Indexerare i Azure AI Search
En indexerare i Azure AI Search är en crawlare som extraherar textdata från molndatakällor och fyller i ett sökindex med hjälp av fält-till-fält-mappningar mellan källdata och ett sökindex. Den här metoden kallas ibland för en "pull-modell" eftersom söktjänsten hämtar data utan att du behöver skriva någon kod som lägger till data i ett index.
Indexerare driver också kompetensuppsättningskörning och AI-berikning, där du kan konfigurera färdigheter för att integrera extra bearbetning av innehåll på väg till ett index. Några exempel är OCR över bildfiler, textdelningsfärdighet för datasegmentering, textöversättning för flera språk.
Indexerare riktar in sig på datakällor som stöds. En indexerares konfiguration anger en datakälla (ursprung) och ett sökindex (mål). Flera källor, till exempel Azure Blob Storage, har fler konfigurationsegenskaper som är specifika för den innehållstypen.
Du kan köra indexerare på begäran eller enligt ett återkommande datauppdateringsschema som körs så ofta som var femte minut. Mer frekventa uppdateringar kräver en "push-modell" som samtidigt uppdaterar data i både Azure AI Search och din externa datakälla.
En söktjänst kör ett indexerarjobb per sökenhet. Om du behöver samtidig bearbetning kontrollerar du att du har tillräckligt med repliker. Indexerare körs inte i bakgrunden, så du kan identifiera fler frågebegränsningar än vanligt om tjänsten är under press.
Indexerarier och användningsfall
Du kan använda en indexerare som enda medel för datainmatning eller i kombination med andra tekniker. I följande tabell sammanfattas huvudscenarierna.
| Scenario | Strategi |
|---|---|
| Enskild datakälla | Det här mönstret är det enklaste: en datakälla är den enda innehållsleverantören för ett sökindex. De flesta datakällor som stöds tillhandahåller någon form av ändringsidentifiering så att efterföljande indexerare körs och hämtar skillnaden när innehåll läggs till eller uppdateras i källan. |
| Flera datakällor | En indexerares specifikation kan bara ha en datakälla, men själva sökindexet kan acceptera innehåll från flera källor, där varje indexeringskörning ger nytt innehåll från en annan dataprovider. Varje källa kan bidra med sin del av fullständiga dokument eller fylla i valda fält i varje dokument. En närmare titt på det här scenariot finns i Självstudie: Index från flera datakällor. |
| Flera indexerare | Flera datakällor paras vanligtvis ihop med flera indexerare om du behöver variera körningsparametrar, schema eller fältmappningar. Utskalning mellan regioner i Azure AI Search är ett annat scenario. Du kan ha kopior av samma sökindex i olika regioner. Om du vill synkronisera innehåll för sökindex kan du ha flera indexerare som hämtar från samma datakälla, där varje indexerare riktar in sig på ett annat sökindex i varje region. Parallell indexering av mycket stora datamängder kräver också en strategi för flera indexerare, där varje indexerare riktar in sig på en delmängd av data. |
| Innehållstransformering | Indexerare driver kompetensuppsättningskörning och AI-berikande. Innehållstransformering definieras i en kompetensuppsättning som du kopplar till indexeraren. Du kan använda kunskaper för att införliva datasegmentering och vektorisering. |
Du bör planera att skapa en indexerare för varje kombination av målindex och datakälla. Du kan ha flera indexerare som skriver till samma index och du kan återanvända samma datakälla för flera indexerare. En indexerare kan dock bara använda en datakälla i taget och kan bara skriva till ett enda index. Som följande bild illustrerar ger en datakälla indata till en indexerare, som sedan fyller i ett enda index:

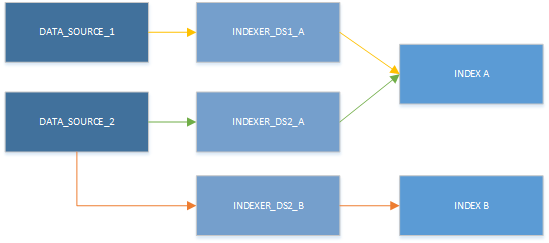
Även om du bara kan använda en indexerare i taget kan resurser användas i olika kombinationer. Det viktigaste i nästa bild är att observera att en datakälla kan paras ihop med mer än en indexerare och att flera indexerare kan skriva till samma index.
Datakällor som stöds
Indexerare crawlar datalager i Azure och utanför Azure.
- Azure Blob Storage
- Azure Cosmos DB
- Azure Data Lake Storage Gen2
- Azure SQL Database
- Azure Table Storage
- Hanterad Azure SQL-instans
- SQL Server på Azure Virtual Machines
- Azure Files (i förhandsversion)
- Azure MySQL (förhandsversion)
- SharePoint i Microsoft 365 (förhandsversion)
- Azure Cosmos DB för MongoDB (i förhandsversion)
- Azure Cosmos DB för Apache Gremlin (i förhandsversion)
Azure Cosmos DB för Cassandra stöds inte.
Indexerare accepterar utplattade raduppsättningar, till exempel en tabell eller vy, eller objekt i en container eller mapp. I de flesta fall skapas ett sökdokument per rad, post eller objekt.
Indexerareanslutningar till fjärranslutna datakällor kan göras med vanliga Internetanslutningar (offentliga) eller krypterade privata anslutningar när du använder en delad privat länk. Du kan också konfigurera anslutningar för att autentisera med hjälp av en hanterad identitet. Mer information om säkra anslutningar finns i Indexer-åtkomst till innehåll som skyddas av Azure-nätverkssäkerhetsfunktioner och Anslut till en datakälla med hjälp av en hanterad identitet.
Steg i indexering
Vid en första körning, när indexet är tomt, läser en indexerare in alla data som anges i tabellen eller containern. Vid efterföljande körningar kan indexeraren vanligtvis identifiera och hämta bara de data som har ändrats. För blobdata sker ändringsidentifiering automatiskt. För andra datakällor som Azure SQL eller Azure Cosmos DB måste ändringsidentifiering vara aktiverat.
För varje dokument som den tar emot implementerar eller samordnar en indexerare flera steg, från dokumenthämtning till en slutlig sökmotor för indexering. En indexerare kan också köra och mata ut kunskapsuppsättningar, förutsatt att en kompetensuppsättning har definierats.

Steg 1: Dokumentsprickor
Dokumentsprickor är processen att öppna filer och extrahera innehåll. Textbaserat innehåll kan extraheras från filer på en tjänst, rader i en tabell eller objekt i container eller samling. Om du lägger till en kompetensuppsättning och bildkunskaper kan dokumentsprickor också extrahera bilder och köa dem för bildbearbetning.
Beroende på datakällan provar indexeraren olika åtgärder för att extrahera potentiellt indexerbart innehåll:
När dokumentet är en fil med inbäddade bilder, till exempel en PDF, extraherar indexeraren text, bilder och metadata. Indexerare kan öppna filer från Azure Blob Storage, Azure Data Lake Storage Gen2 och SharePoint.
När dokumentet är en post i Azure SQL extraherar indexeraren icke-binärt innehåll från varje fält i varje post.
När dokumentet är en post i Azure Cosmos DB extraherar indexeraren icke-binärt innehåll från fält och underfält från Azure Cosmos DB-dokumentet.
Steg 2: Fältmappningar
En indexerare extraherar text från ett källfält och skickar den till ett målfält i ett index eller kunskapslager. När fältnamn och datatyper sammanfaller är sökvägen tydlig. Du kanske dock vill ha olika namn eller typer i utdata, i vilket fall du måste tala om för indexeraren hur fältet ska mappas.
Ange fältmappningar genom att ange käll- och målfälten i indexerarens definition.
Fältmappning sker efter dokumentsprickor, men före transformeringar, när indexeraren läser från källdokumenten. När du definierar en fältmappning skickas värdet för källfältet som det är till målfältet utan ändringar.
Steg 3: Körning av kompetensuppsättningar
Körning av kompetensuppsättningar är ett valfritt steg som anropar inbyggd eller anpassad AI-bearbetning. Kunskapsuppsättningar kan lägga till optisk teckenigenkänning (OCR) eller andra former av bildanalys om innehållet är binärt. Kompetensuppsättningar kan också lägga till bearbetning av naturligt språk. Du kan till exempel lägga till textöversättning eller extrahering av nyckelfraser.
Oavsett omvandling är det kompetensuppsättningskörningen där berikning sker. Om en indexerare är en pipeline kan du se en kompetensuppsättning som en "pipeline i pipelinen".
Steg 4: Mappningar av utdatafält
Om du inkluderar en kompetensuppsättning måste du ange mappningar för utdatafält i indexerarens definition. Utdata från en kompetensuppsättning visas internt som en trädstruktur som kallas för ett berikat dokument. Med mappningar av utdatafält kan du välja vilka delar av det här trädet som ska mappas till fält i indexet.
Trots likheten i namn skapar utdatafältmappningar och fältmappningar associationer från olika källor. Fältmappningar associerar innehållet i källfältet till ett målfält i ett sökindex. Mappningar av utdatafält associerar innehållet i ett internt berikat dokument (kunskapsutdata) med målfälten i indexet. Till skillnad från fältmappningar, som anses vara valfria, krävs en mappning av utdatafält för allt transformerat innehåll som ska finnas i indexet.
Nästa bild visar ett exempel på en indexerare som felsöker sessionsrepresentation av indexeringsstegen: dokumentsprickor, fältmappningar, körning av kompetensuppsättningar och mappningar av utdatafält.

Grundläggande arbetsflöde
Indexerare kan erbjuda funktioner som är unika för datakällan. I detta avseende varierar vissa aspekter av indexerarna och datakällskonfigurationen kan variera efter indexerartyp. Alla indexerare delar dock samma grundläggande sammansättning och krav. De steg som är gemensamma för alla indexerare beskrivs nedan.
Steg 1: Skapa en datakälla
Indexerare kräver ett datakällans objekt som tillhandahåller en anslutningssträng och eventuellt autentiseringsuppgifter. Datakällor är oberoende objekt. Flera indexerare kan använda samma datakällaobjekt för att läsa in mer än ett index i taget.
Du kan skapa en datakälla med någon av följande metoder:
- Med hjälp av Azure Portal går du till fliken Datakällor på söktjänstsidorna och väljer Lägg till datakälla för att ange datakällans definition.
- Med hjälp av Azure Portal matar guiden Importera data ut en datakälla.
- Anropa Skapa datakälla med hjälp av REST-API:erna.
- Anropa klassen SearchIndexerDataSourceConnection med hjälp av Azure SDK för .NET
Steg 2: Skapa ett index
En indexerare automatiserar vissa uppgifter som rör datapåfyllning, men att skapa ett index är vanligtvis inte en av dem. Som en förutsättning måste du ha ett fördefinierat index som innehåller motsvarande målfält för alla källfält i den externa datakällan. Fält måste matcha efter namn och datatyp. Annars kan du definiera fältmappningar för att upprätta associationen.
Mer information finns i Skapa ett index.
Steg 3: Skapa och köra (eller schemalägga) indexeraren
En indexeraredefinition består av egenskaper som unikt identifierar indexeraren, anger vilken datakälla och vilket index som ska användas och tillhandahåller andra konfigurationsalternativ som påverkar körningstidsbeteenden, inklusive om indexeraren körs på begäran eller enligt ett schema.
Eventuella fel eller varningar om dataåtkomst eller validering av kompetensuppsättningar inträffar under indexeringskörningen. Tills indexeringskörningen startar är beroende objekt som datakällor, index och kompetensuppsättningar passiva i söktjänsten.
Mer information finns i Skapa en indexerare
När den första indexeraren har körts kan du köra den igen på begäran eller konfigurera ett schema.
Du kan övervaka indexerarens status i portalen eller via Hämta indexerarens status-API. Du bör också köra frågor i indexet för att kontrollera att resultatet är det du förväntade dig.
Indexerare har inte dedikerade bearbetningsresurser. Baserat på detta kan indexerarnas status visas som inaktiv innan den körs (beroende på andra jobb i kön) och körningstiderna kanske inte är förutsägbara. Andra faktorer definierar även indexerarens prestanda, till exempel dokumentstorlek, dokumentkomplexitet, bildanalys med mera.
Nästa steg
Nu när du har introducerats för indexerare är nästa steg att granska indexerarens egenskaper och parametrar, schemaläggning och indexeringsövervakning. Du kan också gå tillbaka till listan över datakällor som stöds för mer information om en specifik källa.