Konfigurera strömmande inmatning på din Azure Synapse Data Explorer-pool (förhandsversion)
Direktuppspelningsinmatning är användbart för att läsa in data när du behöver korta svarstider mellan inmatning och fråga. Överväg att använda strömningsinmatning i följande scenarier:
- Svarstid på mindre än en sekund krävs.
- Optimera driftbearbetningen av många tabeller där dataströmmen till varje tabell är relativt liten (några poster per sekund), men den totala datainmatningsvolymen är hög (tusentals poster per sekund).
Om dataströmmen i varje tabell är hög (över 4 GB per timme) bör du överväga att använda batchinmatning.
Mer information om olika inmatningsmetoder finns i översikten över datainmatning.
Välj lämplig typ av direktuppspelningsinmatning
Två typer av direktuppspelningsinmatning stöds:
| Inmatningstyp | Beskrivning |
|---|---|
| Händelsehubb eller IoT Hub | Hubbar konfigureras som datakällor för tabellströmning. Information om hur du konfigurerar dessa finns i Event Hub. |
| Anpassad inmatning | Anpassad inmatning kräver att du skriver ett program som använder något av de Azure Synapse Data Explorer klientbiblioteken. Använd informationen i det här avsnittet för att konfigurera anpassad inmatning. Du kanske också tycker att C#-exempelprogrammet för direktuppspelning är användbart. |
Använd följande tabell för att hjälpa dig att välja den inmatningstyp som är lämplig för din miljö:
| Kriterium | Händelsehubb/IoT Hub | Anpassad inmatning |
|---|---|---|
| Datafördröjning mellan inmatningsinitiering och tillgängliga data för fråga | Längre fördröjning | Kortare fördröjning |
| Utvecklingskostnader | Snabb och enkel installation, inga utvecklingskostnader | Höga utvecklingskostnader för att skapa ett program som matar in data, hanterar fel och säkerställer datakonsekvens |
Anteckning
Att mata in data från en händelsehubb i Data Explorer pooler fungerar inte om synapse-arbetsytan använder ett hanterat virtuellt nätverk med dataexfiltreringsskydd aktiverat.
Förutsättningar
En Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto.
Skapa en Data Explorer pool med Synapse Studio eller Azure Portal
Skapa en Data Explorer databas.
I Synapse Studio väljer du Data i fönstret till vänster.
Välj + (Lägg till ny resurs) >Data Explorer pool och använd följande information:
Inställning Föreslaget värde Beskrivning Poolnamn contosodataexplorer Namnet på den Data Explorer pool som ska användas Name TestDatabase Databasnamnet måste vara unikt inom klustret. Standardkvarhållningsperiod 365 Det tidsintervall (i dagar) då det är garanterat att data förblir tillgängliga för frågor. Tidsintervallet mäts från det att data matas in. Standardcacheperiod 31 Det tidsintervall (i dagar) då data som frågor körs mot ofta ska vara tillgängliga i SSD-lagring eller RAM i stället för i långsiktig lagring. Välj Skapa för att skapa databasen. Det brukar ta mindre än en minut att skapa en databas.
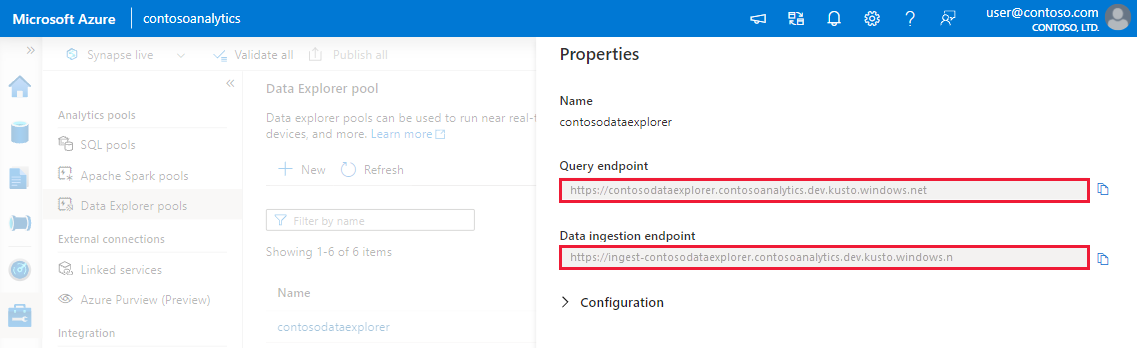
- Hämta slutpunkterna fråga och datainmatning.
I Synapse Studio väljer du Hantera>Data Explorer pooler i fönstret till vänster.
Välj den Data Explorer pool som du vill använda för att visa dess information.
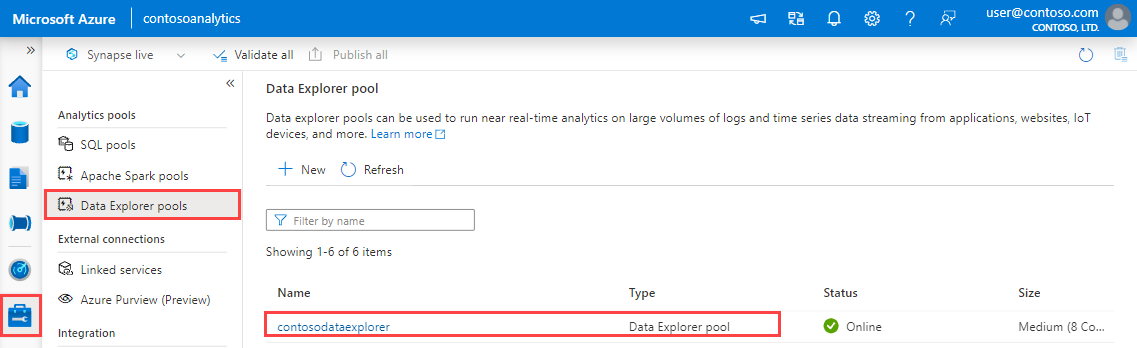
Anteckna fråge- och datainmatningsslutpunkterna. Använd frågeslutpunkten som kluster när du konfigurerar anslutningar till din Data Explorer pool. När du konfigurerar SDK:er för datainmatning använder du slutpunkten för datainmatning.
Prestanda- och driftsöverväganden
De främsta bidragsgivarna som kan påverka strömmande inmatning är:
- Beräkningsspecifikation: Strömmande inmatningsprestanda och kapacitetsskalor med ökade Data Explorer poolstorlekar. Antalet samtidiga inmatningsbegäranden är begränsat till sex per kärna. För arbetsbelastningstypen 16 kärnor, till exempel Beräkningsoptimerad (stor) och Lagringsoptimerad (stor), är den maximala belastningen 96 samtidiga inmatningsbegäranden. För två kärnarbetsbelastningstyper, till exempel Beräkningsoptimerad (extra liten), är den maximala belastningen som stöds 12 samtidiga inmatningsbegäranden.
- Datastorleksgräns: Datastorleksgränsen för en begäran om strömmande inmatning är 4 MB.
- Schemauppdateringar: Schemauppdateringar, till exempel skapande och ändring av tabeller och inmatningsmappningar, kan ta upp till fem minuter för tjänsten för direktuppspelning. Mer information finns i Strömmande inmatning och schemaändringar.
- SSD-kapacitet: Aktivera strömmande inmatning på en Data Explorer pool, även om data inte matas in via strömning, använder en del av den lokala SSD-disken på Data Explorer pooldatorer för strömmande inmatningsdata och minskar lagringen som är tillgänglig för frekvent cache.
Aktivera strömningsinmatning i din Data Explorer pool
Innan du kan använda strömningsinmatning måste du aktivera funktionen i din Data Explorer-pool och definiera en princip för inmatning av direktuppspelning. Du kan aktivera funktionen när du skapar Data Explorer-poolen eller lägga till den i en befintlig Data Explorer pool.
Varning
Granska begränsningarna innan du aktiverar strömningsinmatning.
Aktivera strömningsinmatning när du skapar en ny Data Explorer pool
Du kan aktivera direktuppspelningsinmatning när du skapar en ny Data Explorer-pool med Azure Synapse Studio eller Azure Portal.
När du skapar en Data Explorer pool med hjälp av stegen i Skapa en Data Explorer pool med Synapse Studio går du till fliken Ytterligare inställningar och väljer Direktuppspelningsinmatning>aktiverad.
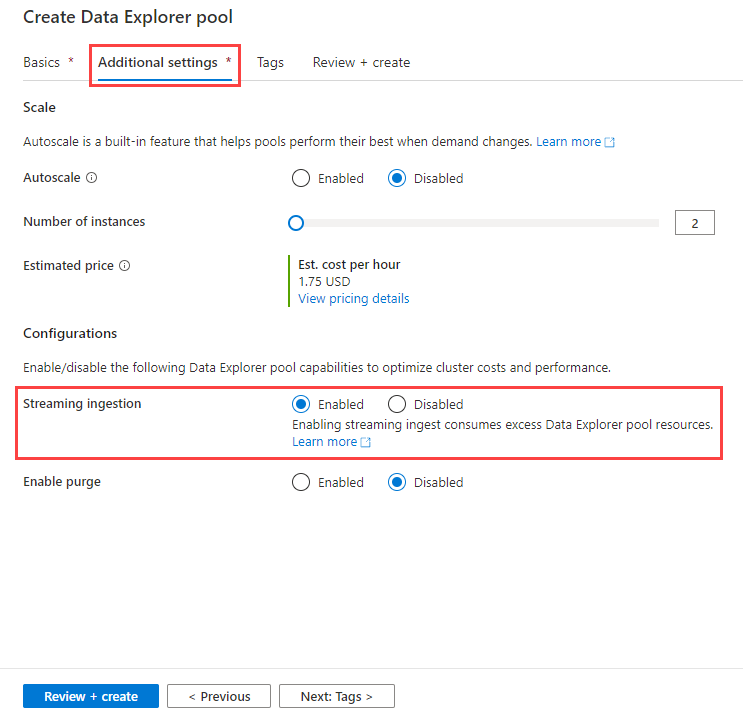
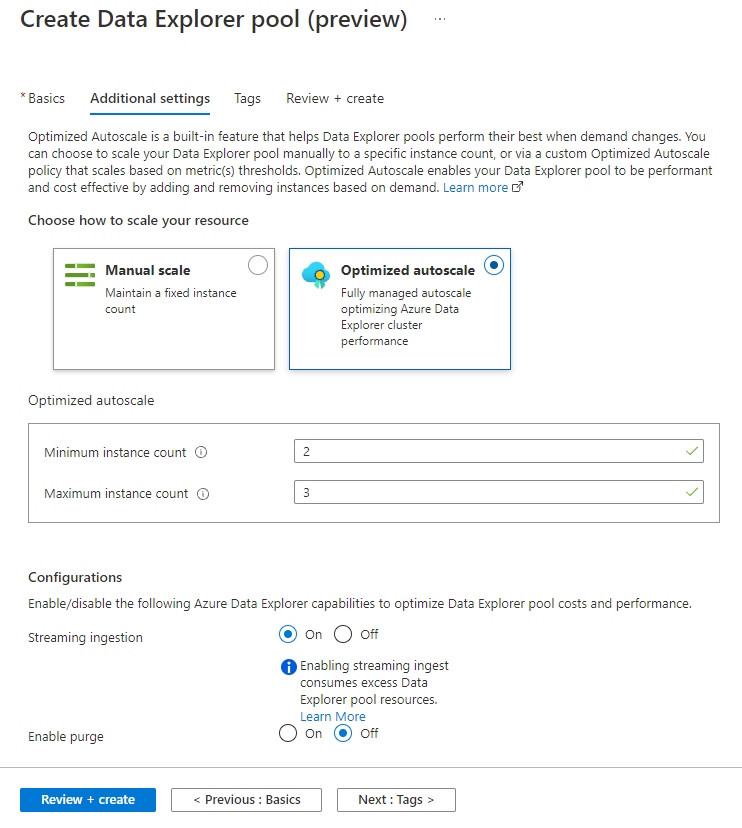
Aktivera strömningsinmatning i en befintlig Data Explorer pool
Om du har en befintlig Data Explorer pool kan du aktivera strömningsinmatning med hjälp av Azure Portal.
- I Azure Portal går du till din Data Explorer pool.
- I Inställningar väljer du Konfigurationer.
- I fönstret Konfigurationer väljer du På för att aktivera strömningsinmatning.
- Välj Spara.
Skapa en måltabell och definiera principen
Skapa en tabell för att ta emot strömmande inmatningsdata och definiera dess relaterade princip med hjälp av Azure Synapse Studio eller Azure Portal.
I Synapse Studio väljer du Utveckla i fönstret till vänster.
Under KQL-skript väljer du + (Lägg till ny resurs) >KQL-skript. I den högra rutan kan du namnge skriptet.
På menyn Anslut till väljer du contosodataexplorer.
På menyn Använd databas väljer du TestDatabase.
Klistra in följande kommando och välj Kör för att skapa tabellen.
.create table TestTable (TimeStamp: datetime, Name: string, Metric: int, Source:string)Kopiera något av följande kommandon till fönstret Fråga och välj Kör. Detta definierar principen för strömningsinmatning i den tabell som du skapade eller i databasen som innehåller tabellen.
Tips
En princip som definieras på databasnivå gäller för alla befintliga och framtida tabeller i databasen.
Om du vill definiera principen i tabellen som du skapade använder du:
.alter table TestTable policy streamingingestion enableOm du vill definiera principen för databasen som innehåller tabellen du skapade använder du:
.alter database StreamingTestDb policy streamingingestion enable
Skapa ett program för direktuppspelningsinmatning för att mata in data till din Data Explorer pool
Skapa ditt program för att mata in data till din Data Explorer pool med det språk du föredrar. För variabeln poolPath använder du den frågeslutpunkt som du antecknar i Krav.
using Kusto.Data;
using Kusto.Ingest;
using System.IO;
using Kusto.Data.Common;
namespace StreamingIngestion
{
class Program
{
static void Main(string[] args)
{
string poolPath = "https://<Poolname>.<WorkspaceName>.kusto.windows.net";
string appId = "<appId>";
string appKey = "<appKey>";
string appTenant = "<appTenant>";
string dbName = "<dbName>";
string tableName = "<tableName>";
// Create Kusto connection string with App Authentication
var csb =
new KustoConnectionStringBuilder(poolPath)
.WithAadApplicationKeyAuthentication(
applicationClientId: appId,
applicationKey: appKey,
authority: appTenant
);
// Create a disposable client that will execute the ingestion
using (IKustoIngestClient client = KustoIngestFactory.CreateStreamingIngestClient(csb))
{
// Initialize client properties
var ingestionProperties =
new KustoIngestionProperties(
databaseName: dbName,
tableName: tableName
);
// Ingest from a compressed file
var fileStream = File.Open("MyFile.gz", FileMode.Open);
// Create source options
var sourceOptions = new StreamSourceOptions()
{
CompressionType = DataSourceCompressionType.GZip,
};
// Ingest from stream
var status = client.IngestFromStreamAsync(fileStream, ingestionProperties, sourceOptions).GetAwaiter().GetResult();
}
}
}
}
Inaktivera strömningsinmatning i din Data Explorer-pool
Varning
Det kan ta några timmar att inaktivera strömningsinmatning.
Innan du inaktiverar strömningsinmatning på din Data Explorer-pool släpper du principen för strömmande inmatning från alla relevanta tabeller och databaser. Borttagningen av den strömmande inmatningsprincipen utlöser omorganisering av data i din Data Explorer-pool. Strömmande inmatningsdata flyttas från den ursprungliga lagringen till permanent lagring i kolumnlagret (utrymmen eller shards). Den här processen kan ta mellan några sekunder och några timmar, beroende på mängden data i den ursprungliga lagringen.
Ta bort principen för strömningsinmatning
Du kan ta bort principen för strömningsinmatning med hjälp av Azure Synapse Studio eller Azure Portal.
I Synapse Studio väljer du Utveckla i fönstret till vänster.
Under KQL-skript väljer du + (Lägg till ny resurs) >KQL-skript. I den högra rutan kan du namnge skriptet.
På menyn Anslut till väljer du contosodataexplorer.
På menyn Använd databas väljer du TestDatabase.
Klistra in följande kommando och välj Kör för att skapa tabellen.
.delete table TestTable policy streamingingestionI Azure Portal går du till din Data Explorer pool.
I Inställningar väljer du Konfigurationer.
I fönstret Konfigurationer väljer du På för att aktivera strömningsinmatning.
Välj Spara.
Begränsningar
- Databasmarkörer stöds inte för en databas om själva databasen eller någon av dess tabeller har principen För direktuppspelning definierad och aktiverad.
- Datamappningar måste skapas i förväg för användning vid strömningsinmatning. Enskilda begäranden om direktuppspelningsinmatning har inte plats för infogade datamappningar.
- Det går inte att ange utrymmestaggar för strömmande inmatningsdata.
- Uppdatera princip. Uppdateringsprincipen kan endast referera till nyligen inmatade data i källtabellen och inte andra data eller tabeller i databasen.
- Om strömningsinmatning används i någon av databastabellerna kan den här databasen inte användas som ledare för uppföljningsdatabaser eller som dataprovider för Azure Synapse Analytics-Data Share.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för