Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure AI Search kan indexera JSON-dokument och matriser i Azure Blob Storage med hjälp av en indexerare som vet hur man läser halvstrukturerade data. Halvstrukturerade data innehåller taggar eller markeringar som separerar innehåll i data. Den delar skillnaden mellan ostrukturerade data som måste indexeras fullständigt och formellt strukturerade data som följer en datamodell, till exempel ett relationsdatabasschema som kan indexeras per fält.
Den här självstudien visar hur du indexera kapslade JSON-matriser med hjälp av en REST-klient och REST-API:er för sökning för att:
- Ställ in exempeldata och konfigurera en
azureblobdatakälla - Skapa ett Azure AI Search-index som innehåller sökbart innehåll
- Skapa och kör en indexerare för att läsa containern och extrahera sökbart innehåll
- Söka i indexet som du precis skapade
Förutsättningar
Ett Azure-konto med en aktiv prenumeration. Skapa ett konto utan kostnad.
Azure AI Search. Skapa en tjänst eller hitta en befintlig tjänst i din aktuella prenumeration.
Visual Studio Code med en REST-klient.
Kommentar
Du kan använda en kostnadsfri söktjänst för den här handledningen. Den kostnadsfria nivån begränsar dig till tre index, tre indexerare och tre datakällor. I den här kursen skapar du en av varje. Innan du börjar måste du se till att du har plats för din tjänst för att acceptera de nya resurserna.
Ladda ned filer
Ladda ned en zip-fil med exempeldatalagringsplatsen och extrahera innehållet. Läs mer.
Exempeldata är en enda JSON-fil som innehåller en JSON-matris och 1 521 kapslade JSON-element. Data kommer från NY Philharmonic Performance History på Kaggle. Vi valde en JSON-fil för att hålla oss under lagringsgränserna för den kostnadsfria nivån.
Här är den första kapslade JSON-filen. Resten av filen innehåller 1520 andra tillfällen av konsertföreställningar.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Ladda upp exempeldata till Azure Storage
I Azure Storage skapar du en ny container med namnet ny-philharmonic-free.
Hämta en lagringsanslutningssträng så att du kan skapa en anslutning i Azure AI Search.
Välj Åtkomstnycklar till vänster.
Kopiera anslutningssträng för antingen nyckel ett eller nyckel två. Anslutningssträng liknar följande exempel:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Kopiera en url för söktjänsten och API-nyckeln
I den här självstudien kräver anslutningar till Azure AI Search en slutpunkt och en API-nyckel. Du kan hämta dessa värden från Azure Portal. Alternativa anslutningsmetoder finns i Hanterade identiteter.
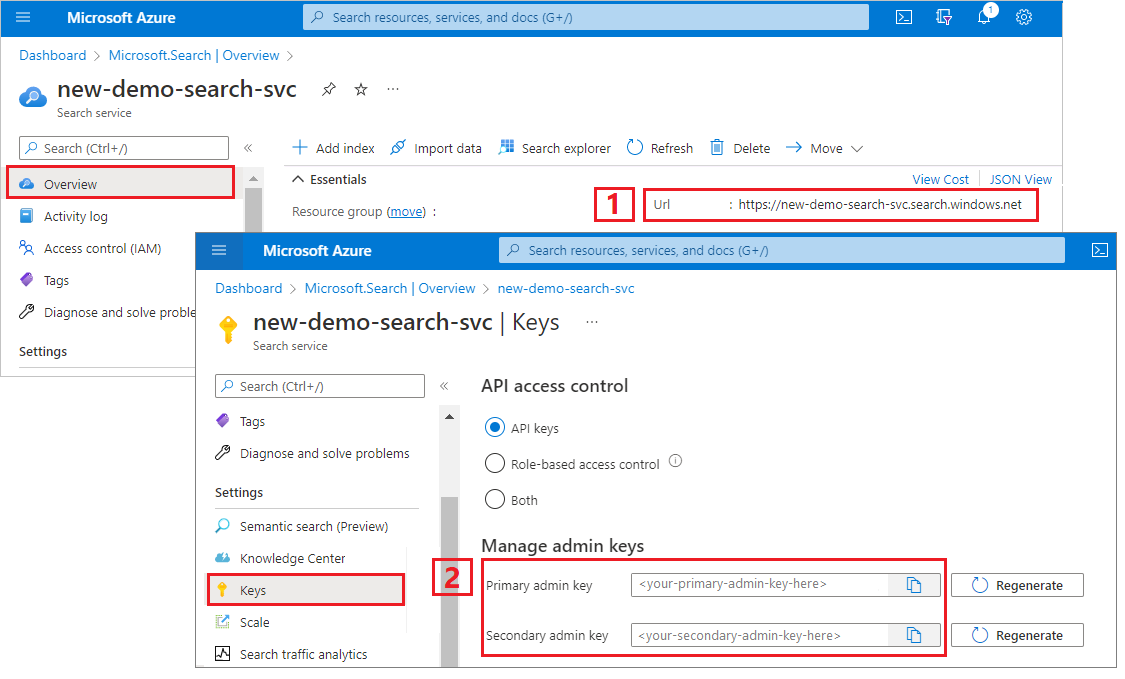
Logga in på Azure Portal, gå till översiktssidan för söktjänsten och kopiera URL:en. Här följer ett exempel på hur en slutpunkt kan se ut:
https://mydemo.search.windows.net.Under Inställningar>Nycklar kopierar du en administratörsnyckel. Administratörsnycklar används för att lägga till, ändra och ta bort objekt. Det finns två utbytbara administratörsnycklar. Kopiera någon av dem.
Konfigurera REST-filen
Starta Visual Studio Code och skapa en ny fil.
Ange värden för variabler som används i begäran.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESpara filen med hjälp av ett
.restfilnamnstillägg eller.httpfilnamnstillägg.
Hjälp med REST-klienten finns i Snabbstart: Fulltextsökning med REST.
Skapa en datakälla
Skapa datakälla (REST) skapar en datakällaanslutning som anger vilka data som ska indexeras.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnection}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Skicka begäran. Svaret ska se ut så här:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
Skapa ett index
Skapa index (REST) skapar ett sökindex i söktjänsten. Ett index anger alla parametrar och deras attribut.
För kapslad JSON måste indexfälten vara identiska med källfälten. För närvarande stöder Inte Azure AI Search fältmappningar till kapslad JSON, så fältnamn och datatyper måste matcha helt. Följande index justeras mot JSON-elementen i råinnehållet.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
Viktiga punkter:
Du kan inte använda fältmappningar för att stämma av skillnader i fältnamn eller datatyper. Det här indexschemat är utformat för att spegla råinnehållet.
Kapslad JSON modelleras som
Collection(Edm.ComplextType). I det råa innehållet finns det flera konserter för varje säsong och flera verk för varje konsert. Använd samlingar för komplexa typer för att hantera den här strukturen.I råinnehållet,
DateochTimeär strängar, så motsvarande datatyper i indexet är också strängar.
Skapa och köra en indexerare
Skapa Indexer skapar en indexerare i söktjänsten. En indexerare ansluter till datakällan, läser in och indexerar data, och du kan även ange ett schema för att automatisera datauppdateringen.
Indexerarens konfiguration innehåller jsonArray parsningsläget och en documentRoot.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
Viktiga punkter:
Den råa innehållsfilen innehåller en JSON-matris (
"programs") med 1 526 kapslade JSON-strukturer. AngeparsingModetilljsonArrayför att tala om för indexeraren att varje blob innehåller en JSON-matris. Eftersom den kapslade JSON startar en nivå nedåt anger dudocumentRoottill/programs.Indexeraren körs i flera minuter. Vänta tills indexerarens körning har slutförts innan du kör några frågekommandon.
Kör frågor
Du kan börja söka så snart det första dokumentet har lästs in.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Skicka begäran. Det här är en ospecificerad fulltextsökningsfråga som returnerar alla fält som markerats som hämtningsbara i indexet, tillsammans med ett antal dokument. Svaret ska se ut så här:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
Lägg till en search parameter för att söka efter en sträng, en select parameter för att begränsa resultatet till färre fält och en filter för att ytterligare begränsa sökningen.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
Två dokument returneras i svaret.
För filter kan du också använda logiska operatorer (och eller inte) och jämförelseoperatorer (eq, ne, gt, lt, ge, le). Strängjämförelser är skiftlägeskänsliga. Mer information och exempel finns i Skapa en fråga.
Kommentar
Parametern $filter fungerar bara på fält som har markerats som filterbara när index skapas.
Återställa och köra igen
Indexerare kan återställas för att ta bort körhistorik, vilket möjliggör en fullständig återstart. Följande POST-begäranden är för återställning, följt av omkörning.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
Rensa resurser
När du arbetar i din egen prenumeration i slutet av ett projekt är det en bra idé att ta bort de resurser som du inte längre behöver. Resurser som fortsätter att köras kan kosta dig pengar. Du kan ta bort enstaka resurser eller hela resursgruppen om du vill ta bort alla resurser.
Du kan använda Azure Portal för att ta bort index, indexerare och datakällor.
Nästa steg
Nu när du är bekant med grunderna i Azure Blob-indexering kan du titta närmare på indexerarkonfigurationen för JSON-blobar i Azure Storage: