Självstudie: Åtgärda en kompetensuppsättning med hjälp av felsökningssessioner
I Azure AI Search samordnar en kompetensuppsättning de färdigheter som analyserar, transformerar eller skapar sökbart innehåll. Ofta blir utdata från en färdighet indata för en annan. När indata är beroende av utdata kan misstag i definitioner för kompetensuppsättningar och fältassociationer resultera i missade åtgärder och data.
Felsökningssessioner är ett Azure-portalverktyg som ger en holistisk visualisering av en kompetensuppsättning som körs i Azure AI Search. Med det här verktyget kan du öka detaljnivån för specifika steg för att enkelt se var en åtgärd kan falla ned.
I den här artikeln använder du Felsökningssessioner för att hitta och åtgärda saknade indata och utdata. Självstudien är allomfattande. Den innehåller exempeldata, en REST-fil som skapar objekt och instruktioner för felsökning av problem i kompetensuppsättningen.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Azure AI Search. Skapa en tjänst eller hitta en befintlig tjänst under din aktuella prenumeration. Du kan använda en kostnadsfri tjänst för den här självstudien. Den kostnadsfria nivån ger inte stöd för hanterad identitet för en Azure AI-usluga pretrage. Du måste använda nycklar för anslutningar till Azure Storage.
Azure Storage-konto med Blob Storage, används som värd för exempeldata och för att spara cachelagrade data som skapats under en felsökningssession. Om du använder en kostnadsfri söktjänst måste lagringskontot ha nycklar för delad åtkomst aktiverade och det måste tillåta åtkomst till det offentliga nätverket.
Visual Studio Code med en REST-klient.
Exempel på filen debug-sessions.rest som används för att skapa berikningspipelinen.
Kommentar
I den här självstudien används även Azure AI-tjänster för språkidentifiering, entitetsigenkänning och extrahering av nyckelfraser. Eftersom arbetsbelastningen är så liten används Azure AI-tjänster i bakgrunden för kostnadsfri bearbetning för upp till 20 transaktioner. Det innebär att du kan slutföra den här övningen utan att behöva skapa en fakturerbar Azure AI-tjänstresurs.
Konfigurera exempeldata
Det här avsnittet skapar exempeldatauppsättningen i Azure Blob Storage så att indexeraren och kompetensuppsättningen har innehåll att arbeta med.
Ladda ned exempeldata (clinical-trials-pdf-19), bestående av 19 filer.
Skapa ett Azure Storage-konto eller hitta ett befintligt konto.
Välj samma region som Azure AI Search för att undvika bandbreddsavgifter.
Välj kontotypen StorageV2 (generell användning V2).
Gå till sidorna för Azure Storage-tjänster i portalen och skapa en blobcontainer. Bästa praxis är att ange åtkomstnivån "privat". Ge containern
clinicaltrialdatasetnamnet .I containern väljer du Ladda upp för att ladda upp exempelfilerna som du laddade ned och uppackade i det första steget.
I portalen kopierar du niska veze för Azure Storage. Du kan hämta niska veze från Åtkomstnycklar för inställningar>i portalen.
Kopiera en nyckel och EN URL
I den här självstudien används API-nycklar för autentisering och auktorisering. Du behöver söktjänstens slutpunkt och en API-nyckel som du kan hämta från Azure-portalen.
Logga in på Azure-portalen, gå till sidan Översikt och kopiera URL:en. Här följer ett exempel på hur en slutpunkt kan se ut:
https://mydemo.search.windows.net.Under Inställningar>Nycklar kopierar du en administratörsnyckel. Administratörsnycklar används för att lägga till, ändra och ta bort objekt. Det finns två utbytbara administratörsnycklar. Kopiera någon av dem.
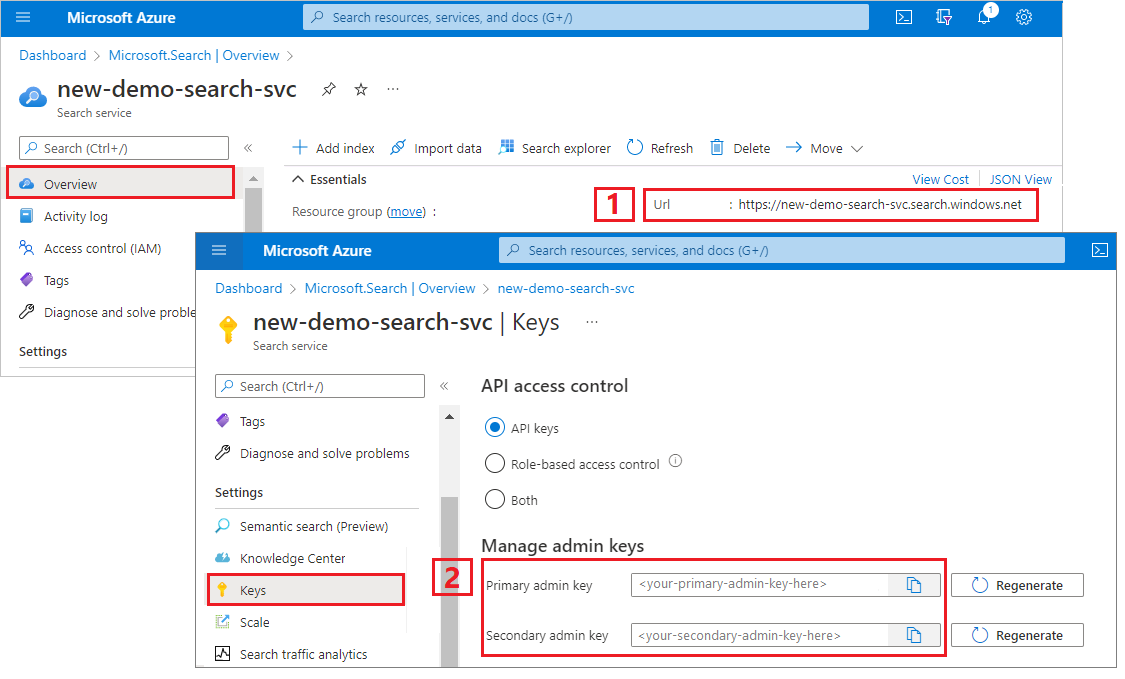
En giltig API-nyckel upprättar förtroende per begäran mellan programmet som skickar begäran och söktjänsten som hanterar den.
Skapa datakälla, kompetensuppsättning, index och indexerare
I det här avsnittet skapar du ett "buggy"-arbetsflöde som du kan åtgärda i den här självstudien.
Starta Visual Studio Code och öppna
debug-sessions.restfilen.Ange följande variabler: söktjänstens URL, api-nyckeln för söktjänsters administratör, lagring niska veze och namnet på blobcontainern som lagrar PDF-filerna.
Skicka varje begäran i tur och ordning. Det tar flera minuter att skapa indexeraren.
Stäng filen.
Kontrollera resultaten i portalen
Exempelkoden skapar avsiktligt ett buggy-index som en följd av problem som uppstod vid körning av kompetensuppsättningar. Problemet är att indexet saknar data.
I Azure-portalen går du till sidan Översikt för söktjänsten och väljer fliken Index.
Välj kliniska prövningar.
Ange den här JSON-frågesträngen i Sökutforskarens JSON-vy. Den returnerar fält för specifika dokument (identifieras av det unika
metadata_storage_pathfältet)."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueKöra frågan. Du bör se tomma värden för
organizationsochlocations.Dessa fält bör ha fyllts i via kompetensuppsättningens entitetsigenkänningsfärdighet, som används för att identifiera organisationer och platser var som helst i blobens innehåll. I nästa övning felsöker du kompetensuppsättningen för att avgöra vad som gick fel.
Ett annat sätt att undersöka fel och varningar är via Azure-portalen.
Öppna fliken Indexerare och välj clinical-trials-idxr.
Observera att även om indexerarjobbet lyckades totalt sett fanns det varningar.
Välj Lyckades om du vill visa varningarna (om det främst fanns fel skulle informationslänken misslyckas). Du ser en lång lista över varje varning som genereras av indexeraren.

Starta felsökningssessionen
I det vänstra navigeringsfönstret för söktjänsten går du till Sökhantering och väljer Felsöka sessioner.
Välj + Lägg till felsökningssession.
Ge sessionen ett namn.
Ange indexerarens namn i Indexer-mallen. Indexeraren har referenser till datakällan, kompetensuppsättningen och indexet.
Välj lagringskontot.
Spara sessionen.
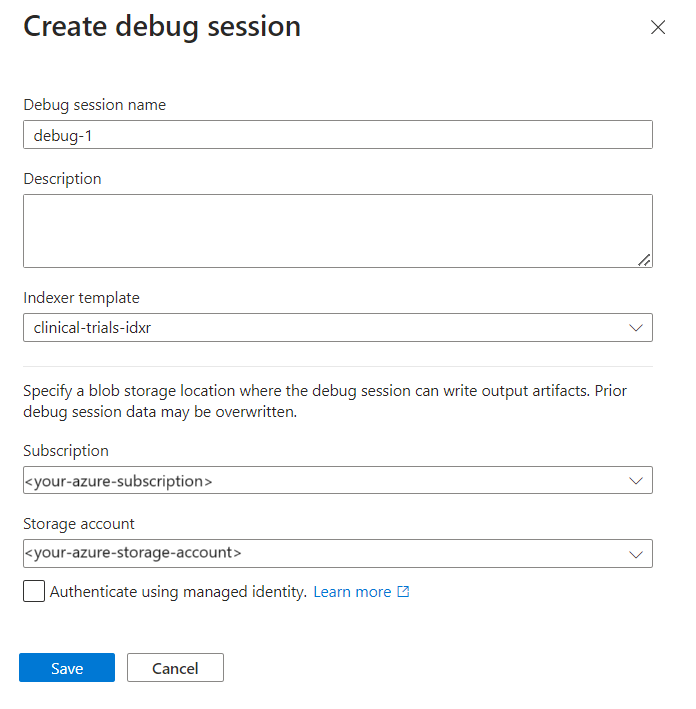
En felsökningssession öppnas på inställningssidan. Du kan göra ändringar i den inledande konfigurationen och åsidosätta alla standardvärden. En felsökningssession fungerar bara med ett enda dokument. Standardvärdet är att acceptera det första dokumentet i samlingen som grund för dina felsökningssessioner. Du kan välja ett specifikt dokument att felsöka genom att ange dess URI i Azure Storage.
När felsökningssessionen har initierats bör du se ett kompetensarbetsflöde med mappningar och ett sökindex. Den berikade dokumentdatastrukturen visas i ett informationsfönster på sidan. Vi exkluderade det från följande skärmbild så att du kunde se mer av arbetsflödet.
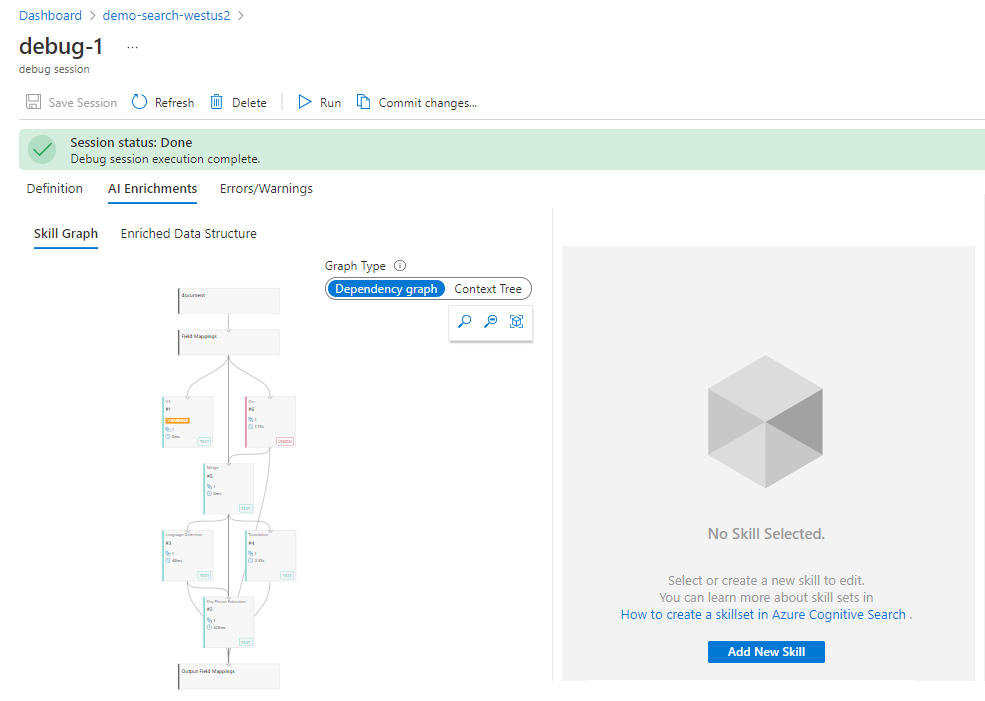


Hitta problem med kompetensuppsättningen
Eventuella problem som rapporteras av indexeraren anges som fel och varningar.
Observera att antalet fel och varningar är en mycket mindre lista än den som visades tidigare eftersom den här listan bara beskriver felen för ett enda dokument. Precis som listan som visas av indexeraren kan du välja ett varningsmeddelande och se information om den här varningen.
Välj Varningar för att granska meddelandena. Du bör se fyra:
"Det gick inte att köra färdigheten eftersom en eller flera kunskapsindata var ogiltiga. Nödvändiga kunskapsindata saknas. Namn: "text", Källa: '/dokument/innehåll'."
"Det gick inte att mappa utdatafältets platser för att söka i indexet. Kontrollera egenskapen outputFieldMappings för indexeraren. Värdet "/document/merged_content/locations" saknas."
"Det gick inte att mappa utdatafältets organisationer för att söka efter index. Kontrollera egenskapen outputFieldMappings för indexeraren. Värdet "/document/merged_content/organizations" saknas."
"Färdigheten utfördes men kan ha oväntade resultat eftersom en eller flera kunskapsindata var ogiltiga. Valfria kunskaper saknas. Namn: 'languageCode', Källa: '/document/languageCode'. Problem med parsning av uttrycksspråk: Värdet /document/languageCode saknas."
Många kunskaper har parametern "languageCode". Genom att granska åtgärden kan du se att den här språkkodinmatningen EntityRecognitionSkill.#1saknas i , vilket är samma entitetsigenkänningsfärdighet som har problem med utdata från "platser" och "organisationer".
Eftersom alla fyra meddelandena handlar om den här färdigheten är nästa steg att felsöka den här färdigheten. Börja om möjligt med att lösa indataproblem först innan du går vidare till utdataproblem.
Åtgärda saknade värden för kunskapsindata
På arbetsytan väljer du den färdighet som rapporterar varningarna. I den här självstudien är det entitetsigenkänningsfärdigheten.
Fönstret Kunskapsinformation öppnas till höger med avsnitt för iterationer och deras respektive indata och utdata, kunskapsinställningar för JSON-definitionen av färdigheten och meddelanden om eventuella fel och varningar som den här färdigheten genererar.

Hovra över varje indata (eller välj en indata) för att visa värdena i uttrycksutvärderingen. Observera att det visade resultatet för den här inmatningen inte ser ut som en textinmatning. Det ser ut som en serie nya radtecken
\n \n\n\n\ni stället för text. Bristen på text innebär att inga entiteter kan identifieras, så antingen misslyckas det här dokumentet med att uppfylla kraven för kunskapen, eller så finns det andra indata som ska användas i stället.
Växla tillbaka till Berikad datastruktur och granska berikningsnoderna för det här dokumentet. Observera att
\n \n\n\n\nför "innehåll" inte har någon ursprungskälla, men ett annat värde för "merged_content" har OCR-utdata. Även om det inte finns någon indikation verkar innehållet i den här PDF-filen vara en JPEG-fil, vilket framgår av den extraherade och bearbetade texten i "merged_content".
Växla tillbaka till färdigheten och välj Inställningar för kompetensuppsättning för att öppna JSON-definitionen.
Ändra uttrycket från
/document/contenttill och välj sedan Spara/document/merged_content. Observera att varningen inte längre visas.
Välj Kör i sessionens fönstermeny. Detta startar en annan körning av kompetensuppsättningen med hjälp av dokumentet.
När körningen av felsökningssessionen har slutförts ser du att antalet varningar har minskat med en. Varningar visar att felet för textinmatning är borta, men de andra varningarna kvarstår. Nästa steg är att åtgärda varningen om det saknade eller tomma värdet
/document/languageCode.
Välj färdigheten och hovra över
/document/languageCode. Värdet för den här indatan är null, vilket inte är en giltig indata.Precis som med det tidigare problemet börjar du med att granska strukturen Berikade data för att få bevis på dess noder. Observera att det inte finns någon "languageCode"-nod, men det finns en för "language". Det finns alltså ett skrivfel i kunskapsinställningarna.
Kopiera uttrycket
/document/language.I fönstret Kunskapsinformation väljer du Färdighetsinställningar för kunskapen #1 och klistrar in det nya värdet,
/document/language.Välj Spara.
Markera Kör.
När körningen av felsökningssessionen har slutförts kan du kontrollera resultatet i fönstret Kompetensinformation. När du hovra över
/document/languagebör du seensom värdet i uttrycksutvärderingen.
Observera att indatavarningarna är borta. Nu återstår bara de två varningarna om utdatafält för organisationer och platser.
Åtgärda saknade kunskapsutdatavärden
Meddelandena säger att kontrollera egenskapen "outputFieldMappings" för indexeraren, så låt oss börja där.
Välj Mappningar för utdatafält på arbetsytan. Observera att mappningarna för utdatafält saknas.

Som ett första steg bekräftar du att sökindexet har de förväntade fälten. I det här fallet har indexet fält för "platser" och "organisationer".
Om det inte finns några problem med indexet är nästa steg att kontrollera kunskapsutdata. Precis som tidigare väljer du strukturen Berikad data och rullar noderna för att hitta "platser" och "organisationer". Observera att det överordnade objektet är "innehåll" i stället för "merged_content". Kontexten är fel.
Växla tillbaka till informationsfönstret Kunskaper för entitetsigenkänningsfärdigheten.
I Kunskapsinställningar ändrar du
contexttilldocument/merged_content. Nu bör du ha tre ändringar av kunskapsdefinitionen helt och hållet.
Välj Spara.
Markera Kör.
Alla fel har lösts.
Checka in ändringar i kompetensuppsättningen
När felsökningssessionen initierades skapade söktjänsten en kopia av kompetensuppsättningen. Detta gjordes för att skydda den ursprungliga kompetensuppsättningen i söktjänsten. Nu när du har felsökt din kompetensuppsättning kan korrigeringarna utföras (skriva över den ursprungliga kompetensuppsättningen).
Om du inte är redo att genomföra ändringar kan du också spara felsökningssessionen och öppna den igen senare.
Välj Checka in ändringar i huvudmenyn för felsökningssessioner.
Välj OK för att bekräfta att du vill uppdatera din kompetensuppsättning.
Stäng Felsökningssessionen och öppna Indexerare i det vänstra navigeringsfönstret.
Välj "clinical-trials-idxr".
Välj Återställ.
Markera Kör.
Välj Uppdatera för att visa status för kommandona för återställning och körning.
När indexeraren har körts bör det finnas en grön bockmarkering och ordet Lyckades bredvid tidsstämpeln för den senaste körningen på fliken Körningshistorik . Så här ser du till att ändringarna har tillämpats:
Öppna Index i det vänstra navigeringsfönstret.
Välj index för kliniska prövningar och ange följande frågesträng på fliken Sökutforskaren:
$select=metadata_storage_path, organizations, locations&$count=trueför att returnera fält för specifika dokument (identifieras av det unikametadata_storage_pathfältet).Välj Sök.
Resultaten bör visa att organisationer och platser nu är ifyllda med de förväntade värdena.
Rensa resurser
När du arbetar i din egen prenumeration kan det dock vara klokt att i slutet av ett projekt kontrollera om du fortfarande behöver de resurser som du skapade. Resurser som fortsätter att köras kostar pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan hitta och hantera resurser i portalen med hjälp av länken Alla resurser eller Resursgrupper i det vänstra navigeringsfönstret.
Den kostnadsfria tjänsten är begränsad till tre index, indexerare och datakällor. Du kan ta bort enskilda objekt i portalen för att hålla dig under gränsen.
Nästa steg
Den här självstudien berörde olika aspekter av definition och bearbetning av kompetensuppsättningar. Mer information om begrepp och arbetsflöden finns i följande artiklar: