Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tips
Microsoft Fabric Data Warehouse är ett relationslager i företagsskala på en datasjögrund med en framtidsklar arkitektur, inbyggd AI och nya funktioner. Om du är nybörjare på datalager börjar du med Fabric Data Warehouse. Befintliga dedicerade SQL-poolarbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Med OPENROWSET(BULK...) funktionen kan du komma åt filer i Azure Storage.
OPENROWSET funktionen läser innehållet i en fjärrdatakälla (till exempel en fil) och returnerar innehållet som en uppsättning rader. I den serverlösa SQL-poolresursen nås OPENROWSET-massraderuppsättningsprovidern genom att anropa funktionen OPENROWSET och ange alternativet BULK.
Funktionen OPENROWSET kan refereras till i klausulen FROM i en fråga som om det vore ett tabellnamn OPENROWSET. Den stöder massåtgärder via en inbyggd BULK-provider som gör att data från en fil kan läsas och returneras som en raduppsättning.
Anteckning
Funktionen OPENROWSET stöds inte i en dedikerad SQL-pool.
Datakälla
Funktionen OPENROWSET i Synapse SQL läser innehållet i filerna från en datakälla. Datakällan är ett Azure-lagringskonto och kan uttryckligen refereras till i funktionen OPENROWSET eller härledas dynamiskt från URL-adressen för de filer som du vill läsa.
Funktionen OPENROWSET kan också innehålla en DATA_SOURCE parameter för att ange den datakälla som innehåller filer.
OPENROWSETutanDATA_SOURCEkan användas för att direkt läsa innehållet i filerna från den URL-plats som anges somBULKalternativ:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Det här är ett snabbt och enkelt sätt att läsa innehållet i filerna utan förkonfiguration. Med det här alternativet kan du använda det grundläggande autentiseringsalternativet för att komma åt lagringen (Microsoft Entra-genomströmning för Microsoft Entra-inloggningar och SAS-token för SQL-inloggningar).
OPENROWSETmedDATA_SOURCEkan användas för att komma åt filer på ett angivet lagringskonto:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Med det här alternativet kan du konfigurera lagringskontots plats i datakällan och ange den autentiseringsmetod som ska användas för åtkomst till lagring.
Viktigt!
OPENROWSETutanDATA_SOURCEger ett snabbt och enkelt sätt att komma åt lagringsfilerna men erbjuder begränsade autentiseringsalternativ. Microsoft Entra-huvudprinciper kan till exempel bara komma åt filer med hjälp av sin Microsoft Entra-identitet eller offentligt tillgängliga filer. Om du behöver mer kraftfulla autentiseringsalternativ använderDATA_SOURCEdu alternativet och definierar autentiseringsuppgifter som du vill använda för att få åtkomst till lagring.
Säkerhet
En databasanvändare måste ha ADMINISTER BULK OPERATIONS behörighet att använda OPENROWSET funktionen.
Lagringsadministratören måste också göra det möjligt för en användare att komma åt filerna genom att tillhandahålla en giltig SAS-token eller aktivera Microsoft Entra-huvudkontot för åtkomst till lagringsfiler. Läs mer om åtkomstkontroll för lagring i den här artikeln.
OPENROWSET använd följande regler för att avgöra hur du autentiserar till lagring:
- I
OPENROWSETutanDATA_SOURCEberor autentiseringsmekanismen på anropartyp.- Alla användare kan använda
OPENROWSETutanDATA_SOURCEatt läsa offentligt tillgängliga filer på Azure Storage. - Microsoft Entra-inloggningar kan komma åt skyddade filer med sin egen Microsoft Entra-identitet om Azure Storage tillåter Microsoft Entra-användaren att komma åt underliggande filer (till exempel om anroparen har
Storage Readerbehörighet på Azure Storage). - SQL-inloggningar kan också använda
OPENROWSETutanDATA_SOURCEför att få åtkomst till offentligt tillgängliga filer, filer som skyddas med SAS-token, eller hanterad identitet för Synapse-arbetsytan. Du skulle behöva skapa autentiseringsuppgifter med serveromfattning för att tillåta åtkomst till lagringsfiler.
- Alla användare kan använda
- I
OPENROWSETmedDATA_SOURCEdefinieras autentiseringsmekanismen i en databasomfattande referens tilldelad den refererade datakällan. Med den här funktionen kan du komma åt offentligt tillgänglig lagring eller få tillgång till lagring med hjälp av SAS-token, Hanterad Identitet för arbetsytan eller Microsoft Entra-identitet för anroparen (om anroparen är en Microsoft Entra-principal). OmDATA_SOURCErefererar till Azure Storage som inte är offentligt måste du skapa en databasspecifik referens och hänvisa till den i för att tillåta åtkomst till lagringsfiler.
Anroparen måste ha REFERENCES behörighet för autentiseringsuppgifter för att kunna använda den för att autentisera till lagring.
Syntax
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumenten
Du har tre alternativ för indatafiler som innehåller måldata för frågor. Giltiga värden är:
"CSV" – Innehåller alla avgränsade textfiler med rad-/kolumnavgränsare. Alla tecken kan användas som fältavgränsare, till exempel TSV: FIELDTERMINATOR = tab.
PARQUET – binär fil i Parquet-format.
"DELTA" – En uppsättning Parquet-filer ordnade i Delta Lake-format (förhandsversion).
Värden med mellanslag är inte giltiga. Till exempel är "CSV" inte ett giltigt värde.
"unstructured_data_path"
Den unstructured_data_path som upprättar en sökväg till data kan vara en absolut eller relativ sökväg:
- Absolut sökväg i formatet
\<prefix>://\<storage_account_path>/\<storage_path>gör det möjligt för en användare att läsa filerna direkt. - Relativ sökväg i det format
<storage_path>som måste användas med parameternDATA_SOURCEoch beskriver filmönstret inom den <storage_account_path> plats som definieras iEXTERNAL DATA SOURCE.
Nedan hittar du relevanta <värden för sökvägen till lagringskontot> som länkar till din specifika externa datakälla.
| Extern datakälla | Prefix | Sökväg för lagringskonto |
|---|---|---|
| Azure Blob Storage | http[s] | < >storage_account.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | < >storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | < >storage_account.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name>.dfs.core.windows.net/path/file |
<lagringsväg>
Anger en sökväg i lagringen som pekar på den mapp eller fil som du vill läsa. Om sökvägen pekar på en container eller mapp kommer alla filer att läsas från den aktuella containern eller mappen. Filer i undermappar inkluderas inte.
Du kan använda jokertecken för att rikta in dig på flera filer eller mappar. Användning av flera icke-konsekutiva jokertecken tillåts.
Nedan visas ett exempel som läser alla csv-filer som börjar med populationen från alla mappar som börjar med /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Om du anger unstructured_data_path som en mapp hämtar en serverlös SQL-poolfråga filer från den mappen.
Du kan instruera serverlös SQL-pool att bläddra i mappar genom att ange /* i slutet av sökvägen som i exempel: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Anteckning
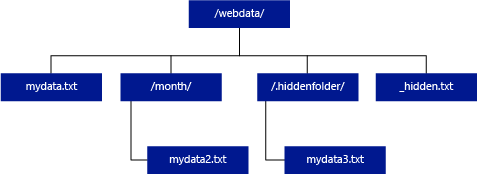
Till skillnad från Hadoop och PolyBase returnerar inte serverlös SQL-pool undermappar om du inte anger /** i slutet av sökvägen. Precis som Hadoop och PolyBase returneras inte filer för vilka filnamnet börjar med en understrykning (_) eller en punkt (.).
I exemplet nedan returnerar en serverlös SQL-poolfråga rader från mydata.txt om unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/. Den returnerar inte mydata2.txt och mydata3.txt eftersom de finns i en undermapp.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
Med WITH-satsen kan du ange kolumner som du vill läsa från filer.
För CSV-datafiler anger du kolumnnamn och deras datatyper för att läsa alla kolumner. Om du vill ha en delmängd av kolumner kan du använda ordningstal för att välja kolumner från de ursprungliga datafilerna. Kolumner kommer att bindas av ordningstalsbeteckningen. Om HEADER_ROW = TRUE används utförs kolumnbindningen efter kolumnnamn i stället för ordningstalsposition.
Tips
Du kan utelämna WITH-satsen för CSV-filer också. Datatyper kommer automatiskt att härledas från filinnehåll. Du kan använda HEADER_ROW argument för att ange förekomsten av rubrikrad i vilket fall kolumnnamn ska läsas från rubrikraden. Mer information finns i automatisk schemaidentifiering.
För Parquet- eller Delta Lake-filer anger du kolumnnamn som matchar kolumnnamnen i de ursprungliga datafilerna. Kolumner kopplas efter namn och är skiftlägeskänsliga. Om WITH-satsen utelämnas returneras alla kolumner från Parquet-filer.
Viktigt!
Kolumnnamn i Parquet- och Delta Lake-filer är skiftlägeskänsliga. Om du anger kolumnnamn med ett annat hölje än kolumnnamnshöljet i filerna
NULLreturneras värdena för den kolumnen.
column_name = Namn på utdatakolumnen. Om det här namnet anges åsidosätter det kolumnnamnet i källfilen och kolumnnamnet som anges i JSON-sökvägen om det finns en. Om json_path inte anges läggs den automatiskt till som $.column_name. Kontrollera json_path argument för beteende.
column_type = Datatyp för utdatakolumnen. Den implicita datatypkonverteringen sker här.
column_ordinal = ordinalt nummer för kolumnen i källfil(er). Det här argumentet ignoreras för Parquet-filer eftersom bindningen görs med namn. I följande exempel returneras endast en andra kolumn från en CSV-fil:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = JSON-sökvägsuttryck till egenskaper i en kolumn eller inbäddad egenskap. Standardsökvägsläget är slappt.
Anteckning
I strikt läge misslyckas frågan med fel om den angivna sökvägen inte finns. I slappt läge kommer frågan att lyckas och JSON-sökvägsuttrycket utvärderas till NULL.
<bulk_options>
FÄLTTERMINATOR ='field_terminator'
Anger den fältavgränsare som ska användas. Standardfältavslutaren är ett kommatecken (",").
ROWTERMINATOR ='row_terminator'
Anger radavgränsaren som ska användas. Om radavgränsaren inte har angetts används en av standardavgränsarna. Standardavgränsare för PARSER_VERSION = "1.0" är \r\n, \n och \r. Standardavgränsare för PARSER_VERSION = "2.0" är \r\n och \n.
Anteckning
När du använder PARSER_VERSION='1.0' och anger \n (ny rad) som radavgränsare, prefixeras den automatiskt med ett \r-tecken (vagnretur), vilket resulterar i en radavgränsare av \r\n.
ESCAPE_CHAR = "char"
Anger tecknet i filen som används för att undkomma sig själv och alla avgränsarvärden i filen. Om escape-tecknet följs av ett annat värde än sig självt, eller något av avgränsarvärdena, tas escape-tecknet bort när värdet läss.
ESCAPECHAR-parametern tillämpas oavsett om FIELDQUOTE är aktiverat eller inte. Den kommer inte att användas för att undkomma citattecknet. Citattecknet måste undanröjas med ett annat citattecken. Citattecken kan endast visas inom kolumnvärdet om värdet kapslas in med citattecken.
FIRSTROW = "first_row"
Anger numret på den första raden som ska läsas in. Standardvärdet är 1 och anger den första raden i den angivna datafilen. Radnumren bestäms genom att radavslutarna räknas. FIRSTROW är 1-baserad.
FIELDQUOTE = "field_quote"
Anger ett tecken som ska användas som citattecken i CSV-filen. Om det inte anges används citattecknet (").
DATA_COMPRESSION = "data_compression_method"
Anger den komprimeringsmetoden. Stöds endast i PARSER_VERSION='1.0'. Följande komprimeringsmetod stöds:
- GZIP
PARSER_VERSION = "parser_version"
Anger den parserversion som ska användas vid läsning av filer. CSV-parserversioner som stöds för närvarande är 1.0 och 2.0:
- PARSER_VERSION = "1.0"
- PARSER_VERSION = "2.0"
CSV-parser version 1.0 är standard och funktionsrik. Version 2.0 är byggd för prestanda och stöder inte alla alternativ och kodningar.
CSV-parser version 1.0- detaljer:
- Följande alternativ stöds inte: HEADER_ROW.
- Standardterminatorer är \r\n, \n och \r.
- Om du anger \n (ny rad) som radavgränsare prefixeras den automatiskt med ett \r-tecken (vagnretur), vilket resulterar i en radavgränsare av \r\n.
CSV-parser version 2.0- detaljer:
- Alla datatyper stöds inte.
- Maximal kolumnlängd är 8 000.
- Maximal radstorleksgräns är 8 MB.
- Följande alternativ stöds inte: DATA_COMPRESSION.
- Den citerade tomma strängen ("") tolkas som en tom sträng.
- Alternativet DATEFORMAT SET bekräftas inte.
- Format som stöds för DATE-datatyp: ÅÅÅÅ-MM-DD
- Format som stöds för TIME-datatyp: HH:MM:SS[.fractional seconds]
- Format som stöds för den DATETIME2-datatyp: ÅÅÅÅ-MM-DD HH:MM:SS[.bråkdelar av sekunder]
- Standardavslutare är \r\n och \n.
HEADER_ROW = { SANT | FALSE }
Anger om en CSV-fil innehåller rubrikrad. Standardvärdet stöds FALSE. i PARSER_VERSION='2.0'. Om värdet är SANT läss kolumnnamnen från den första raden enligt argumentet FIRSTROW. Om TRUE och schema anges med HJÄLP av WITH utförs bindningen av kolumnnamn efter kolumnnamn, inte ordningstalspositioner.
DATAFILETYPE = { 'char' | "widechar" }
Anger kodning: char används för UTF8, widechar används för UTF16-filer.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Anger kodsidan för data i datafilen. Standardvärdet är 65001 (UTF-8-kodning). Mer information om det här alternativet finns här.
ROWSET_OPTIONS = {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Det här alternativet inaktiverar filändringskontrollen under frågekörningen och läser filerna som uppdateras medan frågan körs. Det här är ett användbart alternativ när du behöver läsa append-only-filer som kontinuerligt fylls på medan frågan körs. I de tilläggsbara filerna uppdateras inte det befintliga innehållet och endast nya rader läggs till. Därför minimeras sannolikheten för felaktiga resultat jämfört med de uppdateringsbara filerna. Det här alternativet kan göra att du kan läsa de filer som ofta läggs till utan att hantera felen. Mer information finns i avsnittet om att fråga mot tilläggbara CSV-filer.
Avvisa alternativ
Anteckning
Funktionen Avvisade rader finns i offentlig förhandsversion. Observera att funktionen avvisade rader fungerar för avgränsade textfiler och PARSER_VERSION 1.0.
Du kan ange parametrar för avvisande som avgör hur tjänsten ska hantera felaktiga poster som den hämtar från den externa datakällan. En datapost anses vara "smutsig" om faktiska datatyper inte matchar kolumndefinitionerna för den externa tabellen.
När du inte anger eller ändrar alternativ för avvisande använder tjänsten standardvärden. Tjänsten använder alternativen för att avvisa för att fastställa antalet rader som kan avvisas innan den faktiska frågan misslyckas. Frågan returnerar (partiella) resultat tills tröskelvärdet för avvisande överskrids. Det misslyckas med att ge ett lämpligt felmeddelande.
MAXERRORS = reject_value
Anger antalet rader som kan avvisas innan frågan misslyckas. MAXERRORS måste vara ett heltal mellan 0 och 2 147 483 647.
ERRORFILE_DATA_SOURCE = datakälla
Anger datakällan där avvisade rader och motsvarande felfil ska skrivas.
ERRORFILE_LOCATION = Katalogplats
Anger katalogen i DATA_SOURCE eller, om den har angetts, ERROR_FILE_DATASOURCE, där de avvisade raderna och motsvarande felfil ska skrivas. Om den angivna sökvägen inte finns skapar tjänsten en för din räkning. En underordnad katalog skapas med namnet "rejectedrows". Tecknet "" säkerställer att katalogen är undantagen för annan databehandling om den inte uttryckligen namnges i platsparametern. I den här mappen finns det en mapp som skapats baserat på inläsningstiden i formatet YearMonthDay_HourMinuteSecond_StatementID (till exempel 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Du kan använda instruktions-ID för att korrelera mappen med frågan som genererade den. I den här mappen skrivs två filer: error.json-filen och datafilen.
error.json fil innehåller json-matris med fel som rör avvisade rader. Varje element som representerar fel innehåller följande attribut:
| Attribut | beskrivning |
|---|---|
| Fel | Orsak till varför raden avvisas. |
| Rad | Avvisat radordningsnummer i filen. |
| Kolumn | Avvisat kolumnordningsnummer. |
| Värde | Avvisat kolumnvärde. Om värdet är större än 100 tecken visas endast de första 100 tecknen. |
| Fil | Sökväg till filen som raden tillhör. |
Snabb avgränsad textparsning
Det finns två avgränsade textparser-versioner som du kan använda. CSV-parser version 1.0 är standard och funktionsrik medan parser version 2.0 är byggd för prestanda. Prestandaförbättringar i parser 2.0 kommer från avancerade parsningstekniker och multitrådning. Skillnaden i hastighet blir större när filstorleken växer.
Automatisk schemaupptäckt
Du kan enkelt köra frågor mot både CSV- och Parquet-filer utan att känna till eller ange schema genom att utelämna WITH-satsen. Kolumnnamn och datatyper härleds från filer.
Parquet-filer innehåller kolumnmetadata, som kommer att läsas, typmappningar finns i typmappningar för Parquet. Kontrollera läsningen av Parquet-filer utan att ange schema för exempel.
För CSV-filerna kan kolumnnamn läsas från rubrikraden. Du kan ange om rubrikraden finns med hjälp av HEADER_ROW argument. Om HEADER_ROW = FALSE används allmänna kolumnnamn: C1, C2, ... Cn där n är antalet kolumner i filen. Datatyper härleds från de första 100 dataraderna. Kontrollera läsningen av CSV-filer utan att ange schema för exempel.
Tänk på att om du läser flera filer samtidigt, kommer schemat att härledas från den första filen som tjänsten hämtar från lagringsenheten. Det kan innebära att vissa av de förväntade kolumnerna utelämnas, allt eftersom filen som används av tjänsten för att definiera schemat inte innehöll dessa kolumner. I så fall använder du OPENROWSET WITH-satsen.
Viktigt!
Det finns fall då lämplig datatyp inte kan härledas på grund av brist på information och större datatyp används i stället. Detta medför prestandaomkostnader och är särskilt viktigt för teckenkolumner som härleds som varchar(8000). För att uppnå optimal prestanda, kontrollera härledda datatyper och använd lämpliga datatyper.
Typmappning för Parquet
Parquet- och Delta Lake-filer innehåller typbeskrivningar för varje kolumn. I följande tabell beskrivs hur Parquet-typer mappas till inbyggda SQL-typer.
| Parquet-typ | Parquet logisk datatyp (anteckning) | SQL-datatyp |
|---|---|---|
| BOOLEAN | liten bit | |
| BINÄR / BYTE_ARRAY | varbinary | |
| DUBBEL | flyttal | |
| FLYT | verklig | |
| INT32 | heltal | |
| INT64 | bigint | |
| INT96 | datumtid2 | |
| FIXED_LEN_BYTE_ARRAY | binär | |
| BINÄR | UTF8 | varchar *(UTF8-collation) |
| BINÄR | STRÄNG | varchar *(UTF8-collation) |
| BINÄR | ENUM | varchar *(UTF8-collation) |
| FIXED_LEN_BYTE_ARRAY | UUID (universellt unik identifierare) | unik identifierare |
| BINÄR | DECIMAL | decimal |
| BINÄR | JSON | varchar(8000) *(UTF8-collation) |
| BINÄR | BSON | Stöds inte |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | decimal |
| BYTE_ARRAY | INTERVALL | Stöds inte |
| INT32 | INT(8, sant) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, sant) | heltal |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | heltal |
| INT32 | INT(32, false) | bigint |
| INT32 | DATUM | datum |
| INT32 | DECIMAL | decimal |
| INT32 | TIME (MILLIS) | tid |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, falskt) | decimal(20,0) |
| INT64 | DECIMAL | decimal |
| INT64 | TID (MIKROSEKUNDER) | tid |
| INT64 | TID (NANOSEKUNDER) | Stöds inte |
| INT64 | TIDSSTÄMPEL (normaliserad till UTC) (MILLIS / MICROS) | datumtid2 |
| INT64 | TIDSSTÄMPEL (ej normaliserad till UTC) (MILLIS/MICROS) | bigint – se till att du uttryckligen justerar bigint värdet med tidszonsförskjutningen innan du konverterar det till ett datetime-värde. |
| INT64 | TIDSSTÄMPEL (NANOSEKUNDER) | Stöds inte |
| Komplex typ | LISTA | varchar(8000), serialiserad till JSON |
| Komplex typ | KARTA | varchar(8000), serialiserad till JSON |
Exempel
Läsa CSV-filer utan att ange schema
I följande exempel läss CSV-filen som innehåller rubrikraden utan att ange kolumnnamn och datatyper:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Följande exempel läser CSV-filen som inte innehåller rubrikrad utan att ange kolumnnamn och datatyper:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Läsa Parquet-filer utan att ange schema
I följande exempel returneras alla kolumner i den första raden från censusdatauppsättningen i Parquet-format och utan att ange kolumnnamn och datatyper:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Läsa Delta Lake-filer utan att ange schema
I följande exempel returneras alla kolumner i den första raden från censusdatauppsättningen, i Delta Lake-format, och utan att ange kolumnnamn och datatyper:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Läsa specifika kolumner från CSV-fil
I följande exempel returneras endast två kolumner med ordningstalen 1 och 4 från populationen*.csv filer. Eftersom det inte finns någon rubrikrad i filerna börjar den läsa från den första raden:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Läs specifika kolumner från Parquet-filen
I följande exempel returneras endast två kolumner i den första raden från censusdatauppsättningen i Parquet-format:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Ange kolumner med JSON-sökvägar
I följande exempel visas hur du kan använda JSON-sökvägsuttryck i WITH-satsen och visar skillnaden mellan strikta och släpphänta sökvägslägen:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Ange flera filer/mappar i BULK-sökvägen
I följande exempel visas hur du kan använda flera fil-/mappsökvägar i BULK-parametern:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Nästa steg
Fler exempel finns i snabbstarten för frågedatalagring för att lära dig hur du använder OPENROWSET för att läsa FILformaten CSV, PARQUET, DELTA LAKE och JSON. Kontrollera metodtipsen för att uppnå optimala prestanda. Du kan också lära dig hur du sparar resultatet av din fråga i Azure Storage med hjälp av CETAS.