Köra eller återställa indexerare, färdigheter eller dokument
I Azure AI Search finns det flera sätt att köra en indexerare:
- Kör omedelbart när indexeraren skapas, förutsatt att den inte har skapats i läget "inaktiverad".
- Kör enligt ett schema för att anropa körning med jämna mellanrum.
- Kör på begäran, med eller utan en "återställning".
Den här artikeln beskriver hur du kör indexerare på begäran, med och utan återställning. Den beskriver även indexerarens körning, varaktighet och samtidighet.
Så här ansluter indexerare till Azure-resurser
Indexerare är ett av de få undersystem som gör överutgående anrop till andra Azure-resurser. När det gäller Azure-roller har indexerare inte separata identiteter: en anslutning från sökmotorn till en annan Azure-resurs görs med hjälp av en söktjänsts system- eller användartilldelade hanterade identitet . Om indexeraren ansluter till en Azure-resurs i ett virtuellt nätverk bör du skapa en delad privat länk för den anslutningen. Mer information om säkra anslutningar finns i Säkerhet i Azure AI Search.
Indexerarekörning
En söktjänst kör ett indexerarjobb per sökenhet. Varje söktjänst börjar med en sökenhet, men varje ny partition eller replik ökar sökenheterna för din tjänst. Du kan kontrollera antalet sökenheter i portalens essential-avsnitt på översiktssidan. Om du behöver samtidig bearbetning kontrollerar du att du har tillräckligt med repliker. Indexerare körs inte i bakgrunden, så du kan identifiera fler frågebegränsningar än vanligt om tjänsten är under press.
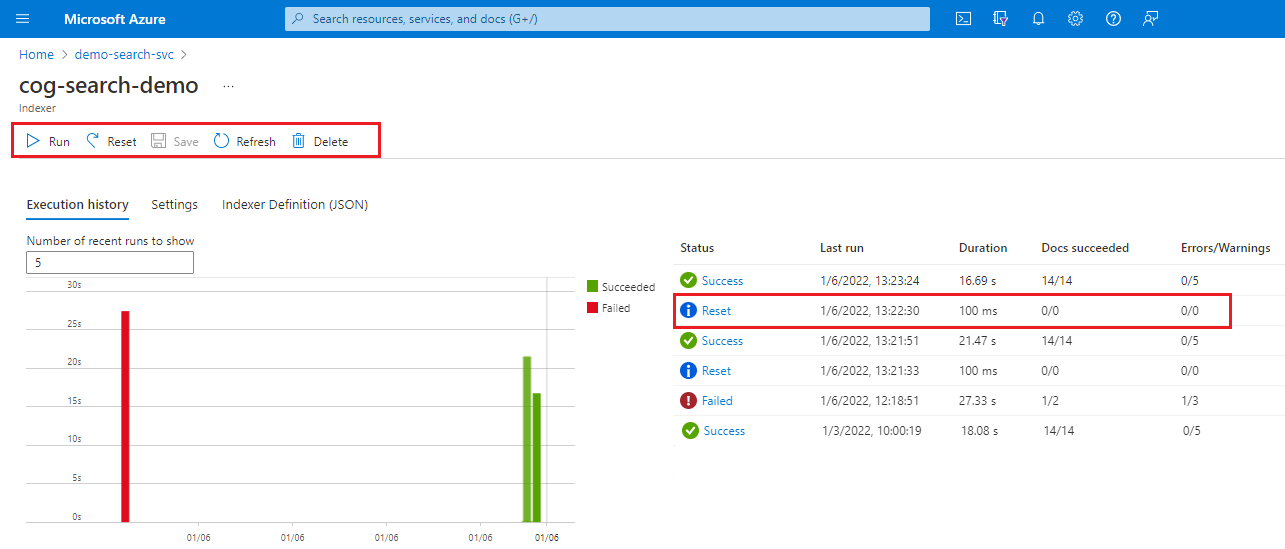
Följande skärmbild visar antalet sökenheter som avgör hur många indexerare som kan köras samtidigt.

När indexerarens körning startar kan du inte pausa eller stoppa den. Indexerarens körning stoppas när det inte finns fler dokument att läsa in eller uppdatera, eller när den maximala tidsgränsen för körning har uppnåtts.
Du kan köra flera indexerare samtidigt med tillräcklig kapacitet, men varje indexerare är en enda instans. Om du startar en ny instans medan indexeraren redan körs uppstår följande fel: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
Ett indexerarjobb körs i en hanterad körningsmiljö. För närvarande finns det två miljöer. Du kan inte styra eller konfigurera vilken miljö som används. Azure AI Search avgör miljön baserat på jobbsammansättning och tjänstens möjlighet att flytta ett indexerarjobb till en innehållsprocessor (vissa säkerhetsfunktioner blockerar miljön för flera klientorganisationer).
I indexerarens körningsmiljöer ingår:
En privat körningsmiljö som körs på söknoder, som är specifik för din söktjänst.
En miljö med flera klientorganisationer med innehållsprocessorer som hanteras och skyddas av Microsoft utan extra kostnad. Den här miljön används för att avlasta beräkningsintensiv bearbetning och lämna tjänstspecifika resurser tillgängliga för rutinåtgärder. När det är möjligt körs de flesta indexerarjobb i miljön för flera klientorganisationer.
Indexerarens gränser varierar för varje miljö:
| Arbetsbelastning | Maximal varaktighet | Maximalt antal jobb | Körningsmiljö |
|---|---|---|---|
| Privat körning | 24 timmar | Ett indexerarjobb per sökenhet 1. | Indexering körs inte i bakgrunden. I stället balanserar söktjänsten alla indexeringsjobb mot pågående frågor och objekthanteringsåtgärder (till exempel att skapa eller uppdatera index). När du kör indexerare bör du förvänta dig att se viss frågesvarstid om indexeringsvolymerna är stora. |
| Flera klientorganisationer | 2 timmar 2 | Obestämd 3 | Eftersom innehållsbearbetningsklustret är multitenant läggs noder till för att möta efterfrågan. Om du får en fördröjning vid körning på begäran eller schemalagd körning beror det förmodligen på att systemet antingen lägger till noder eller väntar på att en ska bli tillgänglig. |
1 Sökenheter kan vara flexibla kombinationer av partitioner och repliker, men indexeringsjobb är inte knutna till det ena eller det andra. Om du har 12 enheter kan du med andra ord ha 12 indexerarjobb som körs samtidigt i privat körning, oavsett hur sökenheterna distribueras.
2 Om du behöver mer än två timmar för att bearbeta alla data aktiverar du ändringsidentifiering och schemalägger indexeraren så att den körs med två timmars intervall. Se Indexera en stor datauppsättning för fler strategier.
3 "Obestämd" innebär att gränsen inte kvantifieras av antalet jobb. Vissa arbetsbelastningar, till exempel bearbetning av kompetensuppsättningar, kan köras parallellt, vilket kan resultera i många jobb även om endast en indexerare är inblandad. Även om miljön inte har några begränsningar gäller indexeringsgränser för söktjänsten fortfarande.
Kör utan återställning
En Run Indexer-åtgärd identifierar och bearbetar endast vad som krävs för att synkronisera sökindexet med ändringar i den underliggande datakällan. Inkrementell indexering börjar med att hitta ett internt högvattenmärke för att hitta det senast uppdaterade sökdokumentet, som blir startpunkten för indexerarens körning över nya och uppdaterade dokument i datakällan.
Ändringsidentifiering är viktigt för att avgöra vad som är nytt eller uppdaterat i datakällan. Indexerare använder funktionerna för ändringsidentifiering i den underliggande datakällan för att avgöra vad som är nytt eller uppdaterat i datakällan.
Azure Storage har inbyggd ändringsidentifiering via egenskapen LastModified.
Andra datakällor, till exempel Azure SQL eller Azure Cosmos DB, måste konfigureras för ändringsidentifiering innan indexeraren kan läsa nya och uppdaterade rader.
Om det underliggande innehållet är oförändrat har en körningsåtgärd ingen effekt. I det här fallet anger 0\0 indexerarens körningshistorik dokument som bearbetas.
Du måste återställa indexeraren, som beskrivs i nästa avsnitt, för att bearbetas i sin helhet.
Återställa indexerare
Efter den första körningen håller en indexerare reda på vilka sökdokument som har indexerats via ett internt högvattenmärke. Markören exponeras aldrig, men internt vet indexeraren var den senast stoppades.
Om du behöver återskapa hela eller delar av ett index kan du rensa indexerarens högvattenmärke genom en återställning. Återställnings-API:er är tillgängliga på fallande nivåer i objekthierarkin:
- Återställ indexerare rensar vattenmärket och utför en fullständig omindexering av alla dokument
- Återställ dokument (förhandsversion) indexerar om ett visst dokument eller en lista med dokument
- Återställ kunskaper (förhandsversion) anropar färdighetsbearbetning för en viss färdighet
Efter återställningen följer du med kommandot Kör för att bearbeta nya och befintliga dokument igen. Överblivna sökdokument som inte har någon motsvarighet i datakällan kan inte tas bort via återställning/körning. Om du behöver ta bort dokument kan du läsa Dokument – Index i stället.
Så här återställer och kör du indexerare
Återställning rensar vattenmärket. Alla dokument i sökindexet flaggas för fullständig överskrivning, utan infogade uppdateringar eller sammanslagning till befintligt innehåll. För indexerare med cachelagring av kunskaper och berikning återställs även implicit kompetensuppsättningen om du återställer indexet.
Det faktiska arbetet inträffar när du följer en återställning med ett Kör-kommando:
- Alla nya dokument som hittat den underliggande källan läggs till i sökindexet.
- Alla dokument som finns i både datakällan och sökindexet skrivs över i sökindexet.
- Allt berikat innehåll som skapas från kunskapsuppsättningar återskapas. Berikningscachen, om den är aktiverad, uppdateras.
Som tidigare nämnts är återställning en passiv åtgärd: du måste följa upp en Körningsbegäran för att återskapa indexet.
Återställnings-/körningsåtgärder gäller för ett sökindex eller ett kunskapslager, för specifika dokument eller projektioner och för cachelagrade berikanden om en återställning uttryckligen eller implicit innehåller kunskaper.
Återställning gäller även för åtgärder för att skapa och uppdatera. Det utlöser inte borttagning eller rensning av överblivna dokument i sökindexet. Mer information om hur du tar bort dokument finns i Dokument – Index.
När du har återställt en indexerare kan du inte ångra åtgärden.
Logga in på Azure-portalen och öppna söktjänstsidan.
På sidan Översikt väljer du fliken Indexerare .
Välj en indexerare.
Välj kommandot Återställ och välj sedan Ja för att bekräfta åtgärden.
Uppdatera sidan för att visa statusen. Du kan välja objektet för att visa dess information.
Välj Kör för att starta indexeringsbearbetningen eller vänta på nästa schemalagda körning.
Så här återställer du kunskaper (förhandsversion)
För indexerare som har kompetensuppsättningar kan du återställa enskilda färdigheter för att framtvinga bearbetning av just den färdigheten och eventuella underordnade färdigheter som är beroende av dess utdata. Berikningscache , om du har aktiverat den, uppdateras också.
Återställningskunskaper är för närvarande endast REST-tillgängliga till och med 2020-06-30-preview eller senare. Vi rekommenderar det senaste förhandsversions-API:et.
POST /skillsets/[skillset name]/resetskills?api-version=2024-05-01-preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
Du kan ange individuella färdigheter, som anges i exemplet ovan, men om någon av dessa färdigheter kräver utdata från olistade färdigheter (#2 till #4) körs olistade färdigheter om inte cacheminnet kan tillhandahålla nödvändig information. För att detta ska vara sant får cachelagrade berikanden för kunskaper #2 till #4 inte ha beroende av #1 (anges för återställning).
Om inga kunskaper anges körs hela kompetensuppsättningen och om cachelagring är aktiverat uppdateras även cacheminnet.
Kom ihåg att följa upp med Run Indexer för att anropa faktisk bearbetning.
Så här återställer du dokument (förhandsversion)
Indexerare – Återställ dokument accepterar en lista med dokumentnycklar så att du kan uppdatera specifika dokument. Om det anges blir återställningsparametrarna den enda avgörande faktorn för vad som bearbetas, oavsett andra ändringar i underliggande data. Om till exempel 20 blobar har lagts till eller uppdaterats sedan den senaste indexeraren kördes, men du bara återställer ett dokument, bearbetas endast det dokumentet.
Baserat på dokument uppdateras alla fält i sökdokumentet med värden från datakällan. Du kan inte välja vilka fält som ska uppdateras.
Om dokumentet utökas via en kompetensuppsättning och har cachelagrade data anropas kunskapsuppsättningen bara för de angivna dokumenten och cachen uppdateras för de ombearbetade dokumenten.
När du testar det här API:et för första gången kan följande API:er hjälpa dig att verifiera och testa beteendena. Du kan använda förhandsversionen av API version 2020-06-30-preview och senare. Vi rekommenderar det senaste förhandsversions-API:et.
Anropa indexerare – Hämta status med en förhandsversion av API:et för att kontrollera återställningsstatus och körningsstatus. Du hittar information om återställningsbegäran i slutet av statussvaret.
Anropa indexerare – Återställ Dokument med en förhandsversion av API:et för att ange vilka dokument som ska bearbetas.
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2024-05-01-preview { "documentKeys" : [ "1001", "4452" ] }Dokumentnycklarna som anges i begäran är värden från sökindexet, som kan skilja sig från motsvarande fält i datakällan. Om du är osäker på nyckelvärdet skickar du en fråga för att returnera värdet. Du kan använda
selectför att bara returnera dokumentnyckelfältet.För blobar som parsas i flera sökdokument (där parsingMode är inställt på jsonLines eller jsonArrays eller avgränsadText) genereras dokumentnyckeln av indexeraren och kan vara okänd för dig. I det här scenariot returnerar en fråga för dokumentnyckeln rätt värde.
Anropa Kör indexerare (valfri API-version) för att bearbeta de dokument som du har angett. Endast de specifika dokumenten indexeras.
Anropa Kör indexerare en andra gång för att bearbeta från det senaste högvattenmärket.
Anropa Sökdokument för att söka efter uppdaterade värden och även för att returnera dokumentnycklar om du är osäker på värdet. Använd
"select": "<field names>"om du vill begränsa vilka fält som visas i svaret.
Skriva över dokumentnyckellistan
Om du anropar API för återställning av dokument flera gånger med olika nycklar läggs de nya nycklarna till i listan över återställning av dokumentnycklar. Om du anropar API:et med parametern overwrite inställd på true skrivs den aktuella listan över med den nya:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Kontrollera återställningsstatusen "currentState"
Om du vill kontrollera återställningsstatusen och se vilka dokumentnycklar som står i kö för bearbetning följer du dessa steg.
Anropa Hämta indexerarstatus med ett förhandsversions-API.
Förhandsgransknings-API:et
currentStatereturnerar avsnittet som finns i slutet av svaret."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Kontrollera läget:
För Återställ färdigheter ska "läge" anges till
indexingAllDocs(eftersom potentiellt alla dokument påverkas, när det gäller de fält som fylls i via AI-berikning).För Återställ dokument ska "läge" vara inställt på
indexingResetDocs. Indexeraren behåller den här statusen tills alla dokumentnycklar som anges i anropet för återställningsdokument bearbetas, under vilken tid inga andra indexerarjobb körs medan åtgärden pågår. Att hitta alla dokument i listan över dokumentnycklar kräver att varje dokument spricker för att hitta och matcha på nyckeln, och det kan ta en stund om datamängden är stor. Om en blobcontainer innehåller hundratals blobar och de dokument som du vill återställa finns i slutet hittar indexeraren inte matchande blobar förrän alla andra har kontrollerats först.När dokumenten har bearbetats igen kör du Hämta indexerarstatus igen. Indexeraren återgår till
indexingAllDocsläget och bearbetar alla nya eller uppdaterade dokument vid nästa körning.
Nästa steg
Återställnings-API:er används för att informera om omfånget för nästa indexerarekörning. För faktisk bearbetning måste du anropa en indexerare på begäran eller tillåta att ett schemalagt jobb slutför arbetet. När körningen är klar återgår indexeraren till normal bearbetning, oavsett om det sker enligt ett schema eller bearbetning på begäran.
När du har återställt och kört indexerarjobben igen kan du övervaka status från söktjänsten eller hämta detaljerad information via resursloggning.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för