Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller riktlinjer för bästa praxis som hjälper dig att använda åtkomstnivåer för att optimera prestanda och minska kostnaderna. Mer information om åtkomstnivåer finns i Åtkomstnivåer för blobdata.
Välj de mest kostnadseffektiva åtkomstnivåerna
Du kan minska kostnaderna genom att placera blobdata på de mest kostnadseffektiva åtkomstnivåerna. Välj mellan tre nivåer som är utformade för att optimera dina kostnader kring dataanvändning. Den heta nivån har till exempel en högre lagringskostnad men lägre läskostnad. Om du planerar att komma åt data ofta kan den heta nivån därför vara det mest kostnadseffektiva valet. Om du läser data mindre ofta kan nivån lågfrekvent, kall eller arkivnivå vara bäst eftersom den sänker lagringskostnaderna men ökar läskostnaderna.
För att hitta den mest optimala åtkomstnivån beräknar du vilken procentandel av data som läss varje månad. I följande diagram visas hur månadsutgifterna påverkas med olika läsprocent.
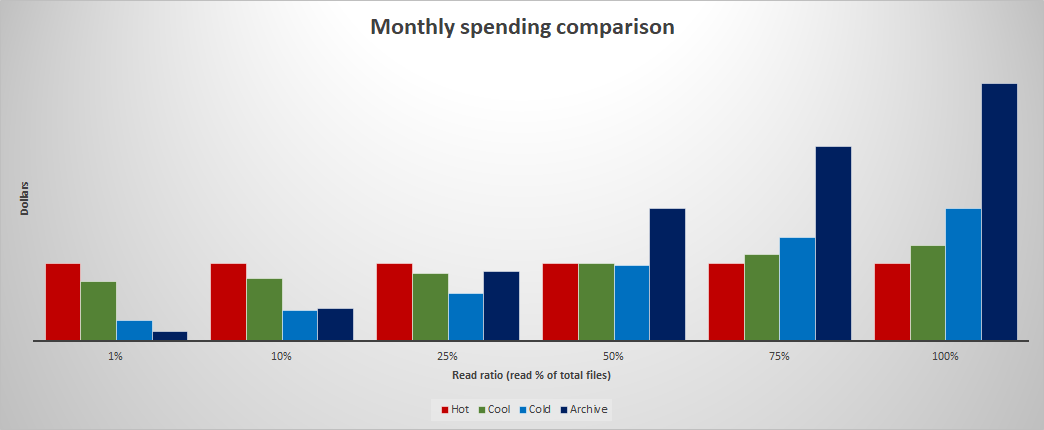
Information om hur du modellerar och analyserar kostnaden för att använda lågfrekvent eller kall lagring jämfört med arkivlagring finns i Arkiv kontra kallt och kallt. Du kan använda liknande modelleringstekniker för att jämföra kostnaden för het, sval, kall eller arkivering.
Använda smart nivå för att optimera kostnaderna automatiskt
Om du inte känner till den mest optimala åtkomstnivån för varje objekt eller inte vill hantera placeringen av dessa objekt kan smart nivå vara ett bra alternativ att välja. Automatisk nednivåindelning av inaktiva data kan leda till stora kostnadsbesparingar över tid. Genom att ta ut en liten övervakningsavgift tillhandahåller den ytterligare förenkling av faktureringsmodellen genom att inte ta betalt för nivåövergångar, tidiga borttagningar eller kapacitetsåteruppbyggning. Mer information finns i Optimera kostnader med smart nivå .
Migrera data direkt till de mest kostnadseffektiva åtkomstnivåerna
Om du väljer den mest optimala nivån i förväg kan du minska kostnaderna. Om du ändrar nivån för en blockblob som du laddar upp betalar du för att skriva till den första nivån när du laddar upp den och betalar sedan för att skriva till den nya nivån. Om du ändrar nivåer med hjälp av en livscykelhanteringsprincip, tar det en dag för principen att träda i kraft och en dag att genomföra. Du betalar också kapacitetskostnaden för att lagra data på den första nivån innan nivån ändras.
Vägledning om hur du laddar upp till en specifik åtkomstnivå finns i Ange åtkomstnivån för en blob.
Information om dataflytt offline till önskad nivå finns i Azure Data Box.
Flytta data till de mest kostnadseffektiva åtkomstnivåerna
När data har laddats upp bör du regelbundet analysera dina containrar och blobar för att förstå hur de lagras, organiseras och används i produktion. Använd sedan livscykelhanteringsprinciper för att flytta data till de mest kostnadseffektiva nivåerna. Till exempel kan data som inte nås på mer än 30 dagar vara mer kostnadseffektiva om de placeras på lågfrekvent nivå. Överväg att arkivera data som inte har använts på över 180 dagar.
Om du vill samla in telemetri aktiverar du blobinventeringsrapporter och aktiverar spårning av senaste åtkomsttid. Analysera användningsmönster baserat på den senaste åtkomsttiden med hjälp av verktyg som Azure Synapse eller Azure Databricks. Mer information om hur du analyserar dina data finns i någon av följande artiklar:
Beräkna antalet blobar och total storlek per container med hjälp Azure Storage-inventering
Så här beräknar du statistik på containernivå i Azure Blob Storage med Azure Databricks
Nivåindelning och sidblobbar
Din analys kan visa tilläggs- eller sidblobar som inte används aktivt. Du kan till exempel ha loggfiler (tilläggsblobar) som inte längre läss eller skrivs till, men du vill lagra dem av efterlevnadsskäl. På samma sätt kanske du vill säkerhetskopiera diskar eller ögonblicksbilder av diskar (sidblobar). Du kan också flytta dessa blobar till svalare nivåer. Du måste dock först konvertera dem till blockblobar.
Information om hur du konverterar tilläggs- och sidblobbar till blockblobar finns i Konvertera tilläggsblobar och sidblobar till blockblobar.
Packa små filer innan du flyttar data till kallare nivåer
Varje läs- eller skrivåtgärd medför en kostnad. Om du vill minska kostnaden för att läsa och skriva data kan du överväga att packa små filer i större filer med hjälp av filformat som TAR eller ZIP. Färre filer minskar antalet åtgärder som krävs för att överföra data.
Följande diagram visar den relativa effekten av att packa filer för cool-nivån. Läskostnaden förutsätter en månatlig läsprocent på 30%.
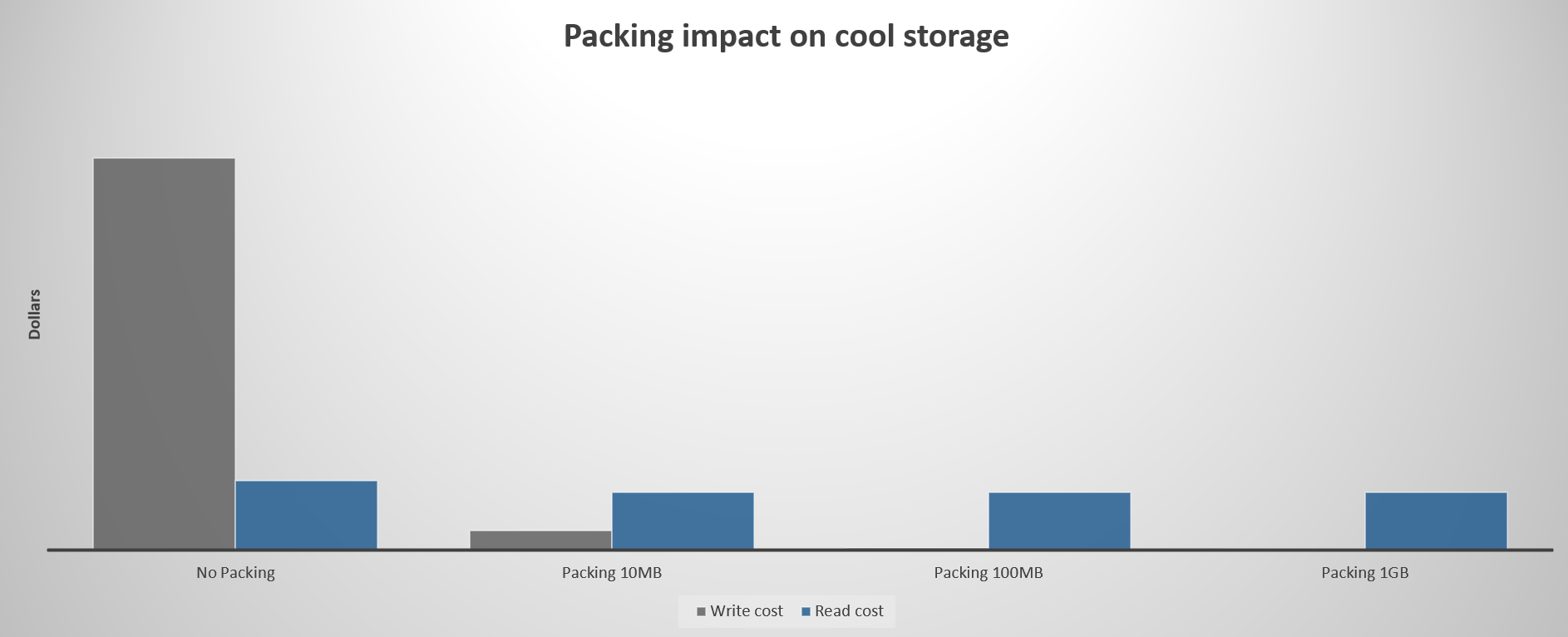
Följande diagram visar den relativa effekten av att packa filer för arkivnivån. Läskostnaden förutsätter en månatlig läsprocent på 30%.

Information om hur du modellerar och analyserar kostnadsbesparingar för paketeringsfiler finns på fliken Spara packning i den här arbetsboken.
Tips/Råd
För att underlätta sök- och lässcenarier bör du överväga att skapa ett index som mappar paketerade filsökvägar med ursprungliga filsökvägar och sedan lagra dessa index som blockblobar på den frekventa nivån.