Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här artikeln får du lära dig hur du skriver en fråga med hjälp av en serverlös Synapse SQL-pool för att läsa Delta Lake-filer. Delta Lake är ett lagringslager med öppen källkod som ger ACID-transaktioner (atomicitet, konsekvens, isolering och hållbarhet) till Apache Spark- och stordataarbetsbelastningar. Du kan lära dig mer genom videon om hur du ställer frågor till Delta Lake-tabeller.
Viktigt!
De serverlösa SQL-poolerna kan fråga Delta Lake version 1.0. De ändringar som har införts sedan Delta Lake 1.2-versionen (som att byta namn på kolumner) stöds inte i serverlösa. Om du använder de högre versionerna av Delta med borttagningsvektorer, v2-kontrollpunkter och andra bör du överväga att använda en annan frågemotor som Microsoft Fabric SQL-slutpunkten för Lakehouses.
Med den serverlösa SQL-poolen i Synapse-arbetsytan kan du läsa data som lagras i Delta Lake-format och hantera dem i rapporteringsverktyg. En serverlös SQL-pool kan läsa Delta Lake-filer som skapas med Apache Spark, Azure Databricks eller någon annan producent av Delta Lake-formatet.
Med Apache Spark-pooler i Azure Synapse kan datatekniker ändra Delta Lake-filer med Scala, PySpark och .NET. Serverlösa SQL-pooler hjälper dataanalytiker att skapa rapporter om Delta Lake-filer som skapats av datatekniker.
Viktigt!
Att köra frågor mot Delta Lake-format med hjälp av den serverlösa SQL-poolen är allmänt tillgänglig funktionalitet. Att köra frågor mot Spark Delta-tabeller är dock fortfarande i öppen förhandsversion och inte färdigt för produktion. Det finns kända problem som kan inträffa om du ställer frågor mot Deltatabeller som skapats i Sparkpoolerna. Se kända problem i självhjälp för serverlös SQL-pool.
Förutsättningar
Viktigt!
Datakällor kan bara skapas i anpassade databaser (inte i huvuddatabasen eller databaser som replikeras från Apache Spark-pooler).
Om du vill använda exemplen i den här artikeln måste du utföra följande steg:
- Skapa en databas med en datakälla som refererar till NYC Yellow Taxi Storage-kontot.
- Initiera objekten genom att köra installationsskriptet på databasen som du skapade i steg 1. Det här installationsskriptet skapar datakällor, databasomfattningsautentiseringsuppgifter och externa filformat som används i dessa exempel.
Om du har skapat databasen och växlat kontexten till databasen (med hjälp av USE database_name instruktionen eller listrutan för att välja databas i någon frågeredigerare) kan du skapa en extern datakälla som innehåller rot-URI:n till din datauppsättning och använda den för att köra frågor mot Delta Lake-filer. Till exempel:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Om en datakälla skyddas med SAS-nyckel eller anpassad identitet kan du konfigurera datakällan med databasomfångsbegränsade autentiseringsuppgifter.
Du kan skapa en extern datakälla med den plats som pekar på lagringens rotmapp. När du har skapat den externa datakällan använder du datakällan och den relativa sökvägen till filen i OPENROWSET funktionen. På så sätt behöver du inte använda den fullständiga absoluta URI:n för dina filer. Du kan också definiera anpassade autentiseringsuppgifter för åtkomst till lagringsplatsen.
Läs mappen Delta Lake
Viktigt!
Använd installationsskriptet i förhandskraven för att konfigurera exempeldatakällorna och tabellerna.
Med funktionen OPENROWSET kan du läsa innehållet i Delta Lake-filer genom att ange URL:en till rotmappen.
Det enklaste sättet att se till innehållet i din DELTA-fil är att ange filens URL till funktionen OPENROWSET och specificera DELTA format. Om filen är offentligt tillgänglig eller om din Microsoft Entra-identitet kan komma åt den här filen bör du kunna se innehållet i filen med hjälp av en fråga som den som visas i följande exempel:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Kolumnnamn och datatyper läses automatiskt från Delta Lake-filer. Funktionen OPENROWSET använder bästa gissningstyper som VARCHAR(1000) för strängkolumnerna.
URI:n i OPENROWSET funktionen måste referera till rotmappen Delta Lake som innehåller en undermapp med namnet _delta_log.
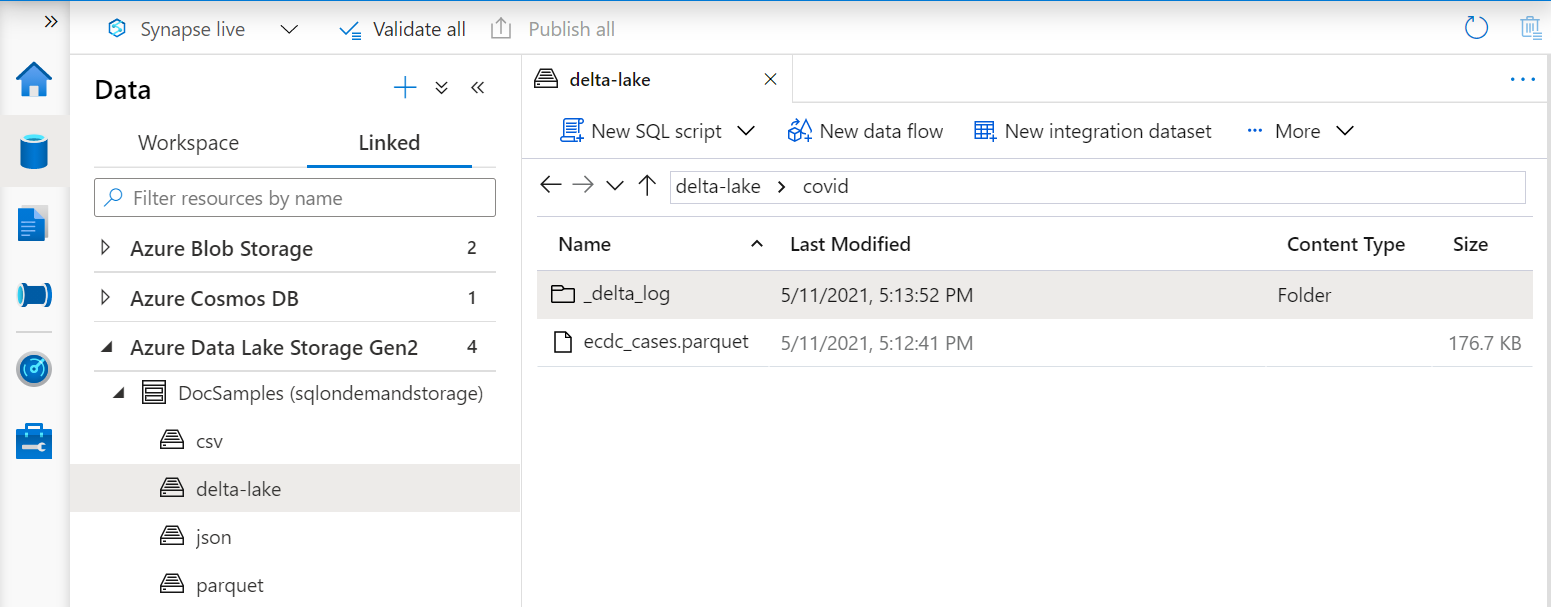
Om du inte har den här undermappen använder du inte Delta Lake-format. Du kan konvertera dina vanliga Parquet-filer i mappen till Delta Lake-format med hjälp av ett skript som i följande exempel apache Spark Python-skript:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Om du vill förbättra prestandan för dina frågor kan du överväga att ange explicita typer i WITH -satsen.
Kommentar
Den serverlösa Synapse SQL-poolen använder schemainferens för att automatiskt fastställa kolumner och deras typer. Reglerna för schemainferens är samma som används för Parquet-filer. För typmappning från Delta Lake till SQL:s inbyggda typ, kontrollera typmappning för Parquet.
Kontrollera att du har åtkomst till filen. Om filen är skyddad med SAS-nyckel eller anpassad Azure-identitet måste du konfigurera en autentiseringsuppgift på servernivå för sql-inloggning.
Viktigt!
Kontrollera att du använder en UTF-8-databassortering (till exempel Latin1_General_100_BIN2_UTF8) eftersom strängvärden i Delta Lake-filer kodas med UTF-8-kodning.
Ett matchningsfel mellan textkodningen i Delta Lake-filen och sorteringen kan orsaka oväntade konverteringsfel.
Du kan enkelt ändra standardsortering av den aktuella databasen med hjälp av följande T-SQL-instruktion:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Mer information om sortering finns i Sorteringstyper som stöds för Synapse SQL.
Ange uttryckligen schema
OPENROWSET gör att du uttryckligen kan ange vilka kolumner du vill läsa från filen med hjälp av WITH -satsen:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Med den explicita specifikationen för resultatuppsättningsschemat kan du minimera typstorlekarna och använda de mer exakta typerna VARCHAR(6) för strängkolumner i stället för pessimistisk VARCHAR(1000). Minimering av typer kan avsevärt förbättra prestanda för dina frågor.
Viktigt!
Kontrollera att du uttryckligen anger en UTF-8-sortering (till exempel Latin1_General_100_BIN2_UTF8) för alla strängkolumner i WITH -satsen eller ange en UTF-8-sortering på databasnivå.
Matchningsfel mellan textkodning i filen och strängkolumnsortering kan orsaka oväntade konverteringsfel.
Du kan enkelt ändra standardsortering av den aktuella databasen med hjälp av följande T-SQL-instruktion:
alter database current collate Latin1_General_100_BIN2_UTF8 Du kan enkelt ange sortering för kolumntyperna med hjälp av följande definition: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Dataset
NYC Yellow Taxi-datauppsättningen används i det här exemplet. Den ursprungliga PARQUET datauppsättningen konverteras till DELTA format och DELTA versionen används i exemplen.
Sök i partitionerade data
Datauppsättningen som anges i det här exemplet är uppdelad (partitionerad) i separata undermappar.
Till skillnad från Parquet behöver du inte rikta in dig på specifika partitioner med hjälp av FILEPATH funktionen. Identifierar OPENROWSET partitioneringskolumner i delta lake-mappstrukturen och gör att du kan fråga data direkt med hjälp av dessa kolumner. Det här exemplet visar prisbelopp per år, månad och payment_type för de tre första månaderna 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
Funktionen OPENROWSET eliminerar partitioner som inte matchar year och month i where-satsen. Den här tekniken för fil-/partitionsrensning minskar avsevärt datamängden, förbättrar prestandan och minskar kostnaden för frågan.
Mappnamnet i OPENROWSET funktionen (yellow i det här exemplet) sammanfogas med hjälp av LOCATION i-datakällan DeltaLakeStorage och måste referera till rotmappen Delta Lake som innehåller en undermapp med namnet _delta_log.
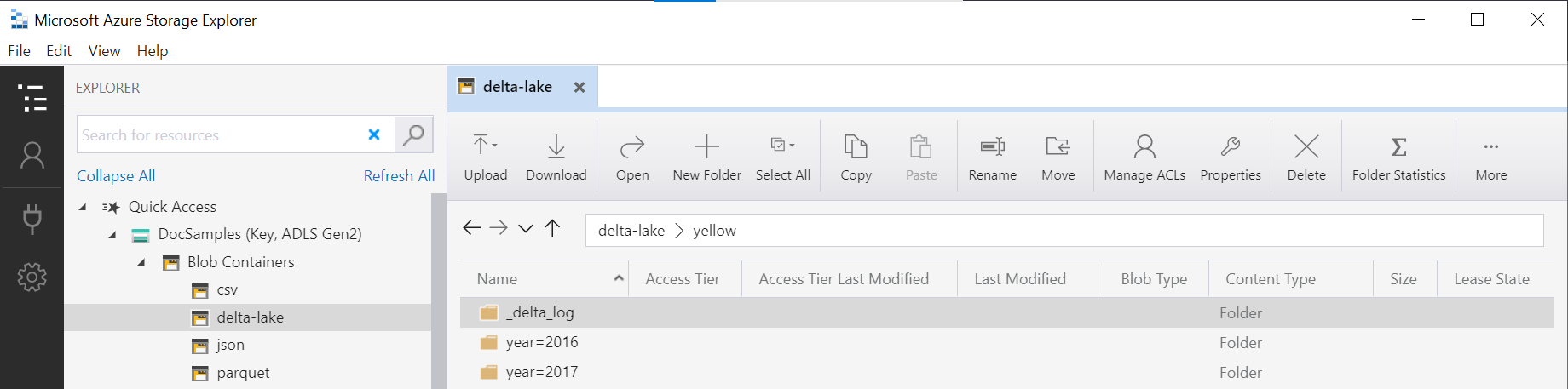
Om du inte har den här undermappen använder du inte Delta Lake-format. Du kan konvertera dina vanliga Parquet-filer i mappen till Delta Lake-format med hjälp av följande Apache Spark Python-skript:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Det andra argumentet i funktionen representerar de partitioneringskolumner DeltaTable.convertToDeltaLake (år och månad) som ingår i mappmönstret (year=*/month=* i det här exemplet) och deras typer.
Begränsningar
- Granska begränsningarna och de kända problemen på självhjälpssidan för Synapse-serverlösa SQL-pooler.
Relaterat innehåll
Gå vidare till nästa artikel för att lära dig hur du utför sökfrågor på kapslade Parquet-typer. Om du vill fortsätta att skapa En Delta Lake-lösning kan du lära dig hur du skapar vyer eller externa tabeller i Delta Lake-mappen.