Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I namnområden har Azure Service Bus stöd för att skapa topologier för länkade köer och ämnesprenumerationer med hjälp av autoforwarding för att möjliggöra implementering av olika routningsmönster. Du kan till exempel ge partner dedikerade köer som de har behörighet att skicka eller ta emot och som tillfälligt kan pausas om det behövs och flexibelt ansluta dem till andra entiteter som är privata för programmet. Du kan också skapa komplexa topologier för routning i flera steg, eller så kan du skapa köer i postlådestil som tömmer köliknande prenumerationer på ämnen och ger mer lagringskapacitet per prenumerant.
Många avancerade lösningar kräver också att meddelanden replikeras över namnområdesgränser för att implementera dessa och andra mönster. Meddelanden kan behöva flöda mellan namnområden som är associerade med flera, olika programklientorganisationer eller mellan flera olika Azure-regioner.
Din lösning underhåller flera Service Bus-namnområden i olika regioner och replikerar meddelanden mellan köer och ämnen, och/eller att du kommer att utbyta meddelanden med källor och mål som Azure Event Hubs, Azure IoT Hub eller Apache Kafka.
De här scenarierna är i fokus för den här artikeln.
Federationsmönster
Det finns många möjliga motiv för varför du kanske vill flytta meddelanden mellan Service Bus-entiteter som köer eller ämnen, eller mellan Service Bus och andra källor och mål.
Jämfört med den liknande uppsättningen mönster för Event Hubs är federation för köliknande entiteter mer komplex eftersom meddelandeköer lovar sina konsumenter exklusivt ägande över ett enskilt meddelande, förväntas bevara ankomstordningen i meddelandeleveransen och för att mäklaren ska samordna rättvis distribution av meddelanden mellan konkurrerande konsumenter.
Det finns praktiska hinder, bland annat begränsningarna i den gemensamma jordbrukspolitikens sats, som gör det svårt att tillhandahålla en enhetlig vy över en kö som samtidigt är tillgänglig i flera regioner och som gör det möjligt för regionalt distribuerade konkurrerande konsumenter att ta exklusivt ägande av meddelanden. En sådan geo-distribuerad kö skulle kräva helt konsekvent replikering, inte bara av meddelanden, utan även leveranstillstånd för varje meddelande innan meddelanden kan göras tillgängliga för konsumenter. Ett mål med fullständig konsekvens för en hypotetisk, regionalt distribuerad kö står i direkt konflikt med det viktiga mål som praktiskt taget alla Azure Service Bus-kunder har när de överväger federationsscenarier: Maximal tillgänglighet och tillförlitlighet för sina lösningar.
Mönstren som presenteras här fokuserar därför på tillgänglighet och tillförlitlighet, samtidigt som syftet är att på bästa sätt undvika både informationsförlust och duplicerad hantering av meddelanden.
Återhämtning mot regionala tillgänglighetshändelser
Även om maximal tillgänglighet och tillförlitlighet är de främsta operativa prioriteringarna för Service Bus, finns det ändå många sätt på vilka en producent eller konsument kan hindras från att prata med sin tilldelade "primära" Service Bus på grund av problem med nätverks- eller namnmatchning, eller där Service Bus-entiteten faktiskt tillfälligt svarar eller returnerar fel. Den avsedda meddelandeprocessorn kan också bli otillgänglig.
Sådana villkor är inte "katastrofala" så att du vill överge den regionala distributionen helt och hållet som du kan göra i en haveriberedskapssituation, men affärsscenariot för vissa program kan redan påverkas av tillgänglighetshändelser som varar i högst några minuter eller till och med sekunder. Azure Service Bus används ofta i hybridmolnmiljöer och med klienter som finns vid nätverksgränsen, till exempel i butiker, restauranger, bankavdelningar, tillverkningsplatser, logistikanläggningar och flygplatser. Det är möjligt att ett problem med nätverksroutning eller överbelastning påverkar en platss möjlighet att nå sin tilldelade Service Bus-slutpunkt medan en sekundär slutpunkt i en annan region kan nås. Samtidigt kan system som bearbetar meddelanden som anländer från dessa platser fortfarande ha obehindrat åtkomst till både de primära och sekundära Service Bus-slutpunkterna.
Det finns många praktiska exempel på sådana hybridmoln- och gränsprogram med låg affärstolerans för påverkan av problem med nätverksroutning eller tillfälliga tillgänglighetsproblem för en Service Bus-entitet. Dessa omfattar bearbetning av betalningar på detaljhandelsplatser, ombordstigning vid flygplatsgrindar och mobiltelefonbeställningar på restauranger, som alla kommer till ett omedelbart och fullständigt stillestånd när den tillförlitliga kommunikationsvägen inte är tillgänglig.
I den här kategorin diskuterar vi tre distinkta distribuerade mönster: "all-active"-replikering, "aktiv-passiv" replikering och "spillover"-replikering.
All-Active replikering
Replikeringsmönstret "helt aktiv" gör att en aktiv replik av samma logiska ämne (eller kö) kan vara tillgänglig i flera namnområden (och regioner) och att alla meddelanden blir tillgängliga i alla repliker, oavsett var de har placerats i kö. Mönstret bevarar vanligtvis ordningen på meddelanden i förhållande till alla utgivare.
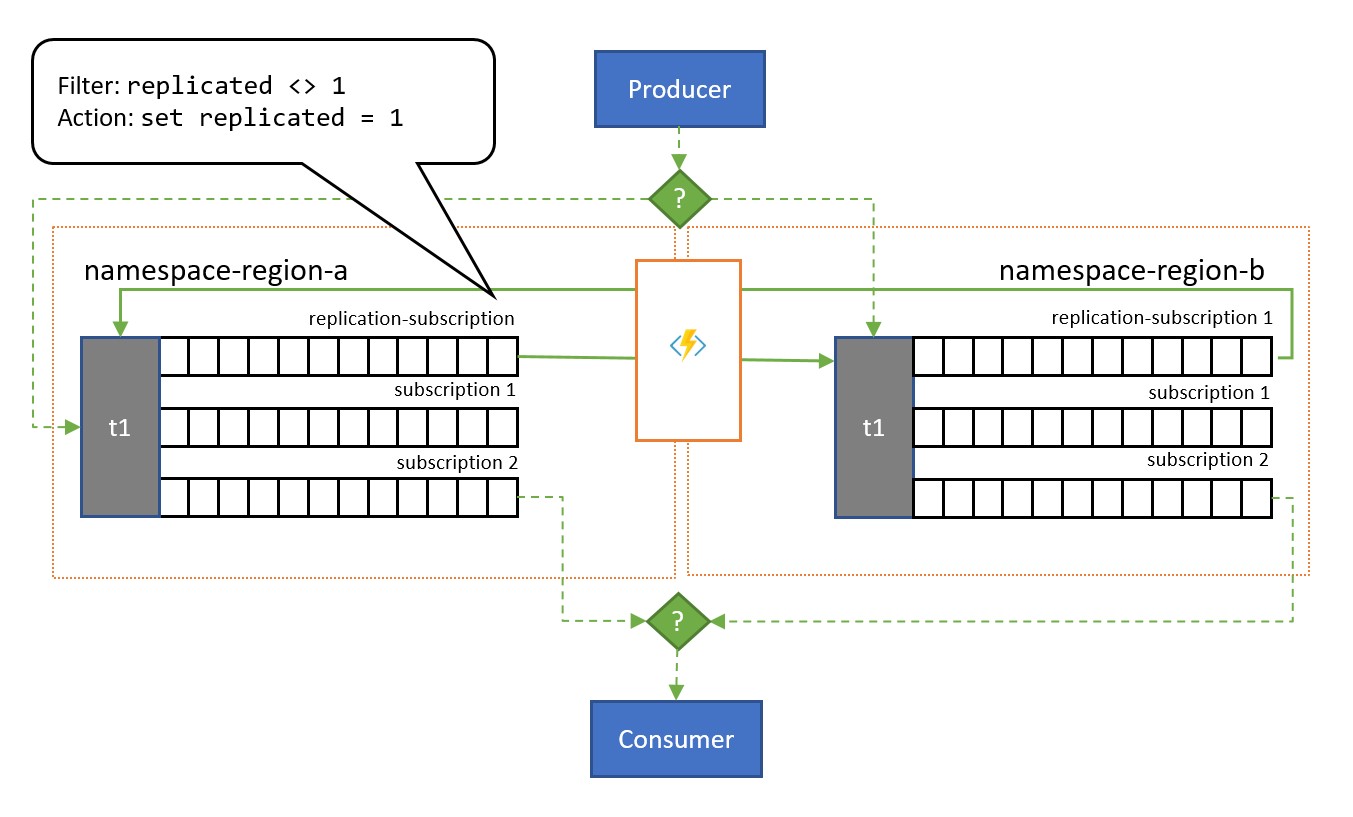
Som du ser i bilden lutar sig mönstret vanligtvis mot Service Bus-ämnen. Ett ämne för varje namnområde som ska delta i replikeringsschemat. Vart och ett av dessa ämnen har en "replikeringsprenumeration" för något av de andra ämnena som meddelanden ska replikeras till. I bilden ovan har vi helt enkelt ett par ämnen och därför en enda replikeringsprenumeration för respektive annat ämne. I ett scenario med tre namnområden {n1, n2, n3}, skulle ett ämne i namnområde n1 ha två replikeringsprenumerationer, en för motsvarande ämne i n2 och en för motsvarande ämne i n3.
Varje replikeringsprenumeration har en regel som kombinerar ett SQL-filteruttryck (replicated <> 1) och en SQL-åtgärd (set replicated = 1). Filtret för regeln säkerställer att endast meddelanden där den anpassade egenskapen replication inte har angetts eller inte har värdet 1 blir berättigade till den här prenumerationen, och åtgärden anger den exakta egenskapen till värdet 1 för varje valt meddelande direkt efteråt. Effekten är att när meddelandet kopieras till motsvarande ämne är det inte längre berättigat till replikering i motsatt riktning och därför undviker vi meddelanden som studsar mellan repliker.
En prenumeration med en respektive regel kan enkelt läggas till i vilket ämne som helst med hjälp av Azure CLI så här.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
För att modellera en kö är varje ämne begränsat till bara en vanlig prenumeration (förutom replikeringsprenumerationerna) som alla konsumenter delar.
Den helt aktiva replikeringsmodellen placerar en kopia av varje meddelande som skickas till något av ämnena i vart och ett av ämnena. Det innebär att programkoden i varje region kommer att se och bearbeta alla meddelanden. Det här mönstret är lämpligt för scenarier där data delas ut i flera regioner eller om redundant bearbetning vanligtvis önskas. Om du bara behöver bearbeta varje meddelande en gång, som med en vanlig kö, måste du överväga något av följande två mönster.
Aktiv-passiv replikering
Replikeringsmönstret "aktiv-passiv" är en variant av det tidigare mönstret där endast ett av ämnena (det "primära") aktivt används av programmet för att skicka och ta emot meddelanden och meddelanden replikeras till ett sekundärt ämne för det fall då det primära ämnet kan bli otillgängligt eller inte kan nås.
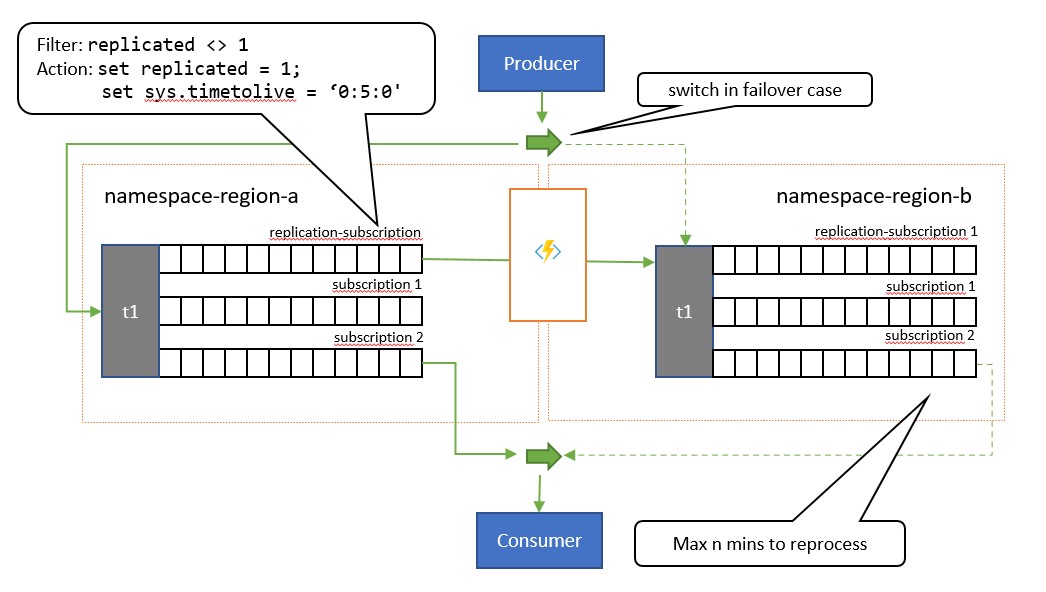
Den största skillnaden mellan det här mönstret och det tidigare mönstret är att replikeringen är enkelriktad från det primära ämnet till det sekundära ämnet. Det sekundära ämnet blir aldrig det primära, men är ett alternativ för säkerhetskopiering när det primära ämnet tillfälligt är oanvändbart.
Fördelen med att använda det här mönstret är att det försöker minimera duplicerad bearbetning. Under replikeringen anges meddelandeegenskapen TimeToLive till en varaktighet för de replikerade meddelandena som återspeglar den förväntade tiden då ett fel i den primära kommer att leda till en redundansväxling. Om ditt användningsfall till exempel kräver en övergång av konsumenten till den sekundära inom högst 1 minut efter hämtningen av meddelanden från den primära starten som visar problem, bör den sekundära helst ha alla tillgängliga meddelanden som du inte kunde komma åt i den primära, men ett minimalt antal meddelanden som du redan hade bearbetat från den primära innan problemen dök upp. Om vi anger till två gånger den TimeToLive perioden, 2 minuter, under replikeringen (set sys.TimeToLive = '0:2:0' i regelåtgärden) behåller den sekundära endast meddelanden i 2 minuter och tar bort äldre meddelanden. Det innebär att när mottagaren växlar över till den sekundära kan den snabbt läsa igenom och ta bort meddelanden som är äldre än den senaste som den bearbetade och sedan bearbeta från det första meddelandet som den ännu inte har sett. Den faktiska kvarhållningstiden beror på det specifika användningsfallet och på hur snabbt du vill och kan växla över till den sekundära i ditt program. Inställningen TimeToLive respekteras i intervallet från några sekunder till dagar.
Även om programmet använder det sekundära kan det också publicera direkt till det sekundära ämnet, som sedan fungerar som vilket vanligt ämne som helst. Efter övergången till den sekundära ser konsumenten därför en blandning av replikerade meddelanden och meddelanden som publiceras direkt till den sekundära. Programmet bör därför först växla tillbaka publiceringen till den primära och ändå tillåta tömning av lokalt publicerade meddelanden innan konsumenten växlas tillbaka till den sekundära. På grund av att replikeringen återupptas automatiskt när den primära är tillgänglig igen, skulle konsumenten också få nya meddelanden publicerade till den primära under den tiden, om än med något högre svarstid.
Det här mönstret är lämpligt för scenarier där meddelanden endast ska bearbetas en gång. Programmet måste samarbeta för att hålla reda på meddelanden som det har bearbetat från den primära eftersom det hittar dubbletter under redundansfönstrets varaktighet i det sekundära, och det kommer återigen att hitta dubbletter när du byter tillbaka. Kriteriet för deduplicering bör bäst vara ett program som tillhandahålls
MessageId. VärdetEnqueuedTimeUtcär också lämpligt som en vattenstämpelindikator, men programmet måste tillåta en viss mängd klockdrift (flera sekunder) mellan primär och sekundär som med alla distribuerade system.
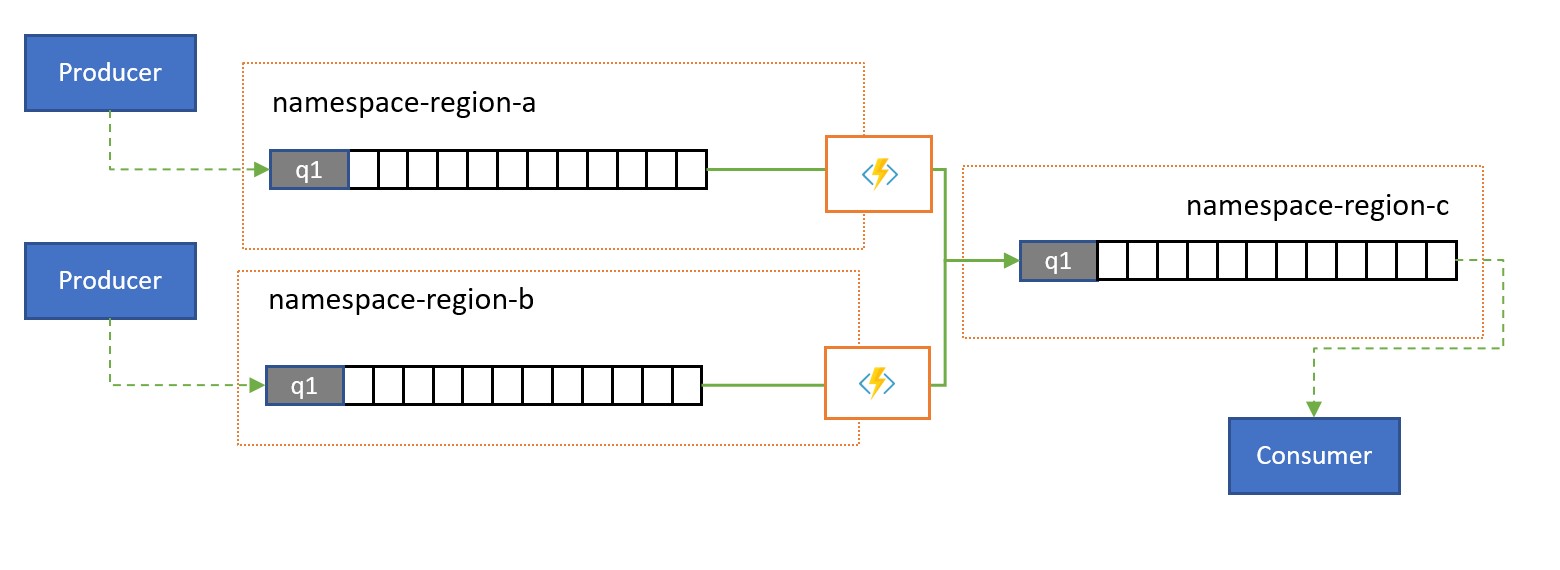
Spillover-replikering
Replikeringsmönstret "spillover" tillåter aktiv/aktiv användning av flera Service Bus-entiteter i flera regioner för att hantera scenariot där Service Bus är felfritt, men konsumenten blir överväldigad av antalet väntande meddelanden eller är helt otillgänglig. En orsak till det kan vara att en databas som stöder konsumentprocessen kan vara långsam eller otillgänglig. Det här mönstret fungerar med vanliga köer och med ämnesprenumerationer.
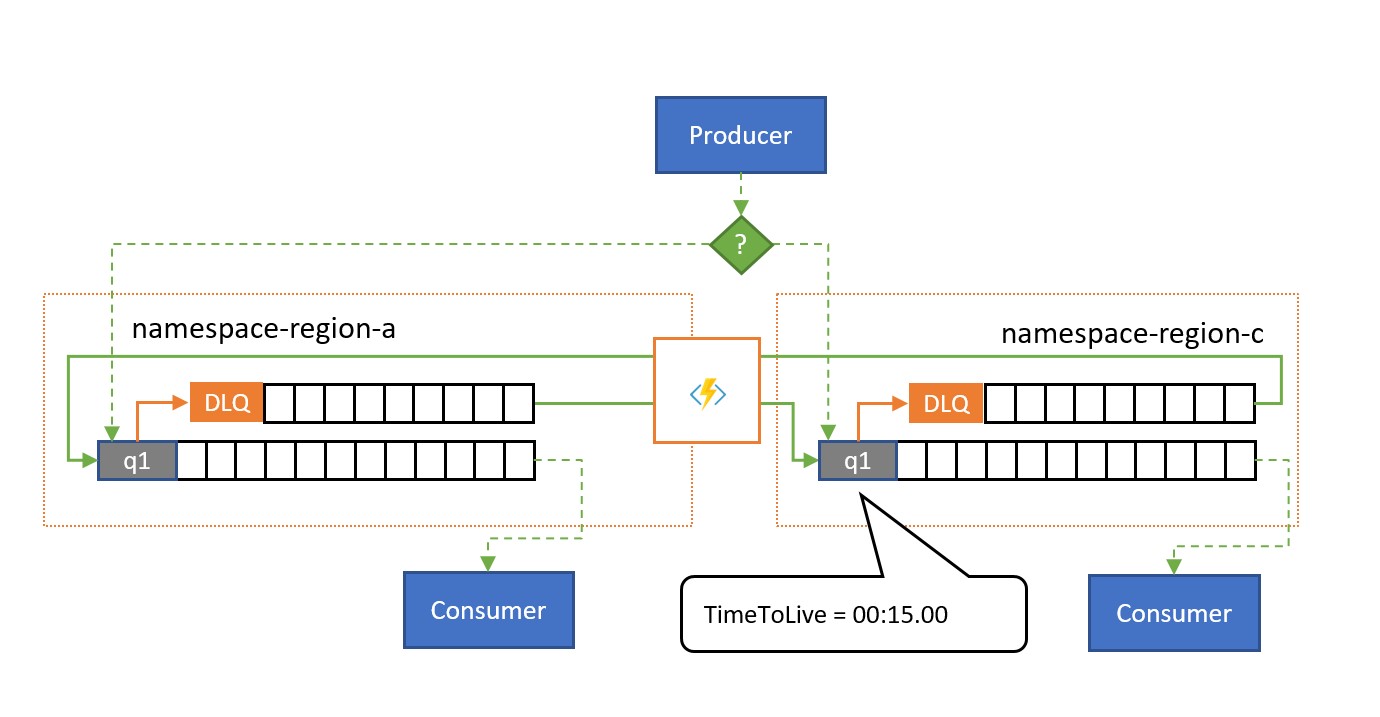
Som du ser i bilden replikerar spillover-replikeringsmönstret meddelanden från en kös eller prenumerations associerade kö med obeställbara bokstäver till en länkad kö eller ett ämne i ett annat namnområde.
Utan att det uppstår ett fel används de två namnrymderna parallellt, var och en tar emot en delmängd av den övergripande meddelandetrafiken och deras associerade konsumenter som hanterar den delmängden. När en av konsumenterna börjar uppvisa höga felfrekvenser eller stoppas direkt hamnar respektive meddelanden i kön med obeställbara meddelanden antingen genom att överskrida leveransantalet eller eftersom det upphör att gälla. Replikeringsuppgifterna hämtar dem sedan och skickar dem på nytt i den parkopplade kön, där de sedan presenteras för den förmodligen felfria konsumenten.
Om bearbetningen måste ske inom en viss tidsgräns TimeToLive bör för kön och/eller meddelanden anges så att bearbetningen fortfarande kan ske i tid av spillover-sekundären, till exempel TimeToLive kan vara inställd på hälften av den tillåtna tiden.
Precis som med det helt aktiva mönstret kan programmet lägga till en indikator i meddelandet om meddelandet redan har replikerats en gång så att de inte studsar mellan köparet, utan snarare publiceras i en extra kö som fungerar som kö med obeställbara bokstäver för det sammansatta mönstret.
Det här mönstret är lämpligt för scenarier där det främsta problemet är att skydda mot tillgänglighetsproblem hos konsumenter eller resurser som konsumenterna förlitar sig på, och även för att omdistribuera trafiktoppar i en av de kopplade köerna. Det ger också skydd mot att ett av namnrymderna blir otillgängligt om konsumenter läser från båda köerna, men replikeringsfördröjningen
TimeToLivesom infördes vid förfallodatumet kan leda till att meddelanden inom den tidsperioden strandar i det otillgängliga namnområdet.
Optimering av svarstid
Ämnen används för att distribuera information till flera konsumenter. I vissa fall, särskilt konsumenter med bred geografisk fördelning, kan det vara fördelaktigt att replikera meddelanden från ett ämne till ett ämne i ett sekundärt namnområde närmare konsumenterna.

När du till exempel delar data mellan regionala, kontinentala hubbar är det mer effektivt att bara överföra information en gång mellan hubbar och låta konsumenterna få sin kopia av data från dessa hubbar.
Replikeringsöverföringar kan göras i batchar, som konsumenter ofta får och kvittar meddelanden en efter en. Med en basnätverksfördröjning på 100 ms mellan till exempel Nordamerika och Europa tar varje meddelande 200 ms längre tid att bearbeta för de två tur- och returresorna till en fjärrentitet för att hämta och lösa meddelandena, jämfört med en entitet i samma region.
Validering, minskning och berikning
Meddelanden kan skickas till en Service Bus-kö eller ett ämne av klienter utanför din egen lösning.

Sådana meddelanden kan kräva kontroll av kompatibilitet med ett visst schema och för att icke-kompatibla meddelanden ska tas bort eller vara obeställbara. Vissa meddelanden kan behöva minskas i komplexitet genom att utelämna data och vissa kan behöva berikas genom att lägga till data baserat på referensdatasökningar. Åtgärderna kan utföras med anpassade funktioner i replikeringsaktiviteten.
Strömma till köreplikering
Azure Event Hubs är en idealisk lösning för hantering av extrema volymer av inkommande händelser. Men varken Event Hubs eller liknande motorer som Apache Kafka tillhandahåller en tjänsthanterad konkurrerande konsumentmodell där flera konsumenter kan hantera meddelanden från samma källa samtidigt utan att riskera duplicerad bearbetning och slutligen lösa dessa meddelanden när de har bearbetats.
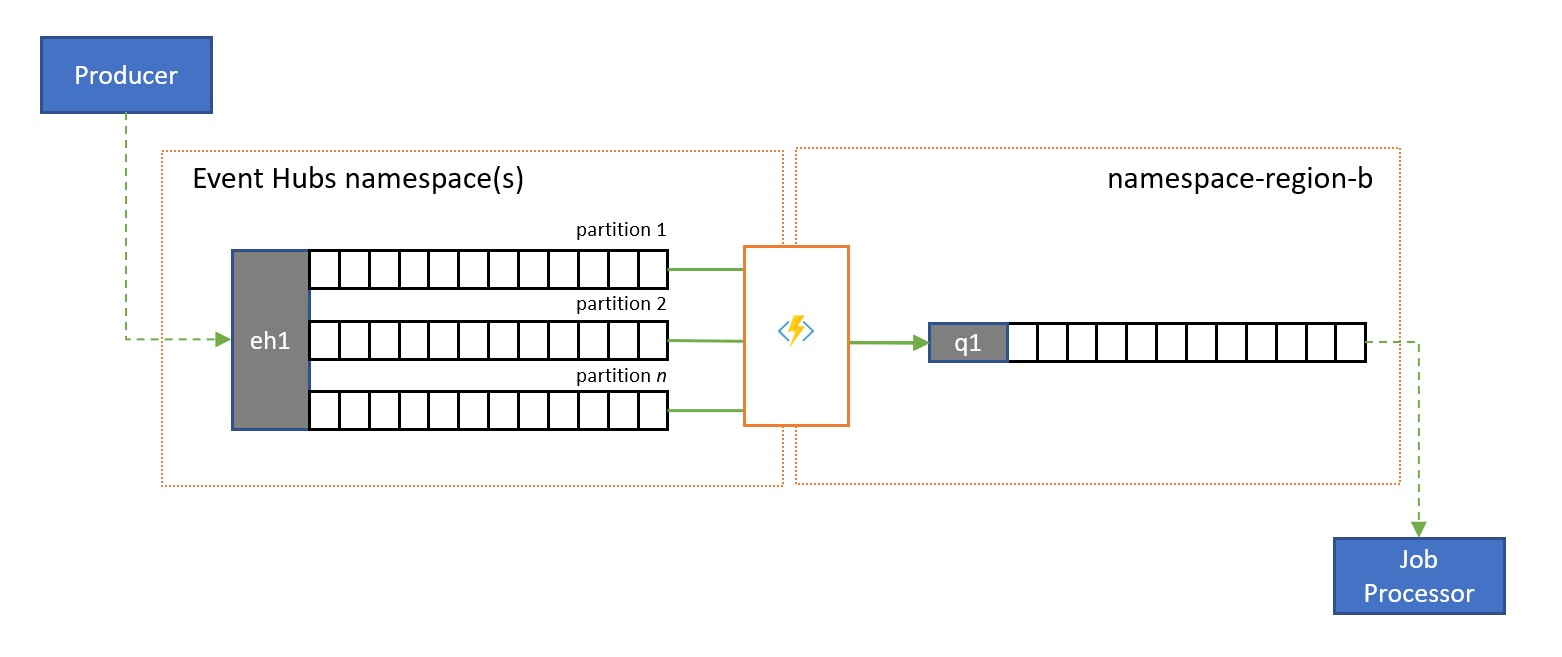
En dataström till köreplikering överför innehållet i en enda händelsehubbpartition eller innehållet i en fullständig händelsehubb till en Service Bus-kö, varifrån meddelandena kan bearbetas på ett säkert sätt, transaktionsmässigt och med konkurrerande konsumenter. Den här replikeringen gör det också möjligt att använda alla andra Service Bus-funktioner för dessa meddelanden, inklusive routning med ämnen och sessionsbaserad demultiplexing.
Konsolidering och normalisering
Globala lösningar består ofta av regionala fotavtryck som till stor del är oberoende, inklusive att ha egna bearbetningsfunktioner, men överstatliga och globala perspektiv kräver dataintegrering och därför en central konsolidering av samma meddelandedata som utvärderas i respektive regional fotavtryck för det lokala perspektivet.
Normalisering är en smak av konsolideringsscenariot, där två eller flera inkommande sekvenser av meddelanden har samma typ av information, men med olika strukturer eller olika kodningar, och meddelandena måste omkodas eller transformeras innan de kan användas.
Normalisering kan också omfatta kryptografiskt arbete som att dekryptera krypterade nyttolaster från slutpunkt till slutpunkt och omkryptera den med olika nycklar och algoritmer för den nedströmskonsumenten.
Delning och routning
Service Bus-ämnen och deras prenumerationsregler används ofta för att filtrera en ström av meddelanden för en viss målgrupp och den målgruppen fick sedan den filtrerade uppsättningen från en prenumeration.
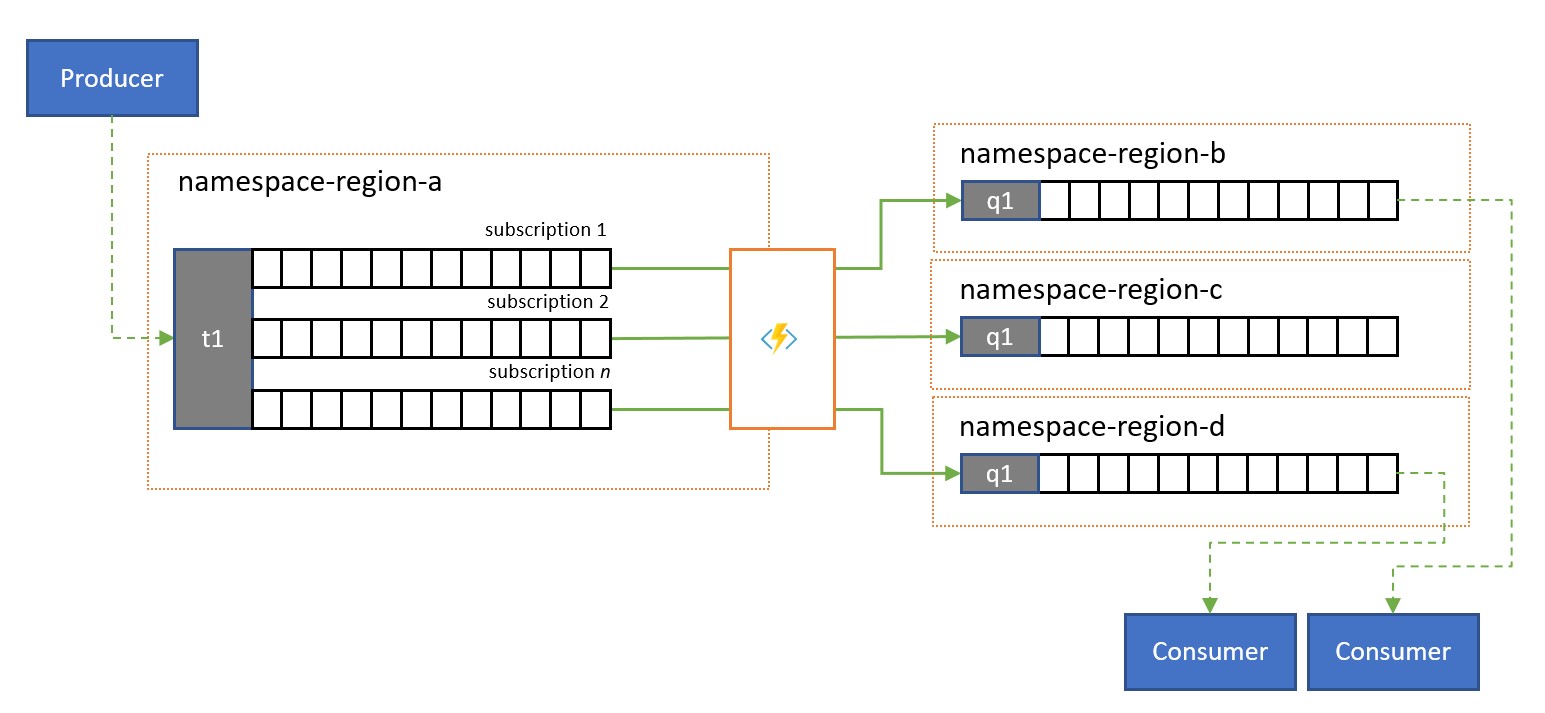
I ett globalt system där målgruppen för dessa meddelanden distribueras globalt eller tillhör olika program kan replikering användas för att överföra meddelanden från en sådan prenumeration till en kö eller ett ämne i ett annat namnområde än där de används.
Replikeringsprogram i Azure Functions
För att implementera mönstren ovan krävs en skalbar och tillförlitlig körningsmiljö för de replikeringsuppgifter som du vill konfigurera och köra. I Azure är den körningsmiljö som passar bäst för tillståndslösa uppgifter Azure Functions.
Azure Functions kan köras under en Hanterad Azure-identitet så att replikeringsuppgifterna kan integreras med de rollbaserade åtkomstkontrollreglerna för käll- och måltjänsterna utan att du behöver hantera hemligheter längs replikeringsvägen. För replikeringskällor och mål som kräver explicita autentiseringsuppgifter kan Azure Functions lagra konfigurationsvärdena för dessa autentiseringsuppgifter i strikt åtkomstkontrollerad lagring i Azure Key Vault.
Med Azure Functions kan replikeringsuppgifterna dessutom integreras direkt med virtuella Azure-nätverk och tjänstslutpunkter för alla Azure-meddelandetjänster, och de är enkelt integrerade med Azure Monitor.
Viktigast av allt är att Azure Functions har fördefinierade, skalbara utlösare och utdatabindningar för Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid och Azure Queue Storage, anpassade tillägg för RabbitMQ och Apache Kafka. De flesta utlösare anpassas dynamiskt efter dataflödesbehoven genom att skala upp och ned antalet instanser som körs samtidigt baserat på dokumenterade mått.
Med förbrukningsplanen för Azure Functions kan de fördefinierade utlösarna till och med skalas ned till noll medan inga meddelanden är tillgängliga för replikering, vilket innebär att du inte medför några kostnader för att hålla konfigurationen redo att skalas upp igen. Den viktigaste nackdelen med att använda förbrukningsplanen är att svarstiden för replikeringsuppgifter "vaknar upp" från det här tillståndet är betydligt högre än med de värdplaner där infrastrukturen hålls igång.
Till skillnad från allt detta kräver de vanligaste replikeringsmotorerna för meddelanden och händelser, till exempel Apache Kafkas MirrorMaker, att du tillhandahåller en värdmiljö och skalar replikeringsmotorn själv. Det omfattar att konfigurera och integrera säkerhets- och nätverksfunktioner och underlätta flödet av övervakningsdata, och sedan har du fortfarande inte möjlighet att mata in anpassade replikeringsuppgifter i flödet.
Replikeringsuppgifter med Azure Logic Apps
Ett icke-kodningsalternativ för replikering med hjälp av Functions är att använda Logic Apps i stället. Logic Apps har fördefinierade replikeringsuppgifter för Service Bus. Dessa kan hjälpa dig med att konfigurera replikering mellan olika instanser och kan justeras för ytterligare anpassning.
Nästa steg
I den här artikeln utforskade vi en rad federationsmönster och förklarade rollen för Azure Functions som händelse- och meddelandereplikeringskörning i Azure.
Därefter kanske du vill läsa om hur du konfigurerar ett replikatorprogram med Azure Functions och sedan hur du replikerar händelseflöden mellan Event Hubs och olika andra händelse- och meddelandesystem: