Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Viktigt!
Azure Synapse Analytics Data Explorer (förhandsversion) dras tillbaka den 7 oktober 2025. Efter det här datumet tas arbetsbelastningar som körs i Synapse Data Explorer bort och associerade programdata går förlorade. Vi rekommenderar starkt att du migrerar till Eventhouse i Microsoft Fabric.
Microsoft Cloud Migration Factory-programmet (CMF) är utformat för att hjälpa kunder att migrera till Fabric. Programmet erbjuder praktiska tangentbordsresurser utan kostnad för kunden. Dessa resurser tilldelas för en period på 6–8 veckor, med ett fördefinierat och överenskommet omfång. Kundnomineringar accepteras från Microsoft-kontoteamet eller direkt genom att skicka en begäran om hjälp till CMF-teamet.
Azure Synapse Data Explorer ger kunderna en interaktiv frågeupplevelse för att låsa upp insikter från logg- och telemetridata. För att komplettera befintliga SQL- och Apache Spark-analysmotorer optimeras Data Explorer-analyskörningen för effektiv logganalys med hjälp av kraftfull indexeringsteknik för att automatiskt indexera fritext och halvstrukturerade data som ofta finns i telemetridata.

Mer information finns i följande video:
Vad gör Azure Synapse Data Explorer unikt?
Enkel inmatning – Data Explorer erbjuder inbyggda integreringar för datainmatning utan kod/låg kod, datainmatning med högt dataflöde och cachelagring av data från realtidskällor. Data kan matas in från källor som Azure Event Hubs, Kafka, Azure Data Lake, agenter med öppen källkod som Fluentd/Fluent Bit och en mängd olika moln- och lokala datakällor.
Ingen komplex datamodellering – Med Datautforskaren behöver du inte skapa komplexa datamodeller och du behöver inte använda komplexa skript för att transformera data innan de används.
Inget indexunderhåll – Det finns inget behov av underhållsaktiviteter för att optimera data för frågeprestanda och inget behov av indexunderhåll. Med Data Explorer är alla rådata tillgängliga omedelbart, så att du kan köra frågor med höga prestanda och hög samtidighet på dina strömmande och beständiga data. Du kan använda dessa frågor för att skapa instrumentpaneler och aviseringar i nära realtid och ansluta driftanalysdata till resten av dataanalysplattformen.
Demokratisera dataanalys – Data Explorer demokratiserar självbetjäning, stordataanalys med det intuitiva Kusto Query Language (KQL) som ger uttrycksfullhet och kraft i SQL med enkelheten i Excel. KQL är mycket optimerat för att utforska rå telemetri och tidsseriedata genom att utnyttja Data Explorers förstklassiga textindexeringsteknik för effektiv fritext- och regex-sökning och omfattande parserfunktioner för att köra frågor på spår och textdata samt JSON-halvstrukturerade data, inklusive matriser och kapslade strukturer. KQL erbjuder avancerat stöd för tidsserier för att skapa, manipulera och analysera flera tidsserier, med stöd för Python-körning i motorn för modellvärdering.
Beprövad teknik i petabyteskala – Datautforskaren är ett distribuerat system med beräkningsresurser och lagring som kan skalas separat, vilket möjliggör analys på gigabyte eller petabyte med data.
Integrerad – Azure Synapse Analytics ger samverkan mellan data mellan Data Explorer-, Apache Spark- och SQL-motorer som gör det möjligt för datatekniker, dataforskare och dataanalytiker att enkelt och säkert få åtkomst till och samarbeta om samma data i datasjön.
När ska du använda Azure Synapse Data Explorer?
Använd Data Explorer som en dataplattform för att skapa loganalyser i nära realtid och IoT-analyslösningar för att:
Konsolidera och korrelera dina loggar och händelsedata mellan lokala datakällor, molndata och datakällor från tredje part.
Påskynda AI Ops-resan (mönsterigenkänning, avvikelseidentifiering, prognostisering med mera).
Ersätt infrastrukturbaserade loggsökningslösningar för att spara kostnader och öka produktiviteten.
Skapa IoT-analyslösningar för dina IoT-data.
Skapa SaaS-lösningar för analys för att erbjuda tjänster till dina interna och externa kunder.
Data Explorer-poolarkitektur
Data Explorer-pooler implementerar en utskalningsarkitektur genom att separera beräknings- och lagringsresurserna. På så sätt kan du separat skala varje resurs och till exempel köra flera skrivskyddade beräkningar på samma data. Data Explorer-pooler består av en uppsättning beräkningsresurser som kör motorn som ansvarar för automatisk indexering, komprimering, cachelagring och hantering av distribuerade frågor. De har också en andra uppsättning datorresurser som kör datahanteringstjänsten, vilken ansvarar för bakgrundssystemuppgifter samt för hantering och köning av datainmatning. Alla data sparas på hanterade bloblagringskonton med ett komprimerat kolumnformat.
Data Explorer-pooler stöder ett omfattande ekosystem för inmatning av data med hjälp av anslutningsappar, SDK:er, REST-API:er och andra hanterade funktioner. Den erbjuder olika sätt att använda data för ad hoc-frågor, rapporter, instrumentpaneler, aviseringar, REST-API:er och SDK:er.
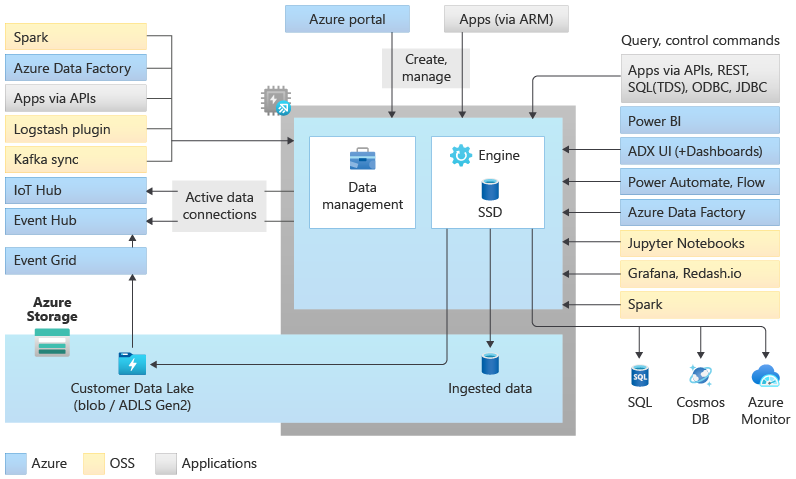
Det finns många unika funktioner som gör Data Explore till den bästa analysmotorn för analys av logg- och tidsserier i Azure.
I följande avsnitt markeras viktiga differentiatorer.
Fritext- och halvstrukturerad dataindexering möjliggör nästan realtidsprestanda och höga samtidiga frågor
Data Explorer indexerar halvstrukturerade data (JSON) och ostrukturerade data (fritext) vilket gör att körande frågor fungerar bra på den här typen av data. Som standard indexeras varje fält under datainmatningen med alternativet att använda en kodningsprincip på låg nivå för att finjustera eller inaktivera indexet för specifika fält. Indexets omfång är en enda datashard.
Implementeringen av indexet beror på typen av fält enligt följande:
| Fälttyp | Implementeringen av indexering |
|---|---|
| String | Motorn skapar ett inverterat termindex för strängkolumnvärden. Varje strängvärde analyseras och delas upp i normaliserade termer och en ordnad lista över logiska positioner, som innehåller postordinaler, registreras för varje term. Den resulterande sorterade listan med termer och deras associerade positioner lagras som ett oföränderligt B-träd. |
|
Numerisk Datum och tid TimeSpan |
Motorn skapar ett enkelt intervallbaserat framåtindex. Indexet registrerar min/max-värdena för varje block, för en grupp block och för hela kolumnen i datashard. |
| Dynamiskt | Inmatningsprocessen räknar upp alla "atomiska" element i det dynamiska värdet, till exempel egenskapsnamn, värden och matriselement, och vidarebefordrar dem till indexverktyget. Dynamiska fält har samma inverterade termindex som strängfält. |
Dessa effektiva indexeringsfunktioner gör det möjligt för Data Explore att göra data tillgängliga nästan i realtid för frågor med höga prestanda och hög samtidighet. Systemet optimerar automatiskt datafragment för att ytterligare öka prestandan.
Kusto-frågespråk
KQL har en stor, växande community med snabb implementering av Azure Monitor Log Analytics och Application Insights, Microsoft Sentinel, Azure Data Explorer och andra Microsoft-erbjudanden. Språket är väl utformat med en lättläst syntax och ger en smidig övergång från enkla enradare till komplexa databehandlingsfrågor. Detta gör att Data Explorer kan ge omfattande Intellisense-stöd och en omfattande uppsättning språkkonstruktioner och inbyggda funktioner för aggregeringar, tidsserier och användaranalyser som inte är tillgängliga i SQL för snabb utforskning av telemetridata.