Integrera Azure Stream Analytics med Azure Machine Learning
Du kan implementera maskininlärningsmodeller som en användardefinierad funktion (UDF) i dina Azure Stream Analytics-jobb för att göra bedömning och förutsägelser i realtid på dina strömmande indata. Med Azure Machine Learning kan du använda alla populära verktyg med öppen källkod, till exempel TensorFlow, scikit-learn eller PyTorch, för att förbereda, träna och distribuera modeller.
Förutsättningar
Slutför följande steg innan du lägger till en maskininlärningsmodell som en funktion i ditt Stream Analytics-jobb:
Använd Azure Machine Learning för att distribuera din modell som en webbtjänst.
Din maskininlärningsslutpunkt måste ha en associerad swagger som hjälper Stream Analytics att förstå schemat för indata och utdata. Du kan använda den här swagger-exempeldefinitionen som referens för att se till att du har konfigurerat den korrekt.
Kontrollera att webbtjänsten accepterar och returnerar JSON-serialiserade data.
Distribuera din modell i Azure Kubernetes Service för storskaliga produktionsdistributioner. Om webbtjänsten inte kan hantera antalet begäranden som kommer från ditt jobb försämras prestandan för ditt Stream Analytics-jobb, vilket påverkar svarstiden. Modeller som distribueras på Azure Container Instances stöds endast när du använder Azure-portalen.
Lägga till en maskininlärningsmodell i ditt jobb
Du kan lägga till Azure Machine Learning-funktioner i ditt Stream Analytics-jobb direkt från Azure-portalen eller Visual Studio Code.
Azure Portal
Gå till Stream Analytics-jobbet i Azure-portalen och välj Funktioner under Jobbtopologi. Välj sedan Azure Machine Learning Service på den nedrullningsbara menyn + Lägg till .
Fyll i funktionsformuläret för Azure Machine Learning Service med följande egenskapsvärden:
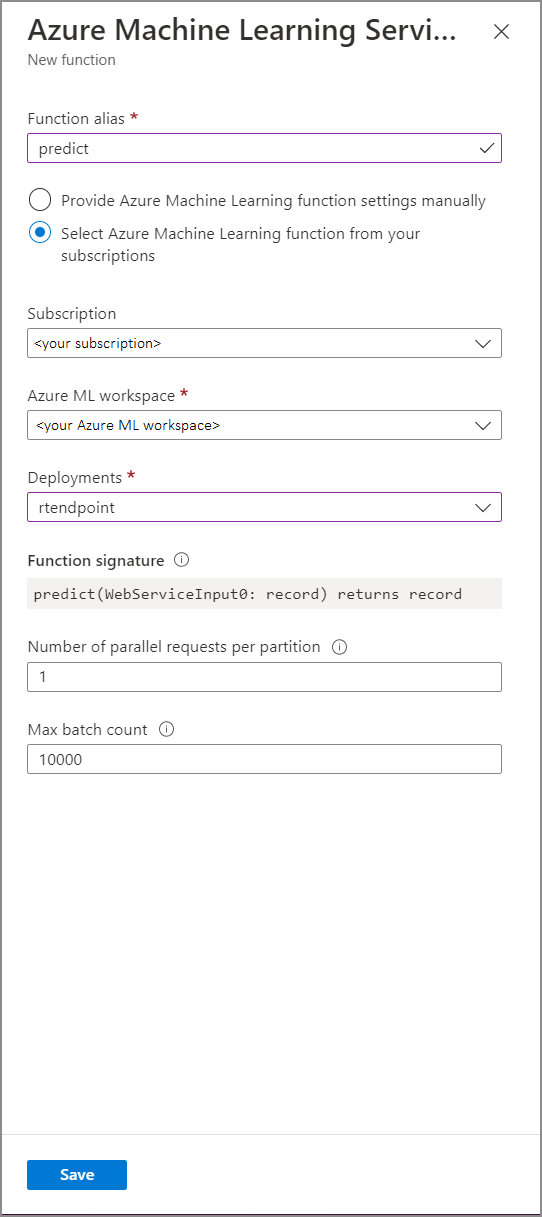
I följande tabell beskrivs varje egenskap för Azure Machine Learning Service-funktioner i Stream Analytics.
| Property | beskrivning |
|---|---|
| Funktionsalias | Ange ett namn för att anropa funktionen i din fråga. |
| Prenumeration | Din Azure-prenumeration. |
| Azure Machine Learning-arbetsyta | Den Azure Machine Learning-arbetsyta som du använde för att distribuera din modell som en webbtjänst. |
| Slutpunkt | Webbtjänsten som är värd för din modell. |
| Funktionssignatur | Signaturen för webbtjänsten som härleds från API:ets schemaspecifikation. Om signaturen inte kan läsas in kontrollerar du att du har angett exempelindata och utdata i bedömningsskriptet för att automatiskt generera schemat. |
| Antal parallella begäranden per partition | Det här är en avancerad konfiguration för att optimera storskaligt dataflöde. Det här numret representerar de samtidiga begäranden som skickas från varje partition av jobbet till webbtjänsten. Jobb med sex direktuppspelningsenheter (SU) och lägre har en partition. Jobb med 12 SUs har två partitioner, 18 SUs har tre partitioner och så vidare. Om ditt jobb till exempel har två partitioner och du anger den här parametern till fyra, kommer det att finnas åtta samtidiga begäranden från jobbet till webbtjänsten. |
| Max batchantal | Det här är en avancerad konfiguration för att optimera storskaligt dataflöde. Det här talet representerar det maximala antalet händelser som batchas tillsammans i en enda begäran som skickas till webbtjänsten. |
Anropa maskininlärningsslutpunkten från din fråga
När Stream Analytics-frågan anropar en Azure Machine Learning UDF skapar jobbet en JSON-serialiserad begäran till webbtjänsten. Begäran baseras på ett modellspecifikt schema som Stream Analytics härleder från slutpunktens swagger.
Varning
Machine Learning-slutpunkter anropas inte när du testar med Azure-portalens frågeredigerare eftersom jobbet inte körs. För att testa slutpunktsanropet från portalen måste Stream Analytics-jobbet köras.
Följande Stream Analytics-fråga är ett exempel på hur du anropar en Azure Machine Learning UDF:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Om dina indata som skickas till ML UDF är inkonsekventa med det schema som förväntas returnerar slutpunkten ett svar med felkoden 400, vilket gör att Stream Analytics-jobbet hamnar i ett misslyckat tillstånd. Vi rekommenderar att du aktiverar resursloggar för ditt jobb, vilket gör att du enkelt kan felsöka och felsöka sådana problem. Därför rekommenderar vi starkt att du:
- Verifiera att indata till ML UDF inte är null
- Verifiera typen av varje fält som är en indata till din ML UDF för att säkerställa att den matchar vad slutpunkten förväntar sig
Kommentar
ML UDF:er utvärderas för varje rad i ett visst frågesteg, även när de anropas via ett villkorsuttryck (dvs. CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Om det behövs använder du WITH-satsen för att skapa olika sökvägar och anropar endast ML UDF där det behövs, innan du använder UNION för att sammanfoga sökvägar igen.
Skicka flera indataparametrar till UDF
De vanligaste exemplen på indata till maskininlärningsmodeller är numpy-matriser och DataFrames. Du kan skapa en matris med hjälp av en JavaScript UDF och skapa en JSON-serialiserad DataFrame med hjälp av WITH -satsen.
Skapa en indatamatris
Du kan skapa en JavaScript UDF som accepterar N antal indata och skapar en matris som kan användas som indata till din Azure Machine Learning UDF.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
När du har lagt till JavaScript UDF i jobbet kan du anropa din Azure Machine Learning UDF med hjälp av följande fråga:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
Följande JSON är en exempelbegäran:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Skapa en Pandas- eller PySpark-dataram
Du kan använda WITH -satsen för att skapa en JSON-serialiserad dataram som kan skickas som indata till din Azure Machine Learning UDF enligt nedan.
Följande fråga skapar en DataFrame genom att välja nödvändiga fält och använder DataFrame som indata till Azure Machine Learning UDF.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Följande JSON är en exempelbegäran från föregående fråga:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Optimera prestanda för Azure Machine Learning UDF:er
När du distribuerar din modell till Azure Kubernetes Service kan du profilera din modell för att fastställa resursutnyttjande. Du kan också aktivera App Insights för dina distributioner för att förstå begärandefrekvenser, svarstider och felfrekvenser.
Om du har ett scenario med högt händelsedataflöde kan du behöva ändra följande parametrar i Stream Analytics för att uppnå optimala prestanda med korta svarstider från slutpunkt till slutpunkt:
- Maximalt antal batchar.
- Antal parallella begäranden per partition.
Fastställa rätt batchstorlek
När du har distribuerat webbtjänsten skickar du exempelbegäran med varierande batchstorlekar från 50 och ökar den i storleksordningen hundratals. Till exempel 200, 500, 1000, 2000 och så vidare. Du kommer att märka att svarstiden ökar efter en viss batchstorlek. Den punkt varefter svarstiden ökar bör vara det maximala batchantalet för ditt jobb.
Fastställa antalet parallella begäranden per partition
Vid optimal skalning bör ditt Stream Analytics-jobb kunna skicka flera parallella begäranden till webbtjänsten och få ett svar inom några millisekunder. Svarstiden för webbtjänstens svar kan direkt påverka svarstiden och prestandan för ditt Stream Analytics-jobb. Om anropet från ditt jobb till webbtjänsten tar lång tid ser du förmodligen en ökning av vattenstämpelfördröjningen och kan också se en ökning av antalet bakåtloggade indatahändelser.
Du kan uppnå låg svarstid genom att se till att ditt Azure Kubernetes Service-kluster (AKS) har etablerats med rätt antal noder och repliker. Det är viktigt att webbtjänsten är mycket tillgänglig och returnerar lyckade svar. Om jobbet får ett fel som kan försökas igen, till exempel svar om tjänsten inte är tillgänglig (503), försöker det automatiskt igen med exponentiell säkerhetskopiering. Om ditt jobb får något av dessa fel som ett svar från slutpunkten, kommer jobbet att gå till ett misslyckat tillstånd.
- Felaktig begäran (400)
- Konflikt (409)
- Hittades inte (404)
- Ej behörig (401)
Begränsningar
Om du använder en Azure ML-hanterad slutpunktstjänst kan Stream Analytics för närvarande bara komma åt slutpunkter som har offentlig nätverksåtkomst aktiverad. Läs mer om det på sidan om privata Azure ML-slutpunkter.