Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver hur du kan förbättra prestanda för NFS (Network File System) Azure filresurser.
Gäller för
| Hanteringsmodell | Faktureringsmodell | Medieklass | Redundans | Små och medelstora företag (SMB) | NFS (Network File System) |
|---|---|---|---|---|---|
| Microsoft.Storage, lagringstjänster | Provisionerad v2 | SSD (hög kvalitet) | Lokalt (LRS) |
|
|
| Microsoft.Storage, lagringstjänster | Provisionerad v2 | SSD (hög kvalitet) | Zon (ZRS) |
|
|
| Microsoft.Storage, lagringstjänster | Provisionerad v2 | HDD (standard) | Lokalt (LRS) |
|
|
| Microsoft.Storage, lagringstjänster | Provisionerad v2 | HDD (standard) | Zon (ZRS) |
|
|
| Microsoft.Storage, lagringstjänster | Provisionerad v2 | HDD (standard) | Geo (GRS) |
|
|
| Microsoft.Storage, lagringstjänster | Provisionerad v2 | HDD (standard) | GeoZone (GZRS) |
|
|
| Microsoft.Storage, lagringstjänster | Tillhandahållen v1 | SSD (hög kvalitet) | Lokalt (LRS) |
|
|
| Microsoft.Storage, lagringstjänster | Tillhandahållen v1 | SSD (hög kvalitet) | Zon (ZRS) |
|
|
| Microsoft.Storage, lagringstjänster | Betala efter hand | HDD (standard) | Lokalt (LRS) |
|
|
| Microsoft.Storage, lagringstjänster | Betala efter hand | HDD (standard) | Zon (ZRS) |
|
|
| Microsoft.Storage, lagringstjänster | Betala efter hand | HDD (standard) | Geo (GRS) |
|
|
| Microsoft.Storage, lagringstjänster | Betala efter hand | HDD (standard) | GeoZone (GZRS) |
|
|
Öka förladdningsstorleken för att förbättra läsgenomströmningen
Kernelparametern read_ahead_kb i Linux anger mängden data som ska förladdas under en sekventiell läsåtgärd. Linux-kernelversioner före 5.4 anger läs-före-värdet till motsvarande 15 gånger det monterade filsystemets rsize, vilket representerar monteringsalternativet på klientsidan för läsbuffertstorlek. Detta ställer in läs-framåt-värdet tillräckligt högt för att förbättra klientens sekventiella läsdataflöde i de flesta fall.
Från och med Linux-kernel version 5.4 använder Linux NFS-klienten dock ett standardvärde read_ahead_kb på 128 KiB. Det här lilla värdet kan minska mängden läsdataflöde för stora filer. Kunder som uppgraderar från Linux-versioner med det större läs-före-värdet till versioner med standardvärdet 128 KiB kan uppleva en minskning av sekventiell läsprestanda.
För Linux-kernels 5.4 eller senare rekommenderar vi att du beständigt ställer in read_ahead_kb till 15 MiB för bättre prestanda.
Om du vill ändra det här värdet anger du läsföreläsningsstorleken genom att lägga till en regel i udev, en Linux-kernelenhetshanterare. Följ dessa steg:
I en textredigerare skapar du filen /etc/udev/rules.d/99-nfs.rules genom att ange och spara följande text:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"I en konsol tillämpar du udev-regeln genom att köra kommandot udevadm som en superanvändare och läsa in regelfilerna och andra databaser igen. Du behöver bara köra det här kommandot en gång för att göra udev medveten om den nya filen.
sudo udevadm control --reload
NFS nconnect
NFS nconnect är ett monteringsalternativ på klientsidan för NFS-filresurser som gör att du kan använda flera TCP-anslutningar mellan klienten och NFS-filresursen.
Fördelar
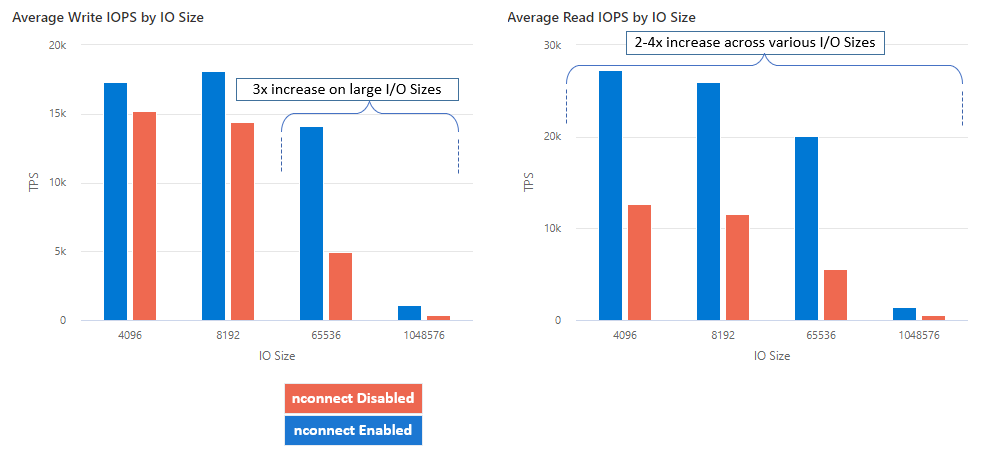
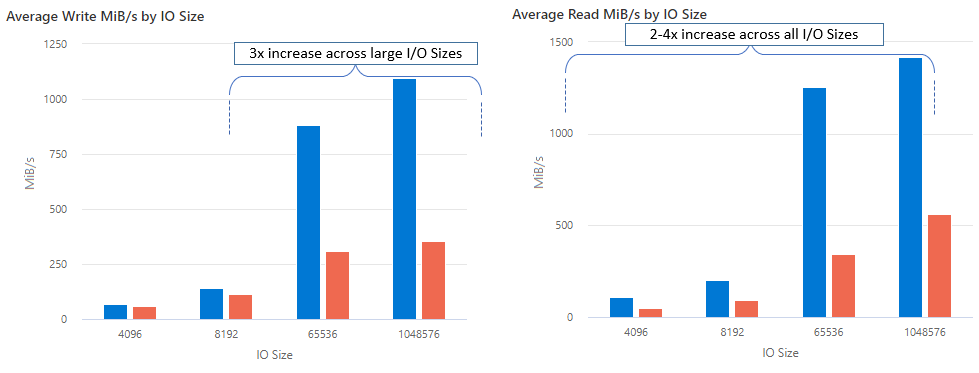
Med nconnect kan du öka prestandan i stor skala med färre klientdatorer för att minska den totala ägandekostnaden (TCO). Nconnect-funktionen ökar prestandan genom att använda flera TCP-kanaler på en eller flera nätverkskort med hjälp av en eller flera klienter. Utan nconnect skulle du behöva ungefär 20 klientdatorer för att uppnå bandbreddsgränserna (10 GiB/s) som erbjuds av den största tilldelningen av SSD-filresurser. Med nconnect kan du uppnå dessa gränser med endast 6–7 klienter, vilket minskar beräkningskostnaderna med nästan 70% samtidigt som du ger betydande förbättringar i I/O-åtgärder per sekund (IOPS) och dataflöde i stor skala. Se följande tabell.
| Mått (åtgärd) | I/O-storlek | Prestandaförbättring |
|---|---|---|
| IOPS (skrivning) | 64 KiB, 1 024 KiB | 3x |
| IOPS (läs) | Alla I/O-storlekar | 2-4 gånger |
| Dataflöde (skrivning) | 64 KiB, 1 024 KiB | 3x |
| Läshastighet | Alla I/O-storlekar | 2-4 gånger |
Förutsättningar
- De senaste Linux-distributionerna har fullt stöd för nconnect. För äldre Linux-distributioner kontrollerar du att Linux-kernelversionen är 5.3 eller senare.
- Konfiguration per monteringspunkt stöds endast när endast en filresurs används för varje lagringskonto över en privat nätverksslutpunkt.
Prestandapåverkan
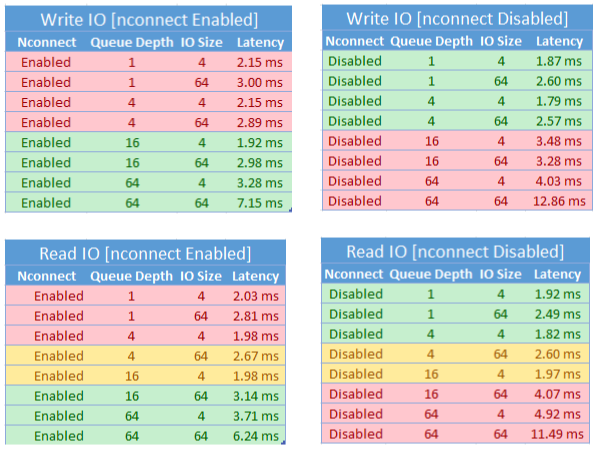
Vi uppnådde följande prestandaresultat när vi använde monteringsalternativet nconnect med NFS Azure-filshares på Linux-klienter i större skala. Mer information om hur vi uppnådde dessa resultat finns i konfiguration av prestandatest.
Rekommendationer
Följ dessa rekommendationer för att få bästa resultat från nconnect.
Ange nconnect=4
Även om Azure Files stöder inställning av nconnect upp till maxinställningen 16 rekommenderar vi att du konfigurerar monteringsalternativen med den optimala inställningen nconnect=4. För närvarande finns det inga vinster utöver fyra kanaler för Azure Files-implementeringen av nconnect. Att överskrida fyra kanaler till en enda Azure-fildelning från en enda klient kan faktiskt påverka prestanda negativt på grund av mättnad i TCP-nätverket.
Ändra storlek på virtuella datorer noggrant
Beroende på dina arbetsbelastningskrav är det viktigt att du har rätt storlek på de virtuella klientdatorerna för att undvika att begränsas av deras förväntade nätverksbandbredd. Du behöver inte flera nätverksgränssnittsstyrenheter (NIC) för att uppnå det förväntade nätverkets dataflöde. Det är vanligt att använda virtuella datorer för generell användning med Azure Files, men olika typer av virtuella datorer är tillgängliga beroende på dina arbetsbelastningsbehov och regionens tillgänglighet. Mer information finns i Azure VM Selector(Azure VM Selector).
Håll ködjupet mindre än eller lika med 64
Ködjup är antalet väntande I/O-begäranden som en lagringsresurs kan betjäna. Vi rekommenderar inte att du överskrider det optimala ködjupet på 64 eftersom du inte ser några fler prestandavinster. Mer information finns i Ködjup.
Per monteringskonfiguration
Om en arbetsbelastning kräver montering av flera resurser med ett eller flera lagringskonton med olika nconnect-inställningar från en enda klient kan vi inte garantera att inställningarna bevaras när de monteras över den offentliga slutpunkten. Varje monteringskonfiguration stöds endast när en enda Azure-fildelning används per lagringskonto via den privata slutpunkten enligt beskrivningen i scenario 1.
Scenario 1: per monteringskonfiguration över privat slutpunkt med flera lagringskonton (stöds)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Scenario 2: per monteringskonfiguration via offentlig slutpunkt (stöds inte)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Anmärkning
Även om lagringskontot matchar en annan IP-adress kan vi inte garantera att adressen bevaras eftersom offentliga slutpunkter inte är statiska adresser.
Scenario 3: per monteringskonfiguration över en privat slutpunkt med flera resurser på ett enda lagringskonto (stöds inte)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Konfiguration av prestandatest
Vi använde följande resurser och verktyg för benchmarking för att uppnå och mäta de resultat som beskrivs i den här artikeln.
- Enskild klient: Virtuell Azure-dator (DSv4-serien) med ett enda nätverkskort
- OS: Linux (Ubuntu 20.04)
-
NFS-lagring: SSD-filandel (provisionerad 30 TiB, ställ in
nconnect=4)
| Storlek | vCPU | Minne | Temp Storage (SSD) | Maximalt antal datadiskar | Maximalt antal nätverkskort | Förväntad nätverksbandbredd |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | Endast fjärrlagring | 32 | 8 | 12 500 Mbit/s |
Verktyg och tester för benchmarking
Vi använde FIO (Flexible I/O Tester), ett kostnadsfritt disk-I/O-verktyg med öppen källkod som används både för benchmark- och stress-/maskinvaruverifiering. Om du vill installera FIO följer du avsnittet Binära paket i FIO README-filen för att installera för valfri plattform.
Även om dessa tester fokuserar på slumpmässiga I/O-åtkomstmönster får du liknande resultat när du använder sekventiell I/O.
Hög IOPS: 100% läsningar
4k I/O-storlek – slumpläsning – 64 ködjup
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
8k I/O-storlek – slumpmässig läsning – 64 ködjup
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Högt genomflöde: 100% läsningar
64 KiB I/O-storlek – slumpmässig läsning – 64 ködjup
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
1 024 KiB I/O-storlek – 100 slumpmässiga läsningar% – kövärdedjup på 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Hög IOPS: 100% skrivningar
4 KiB I/O-storlek – 100% slumpmässig skrivning – 64 ködjup
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
8 KiB I/O-storlek – 100% slumpmässig skrivning – 64 ködjup
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Högt dataflöde: 100% skrivningar
64 KiB I/O-storlek – 100% slumpmässig skrivning – ködjup på 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
1024 KiB I/O-storlek – 100% slumpmässig skrivning – 64 kö-djup
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Prestandaöverväganden för nconnect
När du använder monteringsalternativet nconnect bör du noggrant utvärdera arbetsbelastningar som har följande egenskaper:
- Svarstidskänsliga skrivarbetsbelastningar som är enkla trådade och/eller använder ett lågt ködjup (mindre än 16)
- Svarstidskänsliga läsarbetsbelastningar som är enkla trådade och/eller använder ett lågt ködjup i kombination med mindre I/O-storlekar
Alla arbetsbelastningar kräver inte storskalig IOPS eller prestanda. För arbetsbelastningar i mindre skala kan nconnect kanske inte vara meningsfullt. Använd följande tabell för att avgöra om nconnect det är fördelaktigt för din arbetsbelastning. Scenarier som är markerade i grönt rekommenderas, medan scenarier som är markerade i rött inte är det. Scenarier markerade i gult är neutrala.