Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Azure Synapse Analytics Data Explorer (förhandsversion) dras tillbaka den 7 oktober 2025. Efter det här datumet tas arbetsbelastningar som körs i Synapse Data Explorer bort och associerade programdata går förlorade. Vi rekommenderar starkt att du migrerar till Eventhouse i Microsoft Fabric.
Microsoft Cloud Migration Factory-programmet (CMF) är utformat för att hjälpa kunder att migrera till Fabric. Programmet erbjuder praktiska tangentbordsresurser utan kostnad för kunden. Dessa resurser tilldelas för en period på 6–8 veckor, med ett fördefinierat och överenskommet omfång. Kundnomineringar accepteras från Microsoft-kontoteamet eller direkt genom att skicka en begäran om hjälp till CMF-teamet.
I den här snabbstarten lär du dig att läsa in data från en datakälla till Azure Synapse Data Explorer-poolen.
Förutsättningar
Ett Azure-abonnemang. Skapa ett kostnadsfritt Azure-konto.
Skapa en Data Explorer-pool med Synapse Studio eller Azure Portal
Skapa en Data Explorer-databas.
Välj Data i fönstret till vänster i Synapse Studio.
Välj + (Lägg till ny resurs) >Data Explorer-pool och använd följande information:
Inställning Föreslaget värde Beskrivning Poolnamn contosodataexplorer Namnet på datautforskarens pool som ska användas Namn TestDatabase Databasnamnet måste vara unikt inom klustret. Standardkvarhållningsperiod 365 Det tidsintervall (i dagar) då det är garanterat att data förblir tillgängliga för frågor. Tidsintervallet mäts från det att data matas in. Standard cacheperiod 31 Det tidsintervall (i dagar) då data som frågor körs mot ofta ska vara tillgängliga i SSD-lagring eller RAM i stället för i långsiktig lagring. Välj Skapa för att skapa databasen. Det brukar ta mindre än en minut att skapa en databas.
Skapa en tabell
- I Synapse Studio går du till fönstret till vänster och väljer Utveckla.
- Under KQL-skript väljer du + (Lägg till ny resurs) >KQL-skript. I den högra rutan kan du namnge skriptet.
- I menyn Anslut till väljer du contosodataexplorer.
- I menyn Använd databas väljer du TestDatabase.
- Klistra in följande kommando och välj Kör för att skapa tabellen.
.create table StormEvents (StartTime: datetime, EndTime: datetime, EpisodeId: int, EventId: int, State: string, EventType: string, InjuriesDirect: int, InjuriesIndirect: int, DeathsDirect: int, DeathsIndirect: int, DamageProperty: int, DamageCrops: int, Source: string, BeginLocation: string, EndLocation: string, BeginLat: real, BeginLon: real, EndLat: real, EndLon: real, EpisodeNarrative: string, EventNarrative: string, StormSummary: dynamic)Tips/Råd
Kontrollera att tabellen har skapats. I den vänstra rutan väljer du Data, väljer menyn contosodataexplorer more och väljer sedan Uppdatera. Under contosodataexplorer expanderar du Tabeller och kontrollerar att tabellen StormEvents visas i listan.
Hämta slutpunkterna för frågehantering och dataingestion. Du behöver frågeslutpunkten för att konfigurera den länkade tjänsten.
I Synapse Studio går du till den vänstra rutan och väljer Hantera>datautforskarens pooler.
Välj den datautforskarepool som du vill använda för att visa dess information.
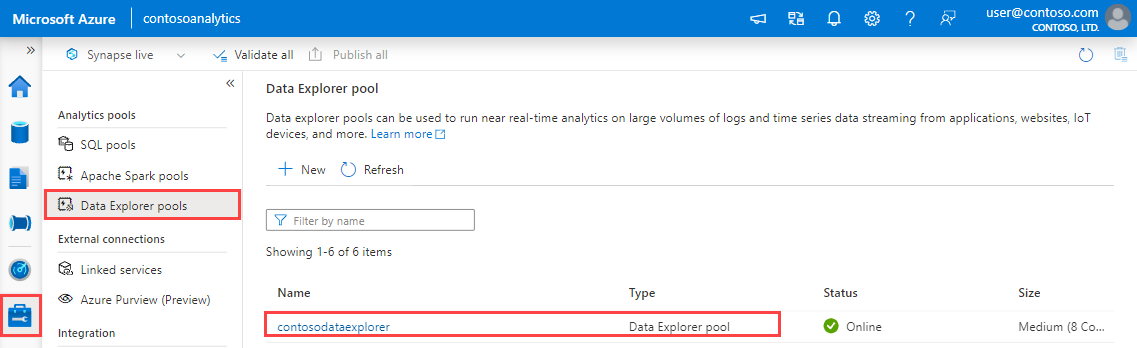
Anteckna slutpunkterna för fråga och datainmatning. Använd frågeslutpunkten som kluster när du konfigurerar anslutningar till datautforskarens pool. När du konfigurerar SDK:er för datainmatning använder du slutpunkten för datainmatning.
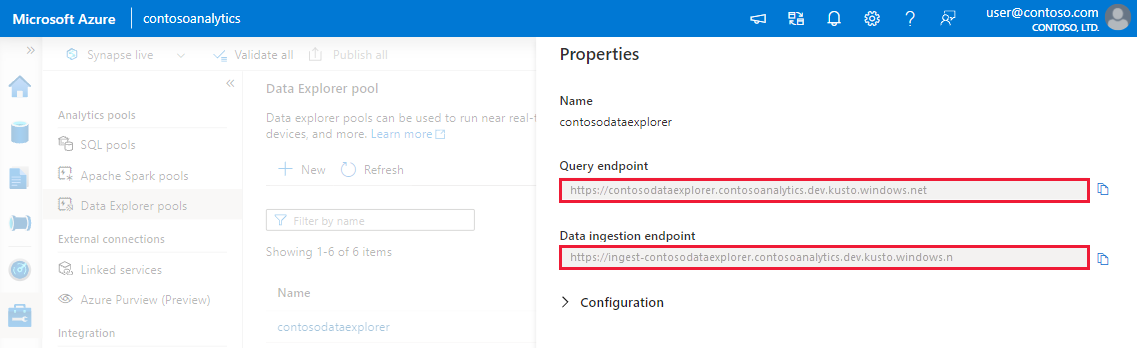
Skapa en länkad tjänst
I Azure Synapse Analytics är en länkad tjänst där du definierar anslutningsinformationen till andra tjänster. I det här avsnittet skapar du en länkad tjänst för Azure Data Explorer.
I Synapse Studio går du till fönstret till vänster och väljer Hantera>länkade tjänster.
Välj + Ny.
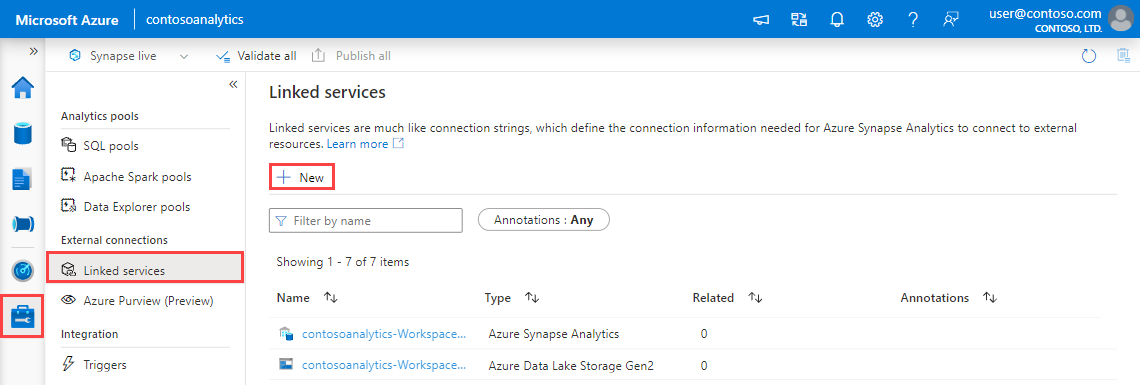
Välj Azure Data Explorer-tjänsten från galleriet och välj sedan Fortsätt.

På sidan Nya länkade tjänster använder du följande information:
Inställning Föreslaget värde Beskrivning Namn contosodataexplorerlinkedservice Namnet på den nya länkade Azure Data Explorer-tjänsten. Autentiseringsmetod Hanterad identitet Autentiseringsmetoden för den nya tjänsten. Metod för kontoval Ange manuellt Metoden för att ange frågeslutpunkten. Slutpunkt https://contosodataexplorer.contosoanalytics.dev.kusto.windows.net Frågeslutpunkten som du antecknade tidigare. Databas TestDatabase Databasen där du vill mata in data. 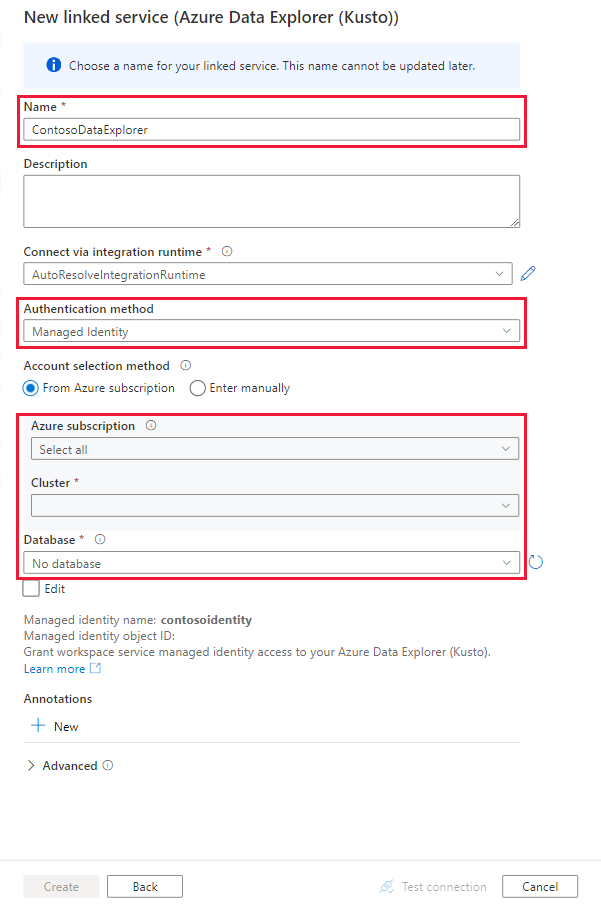
Välj Testa anslutning för att verifiera inställningarna och välj sedan Skapa.
Skapa en pipeline för att mata in data
En pipeline innehåller det logiska flödet för en körning av en uppsättning aktiviteter. I det här avsnittet skapar du en pipeline som innehåller en kopieringsaktivitet som matar in data från önskad källa till en Data Explorer-pool.
I Synapse Studio går du till fönstret till vänster och väljer Integrera.
Välj +>Pipeline. I den högra rutan kan du namnge din pipeline.
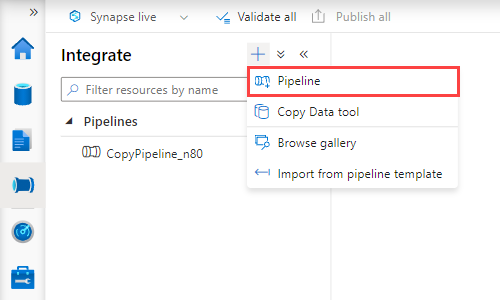
Under Aktiviteter>Flytta och transformera drar du Kopiera data till pipelinearbetsytan.
Välj kopieringsaktiviteten och gå till fliken Källa . Välj eller skapa en ny källdatauppsättning som källa att kopiera data från.
Gå till fliken Mottagare . Välj Ny för att skapa en ny datauppsättning för mottagare.
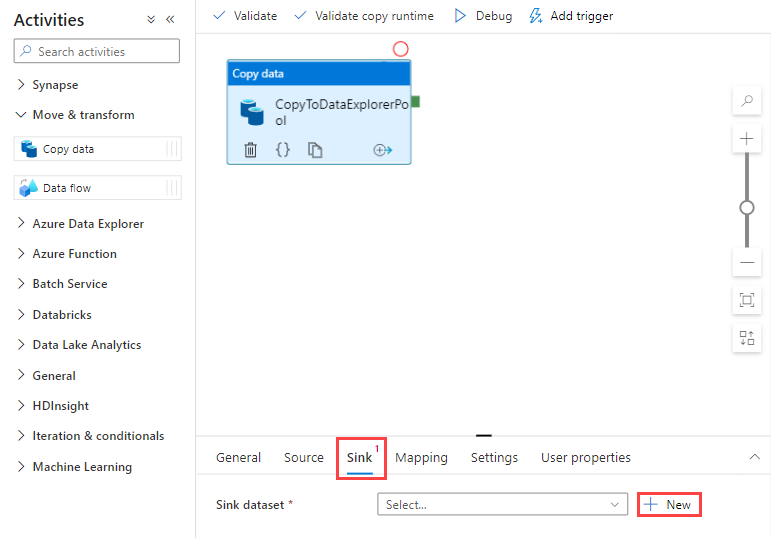
Välj Azure Data Explorer-datamängden från galleriet och välj sedan Fortsätt.
I fönstret Ange egenskaper använder du följande information och väljer sedan OK.
Inställning Föreslaget värde Beskrivning Namn AzureDataExplorerTable Namnet på den nya pipelinen. Länkad tjänst contosodataexplorerlinkedservice Den länkade tjänsten som du skapade tidigare. Tabell StormEvents Tabellen som du skapade tidigare. 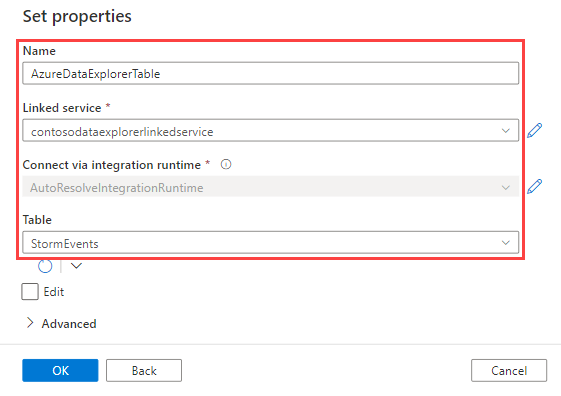
Om du vill verifiera pipelinen väljer du Verifiera i verktygsfältet. Du ser resultatet av pipelinevalideringens utdata på sidan till höger.
Felsöka och publicera pipelinen
När du har konfigurerat pipelinen kan du köra en felsökningskörning innan du publicerar artefakterna för att kontrollera att allt är korrekt.
Välj Felsök i verktygsfältet. Du ser status för pipelinekörningen på fliken Utdata längst ned i fönstret.
När pipelinekörningen är klar väljer du Publicera alla i det översta verktygsfältet. Den här åtgärden publicerar entiteter (datauppsättningar och pipelines) som du har skapat till Synapse Analytics-tjänsten.
Vänta tills du ser meddelandet Publicerat med framgång. Om du vill se meddelanden väljer du klockknappen längst upp till höger.
Utlösa och övervaka pipelinen
I det här avsnittet utlöser du pipelinen som publicerades i föregående steg manuellt.
Välj Lägg till utlösare i verktygsfältet och välj sedan Utlösa nu. På sidan Pipeline Körning väljer du OK.
Gå till fliken Övervaka i det vänstra sidofältet. Du ser en pipelinekörning som är utlöst av en manuell utlösare.
När pipelinekörningen har slutförts väljer du länken under kolumnen Pipelinenamn för att visa aktivitetskörningsinformation eller för att köra pipelinen igen. I det här exemplet finns det bara en aktivitet, så du ser bara en post i listan.
Om du vill ha mer information om kopieringsåtgärden väljer du länken Information (glasögonikonen) under kolumnen Aktivitetsnamn . Du kan övervaka detaljer såsom mängden data som kopieras från källan till mottagaren, datagenomströmning, körningssteg och motsvarande varaktighet samt de använda konfigurationerna.
Om du vill växla tillbaka till pipelinekörningsvyn väljer du länken Alla pipelinekörningar längst upp. Om du vill uppdatera listan väljer du Refresh (Uppdatera).
Kontrollera att dina data är korrekt skrivna i datautforskarens pool.