Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Aktiviteten i en Synapse-pipeline kör en Azure Synapse-notebook. Den här artikeln bygger på artikeln om datatransformeringsaktiviteter , som visar en allmän översikt över datatransformering och de omvandlingsaktiviteter som stöds.
Skapa en Synapse Notebook-aktivitet
Du kan skapa en Synapse Notebook-aktivitet direkt från Synapse-pipelinearbetsytan eller från notebook-redigeraren. Aktiviteten i Synapse-notebook körs på den Spark-pool som väljs i Synapse-notebook.
Lägga till en Synapse Notebook-aktivitet från pipelinearbetsytan
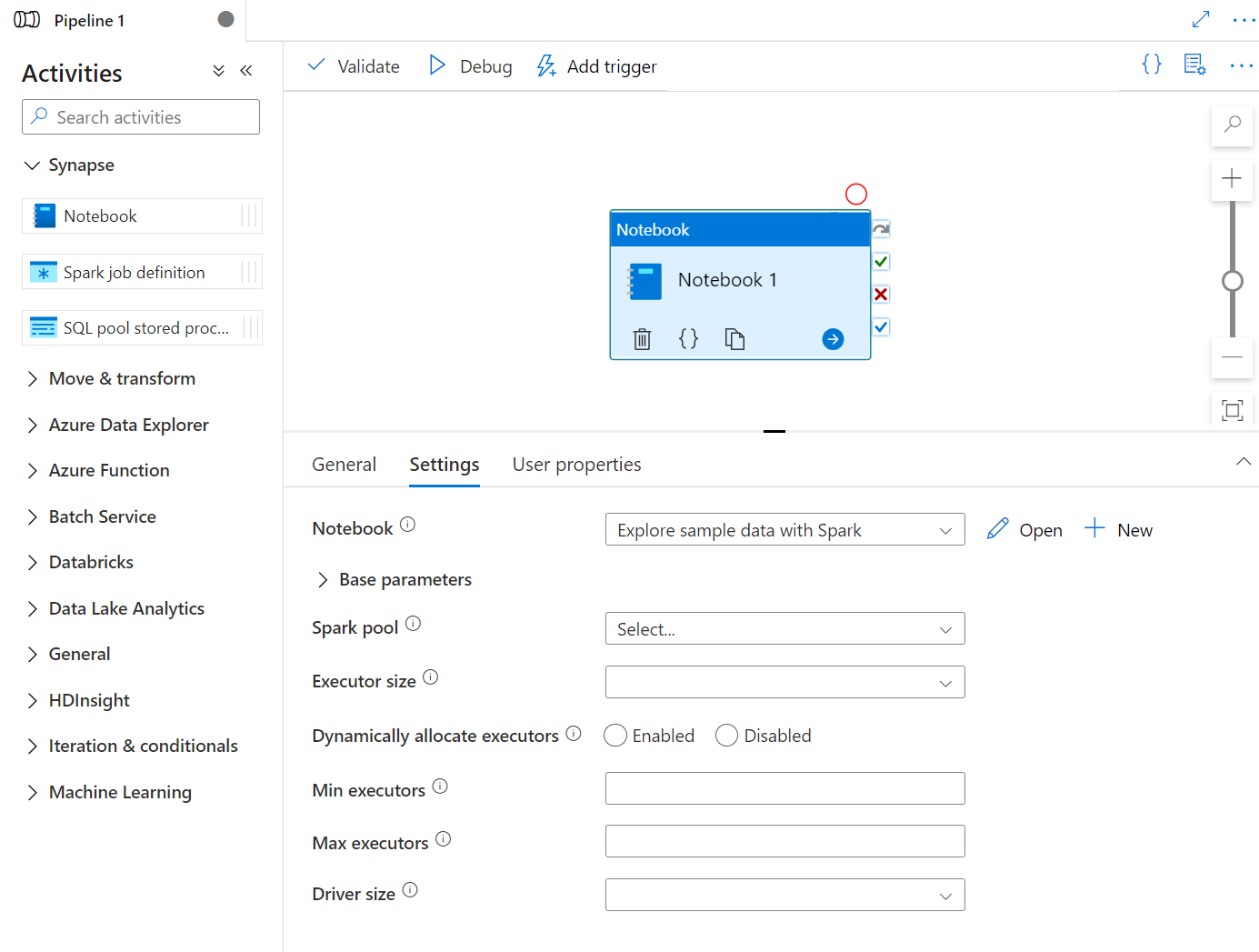
Dra och släpp Synapse Notebook under Aktiviteter på Synapse-pipelinearbetsytan. Välj i aktivitetsrutan Synapse Notebook och konfigurera notebook-innehållet för aktuell aktivitet i inställningarna. Du kan välja en befintlig anteckningsbok från den aktuella arbetsytan eller lägga till en ny.
Om du väljer en befintlig anteckningsbok från den aktuella arbetsytan kan du klicka på knappen Öppna för att öppna anteckningsbokens sida direkt.
(Valfritt) Du kan också konfigurera om Spark-poolen\Exekveringsstorlek\Dynamiskt allokera exekveringsprogram\Minsta antalet exekverare\Maximalt antal exekverare\Drivstorlek\Autentisering i inställningar. Observera att de inställningar som konfigureras om här ersätter inställningarna för den konfigurerade sessionen i Notebook. Om inget anges i inställningarna för den aktuella notebook-aktiviteten körs det med inställningarna för den konfigurerade sessionen i anteckningsboken.
| Egendom | Beskrivning | Obligatoriskt |
|---|---|---|
| Sparkpool | Referens till Spark-poolen. Du kan välja Apache Spark-pool i listan. Om den här inställningen är tom körs den i notebookfilens egen spark-pool. | Nej |
| Utförares storlek | Antal kärnor och minne som ska användas för utförare som allokerats i den angivna Apache Spark-poolen för sessionen. | Nej |
| Att dynamiskt allokera exekutorer | Den här inställningen mappar till den dynamiska allokeringsegenskapen i Spark-konfigurationen för Spark Application Executors-allokering. | Nej |
| Minsta körbara filer | Minsta antal utförare som ska allokeras i den angivna Spark-poolen för jobbet. | Nej |
| Maximalt antal körbara filer | Maximalt antal utförare som ska allokeras i den angivna Spark-poolen för jobbet. | Nej |
| Drivrutinsstorlek | Antal kärnor och minne som ska användas för drivrutinen som anges i den angivna Apache Spark-poolen för jobbet. | Nej |
| Autentisering | Kan autentisera med antingen en systemtilldelad hanterad identitet eller en användartilldelad hanterad identitet. | Nej |
Kommentar
Utförandet av parallella Spark Notebooks i Azure Synapse-pipelines placeras i kö och körs på ett först in, först ut (FIFO)-sätt. Jobbordningen i kön är enligt tidssekvensen, och förfallotiden för ett jobb i kön är 3 dagar. Observera att kön för notebook-filer endast fungerar i Synapse-pipelines.
Lägga till en notebook-fil i Synapse-pipelinen
Välj knappen Lägg till i pipeline i det övre högra hörnet för att lägga till en notebook-fil i en befintlig pipeline eller skapa en ny pipeline.

Skicka parametrar
Ange en parametercell
Om du vill parametrisera anteckningsboken väljer du ellipserna (...) för att få åtkomst till fler kommandon i cellverktygsfältet . Välj sedan Växla parametercell för att ange cellen som parametercell.

Definiera dina parametrar i den här cellen. Det kan vara något så enkelt som:
a = 1
b = 3
c = "Default Value"
Du kan referera till dessa parametrar i andra celler och när du kör notebook-filen för att använda de standardvärden som du anger i parametercellen.
När du kör den här notebook-filen från en pipeline letar Azure Data Factory efter parametercellen och använder de värden som du angav som standardvärden för de parametrar som skickades in vid körningen. Om du tilldelar parametervärden från en pipeline lägger körningsmotorn till en ny cell under parametercellen med indataparametrar för att skriva över standardvärdena.
Tilldela värden till parametrar från en pipeline
När du har skapat en notebook-fil med parametrar kan du köra den från en pipeline med aktiviteten Synapse Notebook. När du har lagt till aktiviteten i pipelinearbetsytan kan du ange parametrarnas värden under avsnittet Basparametrar på fliken Inställningar .

Tips
Data Factory fyller inte i parametrarna automatiskt. Du måste lägga till dem manuellt. Se till att använda exakt samma namn i både parametercellen i notebook-filen och basparametern i pipelinen.
När du har lagt till parametrarna i aktiviteten skickar Data Factory de värden som du anger i din aktivitet till din notebook-fil och notebook-filen körs med de nya parametervärdena i stället för de standardvärden som du angav i parametercellen.
När du tilldelar parametervärden kan du använda pipelineuttrycksspråket eller systemvariablerna.
Läs utdatavärdet för Synapse anteckningsbok-cell
Du kan läsa utdata för notebook-cellen i nästa aktivitet genom att följa stegen nedan:
Anropa mssparkutils.notebook.exit API i din Synapse Notebook-aktivitet för att returnera värdet som du vill visa i aktivitetsutdata, till exempel:
mssparkutils.notebook.exit("hello world")Efter att du sparat notebook-innehållet och återaktiverat pipelinen kommer notebook-aktivitetens utdata att innehålla det exitValue som kan användas för följande aktiviteter i steg 2.
Läs exitValue-egenskapen från notebook-aktivitetsutdata. Här är ett exempeluttryck som används för att kontrollera om exitValue som hämtats från notebook-aktivitetsutdata är lika med "hello world":


Kör en annan Synapse-anteckningsbok
Du kan referera till andra notebook-filer i en Synapse Notebook-aktivitet genom att anropa %run magic eller mssparkutils notebook-verktyg. Båda stöder kapslingsfunktionsanrop. De viktigaste skillnaderna mellan dessa två metoder som du bör överväga baserat på ditt scenario är:
-
%run magic kopierar alla celler från den refererade notebook-filen till cellen %run och delar variabelkontexten. När notebook1 refererar till notebook2 via
%run notebook2och notebook2 anropar funktionen mssparkutils.notebook.exit, stoppas cellkörningen i notebook1. Vi rekommenderar att du använder %run magic när du vill "inkludera" en notebook-fil. -
mssparkutils notebook-verktyg anropar den refererade notebook-filen som en metod eller en funktion. Variabelkontexten delas inte. När notebook1 refererar till notebook2 via
mssparkutils.notebook.run("notebook2")och notebook2 anropar en mssparkutils.notebook.exit-funktion fortsätter cellkörningen i notebook1. Vi rekommenderar att du använder mssparkutils notebook-verktyg när du vill "importera" en notebook.
Se körningshistorik för anteckningsblockaktivitet
Gå till Pipelinekörningar under fliken Övervaka . Du ser den pipeline som du har utlöst. Öppna pipelinen som innehåller notebook-aktivitet för att se körningshistoriken.
Du kan se den senaste ögonblicksbilden av notebook-körningen, inklusive både cellers indata och utdata genom att välja knappen Öppna anteckningsbok .
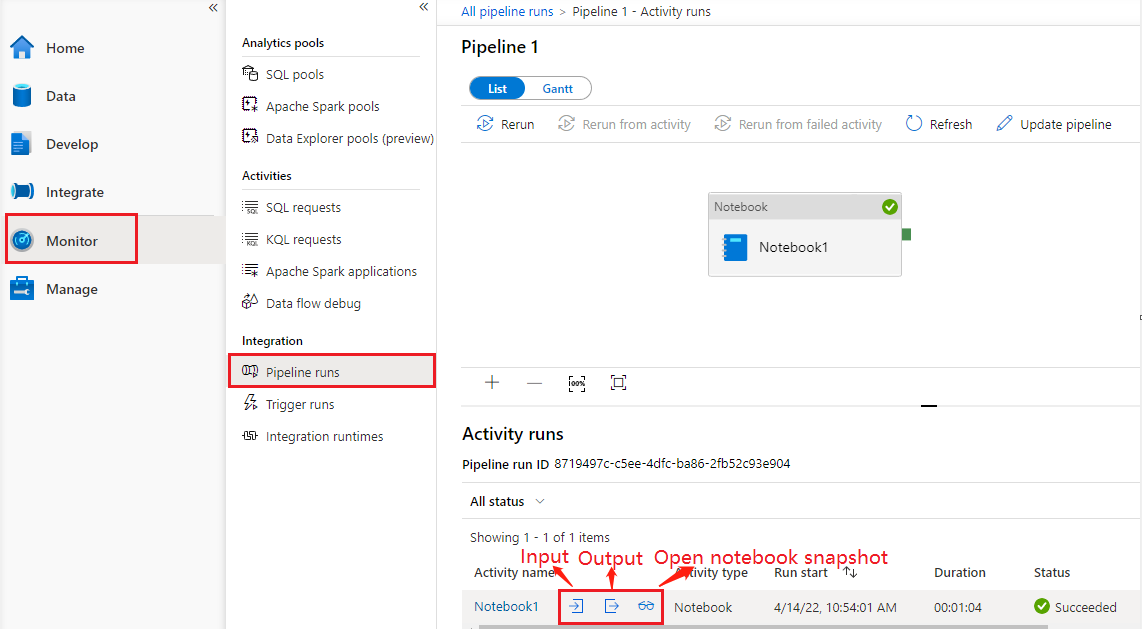
Öppna notebook-ögonblicksbild:
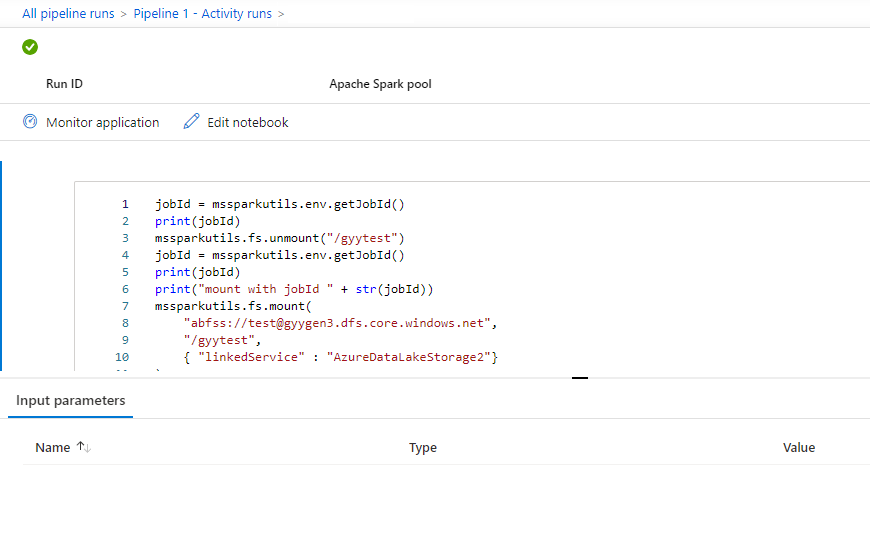
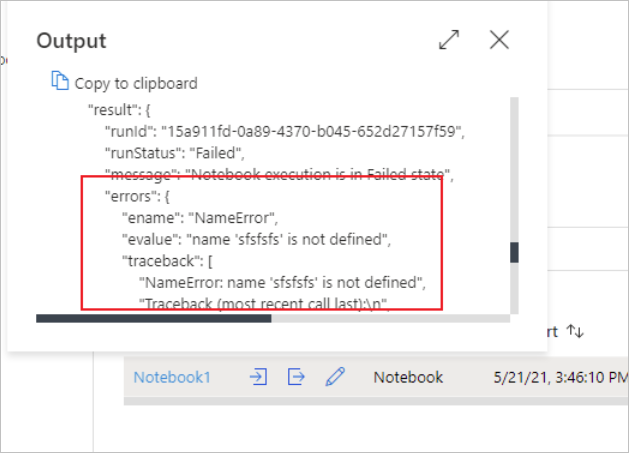
Du kan se input eller output för anteckningsboksaktiviteten genom att välja input eller output-knappen. Om pipelinen misslyckades med ett användarfel markerar du utdata för att kontrollera resultatfältet för att se den detaljerade spårningen av användarfel.
Synapse Notebook-aktivitetsdefinition
Här är JSON-exempeldefinitionen för en Synapse Notebook-aktivitet:
{
"name": "parameter_test",
"type": "SynapseNotebook",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"notebook": {
"referenceName": "parameter_test",
"type": "NotebookReference"
},
"parameters": {
"input": {
"value": {
"value": "@pipeline().parameters.input",
"type": "Expression"
}
}
}
}
}
Utdata för Synapse Notebook-aktivitet
Här är JSON-exempel på en Synapse Notebook-aktivitetsutdata:
{
{
"status": {
"Status": 1,
"Output": {
"status": <livySessionInfo>
},
"result": {
"runId": "<GUID>",
"runStatus": "Succeed",
"message": "Notebook execution is in Succeeded state",
"lastCheckedOn": "2021-03-23T00:40:10.6033333Z",
"errors": {
"ename": "",
"evalue": ""
},
"sessionId": 4,
"sparkpool": "sparkpool",
"snapshotUrl": "https://myworkspace.dev.azuresynapse.net/notebooksnapshot/{guid}",
"exitCode": "abc" // return value from user notebook via mssparkutils.notebook.exit("abc")
}
},
"Error": null,
"ExecutionDetails": {}
},
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (West US 2)",
"executionDuration": 234,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "ExternalActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "Hours"
}
]
}
}
Kända problem
Om notebook-namnet parametriseras i pipeline notebook-aktiviteten kan inte notebook-versionen i opublicerad status refereras till i felsökningskörningarna.