Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tip
Microsoft Fabric Data Warehouse är ett relationslager i företagsskala på en datasjögrund med en framtidsklar arkitektur, inbyggd AI och nya funktioner. Om du är nybörjare på datalager börjar du med Fabric Data Warehouse. Befintliga dedicerade SQL-poolarbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Den här artikeln innehåller rekommendationer för att utforma hash-distribuerade och round-robin distribuerade tabeller i dedikerade SQL-pooler.
Den här artikeln förutsätter att du är bekant med begreppen datadistribution och dataflytt i en dedikerad SQL-pool. Mer information finns i Azure Synapse Analytics-arkitektur.
Vad är en distribuerad tabell?
En distribuerad tabell visas som en enda tabell, men raderna lagras faktiskt i 60 distributioner. Raderna distribueras med en hash- eller omgångsvis algoritm.
Hash-distribution förbättrar frågeprestanda på stora faktatabeller och är i fokus för den här artikeln. Round-robin-fördelning är användbar för att förbättra inläsningshastigheten. De här designvalen har en betydande effekt på att förbättra fråge- och inläsningsprestanda.
Ett annat alternativ för tabelllagring är att replikera en liten tabell över alla beräkningsnoder. Mer information finns i Designvägledning för replikerade tabeller. Information om hur du snabbt väljer mellan de tre alternativen finns i Distribuerade tabeller i översikten över tabeller.
Som en del av tabelldesignen kan du förstå så mycket som möjligt om dina data och hur data efterfrågas. Tänk till exempel på följande frågor:
- Hur stor är tabellen?
- Hur ofta uppdateras tabellen?
- Har jag fakta- och dimensionstabeller i en dedikerad SQL-pool?
Hash distribuerad
En hash-distribuerad tabell distribuerar tabellrader över beräkningsnoderna med hjälp av en deterministisk hash-funktion för att tilldela varje rad till en distribution.
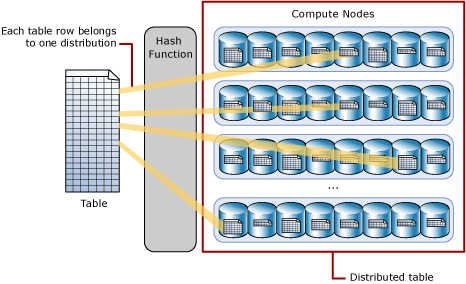
Eftersom identiska värden alltid hashas till samma distribution har SQL Analytics inbyggd kunskap om radernas placering. I den dedikerade SQL-poolen används den här kunskapen för att minimera dataflytt under frågor, vilket förbättrar frågeprestandan.
Hash-distribuerade tabeller fungerar bra för stora faktatabeller i ett stjärnschema. De kan ha ett mycket stort antal rader och ändå uppnå höga prestanda. Det finns några designöverväganden som hjälper dig att få den prestanda som det distribuerade systemet är utformat för att tillhandahålla. Att välja en bra distributionskolumn eller kolumner är ett sådant övervägande som beskrivs i den här artikeln.
Överväg att använda en hash-distribuerad tabell när:
- Tabellstorleken på disken är mer än 2 GB.
- Tabellen har frekventa åtgärder för att infoga, uppdatera och ta bort.
Round-robin distribuerad
En round-robin-distribuerad tabell fördelar tabellrader jämnt över alla distributioner. Tilldelningen av rader till distributioner är slumpmässig. Till skillnad från hash-distribuerade tabeller är rader med lika värden inte garanterade att tilldelas till samma distribution.
Därför måste systemet ibland anropa en dataförflyttningsåtgärd för att bättre organisera dina data innan den kan lösa en fråga. Det här extra steget kan göra dina sökfrågor långsammare. Om du till exempel ansluter till en rundrörelsetabell måste du vanligtvis omtilldela raderna, vilket påverkar prestandan.
Överväg att använda round-robin-distributionen för din tabell i följande scenarier.
- När du börjar, eftersom det är standard, kan du använda det som en enkel utgångspunkt.
- Om det inte finns någon uppenbar kopplingsnyckel
- Om det inte finns någon bra kandidatkolumn för hash-distribution av tabellen
- Om tabellen inte delar en gemensam kopplingsnyckel med andra tabeller
- Om kopplingen är mindre betydande än andra kopplingar i frågan
- När tabellen är en tillfällig mellanlagringstabell
Självstudien Läs in New York-taxidata ger ett exempel på hur du läser in data i en round-robin-mellanlagringstabell.
Välja en distributionskolumn
En hash-distribuerad tabell har en distributionskolumn eller uppsättning kolumner som är hash-nyckeln. Följande kod skapar till exempel en hash-distribuerad tabell med ProductKey som distributionskolumn.
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
);
Hash-distribution kan tillämpas på flera kolumner för en jämnare fördelning av bastabellen. Med distribution med flera kolumner kan du välja upp till åtta kolumner för distribution. Detta minskar inte bara datasnedvridningen över tid utan förbättrar även frågeprestanda. Till exempel:
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey], [OrderDateKey], [CustomerKey] , [PromotionKey])
);
Anteckning
Distribution med flera kolumner i Azure Synapse Analytics kan aktiveras genom att ändra databasens kompatibilitetsnivå till 50 med det här kommandot.
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50;Mer information om hur du ställer in databasens kompatibilitetsnivå finns i ALTER DATABASE SCOPED CONFIGURATION (ÄNDRA DATABASOMFATTNINGSKONFIGURATION). Mer information om distributioner med flera kolumner finns i SKAPA MATERIALISERAD VY, SKAPA TABELL eller SKAPA TABELL SOM SELECT.
Data som lagras i distributionskolumnerna kan uppdateras. Uppdateringar av data i distributionskolumner kan leda till en dataomfördelningsoperation.
Att välja distributionskolumner är ett viktigt designbeslut eftersom värdena i hash-kolumnerna avgör hur raderna distribueras. Det bästa valet beror på flera faktorer och innebär vanligtvis kompromisser. När du har valt en distributionskolumn eller kolumnuppsättning kan du inte ändra den. Om du inte valde de bästa kolumnerna första gången kan du använda CREATE TABLE AS SELECT (CTAS) för att återskapa tabellen med önskad distributionshashnyckel.
Välj en distributionskolumn med data som distribueras jämnt
För bästa prestanda bör alla distributioner ha ungefär samma antal rader. När en eller flera distributioner har ett oproportionerligt antal rader slutför vissa distributioner sin del av en parallell fråga före andra. Eftersom frågan inte kan slutföras förrän alla distributioner har slutfört bearbetningen är varje fråga bara lika snabb som den långsammaste distributionen.
- Dataförskjutning innebär att data inte fördelas jämnt över distributionerna
- Bearbetningsskevhet innebär att vissa distributioner tar längre tid än andra när parallelfrågor körs. Detta kan inträffa när data är skeva.
Om du vill balansera den parallella bearbetningen väljer du en distributionskolumn eller uppsättning kolumner som:
- Har många unika värden. En eller flera distributionskolumner kan ha duplicerade värden. Alla rader med samma värde tilldelas till samma distribution. Eftersom det finns 60 distributioner kan vissa distributioner ha > 1 unika värden medan andra kan sluta med nollvärden.
- Har inte NULL:er eller har bara några få NULL:er. I ett extremt exempel, om alla värden i distributionskolumnerna är NULL, tilldelas alla rader till samma distribution. Därför är frågebearbetningen snedfördelad mot en distribution och utnyttjar inte parallell bearbetning.
- Är inte en datumkolumn. Alla data för samma datum hamnar i samma distribution eller klustras efter datum. Om flera användare filtrerar på samma datum (till exempel dagens datum) utför endast 1 av de 60 distributionerna allt bearbetningsarbete.
Välj en distributionskolumn som minimerar dataflytten
För att få rätt frågeresultat kan frågor flytta data från en beräkningsnod till en annan. Dataflytt sker ofta när frågor har kopplingar och aggregeringar i distribuerade tabeller. Att välja en distributionskolumn eller kolumnuppsättning som hjälper till att minimera dataflytten är en av de viktigaste strategierna för att optimera prestanda för din dedikerade SQL-pool.
Om du vill minimera dataförflyttningen väljer du en distributionskolumn eller uppsättning kolumner som:
- Används i
JOIN,GROUP BY,DISTINCT,OVERochHAVING-satser. När två stora faktatabeller har frekventa kopplingar förbättras frågeprestandan när du distribuerar båda tabellerna på en av kopplingskolumnerna. När en tabell inte används i kopplingar kan du överväga att distribuera tabellen på en kolumn- eller kolumnuppsättning som ofta finns iGROUP BY-satsen. - Används inte i
WHEREsatser. När en frågas satsWHEREoch tabellens distributionskolumner finns i samma kolumn kan frågan stöta på hög datasnedvridning, vilket leder till att bearbetningsbelastningen bara faller på ett fåtal distributioner. Detta påverkar frågeprestanda, helst delar många distributioner bearbetningsbelastningen. - Är inte en datumkolumn.
WHEREsatser filtrerar ofta efter datum. När detta händer kan all bearbetning endast köras på några få distributioner som påverkar frågeprestanda. Helst delar många distributioner bearbetningsbelastningen.
När du har skapat en hash-distribuerad tabell är nästa steg att läsa in data i tabellen. För inläsningsvägledning, se Översikt över inläsning.
Så här ser du om distributionen är ett bra val
När data har lästs in i en hash-distribuerad tabell kontrollerar du hur jämnt raderna fördelas över de 60 distributionerna. Raderna per distribution kan variera upp till 10 % utan märkbar påverkan på prestanda.
Överväg följande sätt att utvärdera dina distributionskolumner.
Kontrollera om tabellen har datasnedvridning
Ett snabbt sätt att söka efter datasnedvridning är att använda DBCC-PDW_SHOWSPACEUSED. Följande SQL-kod returnerar antalet tabellrader som lagras i var och en av de 60 distributionerna. För balanserade prestanda bör raderna i den distribuerade tabellen fördelas jämnt över alla distributioner.
-- Find data skew for a distributed table
DBCC PDW_SHOWSPACEUSED('dbo.FactInternetSales');
Så här identifierar du vilka tabeller som har mer än 10 % datasnedvridning:
- Skapa den vy
dbo.vTableSizessom visas i översiktsartikeln Tabeller . - Kör följande fråga:
select *
from dbo.vTableSizes
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, row_count;
Kontrollera frågeplaner för dataflytt
Med en bra distributionskolumnuppsättning kan kopplingar och aggregeringar ha minimal dataförflyttning. Detta påverkar hur kopplingar ska skrivas. För att få minimal dataförflyttning för en koppling i två hash-distribuerade tabeller måste en av kopplingskolumnerna finnas i distributionskolumnen eller kolumnerna. När två hash-distribuerade tabeller kopplas till en distributionskolumn av samma datatyp kräver kopplingen inte dataflytt. Kopplingar kan använda ytterligare kolumner utan att medföra dataförflyttning.
Så här undviker du dataförflyttning under en koppling:
- Tabellerna som ingår i kopplingen måste vara hash-distribuerade på en av kolumnerna som deltar i kopplingen.
- Datatyperna för kopplingskolumnerna måste matcha mellan båda tabellerna.
- Kolumnerna måste förenas med en likhetsoperator.
- Kopplingstypen får inte vara en
CROSS JOIN.
Om du vill se om frågor upplever dataförflyttning kan du titta på frågeplanen.
Lösa ett problem med distributionskolumnen
Det är inte nödvändigt att lösa alla fall av datasnedvridning. Att distribuera data handlar om att hitta rätt balans mellan att minimera datasnedvridning och dataförflyttning. Det är inte alltid möjligt att minimera både dataförskjutning och dataförflyttning. Ibland kan fördelen med att ha minimal dataförflyttning uppväga effekten av att ha datasnedvridning.
För att avgöra om du ska lösa datasnedvridning i en tabell bör du förstå så mycket som möjligt om datavolymerna och frågorna i din arbetsbelastning. Du kan använda stegen i artikeln Frågeövervakning för att övervaka effekten av skevhet på frågeprestanda. Specifikt, undersök hur lång tid det tar för stora förfrågningar att bearbetas på enskilda datafördelningar.
Eftersom du inte kan ändra distributionskolumnerna i en befintlig tabell är det vanliga sättet att lösa datasnedvridning att återskapa tabellen med olika distributionskolumner.
Återskapa tabellen med en ny distributionskolumnuppsättning
I det här exemplet används CREATE TABLE AS SELECT för att återskapa en tabell med olika hashdistributionskolumner.
Använd först CREATE TABLE AS SELECT den nya tabellen (CTAS) med den nya nyckeln. Skapa sedan statistiken igen och växla sedan tabellerna genom att byta namn på dem.
CREATE TABLE [dbo].[FactInternetSales_CustomerKey]
WITH ( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([CustomerKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES ( 20000101, 20010101, 20020101, 20030101
, 20040101, 20050101, 20060101, 20070101
, 20080101, 20090101, 20100101, 20110101
, 20120101, 20130101, 20140101, 20150101
, 20160101, 20170101, 20180101, 20190101
, 20200101, 20210101, 20220101, 20230101
, 20240101, 20250101, 20260101, 20270101
, 20280101, 20290101
)
)
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
OPTION (LABEL = 'CTAS : FactInternetSales_CustomerKey')
;
--Create statistics on new table
CREATE STATISTICS [ProductKey] ON [FactInternetSales_CustomerKey] ([ProductKey]);
CREATE STATISTICS [OrderDateKey] ON [FactInternetSales_CustomerKey] ([OrderDateKey]);
CREATE STATISTICS [CustomerKey] ON [FactInternetSales_CustomerKey] ([CustomerKey]);
CREATE STATISTICS [PromotionKey] ON [FactInternetSales_CustomerKey] ([PromotionKey]);
CREATE STATISTICS [SalesOrderNumber] ON [FactInternetSales_CustomerKey] ([SalesOrderNumber]);
CREATE STATISTICS [OrderQuantity] ON [FactInternetSales_CustomerKey] ([OrderQuantity]);
CREATE STATISTICS [UnitPrice] ON [FactInternetSales_CustomerKey] ([UnitPrice]);
CREATE STATISTICS [SalesAmount] ON [FactInternetSales_CustomerKey] ([SalesAmount]);
--Rename the tables
RENAME OBJECT [dbo].[FactInternetSales] TO [FactInternetSales_ProductKey];
RENAME OBJECT [dbo].[FactInternetSales_CustomerKey] TO [FactInternetSales];
Relaterat innehåll
Om du vill skapa en distribuerad tabell använder du någon av följande instruktioner: