Använda .NET för Apache Spark med Azure Synapse Analytics
.NET för Apache Spark tillhandahåller kostnadsfritt .NET-stöd med öppen källkod och plattformsoberoende .NET för Spark.
Den tillhandahåller .NET-bindningar för Spark, vilket gör att du kan komma åt Spark-API:er via C# och F#. Med .NET för Apache Spark kan du också skriva och köra användardefinierade funktioner för Spark som skrivits i .NET. Med .NET API:er för Spark kan du komma åt alla aspekter av Spark DataFrames som hjälper dig att analysera dina data, inklusive Spark SQL, Delta Lake och Structured Streaming.
Du kan analysera data med .NET för Apache Spark via Spark batch-jobbdefinitioner eller med interaktiva Azure Synapse Analytics-notebook-filer. I den här artikeln får du lära dig hur du använder .NET för Apache Spark med Azure Synapse med hjälp av båda teknikerna.
Viktigt!
.NET för Apache Spark är ett projekt med öppen källkod under .NET Foundation som för närvarande kräver .NET 3.1-biblioteket, som har nått statusen out-of-support. Vi vill informera användare av Azure Synapse Spark om borttagningen av .NET för Apache Spark-biblioteket i Azure Synapse Runtime för Apache Spark version 3.3. Användare kan referera till .NET-supportpolicyn för mer information om detta.
Därför är det inte längre möjligt för användare att använda Apache Spark-API:er via C# och F#, eller köra C#-kod i notebook-filer i Synapse eller via Apache Spark-jobbdefinitioner i Synapse. Observera att den här ändringen endast påverkar Azure Synapse Runtime för Apache Spark 3.3 och senare.
Vi kommer att fortsätta att stödja .NET för Apache Spark i alla tidigare versioner av Azure Synapse Runtime enligt deras livscykelsteg. Vi har dock inga planer på att stödja .NET för Apache Spark i Azure Synapse Runtime för Apache Spark 3.3 och framtida versioner. Vi rekommenderar att användare med befintliga arbetsbelastningar som skrivits i C# eller F# migrerar till Python eller Scala. Användarna uppmanas att notera denna information och planera i enlighet med detta.
Skicka batchjobb med hjälp av Spark-jobbdefinitionen
I självstudien får du lära dig hur du använder Azure Synapse Analytics för att skapa Apache Spark-jobbdefinitioner för Synapse Spark-pooler. Om du inte har paketerat din app för att skicka till Azure Synapse utför du följande steg.
Konfigurera programberoenden
dotnetför kompatibilitet med Synapse Spark. Den nödvändiga .NET Spark-versionen anges i Synapse Studio-gränssnittet under konfigurationen av Apache Spark-poolen under verktygslådan Hantera.
Skapa projektet som ett .NET-konsolprogram som matar ut en körbar Ubuntu x86-fil.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Kör följande kommandon för att publicera din app. Se till att ersätta mySparkApp med sökvägen till din app.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Zippa innehållet i publiceringsmappen,
publish.ziptill exempel, som skapades som ett resultat av steg 1. Alla sammansättningar ska finnas i zip-filens rot och det ska inte finnas något mellanliggande mapplager. Det innebär att när du packa upppublish.zipextraheras alla sammansättningar till den aktuella arbetskatalogen.I Windows:
Använd Windows PowerShell eller PowerShell 7 och skapa en .zip från innehållet i publiceringskatalogen.
Compress-Archive publish/* publish.zip -UpdateI Linux:
Öppna ett bash-gränssnitt och en cd i bin-katalogen med alla publicerade binärfiler och kör följande kommando.
zip -r publish.zip
.NET för Apache Spark i Azure Synapse Analytics-notebook-filer
Notebook-filer är ett bra alternativ för prototyper av .NET för Apache Spark-pipelines och scenarier. Du kan börja arbeta med, förstå, filtrera, visa och visualisera dina data snabbt och effektivt.
Datatekniker, dataforskare, affärsanalytiker och maskininlärningstekniker kan alla samarbeta över ett delat interaktivt dokument. Du ser omedelbara resultat från datautforskning och kan visualisera dina data i samma notebook-fil.
Så här använder du .NET för Apache Spark-notebook-filer
När du skapar en ny notebook-fil väljer du en språkkärna som du vill uttrycka din affärslogik. Kernel-stöd är tillgängligt för flera språk, inklusive C#.
Om du vill använda .NET för Apache Spark i din Azure Synapse Analytics-anteckningsbok väljer du .NET Spark (C#) som kernel och kopplar notebook-filen till en befintlig serverlös Apache Spark-pool.
.NET Spark-notebook-filen baseras på interaktiva .NET-upplevelser och ger interaktiva C#-upplevelser med möjligheten att använda .NET för Spark direkt med Spark-sessionsvariabeln spark redan fördefinierad.
Installera NuGet-paket i notebook-filer
Du kan installera valfria NuGet-paket i notebook-filen med hjälp av det #r nuget magiska kommandot före namnet på NuGet-paketet. Följande diagram visar ett exempel:
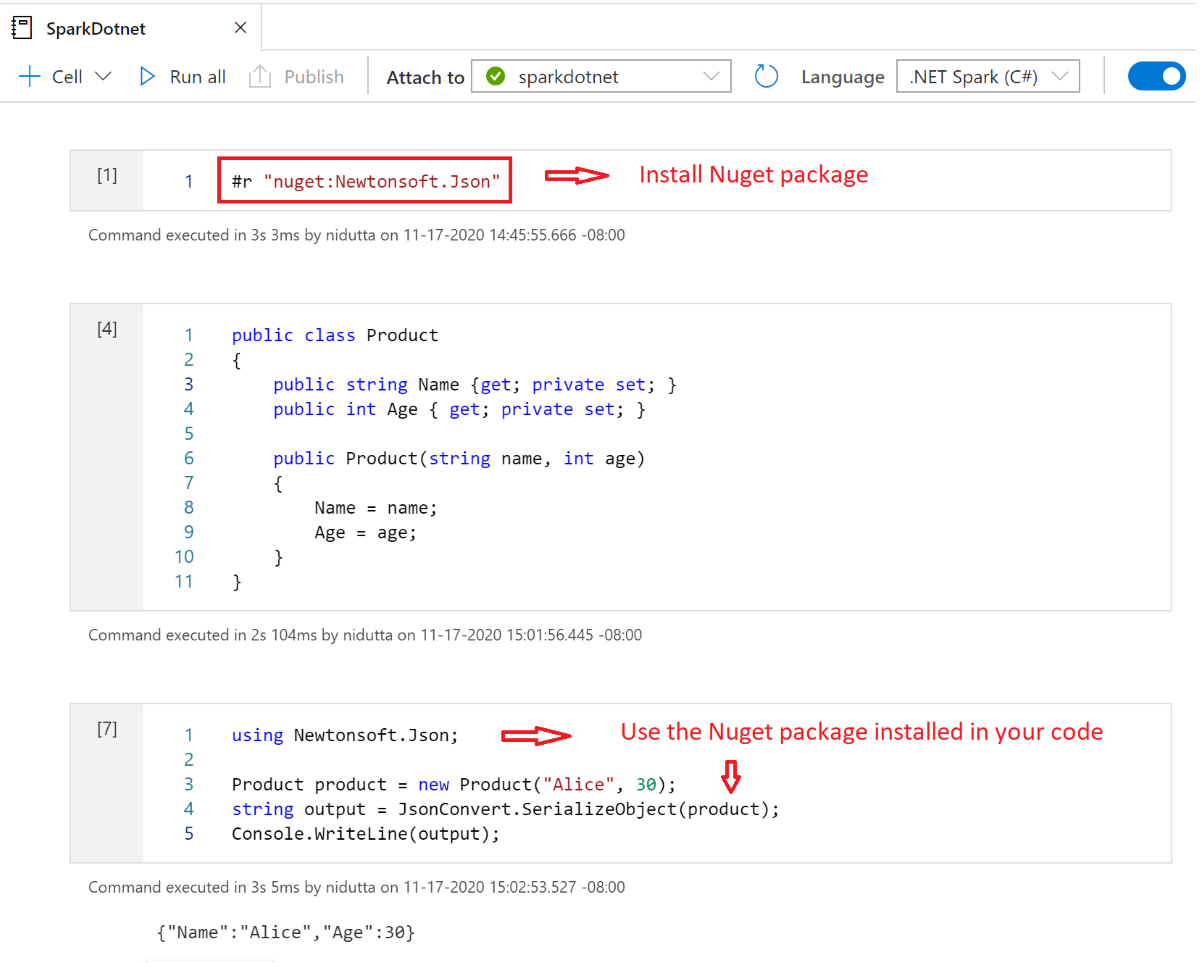
Mer information om hur du arbetar med NuGet-paket i notebook-filer finns i den interaktiva dokumentationen för .NET.
.NET för Apache Spark C#-kernelfunktioner
Följande funktioner är tillgängliga när du använder .NET för Apache Spark i Azure Synapse Analytics-notebook-filen:
- Deklarativ HTML: Generera utdata från dina celler med HTML-syntax, till exempel rubriker, punktlistor och till och med bilder.
- Enkla C#-instruktioner (till exempel tilldelningar, utskrift till konsolen, utlösa undantag och så vidare).
- C#-kodblock med flera rader (till exempel om-instruktioner, foreach-loopar, klassdefinitioner och så vidare).
- Åtkomst till C#-standardbiblioteket (till exempel System, LINQ, Enumerables och så vidare).
- Stöd för C# 8.0-språkfunktioner.
sparksom en fördefinierad variabel för att ge dig åtkomst till din Apache Spark-session.- Stöd för att definiera användardefinierade .NET-funktioner som kan köras i Apache Spark. Vi rekommenderar att du skriver och anropar UDF:er i .NET för interaktiva Apache Spark-miljöer för att lära dig hur du använder UDF:er i .NET för interaktiva Apache Spark-upplevelser.
- Stöd för att visualisera utdata från dina Spark-jobb med hjälp av olika diagram (till exempel linje, stapel eller histogram) och layouter (till exempel enkla, överlagrade och så vidare) med hjälp av
XPlot.Plotlybiblioteket. - Möjlighet att inkludera NuGet-paket i din C#-notebook-fil.
Felsökning
DotNetRunner: null / Futures timeout i Synapse Spark-jobbdefinitionskörning
Synapse Spark-jobbdefinitioner i Spark-pooler med Spark 2.4 kräver Microsoft.Spark 1.0.0. Rensa dina bin kataloger och obj publicera projektet med hjälp av 1.0.0.
OutOfMemoryError: java heap space på org.apache.spark
Dotnet Spark 1.0.0 använder en annan felsökningsarkitektur än 1.1.1+. Du måste använda 1.0.0 för den publicerade versionen och 1.1.1+ för lokal felsökning.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för