Kusto-frågespråk i Microsoft Sentinel
Kusto-frågespråk är det språk som du använder för att arbeta med och manipulera data i Microsoft Sentinel. Loggarna som du matar in på din arbetsyta är inte värda mycket om du inte kan analysera dem och få viktig information dold i alla dessa data. Kusto-frågespråk har inte bara kraften och flexibiliteten att få den informationen, utan enkelheten att hjälpa dig att komma igång snabbt. Om du har en bakgrund inom skriptning eller arbete med databaser kommer mycket av innehållet i den här artikeln att kännas mycket bekant. Om inte, oroa dig inte, eftersom språkets intuitiva karaktär snabbt gör att du kan börja skriva egna frågor och driva värde för din organisation.
Den här artikeln beskriver grunderna i Kusto-frågespråk, som täcker några av de mest använda funktionerna och operatorerna, som ska hantera 75 till 80 procent av de frågor som du kommer att skriva dagligen. När du behöver mer djup eller om du vill köra mer avancerade frågor kan du dra nytta av den nya Advanced KQL för Microsoft Sentinel-arbetsboken (se det här inledande blogginlägget). Se även den officiella Kusto-frågespråk dokumentationen samt en mängd olika onlinekurser (till exempel Pluralsights).
Bakgrund – Varför Kusto-frågespråk?
Microsoft Sentinel bygger på Azure Monitor-tjänsten och använder Azure Monitors Log Analytics-arbetsytor för att lagra alla sina data. Dessa data innehåller något av följande:
- data som matas in från externa källor till fördefinierade tabeller med hjälp av Microsoft Sentinel-dataanslutningsprogram.
- data som matas in från externa källor till användardefinierade anpassade tabeller, med hjälp av anpassade dataanslutningar samt vissa typer av färdiga anslutningsappar.
- data som skapats av Själva Microsoft Sentinel, till följd av de analyser som skapas och utförs, till exempel aviseringar, incidenter och UEBA-relaterad information.
- data som laddats upp till Microsoft Sentinel för att hjälpa till med identifiering och analys – till exempel hotinformationsflöden och bevakningslistor.
Kusto-frågespråk har utvecklats som en del av Azure Data Explorer-tjänsten och är därför optimerad för att söka igenom stordatalager i en molnmiljö. Inspirerad av den berömda undervattensutforskaren Jacques Cousteau (och uttalas i enlighet därmed "koo-STOH"), är den utformad för att hjälpa dig att djupdyka i dina hav av data och utforska deras dolda skatter.
Kusto-frågespråk används också i Azure Monitor (och därför i Microsoft Sentinel), inklusive några ytterligare Azure Monitor-funktioner som gör att du kan hämta, visualisera, analysera och parsa data i Log Analytics-datalager. I Microsoft Sentinel använder du verktyg baserade på Kusto-frågespråk när du visualiserar och analyserar data och jagar efter hot, oavsett om det finns i befintliga regler och arbetsböcker eller när du skapar egna.
Eftersom Kusto-frågespråk är en del av nästan allt du gör i Microsoft Sentinel hjälper en tydlig förståelse för hur det fungerar att få ut så mycket mer av ditt SIEM.
Vad är en fråga?
En Kusto-frågespråk fråga är en skrivskyddad begäran om att bearbeta data och returnera resultat – den skriver inga data. Frågor körs på data som är ordnade i en hierarki med databaser, tabeller och kolumner, som liknar SQL.
Begäranden anges på vanligt språk och använder en dataflödesmodell som är utformad för att göra syntaxen enkel att läsa, skriva och automatisera. Vi kommer att se detta i detalj.
Kusto-frågespråk frågor består av instruktioner avgränsade med semikolon. Det finns många typer av instruktioner, men bara två typer som används ofta som vi diskuterar här:
tabelluttrycksinstruktioner är vad vi vanligtvis menar när vi pratar om frågor – det här är själva brödtexten i frågan. Det viktiga att veta om tabelluttrycksinstruktioner är att de accepterar tabellindata (en tabell eller ett annat tabelluttryck) och skapar tabellutdata. Minst en av dessa krävs. De flesta av resten av den här artikeln kommer att diskutera den här typen av uttalande.
let-instruktioner gör att du kan skapa och definiera variabler och konstanter utanför frågans brödtext för enklare läsbarhet och mångsidighet. Dessa är valfria och beror på dina specifika behov. Vi tar upp den här typen av instruktion i slutet av artikeln.
Demomiljö
Du kan öva Kusto-frågespråk -instruktioner – inklusive de i den här artikeln – i en Log Analytics-demomiljö i Azure-portalen. Det kostar ingenting att använda den här övningsmiljön, men du behöver ett Azure-konto för att komma åt den.
Utforska demomiljön. Precis som Log Analytics i produktionsmiljön kan den användas på flera olika sätt:
Välj en tabell som du vill skapa en fråga på. På fliken Tabeller (visas i den röda rektangeln längst upp till vänster) väljer du en tabell i listan över tabeller grupperade efter ämnen (visas längst ned till vänster). Expandera avsnitten för att se de enskilda tabellerna och du kan expandera varje tabell ytterligare för att se alla dess fält (kolumner). Om du dubbelklickar på en tabell eller ett fältnamn placeras det vid markörens punkt i frågefönstret. Skriv resten av frågan efter tabellnamnet enligt anvisningarna nedan.
Hitta en befintlig fråga att studera eller ändra. Välj fliken Frågor (visas i den röda rektangeln längst upp till vänster) för att se en lista över tillgängliga frågor. Du kan också välja Frågor i knappfältet längst upp till höger. Du kan utforska de frågor som medföljer Microsoft Sentinel direkt. Om du dubbelklickar på en fråga placeras hela frågan i frågefönstret vid markörens punkt.
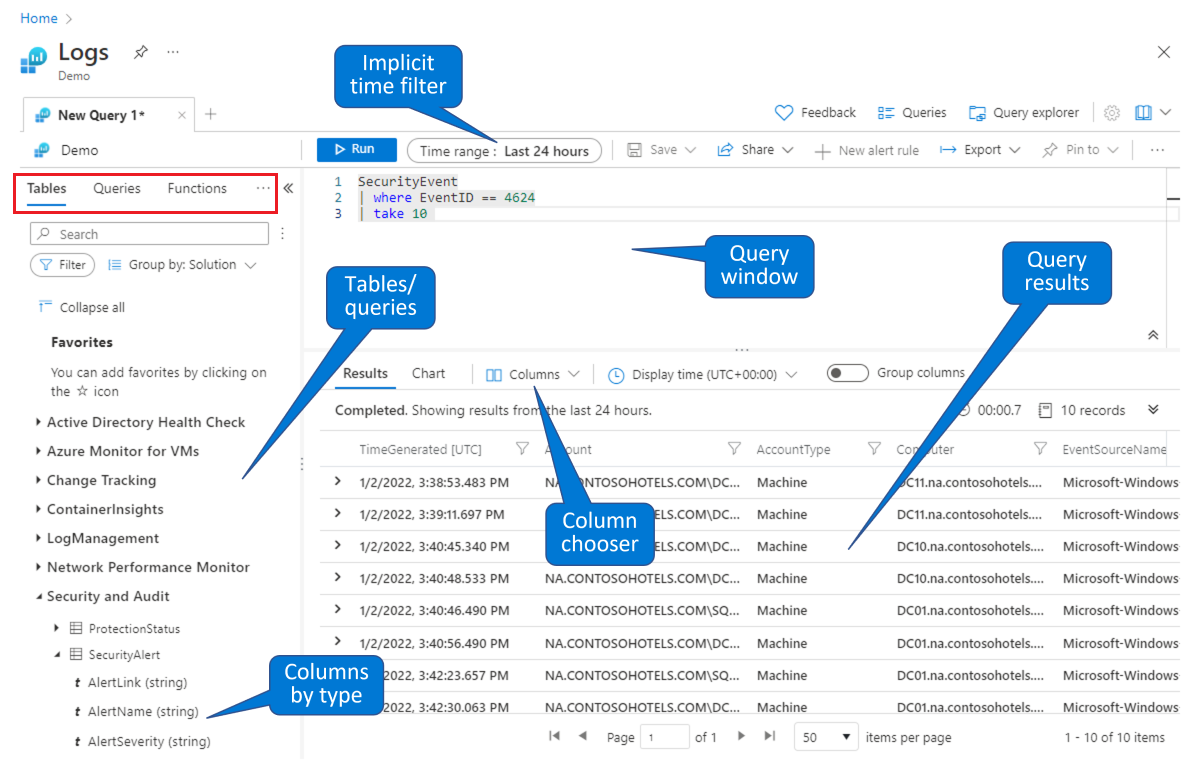
Precis som i den här demomiljön kan du fråga och filtrera data på sidan Microsoft Sentinel-loggar. Du kan välja en tabell och öka detaljnivån för att se kolumner. Du kan ändra standardkolumnerna som visas med kolumnväljaren och du kan ange standardtidsintervallet för frågor. Om tidsintervallet uttryckligen definieras i frågan blir tidsfiltret otillgängligt (nedtonat).
Frågestruktur
Ett bra ställe att börja lära sig Kusto-frågespråk är att förstå den övergripande frågestrukturen. Det första du ser när du tittar på en Kusto-fråga är användningen av pipe-symbolen (|). Strukturen för en Kusto-fråga börjar med att hämta dina data från en datakälla och sedan skicka data över en "pipeline", och varje steg ger en viss bearbetningsnivå och skickar sedan data till nästa steg. I slutet av pipelinen får du ditt slutliga resultat. I själva verket är det här vår pipeline:
Get Data | Filter | Summarize | Sort | Select
Det här konceptet med att skicka data i pipelinen ger en mycket intuitiv struktur, eftersom det är enkelt att skapa en mental bild av dina data i varje steg.
För att illustrera detta ska vi ta en titt på följande fråga, som tittar på Inloggningsloggar för Microsoft Entra. När du läser igenom varje rad kan du se nyckelorden som anger vad som händer med data. Vi har inkluderat relevant steg i pipelinen som en kommentar på varje rad.
Kommentar
Du kan lägga till kommentarer till valfri rad i en fråga genom att föregå dem med ett dubbelt snedstreck (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Eftersom utdata från varje steg fungerar som indata för följande steg kan stegens ordning fastställa frågans resultat och påverka dess prestanda. Det är viktigt att du beställer stegen efter vad du vill få ut av frågan.
Dricks
- En bra tumregel är att filtrera dina data tidigt, så att du bara skickar relevanta data i pipelinen. Detta ökar prestandan avsevärt och ser till att du inte oavsiktligt inkluderar irrelevanta data i sammanfattningsstegen.
- Den här artikeln kommer att peka på några andra metodtips att tänka på. En mer fullständig lista finns i avsnittet om metodtips för frågor.
Förhoppningsvis har du nu en uppskattning för den övergripande strukturen för en fråga i Kusto-frågespråk. Nu ska vi titta på själva frågeoperatorerna, som används för att skapa en fråga.
Datatyper
Innan vi går in på frågeoperatorerna ska vi först ta en snabb titt på datatyper. Precis som i de flesta språk avgör datatypen vilka beräkningar och manipuleringar som kan köras mot ett värde. Om du till exempel har ett värde som är av typen sträng kan du inte utföra aritmetiska beräkningar mot det.
I Kusto-frågespråk följer de flesta datatyperna standardkonventioner och har namn som du förmodligen har sett tidigare. I följande tabell visas den fullständiga listan:
Tabell med datatyp
| Type | Ytterligare namn | Motsvarande .NET-typ |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Även om de flesta datatyper är standard kan du vara mindre bekant med typer som dynamisk, tidsintervall och guid.
Dynamisk har en struktur som liknar JSON, men med en viktig skillnad: Den kan lagra Kusto-frågespråk specifika datatyper som traditionell JSON inte kan, till exempel ett kapslat dynamiskt värde eller tidsintervall. Här är ett exempel på en dynamisk typ:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Tidsintervall är en datatyp som refererar till ett tidsmått, till exempel timmar, dagar eller sekunder. Blanda inte ihop tidsintervall med datetime, som utvärderas till ett faktiskt datum och en faktisk tid, inte ett tidsmått. I följande tabell visas en lista över tidsintervallssuffix .
Tidsspannssuffix
| Function | Description |
|---|---|
D |
dagar |
H |
timmar |
M |
minutes |
S |
sekunder |
Ms |
millisekunder |
Microsecond |
Mikrosekunder |
Tick |
Nanosekunder |
Guid är en datatyp som representerar en 128-bitars, globalt unik identifierare, som följer standardformatet [8]-[4]-[4]-[4]-[12], där varje [tal] representerar antalet tecken och varje tecken kan variera från 0-9 eller a-f.
Kommentar
Kusto-frågespråk har både tabelloperatorer och skaläroperatorer. Under resten av den här artikeln, om du bara ser ordet "operator", kan du anta att det betyder tabelloperator, om inget annat anges.
Hämta, begränsa, sortera och filtrera data
Den grundläggande vokabulären för Kusto-frågespråk – grunden som gör att du kan utföra den överväldigande majoriteten av dina uppgifter – är en samling operatorer för filtrering, sortering och val av data. De återstående uppgifter som du behöver utföra kräver att du utökar dina kunskaper i språket för att uppfylla dina mer avancerade behov. Nu ska vi expandera lite på några av de kommandon som vi använde i exemplet ovan och titta på take, sortoch where.
För var och en av dessa operatorer undersöker vi dess användning i vårt tidigare SigninLogs-exempel och lär oss antingen ett användbart tips eller en metodtips.
Hämta data
Den första raden i en grundläggande fråga anger vilken tabell du vill arbeta med. När det gäller Microsoft Sentinel är detta förmodligen namnet på en loggtyp på din arbetsyta, till exempel SigninLogs, SecurityAlert eller CommonSecurityLog. Till exempel:
SigninLogs
Observera att i Kusto-frågespråk är loggnamn skiftlägeskänsliga, så SigninLogs och signinLogs tolkas på olika sätt. Var försiktig när du väljer namn för dina anpassade loggar, så att de är lätt identifierbara och inte alltför lika en annan logg.
Begränsa data: ta / gräns
Take-operatorn (och den identiska gränsoperatorn) används för att begränsa dina resultat genom att endast returnera ett visst antal rader. Det följs av ett heltal som anger hur många rader som ska returneras. Vanligtvis används den i slutet av en fråga när du har fastställt sorteringsordningen, och i så fall returneras det angivna antalet rader överst i den sorterade ordningen.
Att använda take tidigare i frågan kan vara användbart för att testa en fråga, när du inte vill returnera stora datamängder. Men om du placerar take åtgärden före några sort åtgärder take returneras rader som valts slumpmässigt – och eventuellt en annan uppsättning rader varje gång frågan körs. Här är ett exempel på hur du använder take:
SigninLogs
| take 5
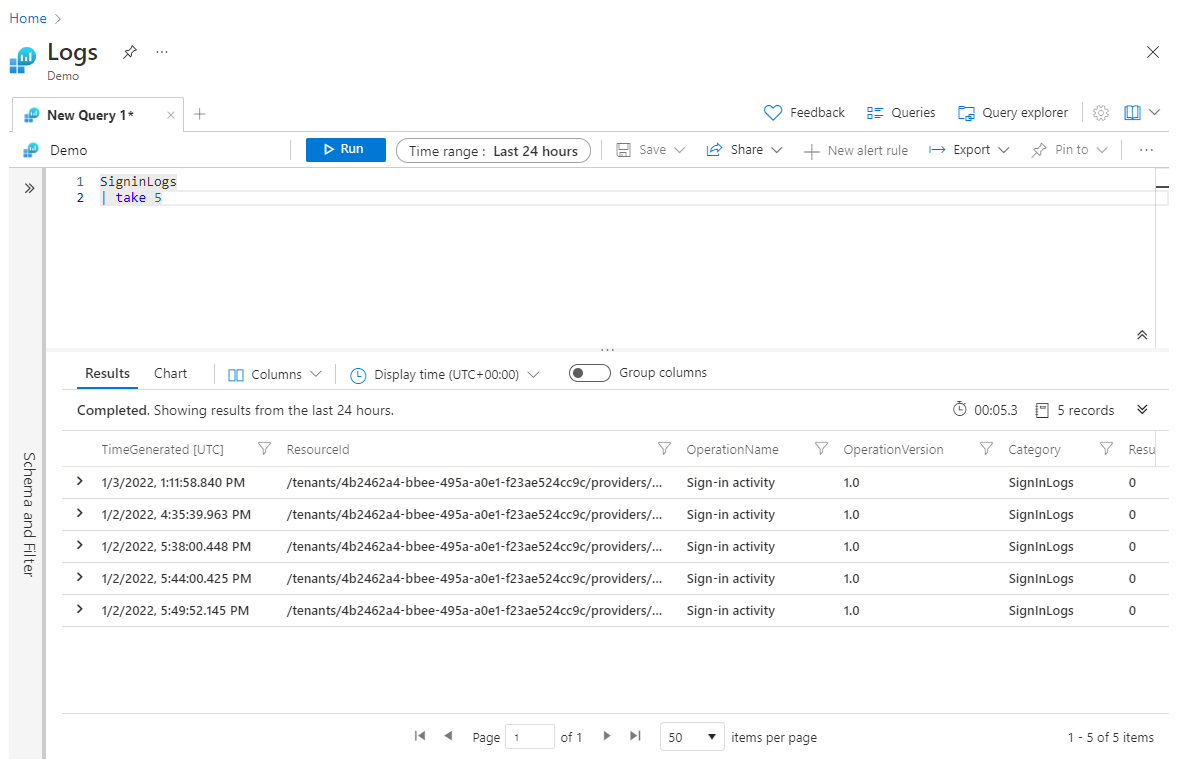
Dricks
När du arbetar med en helt ny fråga där du kanske inte vet hur frågan kommer att se ut kan det vara användbart att placera en take instruktion i början för att artificiellt begränsa datauppsättningen för snabbare bearbetning och experimentering. När du är nöjd med den fullständiga frågan kan du ta bort det första take steget.
Sorteringsdata: sorteringsordning /
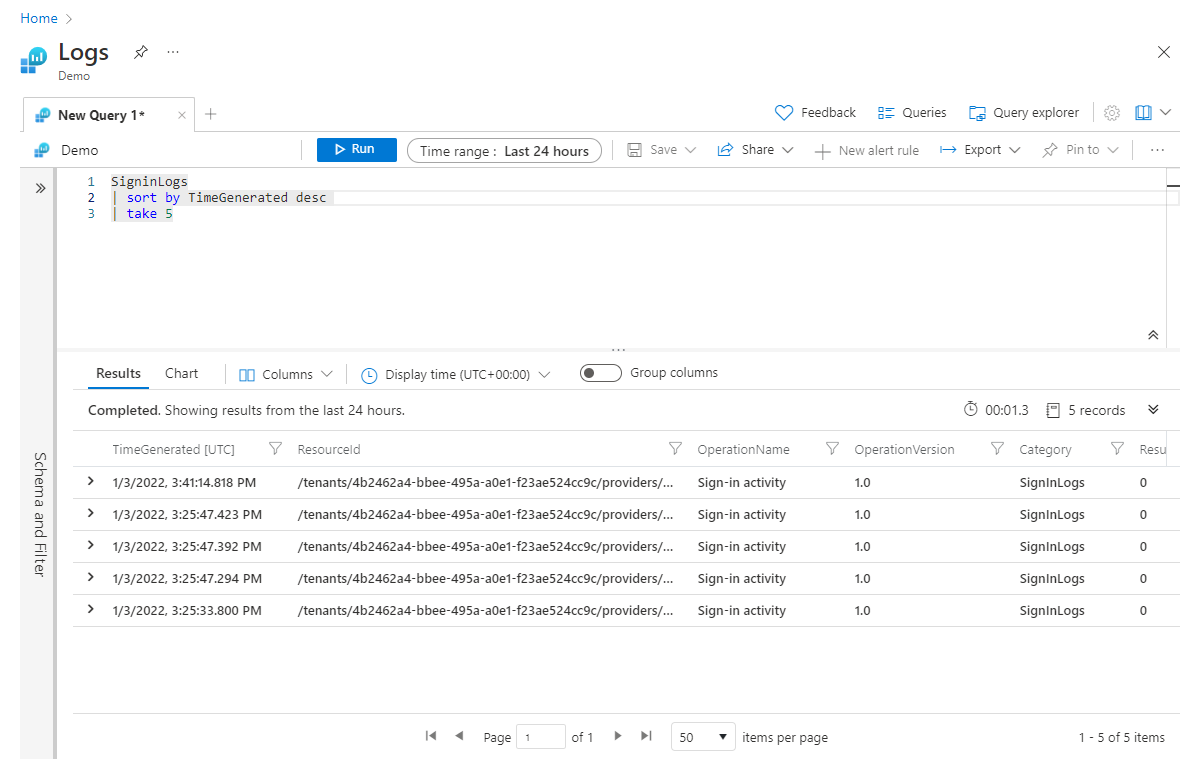
Sorteringsoperatorn (och den identiska orderoperatorn) används för att sortera dina data efter en angiven kolumn. I följande exempel beställde vi resultatet efter TimeGenerated och anger orderriktningen till fallande med desc-parametern och placerar de högsta värdena först. För stigande ordning använder vi asc.
Kommentar
Standardriktningen för sortering är fallande, så tekniskt sett behöver du bara ange om du vill sortera i stigande ordning. Om du anger sorteringsriktningen i vilket fall som helst blir frågan dock mer läsbar.
SigninLogs
| sort by TimeGenerated desc
| take 5
Som vi nämnde placerar vi operatorn sort före operatorn take . Vi måste sortera först för att se till att vi får rätt fem poster.
Topp
Med den översta operatorn kan vi kombinera sort åtgärderna och take till en enda operator:
SigninLogs
| top 5 by TimeGenerated desc
Om två eller flera poster har samma värde i kolumnen som du sorterar efter kan du lägga till fler kolumner att sortera efter. Lägg till extra sorteringskolumner i en kommaavgränsad lista som finns efter den första sorteringskolumnen, men före nyckelordet sorteringsordning. Till exempel:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Om TimeGenerated nu är detsamma mellan flera poster kommer det att försöka sortera efter värdet i kolumnen Identitet.
Kommentar
När du ska använda sort och take, och när du ska använda top
Om du bara sorterar i ett fält använder du
top, eftersom det ger bättre prestanda än kombinationen avsortochtake.Om du behöver sortera på fler än ett fält (som i det senaste exemplet ovan)
topkan du inte göra det, så du måste användasortochtake.
Filtrera data: där
Där operatorn utan tvekan är den viktigaste operatorn, eftersom det är nyckeln till att se till att du bara arbetar med den delmängd av data som är relevant för ditt scenario. Du bör göra ditt bästa för att filtrera dina data så tidigt som möjligt i frågan eftersom det förbättrar frågeprestandan genom att minska mängden data som behöver bearbetas i efterföljande steg. Det säkerställer också att du bara utför beräkningar på önskade data. Se det här exemplet:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
Operatorn where anger en variabel, en jämförelseoperator (skalär) och ett värde. I vårt fall brukade >= vi ange att värdet i kolumnen TimeGenerated måste vara större än (dvs. senare än) eller lika med för sju dagar sedan.
Det finns två typer av jämförelseoperatorer i Kusto-frågespråk: sträng och numerisk. I följande tabell visas en fullständig lista över numeriska operatorer:
Numeriska operatorer
| Operatör | Description |
|---|---|
+ |
Tillägg |
- |
Subtraktion |
* |
Multiplikation |
/ |
Division |
% |
Modulo |
< |
Mindre än |
> |
Större än |
== |
Lika med |
!= |
Inte lika med |
<= |
Mindre än eller lika med |
>= |
Större än eller lika med |
in |
Lika med ett av elementen |
!in |
Inte lika med något av elementen |
Listan över strängoperatorer är en mycket längre lista eftersom den har permutationer för skiftlägeskänslighet, understrängsplatser, prefix, suffix och mycket mer. Operatorn == är både en numerisk operator och strängoperator, vilket innebär att den kan användas för både tal och text. Båda följande påståenden skulle till exempel vara giltiga där -instruktioner:
| where ResultType == 0| where Category == 'SignInLogs'
Dricks
Bästa praxis: I de flesta fall vill du förmodligen filtrera dina data med mer än en kolumn eller filtrera samma kolumn på mer än ett sätt. I dessa fall finns det två metodtips som du bör tänka på.
Du kan kombinera flera where instruktioner i ett enda steg med hjälp av nyckelordet och . Till exempel:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
När du har flera filter anslutna till en enda where instruktion med nyckelordet och , som ovan, får du bättre prestanda genom att placera filter som bara refererar till en enda kolumn först. Så ett bättre sätt att skriva ovanstående fråga är:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
I det här exemplet nämner det första filtret en enda kolumn (TimeGenerated), medan det andra refererar till två kolumner (Resurs och ResourceGroup).
Sammanfatta data
Summarize är en av de viktigaste tabelloperatorerna i Kusto-frågespråk, men det är också en av de mer komplexa operatorerna att lära sig om du är nybörjare på att fråga språk i allmänhet. Jobbet summarize är att ta in en tabell med data och mata ut en ny tabell som aggregeras av en eller flera kolumner.
Struktur för sammanfattningssatsen
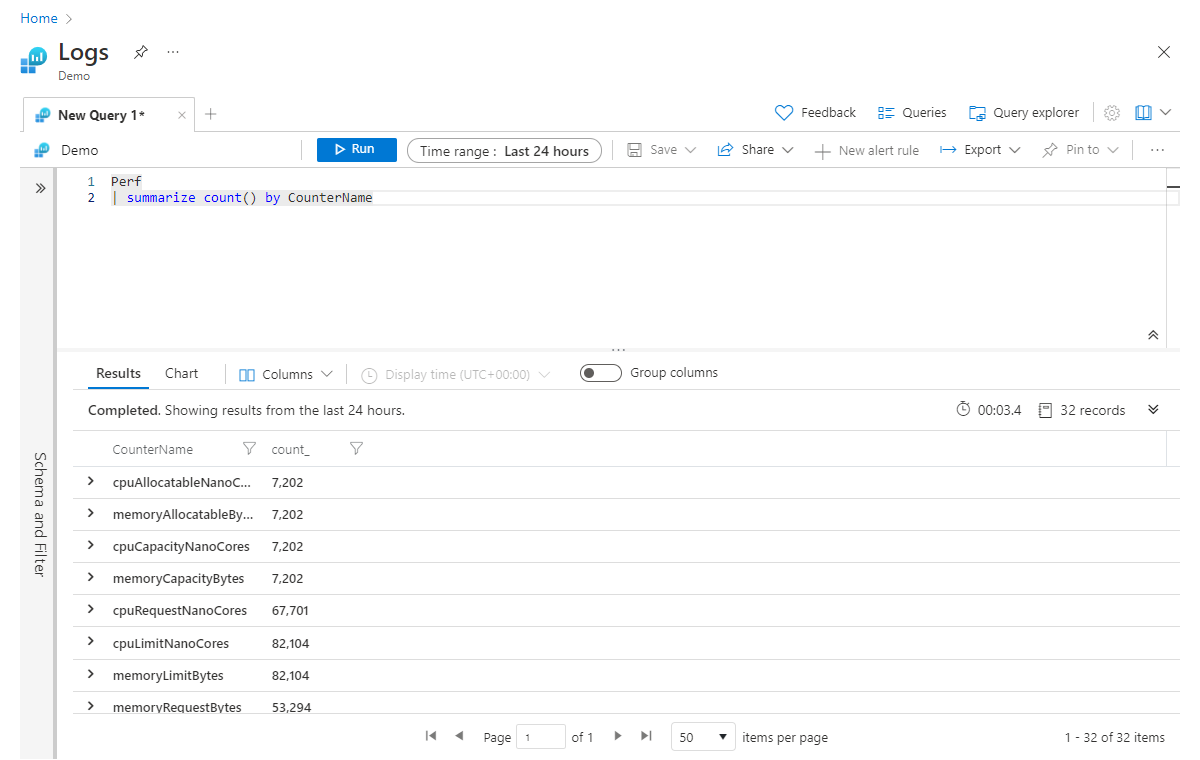
Den grundläggande strukturen för en summarize instruktion är följande:
| summarize <aggregation> by <column>
Följande returnerar till exempel antalet poster för varje CounterName-värde i tabellen Perf :
Perf
| summarize count() by CounterName
Eftersom utdata summarize från är en ny tabell skickas inte alla kolumner som inte uttryckligen anges i -instruktionen summarizei pipelinen. För att illustrera det här konceptet bör du tänka på följande exempel:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
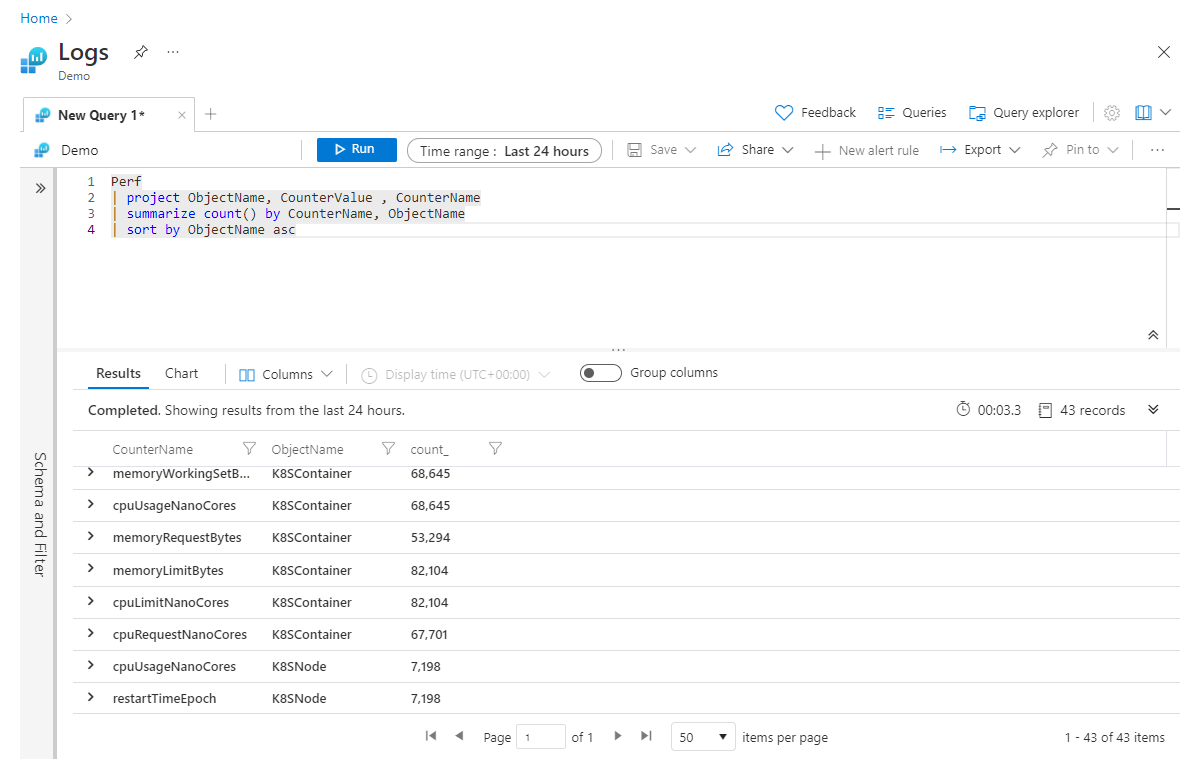
På den andra raden anger vi att vi bara bryr oss om kolumnerna ObjectName, CounterValue och CounterName. Sedan sammanfattade vi för att hämta antalet poster efter CounterName och slutligen försöker vi sortera data i stigande ordning baserat på kolumnen ObjectName . Tyvärr misslyckas den här frågan med ett fel (som anger att ObjectName är okänt) eftersom vi när vi sammanfattade bara inkluderade kolumnerna Count och CounterName i vår nya tabell. För att undvika det här felet kan vi helt enkelt lägga till ObjectName i slutet av vårt summarize steg, så här:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
Sättet att läsa summarize raden i huvudet är: "sammanfatta antalet poster efter CounterName och gruppera efter ObjectName". Du kan fortsätta att lägga till kolumner, avgränsade med kommatecken, i slutet av -instruktionen summarize .
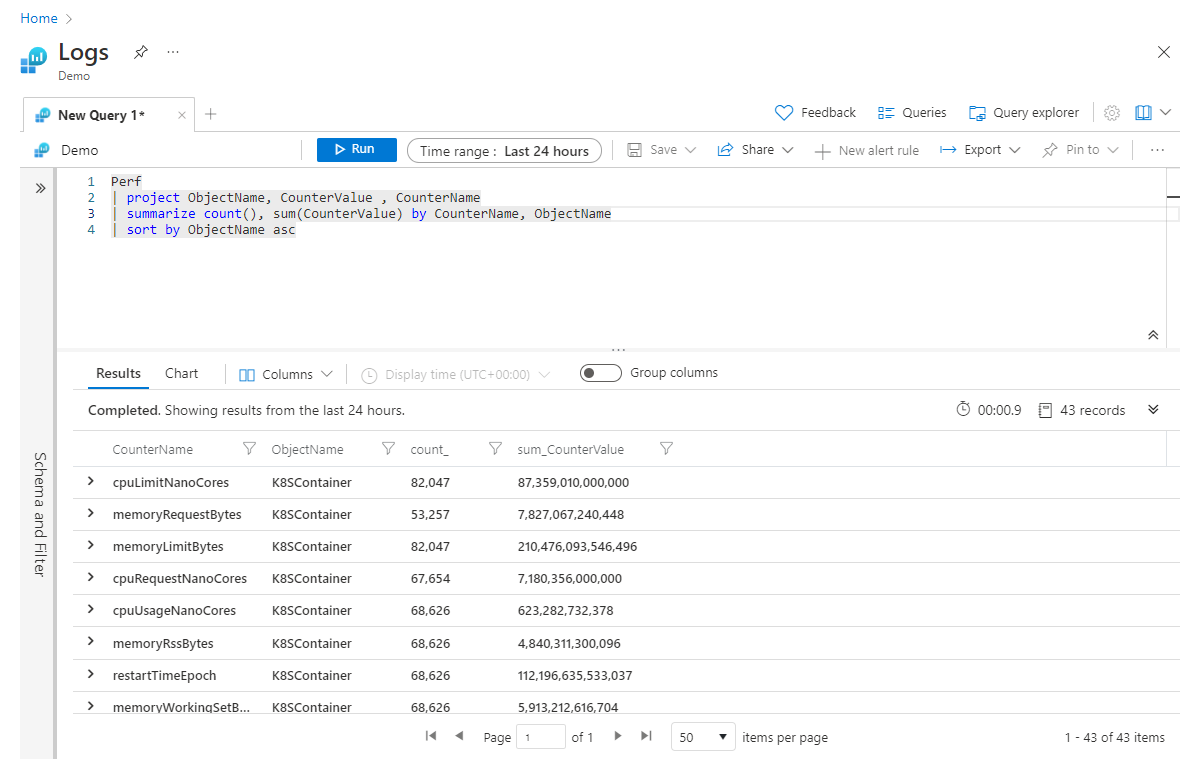
Om vi bygger vidare på det föregående exemplet, om vi vill aggregera flera kolumner samtidigt, kan vi uppnå detta genom att lägga till aggregeringar till operatorn summarize , avgränsade med kommatecken. I exemplet nedan får vi inte bara ett antal poster utan också en summa av värdena i kolumnen CounterValue för alla poster (som matchar alla filter i frågan):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
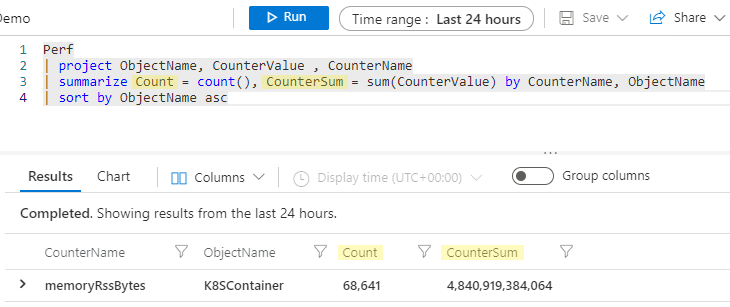
Byta namn på aggregerade kolumner
Det här verkar vara ett bra tillfälle att prata om kolumnnamn för dessa aggregerade kolumner. I början av det här avsnittet sa vi att operatorn summarize tar in en datatabell och skapar en ny tabell, och endast de kolumner som du anger i -instruktionen summarize fortsätter nedåt i pipelinen. Om du kör exemplet ovan skulle därför de resulterande kolumnerna för vår aggregering vara count_ och sum_CounterValue.
Kusto-motorn skapar automatiskt ett kolumnnamn utan att vi behöver vara explicita, men ofta kommer du att märka att du föredrar att din nya kolumn har ett vänligare namn. Du kan enkelt byta namn på kolumnen i -instruktionen summarize genom att ange ett nytt namn följt av = och aggregeringen, så här:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Nu får våra sammanfattade kolumner namnet Count och CounterSum.
Det finns mycket mer i operatören summarize än vad vi kan ta upp här, men du bör investera tid för att lära dig det eftersom det är en viktig komponent för alla dataanalyser som du planerar att utföra på dina Microsoft Sentinel-data.
Sammansättningsreferens
Det finns många sammansättningsfunktioner, men några av de vanligaste är sum(), count()och avg(). Här är en partiell lista (se hela listan):
Aggregeringsfunktioner
| Function | Description |
|---|---|
arg_max() |
Returnerar ett eller flera uttryck när argumentet maximeras |
arg_min() |
Returnerar ett eller flera uttryck när argumentet minimeras |
avg() |
Returnerar genomsnittligt värde i hela gruppen |
buildschema() |
Returnerar det minimala schemat som tar emot alla värden för dynamiska indata |
count() |
Returnerar antalet för gruppen |
countif() |
Returnerar antal med predikatet för gruppen |
dcount() |
Returnerar ungefärligt distinkt antal gruppelement |
make_bag() |
Returnerar en egenskapsuppsättning med dynamiska värden i gruppen |
make_list() |
Returnerar en lista över alla värden i gruppen |
make_set() |
Returnerar en uppsättning distinkta värden i gruppen |
max() |
Returnerar det maximala värdet i gruppen |
min() |
Returnerar minimivärdet i gruppen |
percentiles() |
Returnerar percentilens ungefärliga för gruppen |
stdev() |
Returnerar standardavvikelsen i gruppen |
sum() |
Returnerar summan av elementen i gruppen |
take_any() |
Returnerar slumpmässigt värde som inte är tomt för gruppen |
variance() |
Returnerar variansen i gruppen |
Välja: lägga till och ta bort kolumner
När du börjar arbeta mer med frågor kan du upptäcka att du har mer information än du behöver om dina ämnen (det vill: för många kolumner i tabellen). Eller så kan du behöva mer information än du har (det vill: du måste lägga till en ny kolumn som innehåller resultatet av analys av andra kolumner). Nu ska vi titta på några av nyckeloperatorerna för kolumnmanipulering.
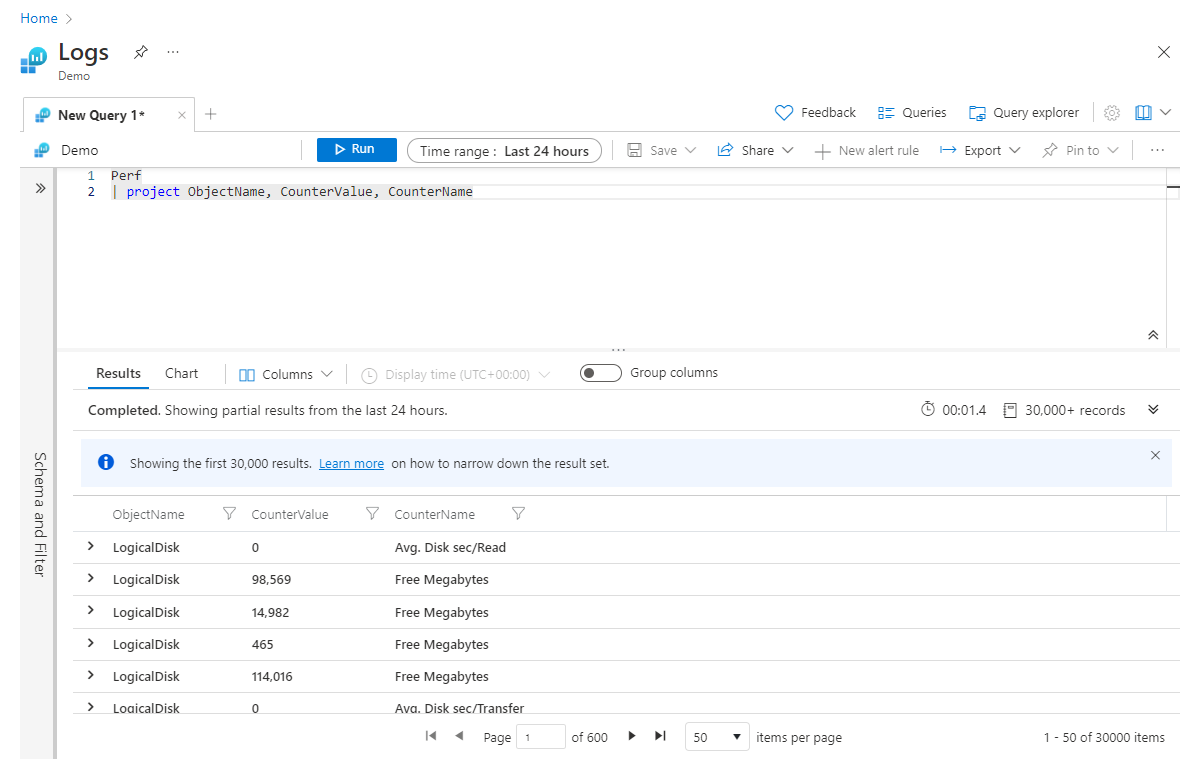
Projekt och projekt bort
Project motsvarar ungefär många språks select-instruktioner . Det gör att du kan välja vilka kolumner som ska behållas. Ordningen på de kolumner som returneras matchar ordningen på de kolumner som du listar i - project instruktionen, som du ser i det här exemplet:
Perf
| project ObjectName, CounterValue, CounterName
Som du kan föreställa dig, när du arbetar med mycket breda datauppsättningar, kan du ha många kolumner som du vill behålla, och att ange dem alla efter namn skulle kräva mycket skrivning. I dessa fall har du project-away, vilket gör att du kan ange vilka kolumner du vill ta bort i stället för vilka som ska behållas, så här:
Perf
| project-away MG, _ResourceId, Type
Dricks
Det kan vara användbart att använda project på två platser i dina frågor, i början och igen i slutet. Att använda project tidigt i frågan kan hjälpa till att förbättra prestanda genom att ta bort stora mängder data som du inte behöver skicka pipelinen. Om du använder den igen i slutet kan du bli av med alla kolumner som kan ha skapats i föregående steg och som inte behövs i dina slutliga utdata.
Utöka
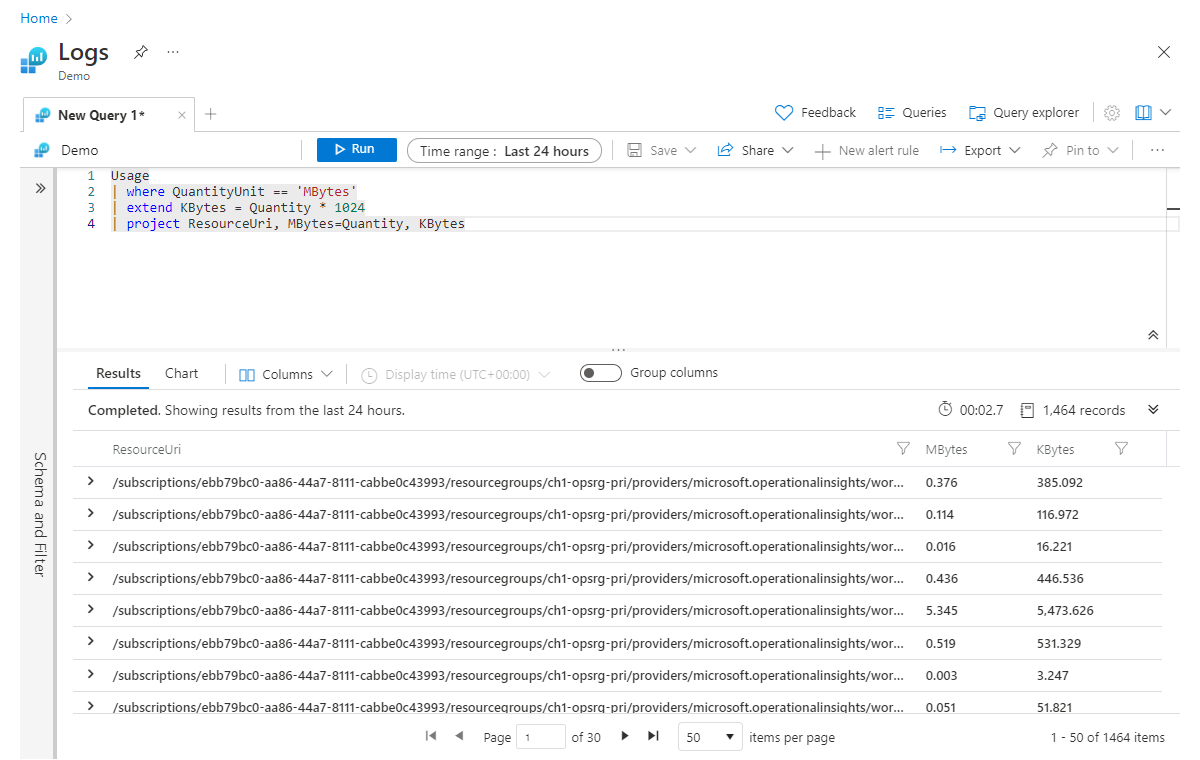
Utöka används för att skapa en ny beräknad kolumn. Detta kan vara användbart när du vill utföra en beräkning mot befintliga kolumner och se utdata för varje rad. Nu ska vi titta på ett enkelt exempel där vi beräknar en ny kolumn med namnet Kbyte, som vi kan beräkna genom att multiplicera MB-värdet (i den befintliga kvantitetskolumnen ) med 1 024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
På den sista raden i vår project -instruktion har vi bytt namn på kolumnen Quantity till Mbytes, så att vi enkelt kan se vilken måttenhet som är relevant för varje kolumn.
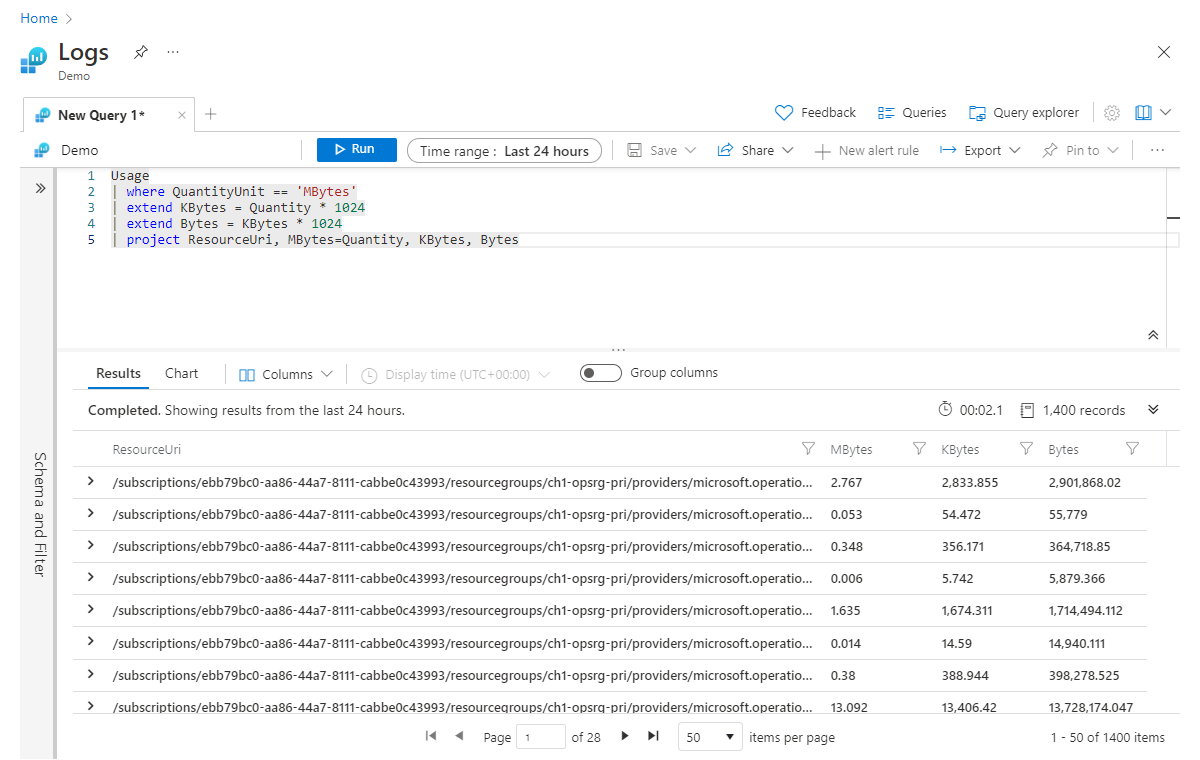
Det är värt att notera att extend även fungerar med redan beräknade kolumner. Vi kan till exempel lägga till ytterligare en kolumn med namnet Byte som beräknas från Kbyte:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Koppla tabeller
Mycket av ditt arbete i Microsoft Sentinel kan utföras med hjälp av en enda loggtyp, men det finns tillfällen då du vill korrelera data tillsammans eller utföra en sökning mot en annan uppsättning data. Precis som de flesta frågespråk erbjuder Kusto-frågespråk några operatorer som används för att utföra olika typer av kopplingar. I det här avsnittet tittar vi på de mest använda operatorerna union och join.
Unionen
Union tar helt enkelt två eller flera tabeller och returnerar alla rader. Till exempel:
OfficeActivity
| union SecurityEvent
Då returneras alla rader från tabellerna OfficeActivity och SecurityEvent . Union erbjuder några parametrar som kan användas för att justera hur facket beter sig. Två av de mest användbara är withsource och kind:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
Med parametern withsource kan du ange namnet på en ny kolumn vars värde på en viss rad är namnet på den tabell som raden kom från. I exemplet ovan namngav vi kolumnen SourceTable, och beroende på raden blir värdet antingen OfficeActivity eller SecurityEvent.
Den andra parametern som vi angav var snäll, som har två alternativ: inre eller yttre. I exemplet ovan har vi angett inre, vilket innebär att de enda kolumner som ska behållas under unionen är de som finns i båda tabellerna. Om vi hade angett yttre (vilket är standardvärdet) returneras också alla kolumner från båda tabellerna.
Join
Kopplingen fungerar på samma sätt som , förutom att unionvi i stället för att koppla tabeller för att skapa en ny tabell sammanfogar rader för att skapa en ny tabell. Precis som de flesta databasspråk finns det flera typer av kopplingar som du kan utföra. Den allmänna syntaxen för en join är:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Efter operatorn join anger vi vilken typ av koppling vi vill utföra följt av en öppen parentes. Inom parenteserna är den plats där du anger den tabell som du vill ansluta till, samt andra frågeinstruktioner i tabellen som du vill lägga till. Efter den avslutande parentesen använder vi nyckelordet på följt av vår vänstra ($left.<columnName-nyckelord> ) och höger ($right.<columnName)->kolumner avgränsade med operatorn == . Här är ett exempel på en inre koppling:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Kommentar
Om båda tabellerna har samma namn för de kolumner där du utför en koppling behöver du inte använda $left och $right. I stället kan du bara ange kolumnnamnet. Att använda $left och $right är dock mer explicit och allmänt anses vara en god praxis.
Som referens visar följande tabell en lista över tillgängliga typer av kopplingar.
Typer av kopplingar
| Kopplingstyp | Description |
|---|---|
inner |
Returnerar en enskild för varje kombination av matchande rader från båda tabellerna. |
innerunique |
Returnerar rader från den vänstra tabellen med distinkta värden i det länkade fältet som har en matchning i den högra tabellen. Det här är standardtypen för ospecificerad koppling. |
leftsemi |
Returnerar alla poster från den vänstra tabellen som har en matchning i den högra tabellen. Endast kolumner från den vänstra tabellen returneras. |
rightsemi |
Returnerar alla poster från den högra tabellen som har en matchning i den vänstra tabellen. Endast kolumner från den högra tabellen returneras. |
leftanti/leftantisemi |
Returnerar alla poster från den vänstra tabellen som inte har någon matchning i den högra tabellen. Endast kolumner från den vänstra tabellen returneras. |
rightanti/rightantisemi |
Returnerar alla poster från den högra tabellen som inte har någon matchning i den vänstra tabellen. Endast kolumner från den högra tabellen returneras. |
leftouter |
Returnerar alla poster från den vänstra tabellen. För poster som inte har någon matchning i den högra tabellen är cellvärdena null. |
rightouter |
Returnerar alla poster från den högra tabellen. För poster som inte har någon matchning i den vänstra tabellen är cellvärdena null. |
fullouter |
Returnerar alla poster från både vänster och höger tabeller, matchande eller inte. Omatchade värden är null. |
Dricks
Det är en bra idé att ha din minsta tabell till vänster. I vissa fall kan du få enorma prestandafördelar genom att följa den här regeln, beroende på vilka typer av kopplingar du utför och storleken på tabellerna.
Utvärdera
Du kanske kommer ihåg att i det första exemplet såg vi utvärdera operatorn på en av raderna. Operatorn evaluate används mindre ofta än de som vi har berört tidigare. Men att veta hur operatören evaluate fungerar är väl värt din tid. Här är ännu en gång den första frågan, där du kommer att se evaluate på den andra raden.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Med den här operatorn kan du anropa tillgängliga plugin-program (i princip inbyggda funktioner). Många av dessa plugin-program fokuserar på datavetenskap, till exempel autocluster, diffpatterns och sequence_detect, så att du kan utföra avancerad analys och upptäcka statistiska avvikelser och extremvärden.
Plugin-programmet som användes i exemplet ovan kallades bag_unpack, och det gör det mycket enkelt att ta en del dynamiska data och konvertera dem till kolumner. Kom ihåg att dynamiska data är en datatyp som liknar JSON, vilket visas i det här exemplet:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
I det här fallet ville vi sammanfatta data efter stad, men staden finns som en egenskap i kolumnen LocationDetails . För att använda stadsegenskapen i vår fråga var vi tvungna att först konvertera den till en kolumn med hjälp av bag_unpack.
När vi gick tillbaka till våra ursprungliga pipelinesteg såg vi följande:
Get Data | Filter | Summarize | Sort | Select
Nu när vi har övervägt operatorn evaluate kan vi se att den representerar en ny fas i pipelinen, som nu ser ut så här:
Get Data | Parse | Filter | Summarize | Sort | Select
Det finns många andra exempel på operatorer och funktioner som kan användas för att parsa datakällor i ett mer läsbart och manipulaterbart format. Du kan lära dig mer om dem – och resten av Kusto-frågespråk – i den fullständiga dokumentationen och i arbetsboken.
Let-instruktioner
Nu när vi har gått igenom många av de viktigaste operatorerna och datatyperna ska vi avsluta med let-instruktionen, vilket är ett bra sätt att göra dina frågor enklare att läsa, redigera och underhålla.
Låt dig skapa och ange en variabel eller tilldela ett namn till ett uttryck. Det här uttrycket kan vara ett enda värde, men det kan också vara en hel fråga. Här är ett enkelt exempel:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Här angav vi ett namn på aWeekAgo och anger att det ska vara lika med utdata för en tidsintervallfunktion , som returnerar ett datetime-värde . Vi avslutar sedan let-instruktionen med ett semikolon. Nu har vi en ny variabel med namnet aWeekAgo som kan användas var som helst i vår fråga.
Som vi nyss nämnde kan du använda en let-instruktion för att ta en hel fråga och ge resultatet ett namn. Eftersom frågeresultat, som är tabelluttryck, kan användas som indata för frågor, kan du behandla det namngivna resultatet som en tabell i syfte att köra en annan fråga på den. Här är en liten ändring i föregående exempel:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
I det här fallet skapade vi en andra let-instruktion , där vi omsluter hela frågan till en ny variabel med namnet getSignins. Precis som tidigare avslutar vi den andra let-instruktionen med ett semikolon. Sedan anropar vi variabeln på den sista raden, som kör frågan. Observera att vi kunde använda aWeekAgo i den andra let-instruktionen . Det beror på att vi har angett den på föregående rad. Om vi skulle växla let-uttrycken så att getSignins kom först skulle vi få ett fel.
Nu kan vi använda getSignins som grund för en annan fråga (i samma fönster):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Låt instruktioner ge dig mer kraft och flexibilitet när det gäller att organisera dina frågor. Let kan definiera skalär- och tabellvärden samt skapa användardefinierade funktioner. De är verkligen praktiska när du organiserar mer komplexa frågor som kan göra flera kopplingar.
Nästa steg
Även om den här artikeln knappt har skrapat på ytan har du nu den nödvändiga grunden, och vi har gått igenom de delar som du använder oftast för att få ditt arbete gjort i Microsoft Sentinel.
Avancerad KQL för Microsoft Sentinel-arbetsbok
Dra nytta av en Kusto-frågespråk arbetsbok direkt i Själva Microsoft Sentinel – arbetsboken Advanced KQL för Microsoft Sentinel. Det ger dig stegvis hjälp och exempel för många av de situationer som du sannolikt kommer att stöta på under dina dagliga säkerhetsåtgärder, och även pekar på många färdiga, färdiga exempel på analysregler, arbetsböcker, jaktregler och fler element som använder Kusto-frågor. Starta arbetsboken från bladet Arbetsböcker i Microsoft Sentinel.
Avancerad KQL Framework-arbetsbok – Ge dig möjlighet att bli KQL-kunnig är ett utmärkt blogginlägg som visar hur du använder den här arbetsboken.
Fler resurser
Se den här samlingen av utbildnings-, utbildnings- och kunskapsresurser för att bredda och fördjupa dina kunskaper om Kusto-frågespråk.