Felsöka en Azure AI Search-kompetensuppsättning i Azure-portalen
Starta en portalbaserad felsökningssession för att identifiera och lösa fel, validera ändringar och skicka ändringar till en befintlig kompetensuppsättning i din Azure AI-usluga pretrage.
En felsökningssession är en cachelagrad indexerare och kompetensuppsättningskörning, begränsad till ett enda dokument, som du kan använda för att redigera och testa ändringar i kompetensuppsättningen interaktivt. När du är klar med felsökningen kan du spara ändringarna i kunskapsuppsättningen.
Bakgrund om hur en felsökningssession fungerar finns i Felsöka sessioner i Azure AI Search. Information om hur du övar ett felsökningsarbetsflöde med ett exempeldokument finns i Självstudie: Felsöka sessioner.
Förutsättningar
En Azure AI-usluga pretrage. Vi rekommenderar att du använder en systemtilldelad hanterad identitet och rolltilldelningar som gör att Azure AI Search kan skriva till Azure Storage och anropa De Azure AI-resurser som används i kompetensuppsättningen.
Ett Azure Storage-konto som används för att spara sessionstillstånd.
En befintlig berikningspipeline, inklusive en datakälla, en kompetensuppsättning, en indexerare och ett index.
För rolltilldelningar måste söktjänstens identitet ha:
Cognitive Services-användarbehörigheter för Azure AI-multiservicekontot som används av kompetensuppsättningen.
Behörigheter för Storage Blob Data-deltagare i Azure Storage. I annat fall planerar du att använda en fullständig åtkomst niska veze för felsökningssessionsanslutningen till Azure Storage.
Om Azure Storage-kontot finns bakom en brandvägg konfigurerar du det för att tillåta åtkomst till söktjänsten.
Begränsningar
Felsökningssessioner fungerar med alla allmänt tillgängliga indexeringsdatakällor och de flesta förhandsgranskningsdatakällor, med följande undantag:
SharePoint Online-indexerare.
Azure Cosmos DB för MongoDB-indexeraren.
Om en rad misslyckas under indexet och det inte finns några motsvarande metadata för Azure Cosmos DB för NoSQL kanske felsökningssessionen inte väljer rätt rad.
Om en partitionerad samling tidigare inte partitionerades för SQL-API:et för Azure Cosmos DB hittar inte felsökningssessionen dokumentet.
För anpassade kunskaper stöds inte en användartilldelad hanterad identitet för en felsökningssessionsanslutning till Azure Storage. Som anges i kraven kan du använda en systemhanterad identitet eller ange en fullständig åtkomst niska veze som innehåller en nyckel. Mer information finns i Ansluta en söktjänst till andra Azure-resurser med hjälp av en hanterad identitet.
Skapa en felsökningssession
Logga in på Azure-portalen och leta reda på söktjänsten.
På den vänstra menyn väljer du Sökhantering>Felsökningssessioner.
I åtgärdsfältet längst upp väljer du Lägg till felsökningssession.
I Namn på felsökningssession anger du ett namn som hjälper dig att komma ihåg vilken kompetensuppsättning, indexerare och datakälla som felsökningssessionen handlar om.
I Indexer-mallen väljer du den indexerare som driver den kompetensuppsättning som du vill felsöka. Kopior av både indexeraren och kunskapsuppsättningen används för att initiera sessionen.
I Lagringskonto hittar du ett allmänt lagringskonto för cachelagring av felsökningssessionen.
Välj Autentisera med hanterad identitet om du tidigare har tilldelat behörigheter för Storage Blob Data Contributor till den systemhanterade identiteten för söktjänsten.
Välj Spara.
- Azure AI Search skapar en blobcontainer på Azure Storage med namnet ms-az-cognitive-search-debugsession.
- I containern skapas en mapp med det namn som du angav för sessionsnamnet.
- Den startar felsökningssessionen.
En felsökningssession öppnas på inställningssidan. Du kan göra ändringar i den inledande konfigurationen och åsidosätta alla standardvärden.
I Storage niska veze kan du ange niska veze eller ändra lagringskontot.
I Dokument att felsöka väljer du det första dokumentet i indexet eller väljer ett specifikt dokument. Om du väljer ett visst dokument, beroende på datakällan, blir du ombedd att ange en URI eller ett rad-ID.
Om ditt specifika dokument är en blob anger du blob-URI:n. Du hittar URI:n på blobegenskapssidan i portalen.
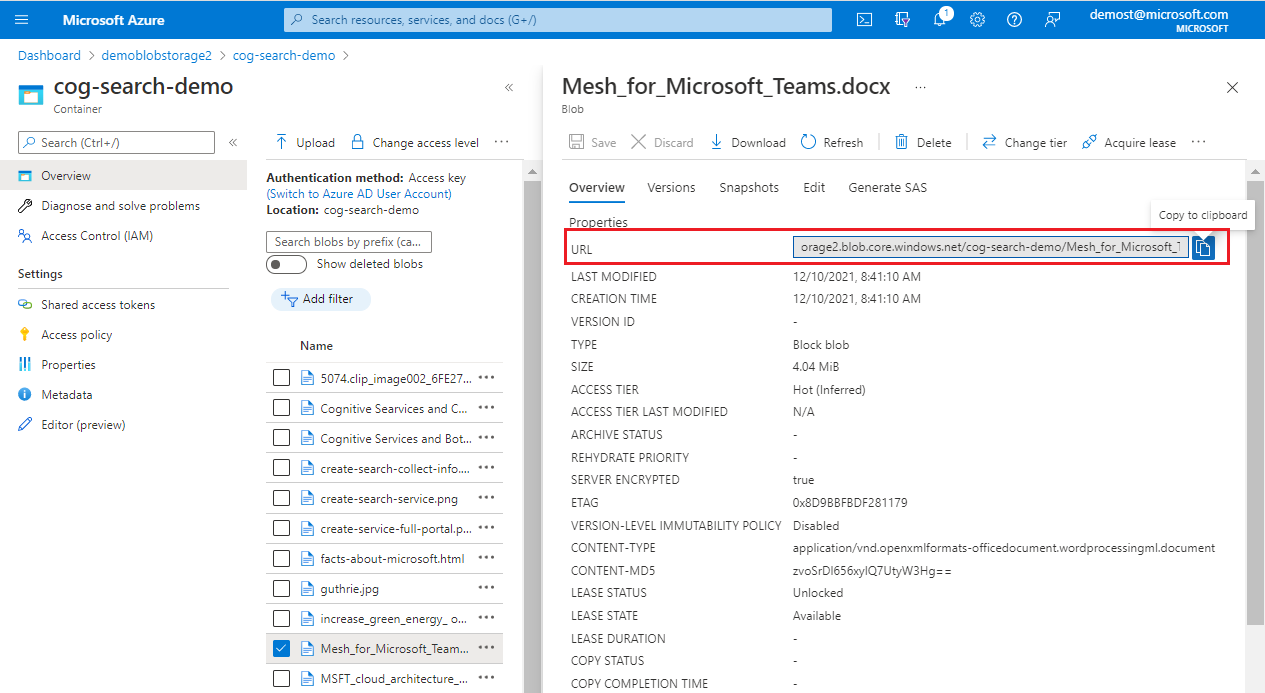
I Indexer-inställningar kan du också ange eventuella inställningar för indexeringskörning som används för att skapa sessionen. Inställningarna bör spegla de inställningar som används av den faktiska indexeraren. Alla indexerare som du anger i en felsökningssession har ingen effekt på själva indexeraren.
Om du har gjort ändringar väljer du Spara session följt av Kör.


Felsökningssessionen börjar med att köra indexeraren och kunskapsuppsättningen i det valda dokumentet. Dokumentets innehåll och metadata är synliga och tillgängliga i sessionen.
En felsökningssession kan avbrytas medan den körs med knappen Avbryt . Om du trycker på knappen Avbryt bör du kunna analysera partiella resultat.
Det förväntas att en felsökningssession tar längre tid att köra än indexeraren eftersom den genomgår extra bearbetning.
Börja med fel och varningar
Indexerarens körningshistorik i portalen ger dig den fullständiga fel- och varningslistan för alla dokument. I en felsökningssession är felen och varningarna begränsade till ett dokument. Du kan gå igenom den här listan, göra dina ändringar och sedan gå tillbaka till listan för att kontrollera om problem har lösts.
Kom ihåg att en felsökningssession baseras på ett dokument från hela indexet. Om indata eller utdata ser fel ut kan problemet vara specifikt för dokumentet. Du kan välja ett annat dokument för att bekräfta om fel och varningar är genomgripande eller specifika för ett enda dokument.
Välj Fel eller Varningar för en lista över problem.

Vi rekommenderar att du löser problem med indata innan du går vidare till utdata.
Följ dessa steg för att bevisa om en ändring löser ett fel:
Välj Spara i fönstret kunskapsinformation för att bevara dina ändringar.
Välj Kör i sessionsfönstret för att anropa körning av kompetensuppsättningar med den ändrade definitionen.
Gå tillbaka till Fel eller Varningarför att se om antalet minskas.
Visa berikat eller genererat innehåll
AI-berikande pipelines extraherar eller härleder information och struktur från källdokument, vilket skapar ett berikat dokument i processen. Ett berikat dokument skapas först under dokumentets sprickbildning och fylls med en rotnod (/document), plus noder för allt innehåll som lyfts direkt från datakällan, till exempel metadata och dokumentnyckeln. Fler noder skapas av färdigheter under färdighetskörningen, där varje kunskapsutdata lägger till en ny nod i berikningsträdet.
Allt innehåll som skapas eller används av en kompetensuppsättning visas i uttrycksutvärderingen. Du kan hovra över länkarna för att visa varje indata- eller utdatavärde i det berikade dokumentträdet. Följ dessa steg om du vill visa indata eller utdata för varje färdighet:
I en felsökningssession expanderar du den blå pilen för att visa sammanhangskänslig information. Som standard är informationen den berikade dokumentdatastrukturen. Men om du väljer en färdighet eller en mappning handlar informationen om det objektet.
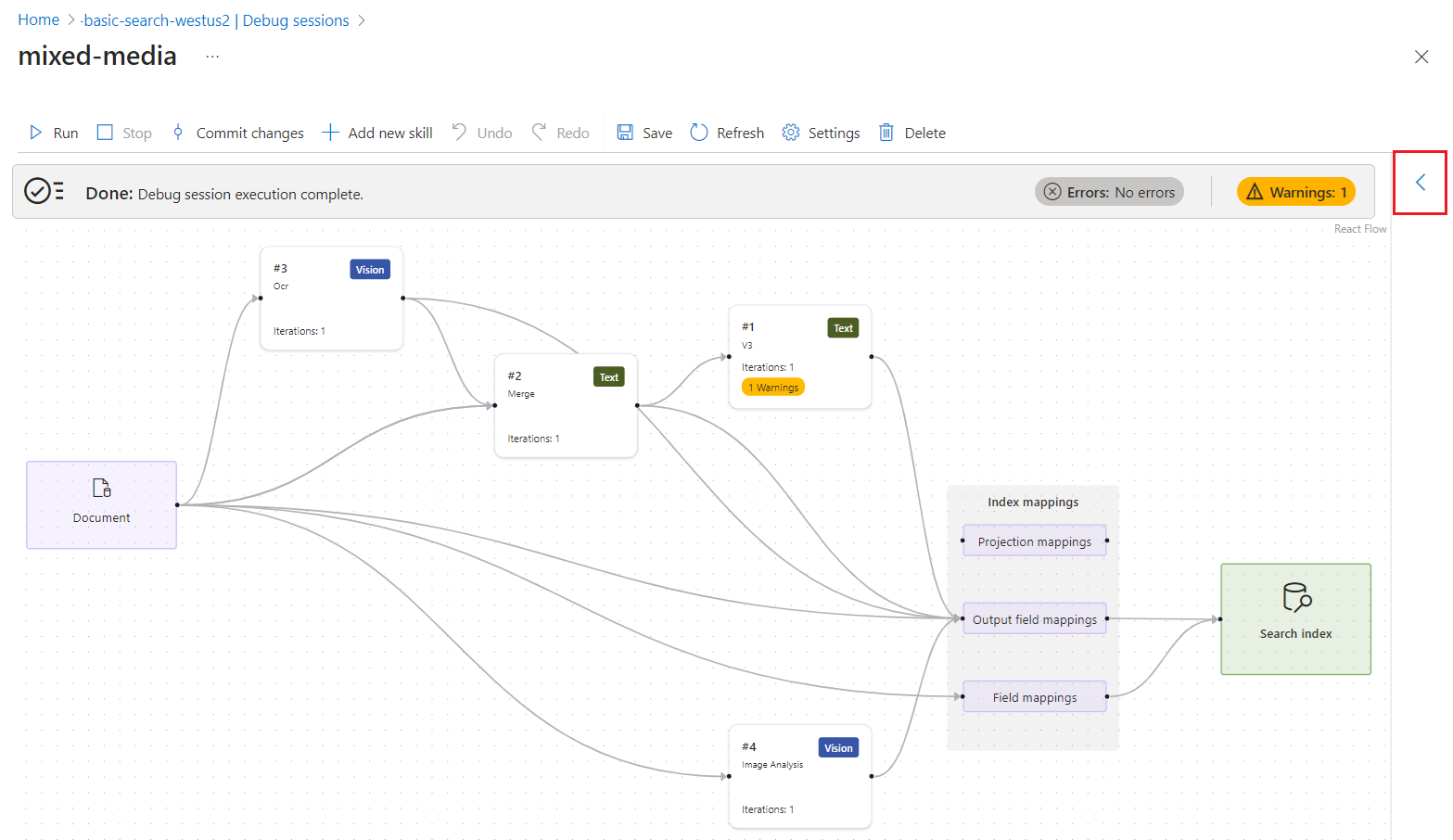
Välj en färdighet.
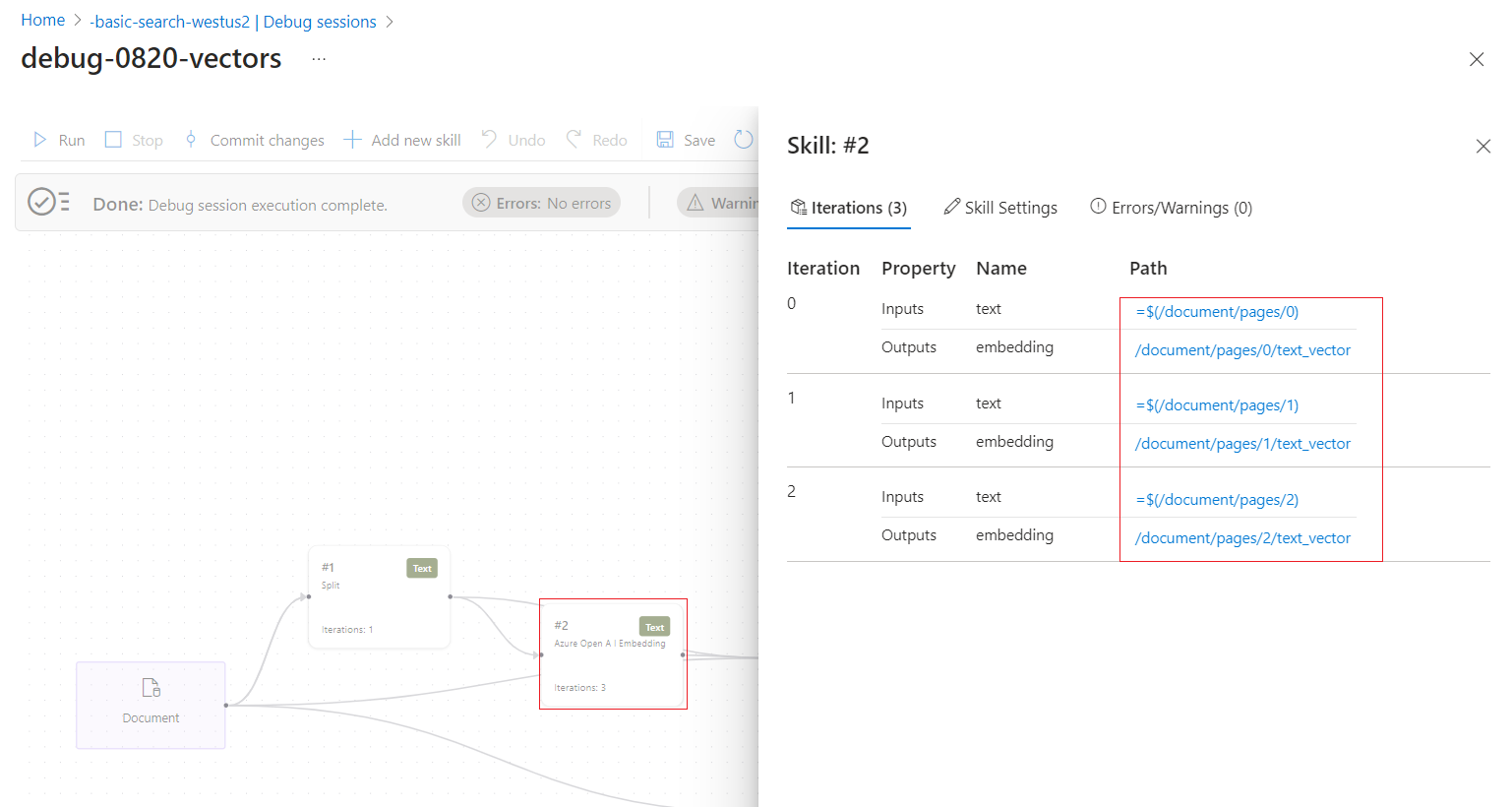
Följ länkarna för att öka detaljnivån i kompetensbearbetningen. Följande skärmbild visar till exempel utdata från den första iterationen av färdigheten Textdelning.




Kontrollera indexmappningar
Om kunskaper genererar utdata men sökindexet är tomt kontrollerar du fältmappningarna. Fältmappningar anger hur innehållet flyttas från pipelinen och till ett sökindex.

Välj ett av mappningsalternativen och expandera informationsvyn för att granska käll- och måldefinitioner.
Projektionsmappningar finns i kompetensuppsättningar som tillhandahåller integrerad vektorisering, till exempel de färdigheter som skapas av guiden Importera och vektorisera data. Dessa mappningar avgör mappningar för överordnade och underordnade fält (segment) och om ett sekundärt index skapas för bara segmenterat innehåll
Mappningar av utdatafält finns i indexerare och används när kompetensuppsättningar anropar inbyggda eller anpassade kunskaper. Dessa mappningar används för att ange datasökvägen från en nod i berikningsträdet till ett fält i sökindexet. Mer information om sökvägar finns i syntaxen för anrikningsnodsökväg.
Fältmappningar finns i indexeringsdefinitioner och de upprättar datasökvägen från rådata i datakällan och ett fält i indexet. Du kan också använda fältmappningar för att lägga till kodnings- och avkodningssteg.
I det här exemplet visas information om en projektionsmappning. Du kan redigera JSON för att åtgärda eventuella mappningsproblem.

Redigera kunskapsdefinitioner
Om fältmappningarna är korrekta kontrollerar du enskilda kunskaper om konfiguration och innehåll. Om en färdighet inte kan generera utdata kanske den saknar en egenskap eller parameter, som kan fastställas genom fel- och valideringsmeddelanden.
Andra problem, till exempel ett ogiltigt kontext- eller indatauttryck, kan vara svårare att lösa eftersom felet talar om för dig vad som är fel, men inte hur du åtgärdar det. Hjälp med kontext- och indatasyntax finns i Referensberikningar i en Azure AI Search-kompetensuppsättning. Hjälp med enskilda meddelanden finns i Felsöka vanliga indexeringsfel och varningar.
Följande steg visar hur du hämtar information om en färdighet.
Välj en färdighet på arbetsytan. Fönstret Kunskapsinformation öppnas till höger.
Redigera en färdighetsdefinition med hjälp av Kunskapsinställningar. Du kan redigera JSON direkt.
Kontrollera sökvägssyntaxen för att referera till noder i ett berikande träd. Följande är några av de vanligaste indatasökvägarna:
/document/contentför textsegment. Den här noden fylls i från blobens innehållsegenskap./document/merged_contentför textsegment i kunskapsuppsättningar som innehåller kunskaper om sammanslagning av text./document/normalized_images/*för text som identifieras eller härleds från bilder.
Felsöka en anpassad färdighet lokalt
Anpassade kunskaper kan vara svårare att felsöka eftersom koden körs externt, så felsökningssessionen kan inte användas för att felsöka dem. I det här avsnittet beskrivs hur du lokalt felsöker din anpassade webb-API-färdighet, felsökningssession, Visual Studio Code och ngrok eller Tunnelmole. Den här tekniken fungerar med anpassade kunskaper som körs i Azure Functions eller något annat webbramverk som körs lokalt (till exempel FastAPI).
Hämta en offentlig URL
I det här avsnittet beskrivs två metoder för att hämta en offentlig URL till en anpassad färdighet.
Använda Tunnelmole
Tunnelmole är ett tunnelverktyg med öppen källkod som kan skapa en offentlig URL som vidarebefordrar begäranden till din lokala dator via en tunnel.
Installera Tunnelmole:
- npm:
npm install -g tunnelmole - Linux:
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac:
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows: Installera med npm. Eller om du inte har NodeJS installerat laddar du ned den förkompilerade .exe-filen för Windows och placerar den någonstans i din PATH.
- npm:
Kör det här kommandot för att skapa en ny tunnel:
tmole 7071Du bör se ett svar som ser ut så här:
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071I föregående exempel
https://m5hdpb-ip-49-183-170-144.tunnelmole.netvidarebefordras till porten7071på den lokala datorn, vilket är standardporten där Azure-funktioner exponeras.
Använda ngrok
ngrok är en populär, sluten källa, plattformsoberoende program som kan skapa en url för tunneltrafik eller vidarebefordran så att internetbegäranden når din lokala dator. Använd ngrok för att vidarebefordra begäranden från en berikningspipeline i söktjänsten till datorn för att tillåta lokal felsökning.
Installera ngrok.
Öppna en terminal och gå till mappen med den körbara ngrok-filen.
Kör ngrok med följande kommando för att skapa en ny tunnel:
ngrok http 7071Kommentar
Som standard exponeras Azure-funktioner på 7071. Andra verktyg och konfigurationer kan kräva att du anger en annan port.
När ngrok startar kopierar och sparar du url:en för offentlig vidarebefordran för nästa steg. Vidarebefordrings-URL:en genereras slumpmässigt.
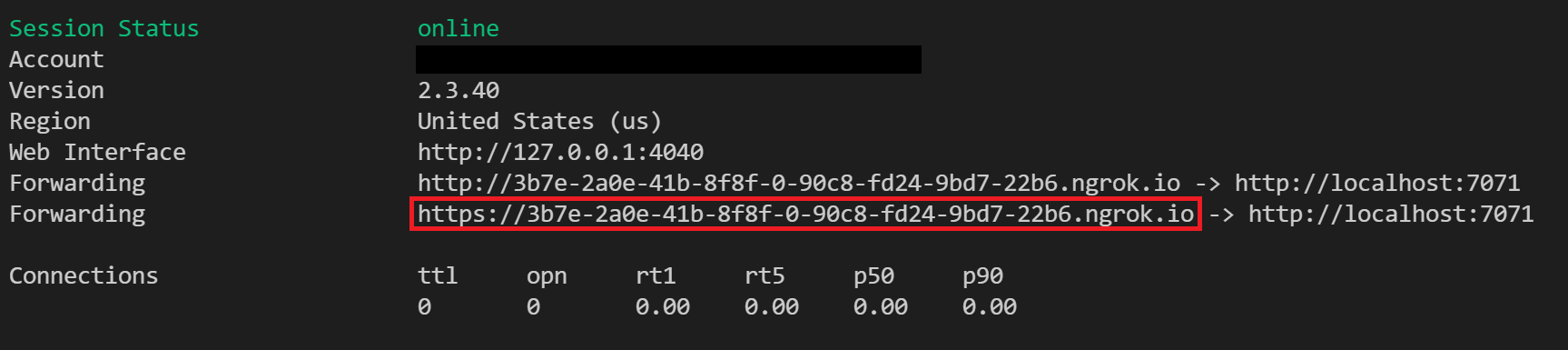
Konfigurera i Azure Portal
När du har en offentlig URL för din anpassade kompetens ändrar du din anpassade webb-API Skill URI i en felsökningssession för att anropa Url:en för Tunnelmole- eller ngrok-vidarebefordran. Se till att lägga till "/api/FunctionName" när du använder Azure Function för att köra koden för kompetensuppsättningen.
Du kan redigera kunskapsdefinitionen i avsnittet Kunskapsinställningar i fönstret Kunskapsinformation .
Testa koden
Nu ska nya begäranden från felsökningssessionen skickas till din lokala Azure-funktion. Du kan använda brytpunkter i Visual Studio Code för att felsöka koden eller köra den steg för steg.
Nästa steg
Nu när du förstår layouten och funktionerna i det visuella redigeringsprogrammet för felsökningssessioner kan du prova självstudien för en praktisk upplevelse.