Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Stream Analytics är en fullständigt hanterad PaaS (plattform-som-en-tjänst) för bearbetning av dataströmmar. Den här artikeln beskriver resursmodellen för Stream Analytics genom att introducera begreppet Stream Analytics-kluster, jobb och komponenterna i ett jobb.
Stream Analytics-jobb
Ett Stream Analytics-jobb är den grundläggande enheten i Stream Analytics som gör att du kan definiera och köra dataströmbearbetningslogik. Ett jobb består av tre huvudkomponenter:
- Input
- Resultat
- Fråga
Input
Ett jobb kan ha en eller flera indata att kontinuerligt läsa data från. Dessa strömmande indatakällor kan vara en Azure Event Hubs, Azure IoT Hub eller Azure Storage. Stream Analytics stöder också läsning av statiska eller långsamt föränderliga indata (kallas referensdata) som ofta används för att berika strömmande data. Att lägga till dessa indata i jobbet är en nollkodsåtgärd.
Resultat
Ett jobb kan ha en eller flera utdata att kontinuerligt skriva data till. Stream Analytics stöder 12 olika utdatamottagare, inklusive Azure SQL Database, Azure Data Lake Storage, Azure Cosmos DB, Power BI med mera. Att lägga till dessa utdata i jobbet är också en åtgärd utan kod.
Fråga
Du kan implementera dataströmbearbetningslogik genom att skriva en SQL-fråga i jobbet. Med det omfattande sql-språkstödet kan du hantera scenarier som att parsa komplex JSON, filtrera värden, beräkna aggregeringar, utföra kopplingar och ännu mer avancerade användningsfall som geospatial analys och avvikelseidentifiering. Du kan också utöka det här SQL-språket med JavaScript-användardefinierade funktioner (UDF) och användardefinierade aggregeringar (UDA). Med Stream Analytics kan du också enkelt justera för sena och oordnade händelser via enkla konfigurationer i jobbets inställningar. Du kan också välja att köra frågan baserat på indatahändelsens ankomsttid vid indatakällan eller när händelsen genererades vid händelsekällan.
Köra en uppgift
När du har utvecklat ditt jobb genom att konfigurera indata, utdata och en fråga kan du starta jobbet genom att ange antalet strömningsenheter. När jobbet har startats försätts det i ett körningsläge och förblir i det läget tills det uttryckligen stoppas eller drabbas av ett oåterställbart fel. När jobbet är i ett aktivt tillstånd hämtar det kontinuerligt data från dina indatakällor, kör frågelogiken som ger resultat som skrivs till dina utdataenheter med millisekunders slut-till-slut latens.
När jobbet startas tar Stream Analytics-tjänsten hand om att kompilera din fråga och tilldelar viss mängd beräkning och minne baserat på antalet enheter för direktuppspelning som konfigurerats i ditt jobb. Du behöver inte bekymra dig om någon underliggande infrastruktur som klusterunderhåll, säkerhetskorrigeringar eftersom det tas hand om automatiskt av plattformen. När du kör jobb i standard-SKU:n debiteras du endast för strömningsenheterna när jobbet körs.
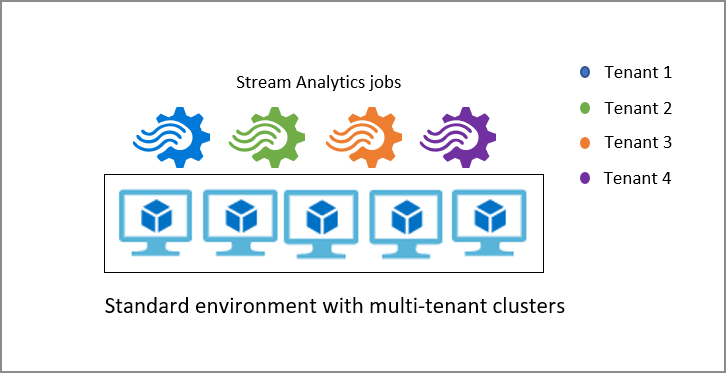
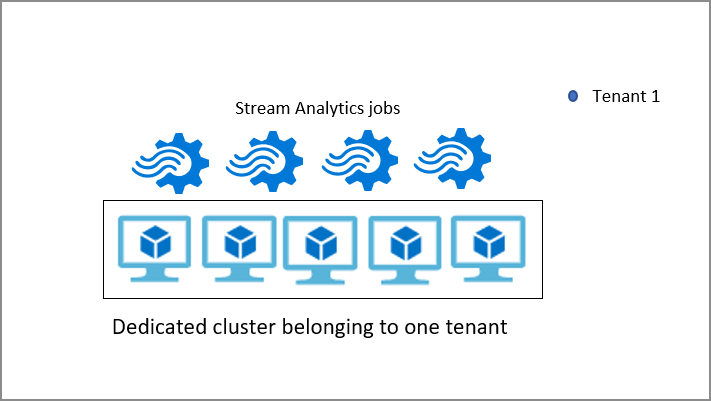
Stream Analytics-kluster
Som standard körs Stream Analytics-jobb i standardmiljön för flera klientorganisationer som utgör standard-SKU:n. Stream Analytics tillhandahåller även en dedikerad SKU där du kan etablera ett helt Stream Analytics-kluster som tillhör dig. Om du gör det får du fullständig kontroll över vilka jobb som körs i klustret. Den minsta storleken på ett Stream Analytics-kluster är 12 strömningsenheter och du debiteras för hela klusterkapaciteten från när den etableras. Du kan lära dig mer om fördelarna med Stream Analytics-kluster och när du ska använda det.
Nästa steg
Lär dig hur du hanterar Azure Stream Analytics och andra begrepp: