Använda externt Hive-metaarkiv för Synapse Spark-pool
Kommentar
Externa Hive-metaarkiv stöds inte längre i Azure Synapse Runtime för Apache Spark 3.4 och efterföljande versioner i Synapse.
Azure Synapse Analytics gör att Apache Spark-pooler på samma arbetsyta kan dela ett hanterat HMS-kompatibelt metaarkiv (Hive Metastore) som katalog. När kunder vill bevara Hive-katalogmetadata utanför arbetsytan och dela katalogobjekt med andra beräkningsmotorer utanför arbetsytan, till exempel HDInsight och Azure Databricks, kan de ansluta till ett externt Hive-metaarkiv. I den här artikeln kan du lära dig hur du ansluter Synapse Spark till ett externt Apache Hive-metaarkiv.
Hive Metastore-versioner som stöds
Funktionen fungerar med Spark 3.1. I följande tabell visas de Hive Metastore-versioner som stöds för varje Spark-version.
| Spark-version | HMS 2.3.x | HMS 3.1.X |
|---|---|---|
| 3.3 | Ja | Ja |
Konfigurera länkad tjänst till Hive-metaarkiv
Kommentar
Endast Azure SQL Database och Azure Database for MySQL stöds som ett externt Hive-metaarkiv. Och för närvarande stöder vi endast autentisering med användarlösenord. Om den angivna databasen är tom etablerar du den via Hive-schemaverktyget för att skapa databasschema.
Följ stegen nedan för att konfigurera en länkad tjänst till det externa Hive-metaarkivet i Synapse-arbetsytan.
Öppna Synapse Studio, gå till Hantera > länkade tjänster till vänster, klicka på Ny för att skapa en ny länkad tjänst.
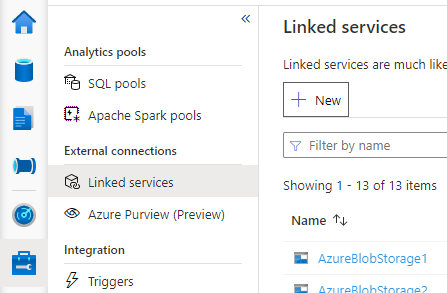
Välj Azure SQL Database eller Azure Database for MySQL baserat på din databastyp och klicka på Fortsätt.
Ange namnet på den länkade tjänsten. Registrera namnet på den länkade tjänsten. Den här informationen kommer att användas för att konfigurera Spark inom kort.
Du kan antingen välja Azure SQL Database Azure Database/for MySQL för det externa Hive-metaarkivet från Azure-prenumerationslistan eller ange informationen manuellt.
Ange användarnamn och lösenord för att konfigurera anslutningen.
Testa anslutningen för att verifiera användarnamnet och lösenordet.
Klicka på Skapa för att skapa den länkade tjänsten.
Testa anslutningen och hämta metaarkivversionen i notebook-filen
Vissa inställningar för nätverkssäkerhetsregler kan blockera åtkomst från Spark-poolen till den externa Hive-metaarkivdatabasen. Innan du konfigurerar Spark-poolen kör du koden nedan i en Spark-poolanteckningsbok för att testa anslutningen till den externa Hive-metaarkivdatabasen.
Du kan också hämta din Hive Metastore-version från utdataresultaten. Hive Metastore-versionen används i Spark-konfigurationen.
Kod för anslutningstestning för Azure SQL
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure SQL database > Connection strings > JDBC **/
val url = s"jdbc:sqlserver://{your_servername_here}.database.windows.net:1433;database={your_database_here};user={your_username_here};password={your_password_here};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
try {
val connection = DriverManager.getConnection(url)
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
Kod för anslutningstestning för Azure Database for MySQL
%%spark
import java.sql.DriverManager
/** this JDBC url could be copied from Azure portal > Azure Database for MySQL > Connection strings > JDBC **/
val url = s"jdbc:mysql://{your_servername_here}.mysql.database.azure.com:3306/{your_database_here}?useSSL=true"
try {
val connection = DriverManager.getConnection(url, "{your_username_here}", "{your_password_here}");
val result = connection.createStatement().executeQuery("select t.SCHEMA_VERSION from VERSION t")
result.next();
println(s"Successful to test connection. Hive Metastore version is ${result.getString(1)}")
} catch {
case ex: Throwable => println(s"Failed to establish connection:\n $ex")
}
Konfigurera Spark för att använda det externa Hive-metaarkivet
När du har skapat den länkade tjänsten till det externa Hive-metaarkivet måste du konfigurera några Spark-konfigurationer för att använda det externa Hive-metaarkivet. Du kan både konfigurera konfigurationen på Spark-poolnivå eller på Spark-sessionsnivå.
Här är konfigurationerna och beskrivningarna:
Kommentar
Synapse strävar efter att fungera smidigt med beräkningar från HDI. HMS 3.1 i HDI 4.0 är dock inte helt kompatibelt med OSS HMS 3.1. För OSS HMS 3.1, kontrollera här.
| Spark-konfiguration | beskrivning |
|---|---|
spark.sql.hive.metastore.version |
Versioner som stöds:
|
spark.sql.hive.metastore.jars |
|
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name |
Namnet på den länkade tjänsten |
spark.sql.hive.metastore.sharedPrefixes |
com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas |
Konfigurera på Spark-poolnivå
När du skapar Spark-poolen går du till fliken Ytterligare inställningar och lägger till konfigurationerna nedan i en textfil och laddar upp den i konfigurationsavsnittet för Apache Spark. Du kan också använda snabbmenyn för en befintlig Spark-pool och välja Apache Spark-konfiguration för att lägga till dessa konfigurationer.
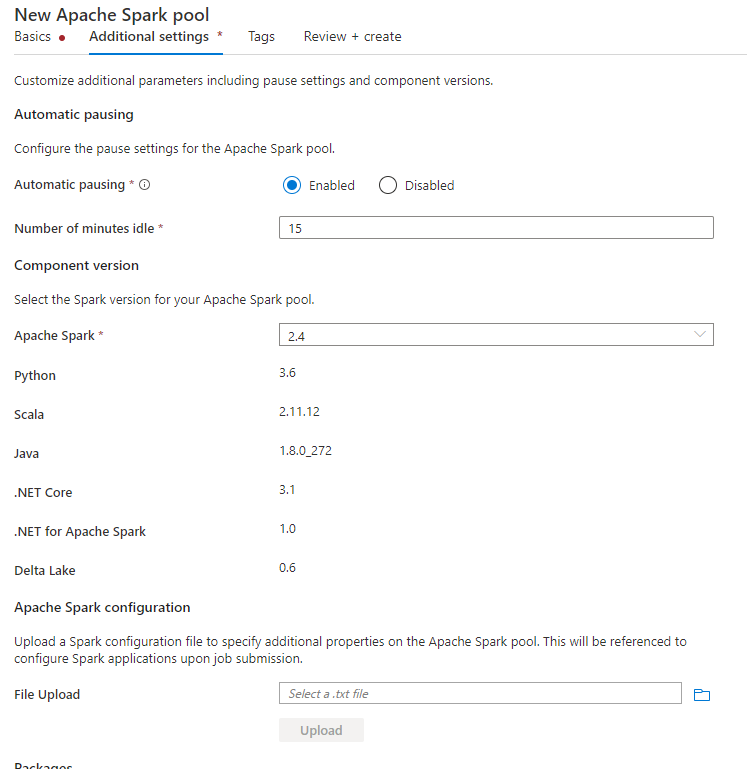
Uppdatera metaarkivversionen och det länkade tjänstnamnet och spara nedanstående konfigurationer i en textfil för Konfiguration av Spark-pool:
spark.sql.hive.metastore.version <your hms version, Make sure you use the first 2 parts without the 3rd part>
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name <your linked service name>
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas
Här är ett exempel på metaarkiv version 2.3 med länkad tjänst med namnet HiveCatalog21:
spark.sql.hive.metastore.version 2.3
spark.hadoop.hive.synapse.externalmetastore.linkedservice.name HiveCatalog21
spark.sql.hive.metastore.jars /opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*
spark.sql.hive.metastore.sharedPrefixes com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas
Konfigurera på Spark-sessionsnivå
För notebook-session kan du även konfigurera Spark-sessionen i notebook-filen med hjälp av %%configure ett magiskt kommando. Här är koden.
%%configure -f
{
"conf":{
"spark.sql.hive.metastore.version":"<your hms version, 2 parts>",
"spark.hadoop.hive.synapse.externalmetastore.linkedservice.name":"<your linked service name>",
"spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-<your hms version, 2 parts>/*:/usr/hdp/current/hadoop-client/lib/*",
"spark.sql.hive.metastore.sharedPrefixes":"com.mysql.jdbc,com.microsoft.sqlserver,com.microsoft.vegas"
}
}
För batchjobb kan samma konfiguration också tillämpas via SparkConf.
Köra frågor för att verifiera anslutningen
När du har alla dessa inställningar kan du försöka lista katalogobjekt genom att köra frågan nedan i Spark Notebook för att kontrollera anslutningen till det externa Hive-metaarkivet.
spark.sql("show databases").show()
Konfigurera lagringsanslutning
Den länkade tjänsten till Hive Metastore-databasen ger bara åtkomst till Hive-katalogmetadata. Om du vill köra frågor mot de befintliga tabellerna måste du även konfigurera anslutningen till lagringskontot som lagrar underliggande data för dina Hive-tabeller.
Konfigurera anslutning till Azure Data Lake Storage Gen 2
Primärt lagringskonto för arbetsyta
Om underliggande data för dina Hive-tabeller lagras i arbetsytans primära lagringskonto behöver du inte göra några extra inställningar. Det fungerar bara så länge du har följt instruktionerna för lagringsinställningen när arbetsytan skapas.
Annat ADLS Gen 2-konto
Om underliggande data i dina Hive-kataloger lagras i ett annat ADLS Gen 2-konto måste du se till att de användare som kör Spark-frågor har rollen Storage Blob Data Contributor på ADLS Gen2-lagringskontot.
Upprätta anslutningen till Blob Storage
Om underliggande data för dina Hive-tabeller lagras i Azure Blob Storage-kontot konfigurerar du anslutningen genom att följa stegen nedan:
Öppna Synapse Studio, gå till fliken > Data länkad Lägg till knappen >Anslut till externa data.>
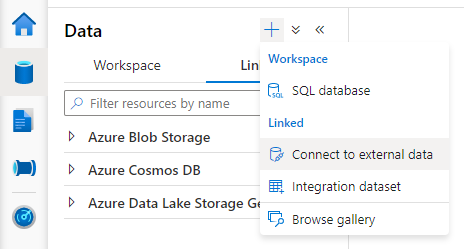
Välj Azure Blob Storage och klicka på Fortsätt.
Ange namnet på den länkade tjänsten. Registrera namnet på den länkade tjänsten. Den här informationen används inom kort i Spark-konfigurationen.
Välj Azure Blob Storage-kontot. Kontrollera att autentiseringsmetoden är kontonyckel. För närvarande kan Spark-poolen bara komma åt Blob Storage-kontot via kontonyckeln.
Testa anslutningen och klicka på Skapa.
När du har skapat den länkade tjänsten till Blob Storage-kontot ska du när du kör Spark-frågor köra spark-koden under Spark-koden i notebook-filen för att få åtkomst till Blob Storage-kontot för Spark-sessionen. Läs mer om varför du behöver göra detta här.
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
När du har konfigurerat lagringsanslutningar kan du fråga de befintliga tabellerna i Hive-metaarkivet.
Kända begränsningar
- Synapse Studio-objektutforskaren fortsätter att visa objekt i det hanterade Synapse-metaarkivet i stället för den externa HMS-filen.
- SQL <–> Spark-synkronisering fungerar inte när du använder extern HMS.
- Endast Azure SQL Database och Azure Database for MySQL stöds som extern Hive-metaarkivdatabas. Endast SQL-auktorisering stöds.
- För närvarande fungerar Spark bara på externa Hive-tabeller och icke-transaktionella/icke-ACID-hanterade Hive-tabeller. Den har inte stöd för Hive ACID/transaktionstabeller.
- Apache Ranger-integrering stöds inte.
Felsökning
Se felet nedan när du frågar en Hive-tabell med data som lagras i Blob Storage
No credentials found for account xxxxx.blob.core.windows.net in the configuration, and its container xxxxx is not accessible using anonymous credentials. Please check if the container exists first. If it is not publicly available, you have to provide account credentials.
När du använder nyckelautentisering till ditt lagringskonto via länkad tjänst måste du ta ett extra steg för att hämta token för Spark-sessionen. Kör koden nedan för att konfigurera Spark-sessionen innan du kör frågan. Läs mer om varför du behöver göra detta här.
%%pyspark
blob_account_name = "<your blob storage account name>"
blob_container_name = "<your container name>"
from pyspark.sql import SparkSession
sc = SparkSession.builder.getOrCreate()
token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary
blob_sas_token = token_library.getConnectionString("<blob storage linked service name>")
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
Se felet nedan när du frågar en tabell som lagras i ADLS Gen2-kontot
Operation failed: "This request is not authorized to perform this operation using this permission.", 403, HEAD
Det här kan inträffa om användaren som kör Spark-frågan inte har tillräcklig åtkomst till det underliggande lagringskontot. Kontrollera att användaren som kör Spark-frågor har rollen Storage Blob Data Contributor på ADLS Gen2-lagringskontot. Det här steget kan göras när du har skapat den länkade tjänsten.
HMS-schemarelaterade inställningar
För att undvika att ändra HMS-serverdelsschema/version anges följande hive-konfigurationer som system som standard:
spark.hadoop.hive.metastore.schema.verification true
spark.hadoop.hive.metastore.schema.verification.record.version false
spark.hadoop.datanucleus.fixedDatastore true
spark.hadoop.datanucleus.schema.autoCreateAll false
Om din HMS-version är 1.2.1 eller 1.2.2finns det ett problem i Hive som kräver endast 1.2.0 om du vänder spark.hadoop.hive.metastore.schema.verification dig till true. Vårt förslag är antingen att du kan ändra din HMS-version till 1.2.0eller skriva över under två konfigurationer för att kringgå:
spark.hadoop.hive.metastore.schema.verification false
spark.hadoop.hive.synapse.externalmetastore.schema.usedefault false
Om du behöver migrera din HMS-version rekommenderar vi att du använder hive-schemaverktyget. Och om HMS har använts av HDInsight-kluster föreslår vi att du använder hdi-tillhandahållen version.
HMS-schemaändring för OSS HMS 3.1
Synapse strävar efter att fungera smidigt med beräkningar från HDI. HMS 3.1 i HDI 4.0 är dock inte helt kompatibelt med OSS HMS 3.1. Så tillämpa följande manuellt på din HMS 3.1 om den inte etableras av HDI.
-- HIVE-19416
ALTER TABLE TBLS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
ALTER TABLE PARTITIONS ADD WRITE_ID bigint NOT NULL DEFAULT(0);
När jag delar metaarkivet med HDInsight 4.0 Spark-klustret kan jag inte se tabellerna
Om du vill dela Hive-katalogen med ett Spark-kluster i HDInsight 4.0 kontrollerar du att egenskapen spark.hadoop.metastore.catalog.default i Synapse spark överensstämmer med värdet i HDInsight Spark. Standardvärdet för HDI Spark är spark och standardvärdet för Synapse Spark är hive.
När jag delar Hive-metaarkivet med HDInsight 4.0 Hive-klustret kan jag visa en lista över tabellerna, men bara få ett tomt resultat när jag frågar tabellen
Som nämnts i begränsningarna stöder Synapse Spark-poolen endast externa hive-tabeller och icke-transaktionella/ACID-hanterade tabeller, den stöder för närvarande inte Hive ACID/transaktionstabeller. I HDInsight 4.0 Hive-kluster skapas alla hanterade tabeller som ACID-/transaktionstabeller som standard. Därför får du tomma resultat när du frågar efter tabellerna.
Se felet nedan när ett externt metaarkiv används medan Intelligent cache är aktiverat
java.lang.ClassNotFoundException: Class com.microsoft.vegas.vfs.SecureVegasFileSystem not found
Du kan enkelt åtgärda det här problemet genom att lägga /usr/hdp/current/hadoop-client/* till i .spark.sql.hive.metastore.jars
Eg:
spark.sql.hive.metastore.jars":"/opt/hive-metastore/lib-2.3/*:/usr/hdp/current/hadoop-client/lib/*:/usr/hdp/current/hadoop-client/*