Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Genom att förstå hur dina blobar och containrar lagras, organiseras och används i produktion kan du bättre optimera kompromisserna mellan kostnad och prestanda.
Den här självstudien visar hur du genererar och visualiserar statistik som datatillväxt över tid, data som läggs till över tid, antal filer som ändras, storlekar på ögonblicksbilder av blobar, åtkomstmönster över varje nivå och hur data distribueras både för närvarande och över tid (till exempel data över nivåer, filtyper, i containrar och blobtyper).
I den här tutorialen lär du dig följande:
- Generera en blobinventeringsrapport
- Konfigurera en Synapse-arbetsyta
- Konfigurera Synapse Studio
- Generera analysdata i Synapse Studio
- Visualisera resultat i Power BI
Prerequisites
En Azure-prenumeration – skapa ett konto kostnadsfritt
Ett Azure Storage-konto – skapa ett lagringskonto
Se till att din användaridentitet har rollen Storage Blob Data Contributor tilldelad.
Generera en inventeringsrapport
Aktivera blobinventeringsrapporter för ditt lagringskonto. Se Aktivera Azure Storage-blob-lagerredovisningsrapporter.
Du kan behöva vänta upp till 24 timmar efter att du har aktiverat inventeringsrapporter för att din första rapport ska genereras.
Konfigurera en Synapse-arbetsyta
Skapa en Azure Synapse-arbetsyta. Se Skapa en Azure Synapse-arbetsyta.
Note
Som en del av skapandet av arbetsytan skapar du ett lagringskonto som har en hierarkisk namnrymd. Azure Synapse lagrar Spark-tabeller och programloggar på det här kontot. Azure Synapse refererar till det här kontot som det primära lagringskontot. För att undvika förvirring använder den här artikeln termen inventeringsrapportkonto för att referera till kontot som innehåller inventeringsrapporter.
På Synapse-arbetsytan tilldelar du rollen Deltagare till din användaridentitet. Se Azure RBAC: Ägarroll för arbetsytan.
Ge Synapse-arbetsytan behörighet att komma åt inventeringsrapporterna i ditt lagringskonto genom att navigera till ditt inventeringsrapportkonto och sedan tilldela rollen Storage Blob Data Contributor till arbetsytans systemhanterade identitet. Se Tilldela Azure-roller med hjälp av Azure-portalen.
Navigera till det primära lagringskontot och tilldela rollen Blob Storage-deltagare till din användaridentitet.
Konfigurera Synapse Studio
Öppna Synapse-arbetsytan i Synapse Studio. Se Öppna Synapse Studio.
I Synapse Studio kontrollerar du att din identitet har tilldelats rollen Synapse-administratör. Se Synapse RBAC: Synapse Administrator-rollen för arbetsyte.
Skapa en Apache Spark-pool. Se Skapa en serverlös Apache Spark-pool.
Konfigurera och köra exempelanteckningsboken
I det här avsnittet genererar du statistiska data som du visualiserar i en rapport. För att förenkla den här självstudien använder det här avsnittet en exempelkonfigurationsfil och en PySpark-exempelanteckningsbok. Notebook-filen innehåller en samling frågor som körs i Azure Synapse Studio.
Ändra och ladda upp exempelkonfigurationsfilen
Ladda ned BlobInventoryStorageAccountConfiguration.json-filen.
Uppdatera följande platshållare för filen:
Ange
storageAccountNamenamnet på ditt lagerrapportkonto.Ange
destinationContainernamnet på containern som innehåller inventeringsrapporterna.Ange
blobInventoryRuleNamenamnet på den inventeringsrapportregel som har genererat de resultat som du vill analysera.Ange
accessKeytill kontonyckeln för inventeringsrapportkontot.
Ladda upp den här filen till containern i ditt primära lagringskonto som du angav när du skapade Synapse-arbetsytan.
Importera PySpark-exempelanteckningsboken
Ladda ned exempelanteckningsboken ReportAnalysis.ipynb .
Note
Spara filen med
.ipynbtillägget.Öppna Synapse-arbetsytan i Synapse Studio. Se Öppna Synapse Studio.
I Synapse Studio väljer du fliken Utveckla .
Välj plustecknet (+) för att lägga till ett objekt.
Välj Importera, bläddra till exempelfilen som du laddade ned, välj den filen och välj Öppna.
Dialogrutan Egenskaper visas.
I dialogrutan Egenskaper väljer du länken Konfigurera session .
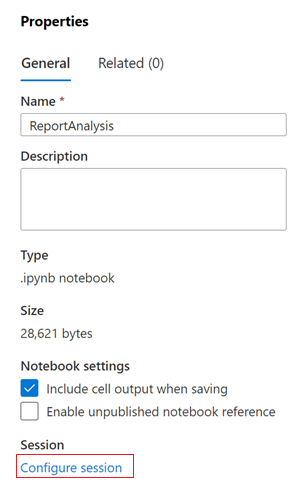
Dialogrutan Konfigurera session öppnas.
I listrutan Anslut till i dialogrutan Konfigurera session väljer du den Spark-pool som du skapade tidigare i den här artikeln. Välj sedan knappen Använd .
Ändra Python-anteckningsboken
I den första cellen i Python-notebook-filen anger du värdet för variabeln
storage_accounttill namnet på det primära lagringskontot.Uppdatera värdet för variabeln
container_nametill namnet på containern i det konto som du angav när du skapade Synapse-arbetsytan.Välj knappen Publicera.
Kör PySpark-anteckningsboken
I Anteckningsboken PySpark väljer du Kör alla.
Det tar några minuter att starta Spark-sessionen och ytterligare några minuter att bearbeta inventeringsrapporterna. Den första körningen kan ta en stund om det finns många inventeringsrapporter att bearbeta. Efterföljande körningar bearbetar endast de nya inventeringsrapporter som skapats sedan den senaste körningen.
Note
Om du gör några ändringar i anteckningsboken medan den körs, se till att publicera ändringarna med hjälp av knappen Publicera.
Kontrollera att anteckningsboken kördes framgångsrikt genom att välja fliken Data.
En databas med namnet reportdata ska visas på fliken Arbetsyta i fönstret Data . Om den här databasen inte visas kan du behöva uppdatera webbsidan.
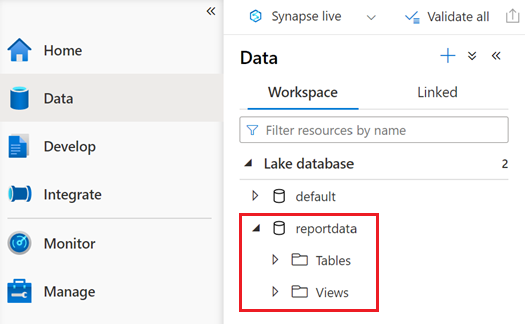
Databasen innehåller en uppsättning tabeller. Varje tabell innehåller information som hämtas genom att köra frågorna från PySpark-anteckningsboken.
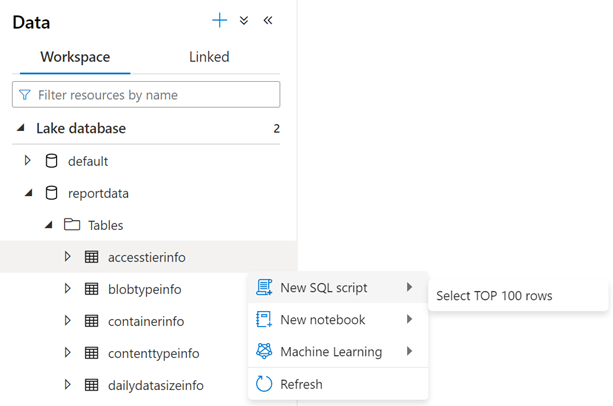
Om du vill undersöka innehållet i en tabell expanderar du mappen Tabeller i databasen reportdata . Högerklicka sedan på en tabell, välj Välj SQL-skript och välj sedan Välj de 100 översta raderna.
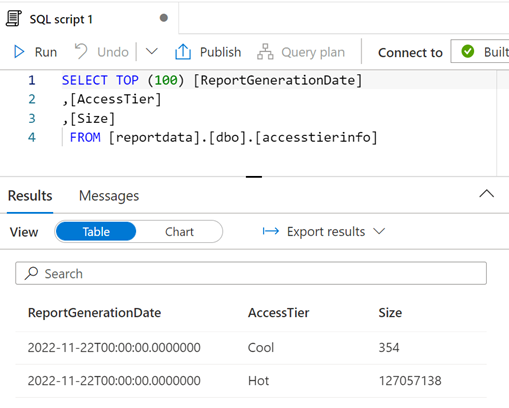
Du kan ändra frågan efter behov och sedan välja Kör för att visa resultatet.
Visualisera datan
Ladda ned exempelrapportfilen ReportAnalysis.pbit .
Öppna Power BI Desktop. Installationsvägledning finns i Hämta Power BI Desktop.
I Power BI väljer du Arkiv, Öppna rapport och sedan Bläddra bland rapporter.
I dialogrutan Öppna ändrar du filtypen till Power BI-mallfiler (*.pbit).

Bläddra till platsen för filen ReportAnalysis.pbit som du laddade ned och välj sedan Öppna.
En dialogruta visas där du uppmanas att ange namnet på Synapse-arbetsytan och databasnamnet.
I dialogrutan anger du fältet synapse_workspace_name till arbetsytans namn och anger fältet database_name till
reportdata. Välj sedan knappen Läs in .
En rapport visas, vilken innehåller visualiseringar av de data som hämtas av notebook. Följande bilder visar de typer av diagram och grafer som visas i den här rapporten.
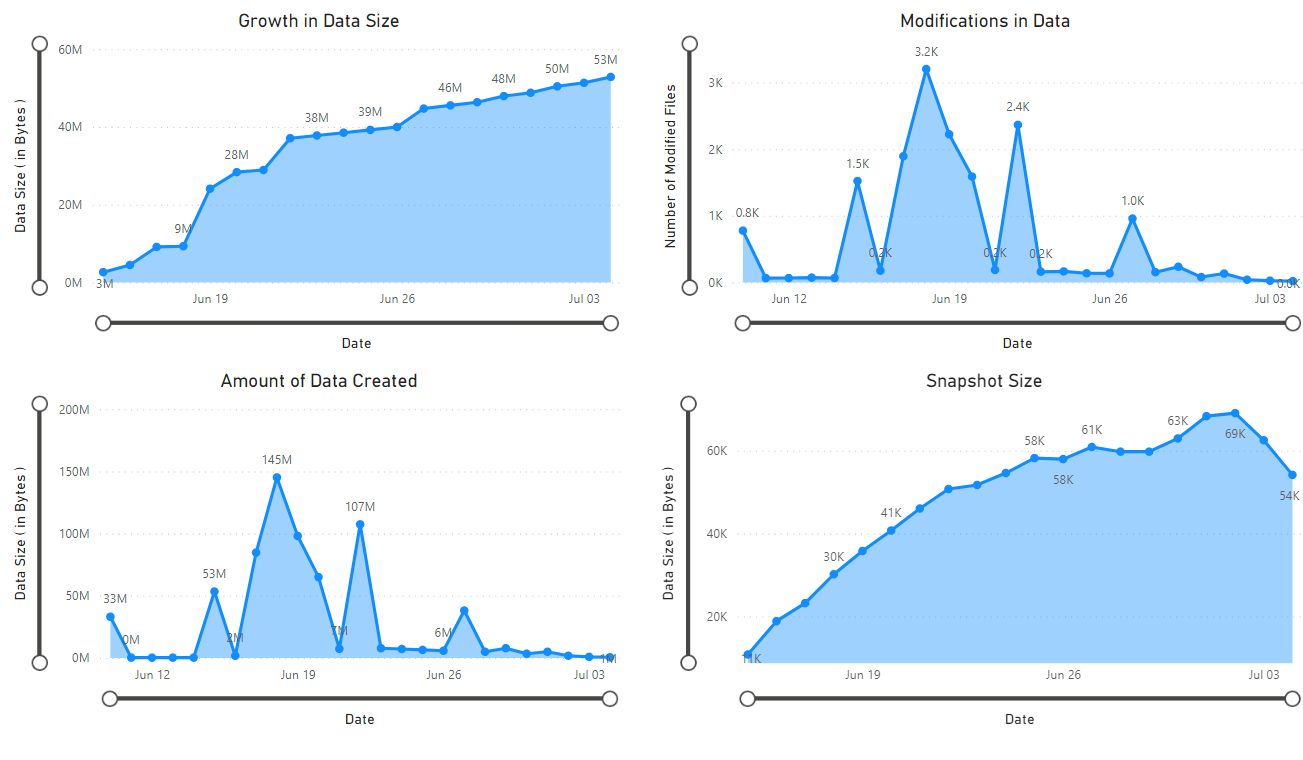
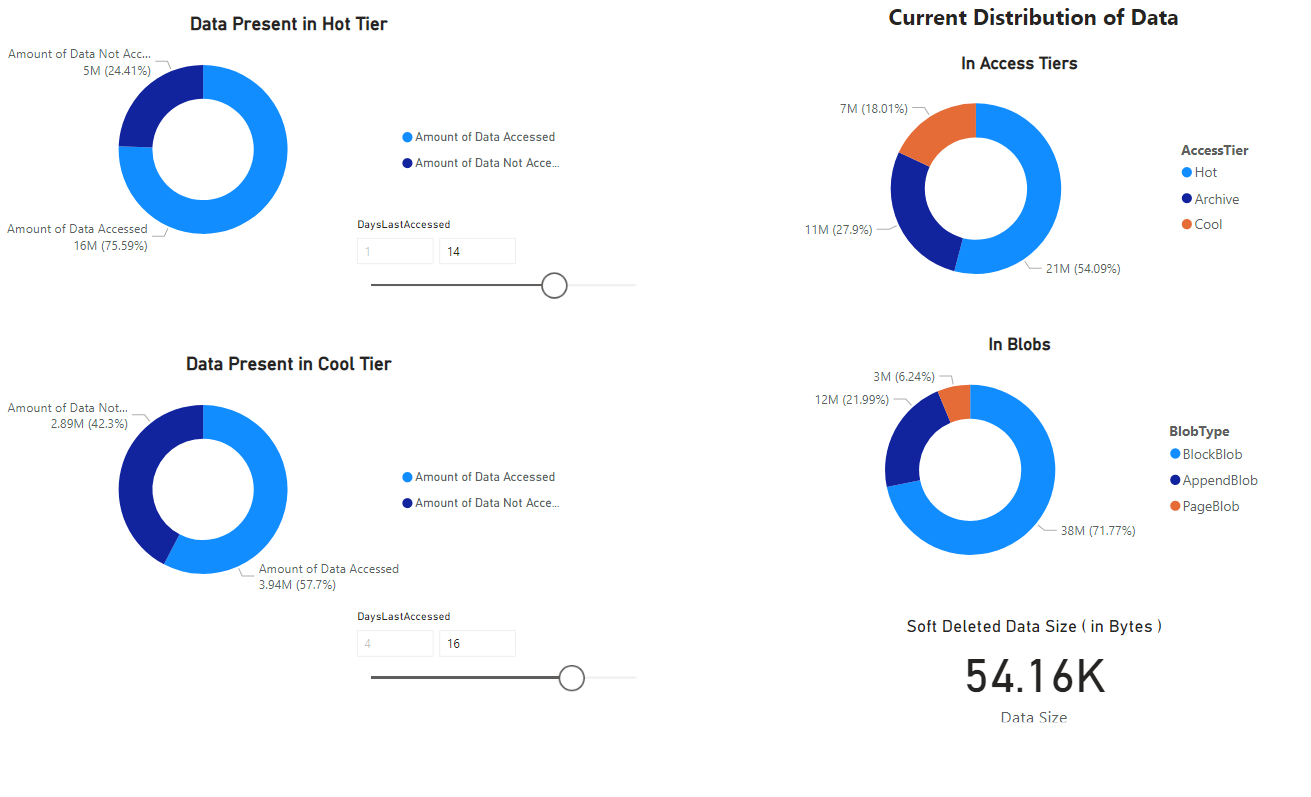
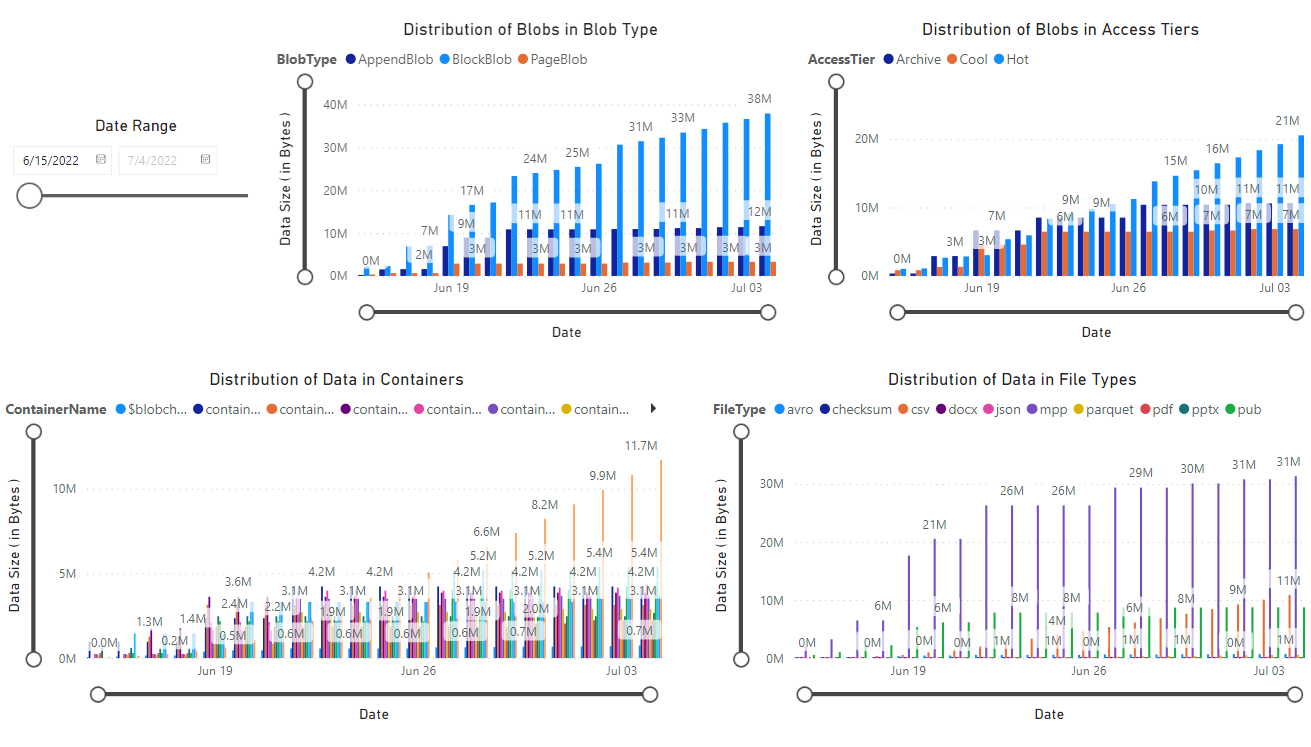
Nästa steg
Konfigurera en Azure Synapse-pipeline för att köra notebooken på regelbundna intervaller. På så sätt kan du bearbeta nya inventeringsrapporter när de skapas. Efter den första körningen analyserar var och en av nästa körningar inkrementella data och uppdaterar sedan tabellerna med resultatet av den analysen. Vägledning finns i Integrera med pipelines.
Lär dig mer om olika sätt att analysera enskilda containrar i ditt lagringskonto. Se följande artiklar:
Beräkna antalet blobar och total storlek per container med hjälp Azure Storage-inventering
Lär dig mer om hur du optimerar dina kostnader baserat på analysen av dina blobar och containrar. Se följande artiklar:
Planera och hantera kostnader för Azure Blob Storage
Beräkna kostnaden för arkivering av data
Optimera kostnaderna genom att automatiskt hantera datalivscykeln