Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Det här fuskbladet innehåller användbara tips och metodtips för att skapa dedikerade SQL-poollösningar (tidigare SQL DW).
Följande bild visar processen att utforma ett informationslager med en dedikerad SQL-pool (tidigare SQL DW):
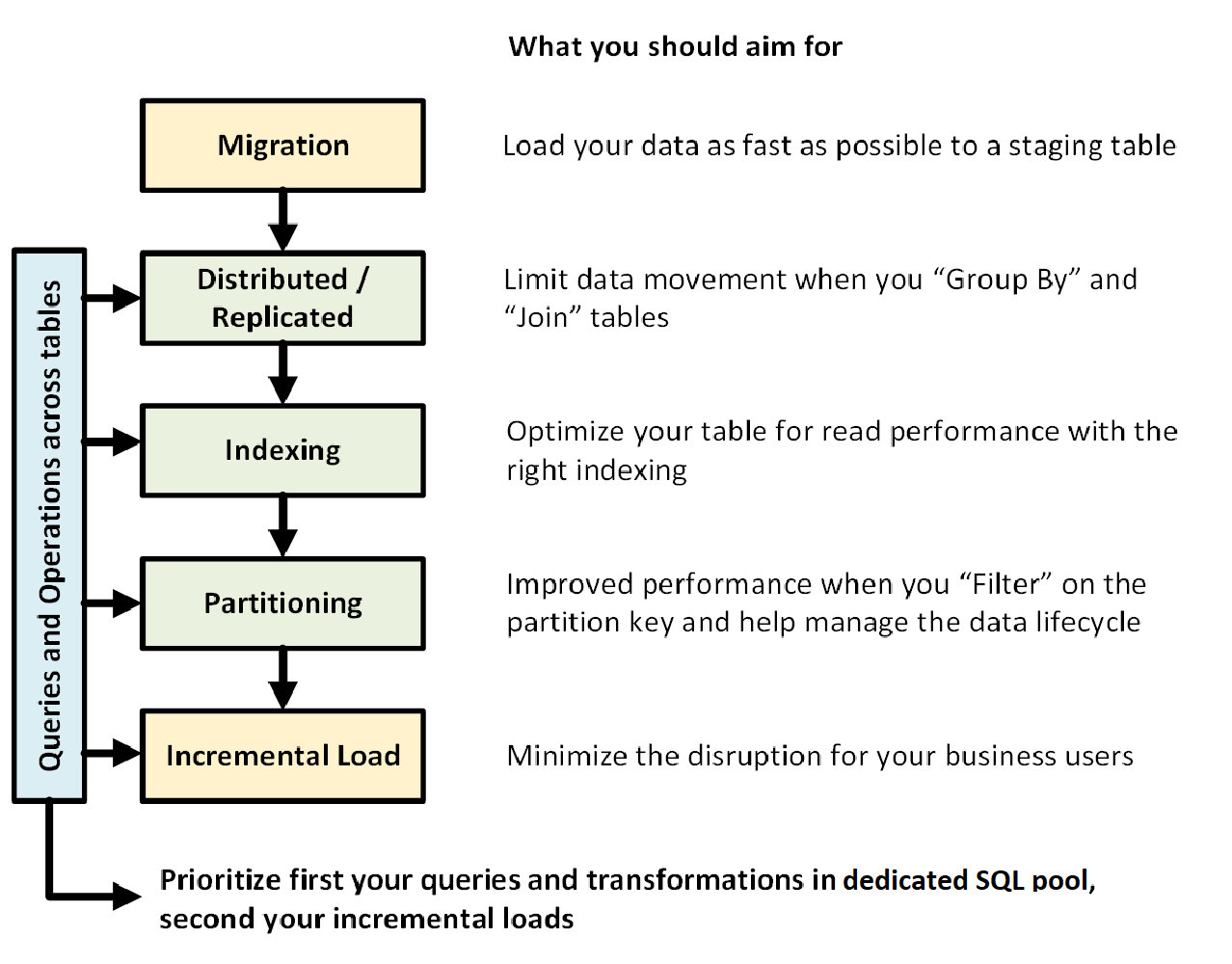
Frågor och åtgärder mellan tabeller
När du i förväg vet vilka primära åtgärder och frågor som ska köras i ditt informationslager kan du prioritera din informationslagerarkitektur för dessa åtgärder. Dessa frågor och åtgärder kan omfatta:
- Koppla en eller två faktatabeller med dimensionstabeller, filtrera den kombinerade tabellen och lägg sedan till resultaten i en data mart.
- Gör stora eller små förändringar i din faktabaserade försäljning.
- Lägger bara till data i dina tabeller.
Genom att känna till de olika typerna av åtgärder i förväg kan du optimera utformningen av dina tabeller.
Dataöverföring
Läs först in dina data i Azure Data Lake Storage eller Azure Blob Storage. Använd sedan COPY-instruktionen för att läsa in dina data i mellanlagringstabeller. Använd följande konfiguration:
| Utformning | Rekommendation |
|---|---|
| Fördelning | Rundtur |
| Indexering | Heap |
| Partitionering | Ingen |
| Resursklass | largerc eller xlargerc |
Läs mer om datamigrering, datainläsning och ELT-processen (Extract, Load och Transform).
Distribuerade eller replikerade tabeller
Använd följande strategier, beroende på tabellegenskaperna:
| Typ | Passar utmärkt för... | Se upp om... |
|---|---|---|
| Replikerade | * Små dimensionstabeller i ett star-schema med mindre än 2 GB lagringsutrymme efter komprimering (~5x komprimering) | * Många skrivtransaktioner finns i tabellen (till exempel insert, upsert, delete, update) * Du ändrar ofta konfigurationen av datalagerenheter (DWU) * Du använder bara 2–3 kolumner men tabellen har många kolumner * Du indexera en replikerad tabell |
| Rundgång (standard) | * Tillfällig/mellanlagringstabell * Ingen uppenbar kopplingsnyckel eller bra kandidatkolumn |
* Prestandan är långsam på grund av dataförflyttning |
| Hashfunktion | * Faktatabeller * Stora dimensionstabeller |
* Distributionsnyckeln kan inte uppdateras |
Tips:
- Börja med Round Robin, men sträva efter en hashdistributionsstrategi för att dra nytta av en massivt parallell arkitektur.
- Kontrollera att vanliga hash-nycklar har samma dataformat.
- Distribuera inte i varchar-format.
- Dimensionstabeller med en vanlig hash-nyckel till en faktatabell med frekventa kopplingsåtgärder kan hash-distribueras.
- Använd sys.dm_pdw_nodes_db_partition_stats för att analysera eventuell snedhet i data.
- Använd sys.dm_pdw_request_steps för att analysera dataförflyttningar bakom frågor, övervaka den tid sändningen tar och omfördelning av operationer. Det här är användbart för att granska distributionsstrategin.
Läs mer om replikerade tabeller och distribuerade tabeller.
Indexera tabellen
Indexering är användbart för att läsa tabeller snabbt. Det finns en unik uppsättning tekniker som du kan använda baserat på dina behov:
| Typ | Passar bra för... | Se upp om... |
|---|---|---|
| Heap | * Staging-tabell/tillfällig tabell * Små tabeller med små uppslag |
* Alla sökningar söker igenom hela tabellen |
| Klustrerad index | * Tabeller med upp till 100 miljoner rader * Stora tabeller (mer än 100 miljoner rader) med endast 1-2 kolumner som används mycket |
* Används i en replikerad tabell * Du har komplexa frågor som involverar flera join- och Group By-operationer * Du gör uppdateringar på de indexerade kolumnerna: det tar minne |
| Klustrat columnstore-index (CCI) (standardläge) | * Stora tabeller (mer än 100 miljoner rader) | * Används i en replikerad tabell * Du gör enorma uppdateringsåtgärder på din tabell * Överpartitionerar du tabellen: radgrupper sträcker sig inte över olika distributionsnoder och partitioner |
Tips:
- Ovanpå ett grupperat index kanske du vill lägga till ett icke-grupperat index i en kolumn som används för filtrering.
- Var försiktig med hur du hanterar minnet på en tabell med CCI. När du läser in data vill du att användaren (eller frågan) ska dra nytta av en stor resursklass. Undvik att trimma och skapa många små komprimerade radgrupper.
- På Gen2 cachelagras CCI-tabeller lokalt på beräkningsnoderna för att maximera prestanda.
- För CCI kan långsam prestanda inträffa på grund av dålig komprimering av dina radgrupper. Om detta inträffar kan du återskapa eller omorganisera din CCI. Du vill ha minst 100 000 rader per komprimerade radgrupper. Idealet är 1 miljon rader i en radgrupp.
- Baserat på inkrementell belastningsfrekvens och storlek vill du automatisera när du omorganiserar eller återskapar dina index. Vårstädning är alltid till hjälp.
- Var strategisk när du vill trimma en radgrupp. Hur stora är de öppna radgrupperna? Hur mycket data förväntar du dig att läsa in under de kommande dagarna?
Läs mer om index.
Partitionering
Du kan partitionera tabellen när du har en stor faktatabell (större än 1 miljard rader). I 99 procent av fallen bör partitionsnyckeln baseras på datum.
Med stegtabeller som kräver ELT kan du dra nytta av partitionering. Det underlättar datalivscykelhantering. Var noga med att inte överpartitionera din faktatabell eller din stagingtabell, särskilt om du använder ett grupperat kolumndatabasinex.
Läs mer om partitioner.
Stegvis inläsning
Om du ska läsa in dina data stegvis måste du först allokera större resursklasser för att läsa in dina data. Detta är särskilt viktigt när du läser in i tabeller med grupperade kolumnlagringsindex. Mer information finns i resursklasser .
Vi rekommenderar att du använder PolyBase och ADF V2 för att automatisera ELT-pipelines till ditt datavaruhus.
För en stor mängd uppdateringar i dina historiska data bör du överväga att använda en CTAS för att skriva de data som du vill behålla i en tabell i stället för att använda INSERT, UPDATE och DELETE.
Underhålla statistik
Det är viktigt att uppdatera statistiken när betydande ändringar sker i dina data. Se uppdatera statistik för att avgöra om betydande ändringar har inträffat. Uppdaterad statistik optimerar dina frågeplaner. Om du upptäcker att det tar för lång tid att behålla all statistik bör du vara mer selektiv när det gäller vilka kolumner som har statistik.
Du kan också definiera uppdateringsfrekvensen. Du kanske till exempel vill uppdatera datumkolumner, där nya värden kan läggas till dagligen. Du får mest nytta av att ha statistik över kolumner som ingår i kopplingar, kolumner som används i WHERE-satsen och kolumner som finns i GROUP BY.
Läs mer om statistik.
Resursklass
Resursgrupper används som ett sätt att allokera minne till frågor. Om du behöver mer minne för att förbättra fråge- eller inläsningshastigheten bör du allokera högre resursklasser. Å andra sidan har användningen av större resursklasser inverkan på samtidighet. Du vill ta hänsyn till detta innan du flyttar alla användare till en stor resursklass.
Om du märker att frågorna tar för lång tid, kontrollera att användarna inte kör sina frågor i stora resursklasser. Stora resursklasser förbrukar många samtidighetsslot. De kan leda till att andra förfrågningar ställer sig i kö.
Genom att använda Gen2 i en dedikerad SQL-pool (tidigare SQL DW) får varje resursklass 2,5 gånger mer minne än Gen1.
Lär dig mer om hur du arbetar med resursklasser och samtidighet.
Sänk din kostnad
En viktig funktion i Azure Synapse är möjligheten att hantera beräkningsresurser. Du kan pausa din dedikerade SQL-pool (tidigare SQL DW) när du inte använder den, vilket stoppar faktureringen av beräkningsresurser. Du kan skala resurser för att uppfylla dina prestandakrav. Om du vill pausa använder du Azure-portalen eller PowerShell. Om du vill skala använder du Azure-portalen, PowerShell, T-SQL eller ett REST-API.
Autoskalning nu när du vill med Azure Functions:

Optimera din arkitektur för prestanda
Vi rekommenderar att du överväger SQL Database och Azure Analysis Services i en hub-and-spoke-arkitektur. Den här lösningen kan ge arbetsbelastningsisolering mellan olika användargrupper samtidigt som du använder avancerade säkerhetsfunktioner från SQL Database och Azure Analysis Services. Det här är också ett sätt att ge användarna obegränsad samtidighet.
Läs mer om typiska arkitekturer som drar nytta av en dedikerad SQL-pool (tidigare SQL DW) i Azure Synapse Analytics.
Distribuera dina komponenter i SQL-databaser från en dedikerad SQL-pool (tidigare känd som SQL DW):