Lägga till bedömningsprofiler för att öka sökpoängen
Med bedömningsprofiler kan du öka rangordningen av matchande dokument baserat på kriterier. I den här artikeln får du lära dig hur du anger och tilldelar en bedömningsprofil som ökar en sökpoäng baserat på parametrar som du anger.
Du kan använda bedömningsprofiler för nyckelordssökning, vektorsökning och hybridsökning. Bedömningsprofiler gäller dock endast för icke-bevektorfält, så se till att indexet har text eller numeriska fält som kan användas i en bedömningsprofil. Stöd för bedömningsprofil för vektor- och hybridsökning är tillgängligt i 2024-05-01-preview och 2024-07-01 REST API:er och i Azure SDK-paket som riktar sig till dessa versioner.
Viktiga punkter om bedömningsprofiler
Bedömningsprofilparametrar är antingen:
Viktade fält, där en matchning hittas i ett specifikt strängfält. Du kanske till exempel vill att matchningar som finns i ett "sammanfattningsfält" ska vara mer relevanta än samma matchning som finns i ett "innehållsfält".
Funktioner för numeriska data, inklusive datum, intervall och geografiska koordinater. Det finns också en taggar-funktion som fungerar på ett fält som tillhandahåller en godtycklig samling strängar. Du kan välja den här metoden framför viktade fält om du vill öka en poäng baserat på om en matchning hittas i ett taggfält.
Du kan skapa flera profiler och sedan ändra frågelogik för att välja vilken som ska användas.
Du kan ha upp till 100 bedömningsprofiler i ett index (se tjänstbegränsningar), men du kan bara ange en profil i taget i en viss fråga.
Kommentar
Känner du inte till relevansbegrepp? Gå till Relevans och bedömning i Azure AI Search för bakgrund. Du kan också titta på det här videosegmentet på YouTube för att bedöma profiler över BM25-rankade resultat.
Bedömningsprofildefinition
En bedömningsprofil heter objekt som definierats i ett indexschema. En bedömningsprofil består av viktade fält, funktioner och parametrar.
Följande definition visar en enkel profil med namnet "geo". Det här exemplet ökar resultaten som har söktermen i fältet hotelName. Den använder distance också funktionen för att gynna resultat som ligger inom 10 kilometer från den aktuella platsen. Om någon söker på termen "inn" och "inn" råkar vara en del av hotellnamnet visas dokument som innehåller hotell med "inn" inom en radie på 10 KM från den aktuella platsen högre i sökresultaten.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Om du vill använda den här bedömningsprofilen formuleras frågan för att ange parametern scoringProfile i begäran. Om du använder REST API anges frågor via GET- och POST-begäranden. I följande exempel har "currentLocation" en avgränsare av ett enda streck (-). Det följs av longitud- och latitudkoordinater, där longitud är ett negativt värde.
GET /indexes/hotels/docs?search+inn&scoringProfile=geo&scoringParameter=currentLocation--122.123,44.77233&api-version=2024-07-01
Observera syntaxskillnaderna när du använder POST. I POST är "scoringParameters" plural och det är en matris.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
Den här frågan söker efter termen "inn" och skickar den aktuella platsen. Observera att den här frågan innehåller andra parametrar, till exempel scoringParameter. Frågeparametrar, inklusive "scoringParameter", beskrivs i Sökdokument (REST API).
Se utökat exempel för vektor- och hybridsökning och Utökat exempel för nyckelordssökning för fler scenarier.
Så här fungerar sökpoäng i Azure AI Search
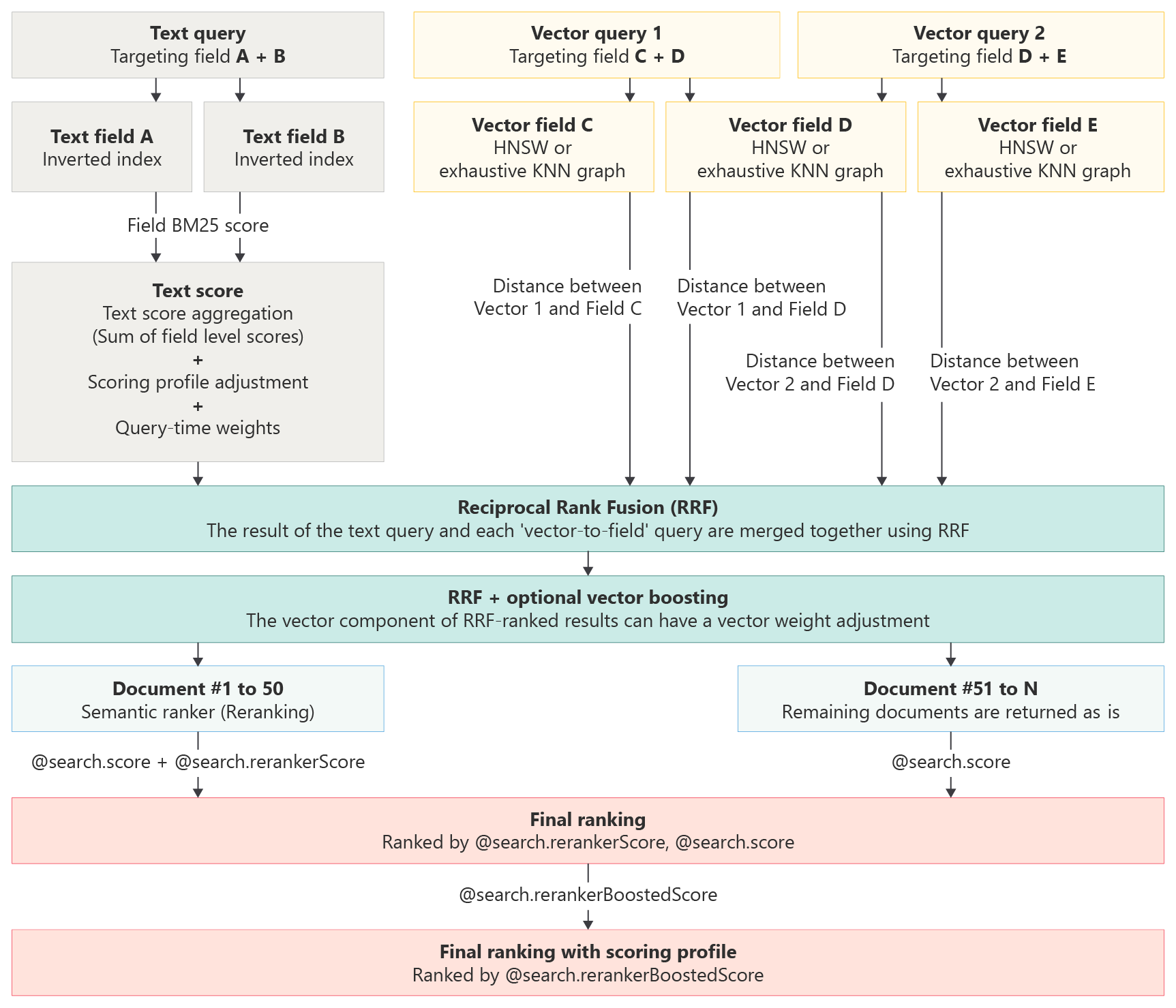
Bedömningsprofiler kompletterar standardbedömningsalgoritmen genom att öka poängen för matchningar som uppfyller profilens kriterier. Bedömningsfunktioner gäller för nyckelordssökning, rena vektorfrågor och hybridfrågor.
När du använder bedömningsprofiler eller andra funktioner för att öka i Azure AI Search tilldelar RRF-algoritmen (Reciprocal Ranking Function) poängen, inklusive för fristående text- och vektorfrågor. Efter RRF sker alla justeringar för bedömning/ökning, semantisk rangordning och vektorviktning .
Dricks
Du kan använda parametern featuresMode (förhandsversion) för att begära extra bedömningsinformation med sökresultaten (inklusive poäng på fältnivå).
Lägga till en bedömningsprofil i ett sökindex
Börja med en indexdefinition. Du kan lägga till och uppdatera bedömningsprofiler i ett befintligt index utan att behöva återskapa det. Använd en begäran om att skapa eller uppdatera index för att publicera en revision.
Klistra in mallen i den här artikeln.
Ange ett namn som följer namngivningskonventionerna.
Ange villkor för att öka. En enskild profil kan innehålla textviktade fält, funktioner eller båda.
Du bör arbeta iterativt med hjälp av en datauppsättning som hjälper dig att bevisa eller motbevisa effekten av en viss profil.
Bedömningsprofiler kan definieras i Azure Portal enligt följande skärmbild eller programmatiskt via REST-API:er eller i Azure SDK:er, till exempel klassen ScoringProfile i Azure SDK för .NET.

Använda textvägda fält
Använd textvägda fält när fältkontexten är viktig och frågor inkluderar searchable strängfält. Om en fråga till exempel innehåller termen "flygplats" kanske du vill att "flygplats" i fältet Beskrivning ska ha större vikt än i HotelName.
Viktade fält är namn/värde-par som består av ett searchable fält och ett positivt tal som används som multiplikator. Om den ursprungliga fältpoängen för HotelName är 3 blir den ökade poängen för fältet 6, vilket bidrar till en högre totalpoäng för själva det överordnade dokumentet.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Använda funktioner
Använd funktioner när enkla relativa vikter är otillräckliga eller inte gäller, vilket är fallet med avstånd och färskhet, som är beräkningar över numeriska data. Du kan ange flera funktioner per bedömningsprofil. Mer information om de EDM-datatyper som används i Azure AI Search finns i Datatyper som stöds.
| Function | beskrivning | Användningsfall |
|---|---|---|
| avstånd | Öka med närhet eller geografisk plats. Den här funktionen kan bara användas med Edm.GeographyPoint fält. |
Använd för scenarier med "hitta nära mig". |
| Friskhet | Öka med värden i ett datetime-fält (Edm.DateTimeOffset). Ange boostDuration för att ange ett värde som representerar ett tidsintervall över vilket ökning sker. |
Använd när du vill öka med nyare eller äldre datum. Rangordna objekt som kalenderhändelser med framtida datum så att objekt närmare nutiden kan rangordnas högre än objekt längre fram i framtiden. Ena änden av intervallet är fast i den aktuella tiden. För att öka ett antal gånger tidigare använder du en positiv boostDuration. För att öka ett antal gånger i framtiden använder du en negativ boostDuration. |
| magnitud | Ändra rangordning baserat på värdeintervallet för ett numeriskt fält. Värdet måste vara ett heltal eller flyttalsnummer. För stjärnbetyg på 1 till 4 skulle detta vara 1. För marginaler över 50 % skulle detta vara 50. Den här funktionen kan bara användas med Edm.Double och Edm.Int fält. För funktionen magnitude kan du vända intervallet, högt till lågt, om du vill ha inverteringsmönstret (till exempel för att öka billigare objekt mer än dyrare objekt). Med tanke på ett prisintervall från $ 100 till $ 1, skulle du sätta boostingRangeStart till 100 och boostingRangeEnd vid 1 för att öka de billigare objekten. |
Använd när du vill öka med vinstmarginal, omdömen, antal klickningar, antal nedladdningar, högsta pris, lägsta pris eller antal nedladdningar. När två objekt är relevanta visas objektet med högre klassificering först. |
| tagg | Öka med taggar som är gemensamma för både sökdokument och frågesträngar. Taggar tillhandahålls i en tagsParameter. Den här funktionen kan endast användas med sökfält av typen Edm.String och Collection(Edm.String). |
Använd när du har taggfält. Om en viss tagg i listan i sig är en kommaavgränsad lista kan du använda en textnormaliserare på fältet för att ta bort kommatecken vid frågetid (mappa kommatecknet till ett blanksteg). Den här metoden "platta ut" listan så att alla termer är en enda, lång sträng med kommaavgränsade termer. |
Regler för att använda funktioner
- Funktioner kan endast tillämpas på fält som tilldelas som
filterable. - Funktionstypen ("freshness", "magnitude", "distance", "tag") måste vara gemen.
- Funktioner kan inte innehålla null- eller tomma värden.
- Funktioner kan bara ha ett enda fält per funktionsdefinition. Om du vill använda magnituden två gånger i samma profil anger du två definitionsstorlekar, en för varje fält.
Template
Det här avsnittet visar syntaxen och mallen för bedömningsprofiler. En beskrivning av egenskaper finns i REST API-referensen.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Ange interpoleringar
Interpolationer anger formen på lutningen som används för bedömning. Eftersom poängsättningen är hög till låg minskar lutningen alltid, men interpolationen avgör kurvan för den nedåtgående lutningen. Följande interpoleringar kan användas:
| Interpolation | beskrivning |
|---|---|
linear |
För objekt som ligger inom max- och minintervallet tillämpas ökning i en ständigt minskande mängd. Linjär är standardinterpolationen för en bedömningsprofil. |
constant |
För objekt som ligger inom start- och slutintervallet tillämpas en konstant ökning på rankningsresultatet. |
quadratic |
I jämförelse med en linjär interpolation som har en ständigt minskande ökning minskar quadratic initialt i mindre takt och sedan när den närmar sig slutintervallet minskar den med ett mycket högre intervall. Det här interpoleringsalternativet tillåts inte i taggbedömningsfunktioner. |
logarithmic |
I jämförelse med en linjär interpolation som har en ständigt minskande ökning minskar logaritmiska initialt i högre takt och sedan när den närmar sig slutintervallet minskar den med ett mycket mindre intervall. Det här interpoleringsalternativet tillåts inte i taggbedömningsfunktioner. |

Ange boostDuration för färskhetsfunktionen
boostingDuration är ett attribut för freshness funktionen. Du använder den för att ange en förfalloperiod varefter en ökning stoppas för ett visst dokument. Om du till exempel vill öka en produktlinje eller ett varumärke för en 10-dagars kampanjperiod anger du 10-dagarsperioden som "P10D" för dessa dokument.
boostingDuration måste formateras som ett XSD-värde för "dayTimeDuration" (en begränsad delmängd av ett ISO 8601-varaktighetsvärde). Mönstret för detta är: "P[nD][T[nH][nM][nS]]".
Följande tabell innehåller flera exempel.
| Varaktighet | boostDuration |
|---|---|
| 1 dag | "P1D" |
| 2 dagar och 12 timmar | "P2DT12H" |
| 15 minuter | "PT15M" |
| 30 dagar, 5 timmar, 10 minuter och 6,334 sekunder | "P30DT5H10M6.334S" |
Fler exempel finns i XML-schema: Datatyper (W3.org webbplats).
Utökat exempel för vektor- och hybridsökning
Se det här blogginlägget och notebook-filen för en demonstration av hur du använder bedömningsprofiler och dokumentförstärkning i vektor- och generativa AI-scenarier.
Utökat exempel för nyckelordssökning
I följande exempel visas schemat för ett index med två bedömningsprofiler (boostGenre, newAndHighlyRated). Alla frågor mot det här indexet som innehåller någon av profilerna som en frågeparameter använder profilen för att poängsätta resultatuppsättningen.
Profilen boostGenre använder viktade textfält, vilket ökar matchningarna som finns i fälten albumTitle, genre och artistName. Fälten ökas 1,5, 5 respektive 2. Varför ökar genren så mycket högre än de andra? Om sökning utförs över data som är något homogena (vilket är fallet med "genre" i musikarkivindexet), kan du behöva en större varians i de relativa vikterna. I musicstoreindex visas till exempel "rock" som både en genre och i identiskt formulerade genrebeskrivningar. Om du vill att genren ska väga tyngre än genrebeskrivningen behöver genrefältet en mycket högre relativ vikt.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}