuder egen dokumentation om hur de använder sina mjuka lagringsinstallationer i Azure som är relaterade till SAP-programvara. Leverantören av den mjuka lagringsinstallationen måste tillhandahålla stöd för konfigurationer eller distributioner som omfattar sådana mjuka lagringsenheter. Det här faktumet visas också i SAP-supportanteckningen #2015553
- Ramverk för hög tillgänglighet: Endast Pacemaker och Windows Server-redundanskluster stöds ramverk för hög tillgänglighet för SAP-arbetsbelastningar i Azure. Som tidigare nämnts beskrivs och dokumenteras lösningen för SIOS
Datakeeperav Microsoft. Komponenterna i SIOSDatakeepermåste dock stödjas via SIOS som leverantör som tillhandahåller dessa komponenter. SAP listade även andra certifierade ramverk för hög tillgänglighet i olika SAP-anteckningar. Vissa av dem har även certifierats av tredjepartsleverantören för Azure. Stöd för konfigurationer som använder dessa produkter måste dock tillhandahållas av produktleverantören. Olika leverantörer har olika integrering i SAP-supportprocesserna. Du bör klargöra vilken supportprocess som fungerar bäst för den specifika leverantören innan du bestämmer dig för att använda produkten med SAP-konfigurationer som distribuerats i Azure. - Delade diskkluster där databasfiler finns på delade diskar stöds inte, förutom maxDB. För alla andra databaser är lösningen som stöds att ha separata lagringsplatser i stället för en SMB- eller NFS-resurs eller delad disk för att konfigurera scenarier med hög tillgänglighet
Andra scenarier som inte stöds är scenarier som:
- Distributionsscenarier som introducerar en större nätverksfördröjning mellan SAP-programnivån och SAP DBMS-nivån som i NetWeaver, S/4HANA och t.ex.
Hybris. Detta inkluderar:- Distribuera en av nivåerna lokalt medan den andra nivån distribueras i Azure
- Distribuera SAP-programnivån för ett system i en annan Azure-region än DBMS-nivån
- Distribuera en nivå i datacenter som är samlokala till Azure och den andra nivån i Azure, förutom när ett sådant arkitekturmönster tillhandahålls av en intern Azure-tjänst
- Distribuera virtuella nätverksinstallationer mellan SAP-programnivån och DBMS-lagret
- Använda lagring som finns i datacenter som finns i Azure-datacenter för SAP DBMS-nivån eller sap global transportkatalog
- Distribuera de två lagren med två olika molnleverantörer. Du kan till exempel distribuera DBMS-nivån i Oracle Cloud Infrastructure och programnivån i Azure
- Multi-Instance HANA Pacemaker-klusterkonfigurationer
- Windows-klusterkonfigurationer med delade diskar via SOFS eller SMB på ANF för SAP-databaser som stöds i Windows. I stället rekommenderar vi användning av intern replikering med hög tillgänglighet för de specifika databaserna och använder separata lagringsstackar
- Distribution av SAP-databaser som stöds i Linux med databasfiler som finns i NFS-resurser ovanpå ANF förutom SAP HANA, Oracle på Oracle Linux och Db2 på Suse och Red Hat
- Distribution av Oracle DBMS på andra gästoperativsystem än Windows och Oracle Linux. Se även SAP-supportanteckning #2039619
Scenarion som vi inte testade och därför inte har någon erfarenhet av lista som:
- Azure Site Recovery replikerar virtuella DBMS-lagerdatorer. Därför rekommenderar vi att du använder databasens inbyggda asynkrona replikeringsfunktion för potentiell haveriberedskapskonfiguration
Nästa steg
Läs nästa steg i planeringen och implementeringen av Azure Virtual Machines för SAP NetWeaver