Skapa en vektorfråga i Azure AI Search
Om du har ett vektorindex i Azure AI Search förklarar den här artikeln hur du:
Den här artikeln använder REST som illustration. Kodexempel på andra språk finns i GitHub-lagringsplatsen azure-search-vector-samples för lösningar från slutpunkt till slutpunkt som innehåller vektorfrågor.
Du kan också använda Sökutforskaren i Azure Portal.
Azure AI Search, i valfri region och på valfri nivå.
Ett vektorindex för Azure AI Search. Kontrollera ett
vectorSearchavsnitt i indexet för att bekräfta ett vektorindex.Du kan också lägga till en vektoriserare i indexet för inbyggd text-till-vektor- eller bild-till-vektorkonvertering under frågor.
Visual Studio Code med en REST-klient och exempeldata om du vill köra dessa exempel på egen hand. Information om hur du kommer igång med REST-klienten finns i Snabbstart: Azure AI Search med HJÄLP av REST.
Om du vill köra frågor mot ett vektorfält måste själva frågan vara en vektor.
En metod för att konvertera en användares textfrågesträng till dess vektorrepresentation är att anropa ett inbäddningsbibliotek eller API i programkoden. Vi rekommenderar att du alltid använder samma inbäddningsmodeller som används för att generera inbäddningar i källdokumenten. Du hittar kodexempel som visar hur du genererar inbäddningar i lagringsplatsen azure-search-vector-samples .
En andra metod är att använda integrerad vektorisering, som nu är allmänt tillgänglig, för att låta Azure AI Search hantera dina indata och utdata för frågevektorisering.
Här är ett REST API-exempel på en frågesträng som skickats till en distribution av en Azure OpenAI-inbäddningsmodell:
POST https://{{openai-service-name}}.openai.azure.com/openai/deployments/{{openai-deployment-name}}/embeddings?api-version={{openai-api-version}}
Content-Type: application/json
api-key: {{admin-api-key}}
{
"input": "what azure services support generative AI'"
}
Det förväntade svaret är 202 för ett lyckat anrop till den distribuerade modellen.
Fältet "inbäddning" i svarets brödtext är vektorrepresentationen av frågesträngen "input". I testsyfte kopierar du värdet för matrisen "inbäddning" till "vectorQueries.vector" i en frågebegäran med hjälp av syntaxen som visas i de kommande avsnitten.
Det faktiska svaret för det här POST-anropet till den distribuerade modellen innehåller 1536 inbäddningar, trimmade här till bara de första vektorerna för läsbarhet.
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.009171937,
0.018715322,
...
-0.0016804502
]
}
],
"model": "ada",
"usage": {
"prompt_tokens": 7,
"total_tokens": 7
}
}
I den här metoden ansvarar programkoden för att ansluta till en modell, generera inbäddningar och hantera svaret.
Det här avsnittet visar den grundläggande strukturen för en vektorfråga. Du kan använda Azure Portal, REST API:er eller Azure SDK:er för att formulera en vektorfråga. Om du migrerar från 2023-07-01-Preview finns det icke-bakåtkompatibla ändringar. Mer information finns i Uppgradera till det senaste REST-API:et .
2024-07-01 är den stabila REST API-versionen för Search POST. Den här versionen stöder:
vectorQueriesär konstruktionen för vektorsökning.vectorQueries.kindinställd påvectorför en vektormatris, eller inställd påtextom indata är en sträng och du har en vektoriserare.vectorQueries.vectorär fråga (en vektorrepresentation av text eller en bild).vectorQueries.weight(valfritt) anger den relativa vikten för varje vektorfråga som ingår i sökåtgärder (se Vektorviktning).exhaustive(valfritt) anropar fullständigt KNN vid frågetillfället, även om fältet indexeras för HNSW.
I följande exempel är vektorn en representation av den här strängen: "vilka Azure-tjänster stöder fulltextsökning". Frågan riktar sig mot fältet contentVector . Frågan returnerar k resultat. Den faktiska vektorn har 1536 inbäddningar, så den trimmas i det här exemplet för läsbarhet.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector",
"weight": 0.5,
"k": 5
}
]
}
I Azure AI Search består frågesvar av alla retrievable fält som standard. Det är dock vanligt att begränsa sökresultaten till en delmängd av retrievable fälten genom att visa dem i en select -instruktion.
I en vektorfråga bör du noga överväga om du behöver vektorfält i ett svar. Vektorfält är inte läsbara för människor, så om du skickar ett svar till en webbsida bör du välja icke-bevektorfält som är representativa för resultatet. Om frågan till exempel körs mot contentVectorkan du returnera content i stället.
Om du vill ha vektorfält i resultatet, här är ett exempel på svarsstrukturen. contentVector är en strängmatris med inbäddningar, trimmad här för korthet. Sökpoängen anger relevans. Andra icke-bevektorfält ingår i kontexten.
{
"@odata.count": 3,
"value": [
{
"@search.score": 0.80025613,
"title": "Azure Search",
"category": "AI + Machine Learning",
"contentVector": [
-0.0018343845,
0.017952163,
0.0025753193,
...
]
},
{
"@search.score": 0.78856903,
"title": "Azure Application Insights",
"category": "Management + Governance",
"contentVector": [
-0.016821077,
0.0037742127,
0.016136652,
...
]
},
{
"@search.score": 0.78650564,
"title": "Azure Media Services",
"category": "Media",
"contentVector": [
-0.025449317,
0.0038463024,
-0.02488436,
...
]
}
]
}
Viktiga punkter:
kavgör hur många närmaste grannresultat som returneras, i det här fallet tre. Vektorfrågor returnerarkalltid resultat, förutsatt att det finns minstkdokument, även om det finns dokument med dålig likhet, eftersom algoritmen hittar närmastekgrannar till frågevektorn.Fält i sökresultat är antingen alla
retrievablefält eller fält i enselectsats. Under körning av vektorfrågor görs matchningen enbart på vektordata. Ett svar kan dock innehålla valfrittretrievablefält i ett index. Eftersom det inte finns någon möjlighet att avkoda ett vektorfältresultat är inkluderingen av icke-inledande textfält användbar för deras mänskliga läsbara värden.
Du kan ange egenskapen "vectorQueries.fields" till flera vektorfält. Vektorfrågan körs mot varje vektorfält som du anger i fields listan. När du kör frågor mot flera vektorfält kontrollerar du att var och en innehåller inbäddningar från samma inbäddningsmodell och att frågan också genereras från samma inbäddningsmodell.
POST https://{{search-service-name}}.search.windows.net/indexes/{{index-name}}/docs/search?api-version=2024-07-01
Content-Type: application/json
api-key: {{admin-api-key}}
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"exhaustive": true,
"fields": "contentVector, titleVector",
"k": 5
}
]
}
Vektorsökning med flera frågor skickar flera frågor över flera vektorfält i ditt sökindex. Ett vanligt exempel på den här frågebegäran är när du använder modeller som CLIP för en multimodal vektorsökning där samma modell kan vektorisera bild- och textinnehåll.
Följande frågeexempel söker efter likhet i både myImageVector och myTextVector, men skickar i två olika frågebäddningar, som var och en körs parallellt. Den här frågan ger ett resultat som poängsätts med hjälp av Reciprocal Rank Fusion (RRF).
vectorQueriesinnehåller en matris med vektorfrågor.vectorinnehåller bildvektorer och textvektorer i sökindexet. Varje instans är en separat fråga.fieldsanger vilket vektorfält som ska riktas.kär antalet närmaste grannmatchningar som ska inkluderas i resultaten.
{
"count": true,
"select": "title, content, category",
"vectorQueries": [
{
"kind": "vector",
"vector": [
-0.009154141,
0.018708462,
. . .
-0.02178128,
-0.00086512347
],
"fields": "myimagevector",
"k": 5
},
{
"kind": "vector"
"vector": [
-0.002222222,
0.018708462,
-0.013770515,
. . .
],
"fields": "mytextvector",
"k": 5
}
]
}
Sökresultaten skulle innehålla en kombination av text och bilder, förutsatt att ditt sökindex innehåller ett fält för bildfilen (ett sökindex lagrar inte bilder).
Det här avsnittet visar en vektorfråga som anropar den integrerade vektoriseringen som konverterar en text- eller bildfråga till en vektor. Vi rekommenderar stabila 2024-07-01 REST API, Search Explorer eller nyare Azure SDK-paket för den här funktionen.
En förutsättning är ett sökindex med en vektoriserare konfigurerad och tilldelad till ett vektorfält. Vektoriseraren tillhandahåller anslutningsinformation till en inbäddningsmodell som används vid frågetillfället.
Search Explorer stöder integrerad vektorisering vid frågetillfället. Om ditt index innehåller vektorfält och har en vektoriserare kan du använda den inbyggda text-till-vektorkonverteringen.
Logga in på Azure Portal med ditt Azure-konto och gå till azure AI-tjänsten Search.
På den vänstra menyn expanderar du Sökhanteringsindex> och väljer ditt index. Sökutforskaren är den första fliken på indexsidan.
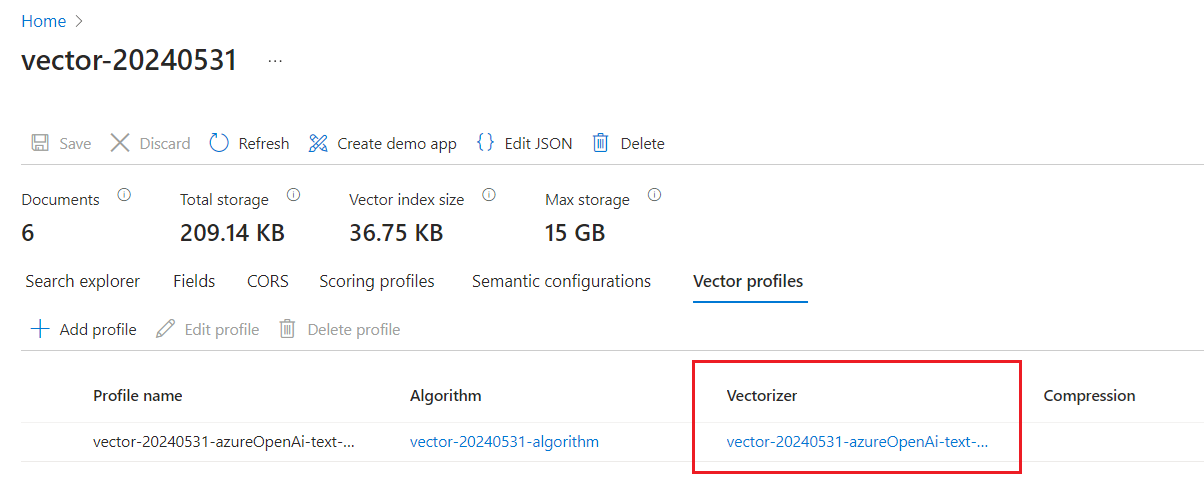
Kontrollera Vektorprofiler för att bekräfta att du har en vektoriserare.
I Sökutforskaren kan du ange en textsträng i standardsökfältet i frågevyn. Den inbyggda vektoriseraren konverterar strängen till en vektor, utför sökningen och returnerar resultat.
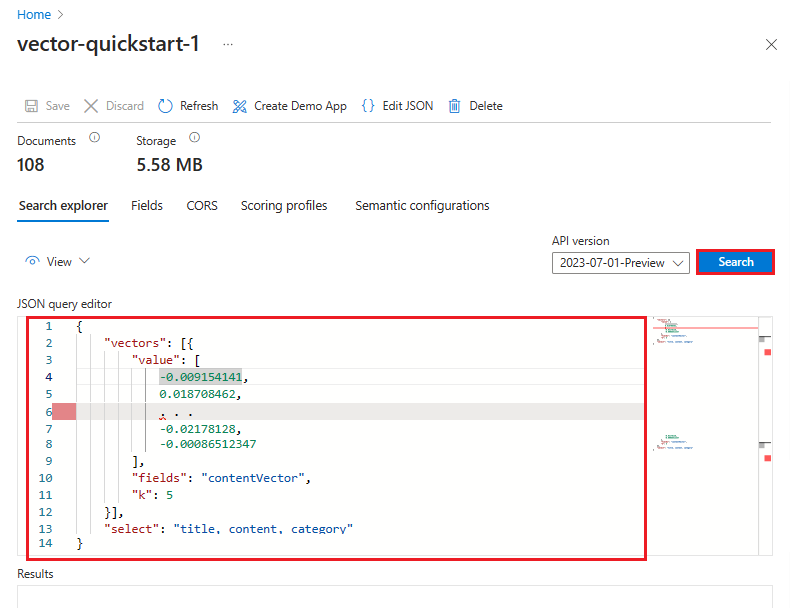
Du kan också välja Visa JSON-vy> för att visa eller ändra frågan. Om det finns vektorer konfigurerar Search Explorer automatiskt en vektorfråga. Du kan använda JSON-vyn för att välja fält som används i sökningen och i svaret lägger du till filter eller skapar mer avancerade frågor som hybrid. Ett JSON-exempel finns på fliken REST API i det här avsnittet.
En vektorfråga anger parametern k som avgör hur många matchningar som returneras i resultatet. Sökmotorn returnerar k alltid antalet matchningar. Om k är större än antalet dokument i indexet avgör antalet dokument den övre gränsen för vad som kan returneras.
Om du är bekant med fulltextsökning vet du att du förväntar dig noll resultat om indexet inte innehåller någon term eller fras. I vektorsökning identifierar sökåtgärden dock närmaste grannar och returnerar k alltid resultat även om närmaste grannar inte är så lika. Därför är det möjligt att få resultat för meningslösa frågor eller frågor utanför ämnet, särskilt om du inte använder uppmaningar för att ange gränser. Mindre relevanta resultat har sämre likhetspoäng, men de är fortfarande de "närmaste" vektorerna om det inte finns något närmare. Därför kan ett svar utan meningsfulla resultat fortfarande returnera k resultat, men varje resultats likhetspoäng skulle vara låg.
En hybridmetod som innehåller fulltextsökning kan åtgärda det här problemet. En annan åtgärd är att ange ett minimitröskelvärde för sökpoängen, men bara om frågan är en ren enskild vektorfråga. Hybridfrågor bidrar inte till minsta tröskelvärden eftersom RRF-intervallen är så mycket mindre och flyktiga.
Frågeparametrar som påverkar resultatantalet är:
"k": nresultat för endast vektorfrågor"top": nresultat för hybridfrågor som innehåller en sökparameter
Både "k" och "top" är valfria. Ospecificerat är standardantalet resultat i ett svar 50. Du kan ange "top" och "skip" för att gå igenom fler resultat eller ändra standardvärdet.
Rangordningen av resultaten beräknas av antingen:
- Likhetsmått
- Reciprocal Rank Fusion (RRF) om det finns flera uppsättningar sökresultat.
Likhetsmåttet som anges i indexavsnittet vectorSearch för en fråga med endast vektorer. Giltiga värden är cosine, euclidean och dotProduct.
Azure OpenAI-inbäddningsmodeller använder cosinélikhet, så om du använder Inbäddningsmodeller cosine för Azure OpenAI är det rekommenderade måttet. Andra rangordningsmått som stöds är euclidean och dotProduct.
Flera uppsättningar skapas om frågan riktar sig mot flera vektorfält, kör flera vektorfrågor parallellt eller om frågan är en hybrid av vektor- och fulltextsökning, med eller utan semantisk rangordning.
Under frågekörningen kan en vektorfråga endast rikta in sig på ett internt vektorindex. För flera vektorfält och flera vektorfrågor genererar sökmotorn därför flera frågor som riktar sig mot respektive vektorindex för varje fält. Utdata är en uppsättning rankade resultat för varje fråga, som sammansvetsas med RRF. Mer information finns i Relevansbedömning med Reciprocal Rank Fusion (RRF).
Lägg till en weight frågeparameter för att ange den relativa vikten för varje vektorfråga som ingår i sökåtgärder. Det här värdet används när du kombinerar resultatet av flera rangordningslistor som skapats av två eller flera vektorfrågor i samma begäran eller från vektordelen av en hybridfråga.
Standardvärdet är 1,0 och värdet måste vara ett positivt tal som är större än noll.
Vikter används vid beräkning av de ömsesidiga fusionspoängen för varje dokument. Beräkningen är multiplikator av weight värdet mot rankningspoängen för dokumentet inom respektive resultatuppsättning.
Följande exempel är en hybridfråga med två vektorfrågesträngar och en textsträng. Vikter tilldelas till vektorfrågorna. Den första frågan är 0,5 eller halva vikten, vilket minskar dess betydelse i begäran. Den andra vektorfrågan är dubbelt så viktig.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-07-01
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my_first_vector_field",
"k": 10,
"weight": 0.5
},
{
"kind": "vector",
"vector": [4.0, 5.0, 6.0],
"fields": "my_second_vector_field",
"k": 10,
"weight": 2.0
}
],
"search": "hello world"
}
Vektorviktning gäller endast för vektorer. Textfrågan i det här exemplet ("hello world") har en implicit vikt på 1,0 eller neutral vikt. I en hybridfråga kan du dock öka eller minska vikten av textfält genom att ange maxTextRecallSize.
Eftersom närmsta grannsökning alltid returnerar de begärda k grannarna är det möjligt att få flera matchningar med låg poäng som en del av att uppfylla nummerkravet i sökresultaten k . Om du vill exkludera sökresultat med låg poäng kan du lägga till en threshold frågeparameter som filtrerar ut resultat baserat på en minimipoäng. Filtrering sker innan resultat från olika återställningsuppsättningar används.
Den här parametern är fortfarande i förhandsversion. Vi rekommenderar förhandsversion av REST API version 2024-05-01-preview.
I det här exemplet undantas alla matchningar som poäng under 0,8 från vektorsökningsresultat, även om antalet resultat hamnar under k.
POST https://[service-name].search.windows.net/indexes/[index-name]/docs/search?api-version=2024-05-01-preview
Content-Type: application/json
api-key: [admin key]
{
"vectorQueries": [
{
"kind": "vector",
"vector": [1.0, 2.0, 3.0],
"fields": "my-cosine-field",
"threshold": {
"kind": "vectorSimilarity",
"value": 0.8
}
}
]
}
Vektorfrågor används ofta i hybridkonstruktioner som innehåller icke-bevektorfält. Om du upptäcker att BM25-rankade resultat är över eller under representerade i ett hybridfrågeresultat kan du ange maxTextRecallSize att öka eller minska BM25-rankade resultat som tillhandahålls för hybridrankning.
Du kan bara ange den här egenskapen i hybridbegäranden som innehåller komponenterna "search" och "vectorQueries".
Den här parametern är fortfarande i förhandsversion. Vi rekommenderar förhandsversion av REST API version 2024-05-01-preview.
Mer information finns i Ange maxTextRecallSize – Skapa en hybridfråga.
Som ett nästa steg granskar du exempel på vektorfrågekod i Python, C# eller JavaScript.