Hög tillgänglighet för SAP HANA på virtuella Azure-datorer på SUSE Linux Enterprise Server
Om du vill etablera hög tillgänglighet i en lokal SAP HANA-distribution kan du använda sap hana-systemreplikering eller delad lagring.
För närvarande är SAP HANA-systemreplikering på Azure den enda funktionen för hög tillgänglighet som stöds på virtuella Azure-datorer (VM).
SAP HANA-systemreplikering består av en primär nod och minst en sekundär nod. Ändringar av data på den primära noden replikeras till den sekundära noden synkront eller asynkront.
Den här artikeln beskriver hur du distribuerar och konfigurerar de virtuella datorerna, installerar klusterramverket och installerar och konfigurerar SAP HANA-systemreplikering.
Läs följande SAP-anteckningar och dokument innan du börjar:
- SAP Note 1928533. Anteckningen innehåller:
- Listan över storlekar på virtuella Azure-datorer som stöds för distribution av SAP-programvara.
- Viktig kapacitetsinformation för vm-storlekar i Azure.
- Sap-programvara, operativsystem (OS) och databaskombinationer som stöds.
- Nödvändiga SAP-kernelversioner för Windows och Linux på Microsoft Azure.
- SAP Note 2015553 listar kraven för SAP-programdistributioner som stöds i Azure.
- SAP Obs 2205917 har rekommenderade os-inställningar för SUSE Linux Enterprise Server 12 (SLES 12) för SAP-program.
- SAP Obs 2684254 har rekommenderade OS-inställningar för SUSE Linux Enterprise Server 15 (SLES 15) för SAP-program.
- SAP Note 2235581 har SAP HANA-operativsystem som stöds
- SAP Note 2178632 innehåller detaljerad information om alla övervakningsmått som rapporteras för SAP i Azure.
- SAP Obs 2191498 har den sap-värdagentversion som krävs för Linux i Azure.
- SAP Note 2243692 har information om SAP-licensiering för Linux i Azure.
- SAP Note 1984787 har allmän information om SUSE Linux Enterprise Server 12.
- SAP Note 1999351 innehåller mer felsökningsinformation för Azure Enhanced Monitoring Extension för SAP.
- SAP Obs 401162 har information om hur du undviker "adress som redan används"-fel när du konfigurerar HANA-systemreplikering.
- SAP Community Support Wiki har alla nödvändiga SAP-anteckningar för Linux.
- SAP HANA-certifierade IaaS-plattformar.
- Planering och implementering av Azure Virtual Machines för SAP på Linux-guide .
- Azure Virtual Machines-distribution för SAP i Linux-guide .
- Azure Virtual Machines DBMS-distribution för SAP i Linux-guide .
- Metodguider för SUSE Linux Enterprise Server för SAP-program 15 och metodtipsguider för SUSE Linux Enterprise Server för SAP-program 12:
- Konfigurera en SAP HANA SR-prestandaoptimerad infrastruktur (SLES för SAP-program). Guiden innehåller all nödvändig information för att konfigurera SAP HANA-systemreplikering för lokal utveckling. Använd den här guiden som baslinje.
- Konfigurera en kostnadsoptimerad SAP HANA SR-infrastruktur (SLES för SAP-program).
Planera för hög tillgänglighet för SAP HANA
För att uppnå hög tillgänglighet installerar du SAP HANA på två virtuella datorer. Data replikeras med hjälp av HANA-systemreplikering.
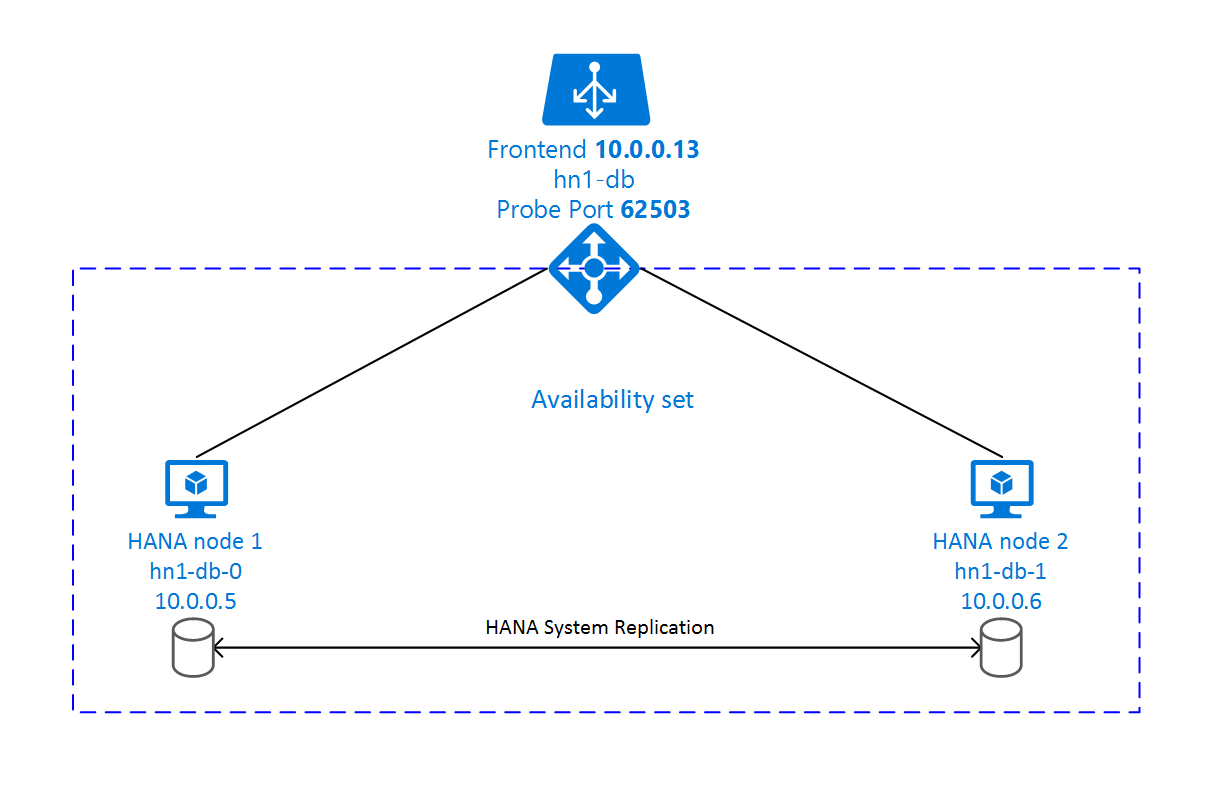
Konfigurationen av SAP HANA-systemreplikering använder ett dedikerat virtuellt värdnamn och virtuella IP-adresser. I Azure behöver du en lastbalanserare för att distribuera en virtuell IP-adress.
Föregående bild visar ett exempel på en lastbalanserare som har följande konfigurationer:
- Klientdels-IP-adress: 10.0.0.13 för HN1-db
- Avsökningsport: 62503
Förbered infrastrukturen
Resursagenten för SAP HANA ingår i SUSE Linux Enterprise Server för SAP-program. En avbildning för SUSE Linux Enterprise Server för SAP-program 12 eller 15 finns på Azure Marketplace. Du kan använda avbildningen för att distribuera nya virtuella datorer.
Distribuera virtuella Linux-datorer manuellt via Azure-portalen
Det här dokumentet förutsätter att du redan har distribuerat en resursgrupp, Azure Virtual Network och undernät.
Distribuera virtuella datorer för SAP HANA. Välj en lämplig SLES-avbildning som stöds för HANA-systemet. Du kan distribuera en virtuell dator i något av tillgänglighetsalternativen – VM-skalningsuppsättning, tillgänglighetszon eller tillgänglighetsuppsättning.
Viktigt!
Kontrollera att operativsystemet du väljer är SAP-certifierat för SAP HANA för de specifika VM-typer som du planerar att använda i distributionen. Du kan leta upp SAP HANA-certifierade VM-typer och deras OS-versioner i SAP HANA-certifierade IaaS-plattformar. Se till att du tittar på informationen om vm-typen för att få en fullständig lista över SAP HANA-versioner som stöds av operativsystemet för den specifika typen av virtuell dator.
Konfigurera Azure-lastbalanserare
Under konfigurationen av den virtuella datorn kan du skapa eller välja att avsluta lastbalanseraren i nätverksavsnittet. Följ stegen nedan för att konfigurera standardlastbalanserare för installation av HANA-databas med hög tillgänglighet.
Följ stegen i Skapa lastbalanserare för att konfigurera en standardlastbalanserare för ett SAP-system med hög tillgänglighet med hjälp av Azure-portalen. Tänk på följande under installationen av lastbalanseraren:
- IP-konfiguration för klientdelen: Skapa en klientdels-IP-adress. Välj samma virtuella nätverk och undernätsnamn som dina virtuella databasdatorer.
- Serverdelspool: Skapa en serverdelspool och lägg till virtuella databasdatorer.
- Regler för inkommande trafik: Skapa en belastningsutjämningsregel. Följ samma steg för båda belastningsutjämningsreglerna.
- Klientdels-IP-adress: Välj en klientdels-IP-adress.
- Serverdelspool: Välj en serverdelspool.
- Portar med hög tillgänglighet: Välj det här alternativet.
- Protokoll: Välj TCP.
- Hälsoavsökning: Skapa en hälsoavsökning med följande information:
- Protokoll: Välj TCP.
- Port: Till exempel 625<instans-no.>.
- Intervall: Ange 5.
- Tröskelvärde för avsökning: Ange 2.
- Tidsgräns för inaktivitet (minuter): Ange 30.
- Aktivera flytande IP: Välj det här alternativet.
Kommentar
Konfigurationsegenskapen numberOfProbesför hälsoavsökningen , även kallad Tröskelvärde för fel i portalen, respekteras inte. Om du vill kontrollera antalet lyckade eller misslyckade efterföljande avsökningar anger du egenskapen probeThreshold till 2. Det går för närvarande inte att ange den här egenskapen med hjälp av Azure-portalen, så använd antingen Azure CLI eller PowerShell-kommandot .
Mer information om de portar som krävs för SAP HANA finns i kapitlet Anslutningar till klientdatabaser i guiden SAP HANA-klientdatabaser eller SAP Note 2388694.
Kommentar
När virtuella datorer som inte har offentliga IP-adresser placeras i serverdelspoolen för en intern (ingen offentlig IP-adress) standardinstans av Azure Load Balancer är standardkonfigurationen ingen utgående Internetanslutning. Du kan vidta extra åtgärder för att tillåta routning till offentliga slutpunkter. Mer information om hur du uppnår utgående anslutning finns i Offentlig slutpunktsanslutning för virtuella datorer med hjälp av Azure Standard Load Balancer i SAP-scenarier med hög tillgänglighet.
Viktigt!
- Aktivera inte TCP-tidsstämplar på virtuella Azure-datorer som placeras bakom Azure Load Balancer. Om du aktiverar TCP-tidsstämplar misslyckas hälsoavsökningarna. Ange parametern
net.ipv4.tcp_timestampstill0. Mer information finns i Load Balancer-hälsoavsökningar eller SAP-anteckning 2382421. - Om du vill förhindra att saptune ändrar värdet manuellt
net.ipv4.tcp_timestampsfrån0tillbaka till1uppdaterar du saptune-versionen till 3.1.1 eller senare. Mer information finns i saptune 3.1.1 – Behöver jag uppdatera?.
Skapa ett Pacemaker-kluster
Följ stegen i Konfigurera Pacemaker på SUSE Linux Enterprise Server i Azure för att skapa ett grundläggande Pacemaker-kluster för den här HANA-servern. Du kan använda samma Pacemaker-kluster för SAP HANA och SAP NetWeaver (A)SCS.
Installera SAP HANA
Stegen i det här avsnittet använder följande prefix:
- [A]: Steget gäller för alla noder.
- [1]: Steget gäller endast för nod 1.
- [2]: Steget gäller endast för nod 2 i Pacemaker-klustret.
Ersätt <placeholders> med värdena för SAP HANA-installationen.
[A] Konfigurera disklayouten med hjälp av Logical Volume Manager (LVM).
Vi rekommenderar att du använder LVM för volymer som lagrar data och loggfiler. I följande exempel förutsätts att de virtuella datorerna har fyra anslutna datadiskar som används för att skapa två volymer.
Kör det här kommandot för att visa en lista över alla tillgängliga diskar:
/dev/disk/azure/scsi1/lun*Exempel på utdata>
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Skapa fysiska volymer för alla diskar som du vill använda:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Skapa en volymgrupp för datafilerna. Använd en volymgrupp för loggfilerna och en volymgrupp för den delade katalogen för SAP HANA:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Skapa de logiska volymerna.
En linjär volym skapas när du använder
lvcreateutan växeln-i. Vi rekommenderar att du skapar en randig volym för bättre I/O-prestanda. Justera randstorlekarna efter de värden som beskrivs i SAP HANA VM-lagringskonfigurationer. Argumentet-iska vara antalet underliggande fysiska volymer och-Iargumentet är randstorleken.Om två fysiska volymer till exempel används för datavolymen anges växelargumentet
-itill 2 och stripe-storleken för datavolymen är 256KiB. En fysisk volym används för loggvolymen, så inga-ieller-Iväxlar används uttryckligen för loggvolymkommandona.Viktigt!
När du använder mer än en fysisk volym för varje datavolym, loggvolym eller delad volym använder du växeln
-ioch anger antalet underliggande fysiska volymer. När du skapar en randig volym använder du växeln-Iför att ange randstorleken.Rekommenderade lagringskonfigurationer, inklusive randstorlekar och antalet diskar, finns i SAP HANA VM-lagringskonfigurationer.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedSkapa monteringskatalogerna och kopiera den universellt unika identifieraren (UUID) för alla logiska volymer:
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidRedigera /etc/fstab-filen för att skapa
fstabposter för de tre logiska volymerna:sudo vi /etc/fstabInfoga följande rader i filen /etc/fstab :
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Montera de nya volymerna:
sudo mount -a
[A] Konfigurera disklayouten med hjälp av oformaterade diskar.
För demosystem kan du placera DINA HANA-data och loggfiler på en disk.
Skapa en partition på /dev/disk/azure/scsi1/lun0 och formatera den med hjälp av XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabInfoga den här raden i /etc/fstab-filen :
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Skapa målkatalogen och montera disken:
sudo mkdir /hana sudo mount -a
[A] Konfigurera värdnamnsmatchning för alla värdar.
Du kan antingen använda en DNS-server eller ändra /etc/hosts-filen på alla noder. Det här exemplet visar hur du använder filen /etc/hosts . Ersätt IP-adresserna och värdnamnen i följande kommandon.
Redigera filen /etc/hosts:
sudo vi /etc/hostsInfoga följande rader i filen /etc/hosts . Ändra IP-adresserna och värdnamnen så att de matchar din miljö.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Installera SAP HANA-paket med hög tillgänglighet:
Kör följande kommando för att installera paket med hög tillgänglighet:
sudo zypper install SAPHanaSR
Om du vill installera SAP HANA-systemreplikering läser du kapitel 4 i guiden för prestandaoptimerade SAP HANA SR-scenarion .
[A] Kör hdblcm-programmet från HANA-installationsmediet.
När du uppmanas att göra det anger du följande värden:
- Välj installation: Ange 1.
- Välj ytterligare komponenter för installation: Ange 1.
- Ange installationssökväg: Ange /hana/shared och välj Retur.
- Ange det lokala värdnamnet: Ange .. och välj Retur.
- Vill du lägga till ytterligare värdar i systemet? (y/n): Ange n och välj Retur.
- Ange SAP HANA-system-ID: Ange DITT HANA SID.
- Ange instansnumret: Ange HANA-instansnumret. Om du har distribuerat med hjälp av Azure-mallen eller om du följde avsnittet för manuell distribution i den här artikeln anger du 03.
- Välj databasläge/Ange indexet: Ange eller välj 1 och välj Retur.
- Välj systemanvändning/Ange indexet: Välj systemanvändningsvärdet 4.
- Ange platsen för datavolymerna: Ange /hana/data/<HANA SID> och välj Retur.
- Ange platsen för loggvolymerna: Ange /hana/log/<HANA SID> och välj Retur.
- Begränsa maximal minnesallokering?: Ange n och välj Retur.
- Ange certifikatvärdnamnet för värden: Ange ... och välj Retur.
- Ange lösenordet för SAP-värdagentanvändaren (sapadm): Ange användarlösenordet för värdagenten och välj sedan Retur.
- Bekräfta lösenordet för SAP-värdagentanvändaren (sapadm): Ange användarlösenordet för värdagenten igen och välj sedan Retur.
- Ange systemadministratörslösenordet (hdbadm): Ange systemadministratörslösenordet och välj sedan Retur.
- Bekräfta lösenordet för systemadministratören (hdbadm): Ange systemadministratörslösenordet igen och välj sedan Retur.
- Ange systemadministratörens hemkatalog: Ange /usr/sap/<HANA SID>/home och välj Retur.
- Ange inloggningsgränssnittet för systemadministratör: Ange /bin/sh och välj Retur.
- Ange systemadministratörens användar-ID: Ange 1001 och välj Retur.
- Ange ID för användargruppen (sapsys): Ange 79 och välj Retur.
- Ange lösenordet för databasanvändaren (SYSTEM): Ange databasanvändarlösenordet och välj sedan Retur.
- Bekräfta lösenordet för databasanvändaren (SYSTEM): Ange databasanvändarlösenordet igen och välj sedan Retur.
- Starta om systemet efter omstart av datorn? (y/n): Ange n och välj Retur.
- Vill du fortsätta? (y/n): Verifiera sammanfattningen. Ange y för att fortsätta.
[A] Uppgradera SAP-värdagenten.
Ladda ned det senaste SAP-värdagentarkivet från SAP Software Center. Kör följande kommando för att uppgradera agenten. Ersätt sökvägen till arkivet för att peka på filen som du laddade ned.
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP host agent SAR>
Konfigurera SAP HANA 2.0-systemreplikering
Stegen i det här avsnittet använder följande prefix:
- [A]: Steget gäller för alla noder.
- [1]: Steget gäller endast för nod 1.
- [2]: Steget gäller endast för nod 2 i Pacemaker-klustret.
Ersätt <placeholders> med värdena för SAP HANA-installationen.
[1] Skapa klientdatabasen.
Om du använder SAP HANA 2.0 eller SAP HANA MDC skapar du en klientdatabas för ditt SAP NetWeaver-system.
Kör följande kommando som <HANA SID>adm:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] Konfigurera systemreplikering på den första noden:
Säkerhetskopiera först databaserna som <HANA SID-adm>:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"Kopiera sedan PKI-filerna (System Public Key Infrastructure) till den sekundära platsen:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Skapa den primära platsen:
hdbnsutil -sr_enable --name=<site 1>[2] Konfigurera systemreplikering på den andra noden:
Registrera den andra noden för att starta systemreplikeringen.
Kör följande kommando som <HANA SID>adm:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Konfigurera SAP HANA 1.0-systemreplikering
Stegen i det här avsnittet använder följande prefix:
- [A]: Steget gäller för alla noder.
- [1]: Steget gäller endast för nod 1.
- [2]: Steget gäller endast för nod 2 i Pacemaker-klustret.
Ersätt <placeholders> med värdena för SAP HANA-installationen.
[1] Skapa de användare som krävs.
Kör följande kommando som rot:
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbsql -u system -i <instance number> 'CREATE USER hdbhasync PASSWORD "<password>"' hdbsql -u system -i <instance number> 'GRANT DATA ADMIN TO hdbhasync' hdbsql -u system -i <instance number> 'ALTER USER hdbhasync DISABLE PASSWORD LIFETIME'[A] Skapa nyckellagringsposten.
Kör följande kommando som rot för att skapa en ny nyckellagringspost:
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbuserstore SET hdbhaloc localhost:3<instance number>15 hdbhasync <password>[1] Säkerhetskopiera databasen.
Säkerhetskopiera databaserna som rot:
PATH="$PATH:/usr/sap/<HANA SID>/HDB<instance number>/exe" hdbsql -d SYSTEMDB -u system -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file>')"Om du använder en installation med flera klientorganisationer säkerhetskopierar du även klientdatabasen:
hdbsql -d <HANA SID> -u system -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file>')"[1] Konfigurera systemreplikering på den första noden.
Skapa den primära platsen som <HANA SID-adm>:
su - hdbadm hdbnsutil -sr_enable --name=<site 1>[2] Konfigurera systemreplikering på den sekundära noden.
Registrera den sekundära platsen som <HANA SID-adm>:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=<HANA SID>-db-<database 1> --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Implementera HANA-krokar SAPHanaSR och susChkSrv
I det här viktiga steget optimerar du integreringen med klustret och förbättrar identifieringen när ett kluster behöver redundans. Vi rekommenderar starkt att du konfigurerar SAPHanaSR Python-kroken. För HANA 2.0 SP5 och senare rekommenderar vi att du implementerar SAPHanaSR-kroken och susChkSrv-kroken.
SusChkSrv-kroken utökar funktionerna i den huvudsakliga SAPHanaSR HA-providern. Den fungerar när HANA-processen hdbindexserver kraschar. Om en enskild process kraschar försöker HANA vanligtvis starta om den. Det kan ta lång tid att starta om indexserverprocessen, under vilken HANA-databasen inte svarar.
När susChkSrv har implementerats körs en omedelbar och konfigurerbar åtgärd. Åtgärden utlöser en redundans under den konfigurerade tidsgränsen i stället för att vänta på att hdbindexserverprocessen ska startas om på samma nod.
[A] Installera HANA-systemreplikeringskroken. Kroken måste vara installerad på båda HANA-databasnoderna.
Dricks
SAPHanaSR Python-kroken kan endast implementeras för HANA 2.0. SAPHanaSR-paketet måste vara minst version 0.153.
Python-kroken susChkSrv kräver SAP HANA 2.0 SP5 och SAPHanaSR-version 0.161.1_BF eller senare måste installeras.
Stoppa HANA på båda noderna.
Kör följande kod som <sapsid>adm:
sapcontrol -nr <instance number> -function StopSystemJustera global.ini på varje klusternod. Om kraven för susChkSrv-kroken inte uppfylls tar du bort hela
[ha_dr_provider_suschksrv]blocket från följande parametrar.Du kan justera beteendet för med hjälp av
susChkSrvparameternaction_on_lost. Giltiga värden är [ignorefence| |stop|kill].# add to global.ini [ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = infoOm du pekar på standardplatsen /usr/share/SAPHanaSR uppdateras Python-hookkoden automatiskt via OS-uppdateringar eller paketuppdateringar. HANA använder hook-koduppdateringarna när den startas om nästa år. Med en valfri egen sökväg som /hana/shared/myHooks kan du frikoppla OS-uppdateringar från den krokversion som du använder.
[A] Klustret kräver sudoers-konfiguration på varje klusternod för <SAP SID-adm>. I det här exemplet uppnås detta genom att skapa en ny fil.
Kör följande kommando som rot:
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks hn1adm ALL=(ALL) NOPASSWD: /usr/sbin/crm_attribute -n hana_hn1_site_srHook_* hn1adm ALL=(ALL) NOPASSWD: /usr/sbin/SAPHanaSR-hookHelper --sid=HN1 --case=fenceMe EOFMer information om hur du implementerar SAP HANA-systemreplikeringskroken finns i Konfigurera HANA HA/DR-leverantörer.
[A] Starta SAP HANA på båda noderna.
Kör följande kommando som <SAP SID-adm>:
sapcontrol -nr <instance number> -function StartSystem[1] Kontrollera hookinstallationen.
Kör följande kommando som <SAP SID-adm>på den aktiva HANA-systemreplikeringsplatsen:
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOKKontrollera installationen av susChkSrv-kroken.
Kör följande kommando som <SAP SID-adm>på alla virtuella HANA-datorer:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Skapa SAP HANA-klusterresurser
Skapa först HANA-topologin.
Kör följande kommandon på en av Pacemaker-klusternoderna:
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
Skapa sedan HANA-resurserna:
Viktigt!
I de senaste testerna netcat slutar svara på begäranden på grund av en kvarvarande information och på grund av dess begränsning av hanteringen av endast en anslutning. Resursen netcat slutar lyssna på Azure Load Balancer-begäranden och den flytande IP-adressen blir otillgänglig.
För befintliga Pacemaker-kluster rekommenderade vi tidigare att du ersätter netcat med socat. För närvarande rekommenderar vi att du använder resursagenten azure-lb , som ingår i ett paket med resource-agents. Följande paketversioner krävs:
- För SLES 12 SP4/SP5 måste versionen vara minst resource-agents-4.3.018.a7fb5035-3.30.1.
- För SLES 15/15 SP1 måste versionen vara minst resource-agents-4.3.0184.6ee15eb2-4.13.1.
Att göra den här ändringen kräver en kort stilleståndstid.
För befintliga Pacemaker-kluster behöver du inte omedelbart växla till resursagenten om konfigurationen redan har ändrats så att den används socat enligt beskrivningen azure-lb i Azure Load Balancer Detection Hardening.
Kommentar
Den här artikeln innehåller referenser till termer som Microsoft inte längre använder. När dessa villkor tas bort från programvaran tar vi bort dem från den här artikeln.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
# Run the following command if the cluster nodes are running on SLES 12 SP05.
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
# Run the following command if the cluster nodes are running on SLES 15 SP03 or later.
sudo crm configure clone msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true" promotable="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Viktigt!
Vi rekommenderar att du endast anger AUTOMATED_REGISTER till false när du slutför noggranna redundanstester för att förhindra att en misslyckad primär instans registreras automatiskt som sekundär. När redundanstesterna har slutförts anger du AUTOMATED_REGISTER till true, så att systemreplikeringen automatiskt återupptas efter övertagandet.
Kontrollera att klusterstatusen är OK och att alla resurser har startats. Det spelar ingen roll vilken nod resurserna körs på.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Konfigurera AKTIV/läsaktiverad HANA-systemreplikering i ett Pacemaker-kluster
I SAP HANA 2.0 SPS 01 och senare versioner tillåter SAP en aktiv/läsaktiverad installation för SAP HANA-systemreplikering. I det här scenariot kan de sekundära systemen för SAP HANA-systemreplikering aktivt användas för läsintensiva arbetsbelastningar.
För att stödja den här konfigurationen i ett kluster krävs en andra virtuell IP-adress så att klienterna kan komma åt den sekundära läsaktiverade SAP HANA-databasen. För att säkerställa att den sekundära replikeringsplatsen fortfarande kan nås efter ett övertagande måste klustret flytta runt den virtuella IP-adressen med den sekundära SAPHana-resursen.
I det här avsnittet beskrivs de extra steg som krävs för att hantera en HANA-aktiv/läsaktiverad systemreplikering i ett SUSE-kluster med hög tillgänglighet som använder en andra virtuell IP-adress.
Innan du fortsätter kontrollerar du att du har konfigurerat SUSE-klustret med hög tillgänglighet som hanterar SAP HANA-databasen enligt beskrivningen i tidigare avsnitt.
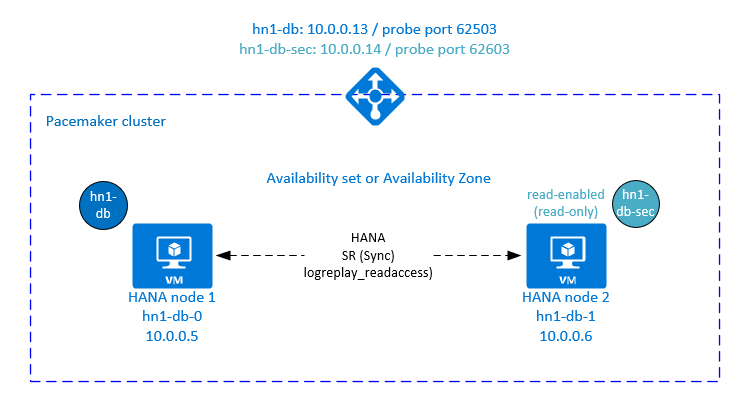
Konfigurera lastbalanseraren för aktiv/läsaktiverad systemreplikering
Om du vill fortsätta med extra steg för att etablera den andra virtuella IP-adressen kontrollerar du att du har konfigurerat Azure Load Balancer enligt beskrivningen i Distribuera virtuella Linux-datorer manuellt via Azure-portalen.
För standardlastbalanseraren utför du de här extra stegen på samma lastbalanserare som du skapade tidigare.
- Skapa en andra IP-pool på klientsidan:
- Öppna lastbalanseraren, välj KLIENTDELS-IP-pool och välj Lägg till.
- Ange namnet på den andra IP-poolen på klientsidan (till exempel hana-secondaryIP).
- Ange tilldelningen till Statisk och ange IP-adressen (till exempel 10.0.0.14).
- Välj OK.
- När den nya KLIENTDELS-IP-poolen har skapats noterar du IP-adressen för klientdelen.
- Skapa en hälsoavsökning:
- I lastbalanseraren väljer du hälsoavsökningar och väljer Lägg till.
- Ange namnet på den nya hälsoavsökningen (till exempel hana-secondaryhp).
- Välj TCP som protokoll och port 626-instansnummer><. Behåll värdet Intervall inställt på 5 och tröskelvärdet Ej felfri är inställt på 2.
- Välj OK.
- Skapa belastningsutjämningsreglerna:
- I lastbalanseraren väljer du belastningsutjämningsregler och väljer Lägg till.
- Ange namnet på den nya lastbalanseringsregeln (till exempel hana-secondarylb).
- Välj klientdelens IP-adress, serverdelspoolen och hälsoavsökningen som du skapade tidigare (till exempel hana-secondaryIP, hana-backend och hana-secondaryhp).
- Välj HA-portar.
- Öka tidsgränsen för inaktivitet till 30 minuter.
- Kontrollera att du aktiverar flytande IP-adress.
- Välj OK.
Konfigurera HANA-aktiv/läsaktiverad systemreplikering
Stegen för att konfigurera HANA-systemreplikering beskrivs i Konfigurera SAP HANA 2.0-systemreplikering. Om du distribuerar ett läsaktiverat sekundärt scenario kör du följande kommando som <HANA SID>adm när du konfigurerar systemreplikering på den andra noden:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Lägga till en sekundär virtuell IP-adressresurs
Du kan konfigurera den andra virtuella IP-adressen och lämplig samlokaliseringsbegränsning med hjälp av följande kommandon:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
Kontrollera att klusterstatusen är OK och att alla resurser har startats. Den andra virtuella IP-adressen körs på den sekundära platsen tillsammans med den sekundära SAPHana-resursen.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
I nästa avsnitt beskrivs den typiska uppsättningen redundanstester som ska köras.
Överväganden när du testar ett HANA-kluster som har konfigurerats med en läsaktiverad sekundär:
När du migrerar klusterresursen
SAPHana_<HANA SID>_HDB<instance number>tillhn1-db-1flyttas den andra virtuella IP-adressen tillhn1-db-0. Om du har konfigureratAUTOMATED_REGISTER="false"och HANA-systemreplikeringen inte registreras automatiskt körs den andra virtuella IP-adressen påhn1-db-0eftersom servern är tillgänglig och klustertjänsterna är online.När du testar en serverkrasch körs den andra virtuella IP-resurserna (
rsc_secip_<HANA SID>_HDB<instance number>) och Azure Load Balancer-portresursen (rsc_secnc_<HANA SID>_HDB<instance number>) på den primära servern tillsammans med de primära virtuella IP-resurserna. När den sekundära servern är nere ansluter de program som är anslutna till en läsaktiverad HANA-databas till den primära HANA-databasen. Beteendet är förväntat eftersom du inte vill att program som är anslutna till en läsaktiverad HANA-databas ska vara otillgängliga när den sekundära servern inte är tillgänglig.När den sekundära servern är tillgänglig och klustertjänsterna är online flyttas den andra virtuella IP- och portresurserna automatiskt till den sekundära servern, även om HANA-systemreplikeringen kanske inte registreras som sekundär. Kontrollera att du registrerar den sekundära HANA-databasen som läsaktiverad innan du startar klustertjänster på den servern. Du kan konfigurera HANA-instansklusterresursen för att automatiskt registrera den sekundära genom att ange parametern
AUTOMATED_REGISTER="true".Under redundansväxling och återställning kan befintliga anslutningar för program, som sedan använder den andra virtuella IP-adressen för att ansluta till HANA-databasen, avbrytas.
Testa klusterkonfigurationen
I det här avsnittet beskrivs hur du kan testa konfigurationen. Varje test förutsätter att du är inloggad som rot och att SAP HANA-huvudservern körs på den hn1-db-0 virtuella datorn.
Testa migreringen
Innan du startar testet kontrollerar du att Pacemaker inte har någon misslyckad åtgärd (kör crm_mon -r), att det inte finns några oväntade platsbegränsningar (till exempel rester av ett migreringstest) och att HANA är i synkroniseringstillstånd, till exempel genom att köra SAPHanaSR-showAttr.
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
Du kan migrera SAP HANA-huvudnoden genom att köra följande kommando:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
Klustret migrerar SAP HANA-huvudnoden och gruppen som innehåller virtuell IP-adress till hn1-db-1.
När migreringen är klar crm_mon -r ser utdata ut så här:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
Med AUTOMATED_REGISTER="false"startar inte klustret om den misslyckade HANA-databasen eller registrerar den mot den nya primära på hn1-db-0. I det här fallet konfigurerar du HANA-instansen som sekundär genom att köra det här kommandot:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
Migreringen skapar platsbegränsningar som måste tas bort igen:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
Du måste också rensa tillståndet för den sekundära nodresursen:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Övervaka tillståndet för HANA-resursen med hjälp crm_mon -rav . När HANA startas hn1-db-0ser utdata ut som i det här exemplet:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Blockera nätverkskommunikation
Resurstillstånd innan testet startas:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Kör brandväggsregeln för att blockera kommunikationen på en av noderna.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
När klusternoder inte kan kommunicera med varandra finns det en risk för ett scenario med delad hjärna. I sådana situationer försöker klusternoder att samtidigt avgränsa varandra, vilket resulterar i stängselrace.
När du konfigurerar en fäktningsenhet rekommenderar vi att du konfigurerar pcmk_delay_max egenskapen. I händelse av split-brain-scenario introducerar klustret därför en slumpmässig fördröjning upp till pcmk_delay_max värdet, till fäktningsåtgärden på varje nod. Noden med den kortaste fördröjningen väljs för stängsel.
För att säkerställa att noden som kör HANA-mastern prioriteras och vinner stängselracet i ett scenario med delad hjärna rekommenderar vi att du anger priority-fencing-delay egenskapen i klusterkonfigurationen. Genom att aktivera egenskapen priority-fencing-delay kan klustret införa ytterligare en fördröjning i fäktningsåtgärden specifikt på noden som är värd för HANA-huvudresursen, vilket gör att noden kan vinna stängselracet.
Kör kommandot nedan för att ta bort brandväggsregeln.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testa SBD-fäktning
Du kan testa konfigurationen av SBD genom att döda inkvisitorprocessen:
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
Klusternoden <HANA SID>-db-<database 1> startas om. Pacemakertjänsten kanske inte startas om. Se till att du startar den igen.
Testa en manuell redundansväxling
Du kan testa en manuell redundansväxling genom att stoppa Pacemaker-tjänsten på hn1-db-0 noden:
service pacemaker stop
Efter redundansväxlingen kan du starta tjänsten igen. Om du anger AUTOMATED_REGISTER="false"startar inte SAP HANA-resursen hn1-db-0 på noden som sekundär.
I det här fallet konfigurerar du HANA-instansen som sekundär genom att köra det här kommandot:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
SUSE-tester
Viktigt!
Kontrollera att det operativsystem som du väljer är SAP-certifierat för SAP HANA på de specifika vm-typer som du planerar att använda. Du kan leta upp SAP HANA-certifierade VM-typer och deras OS-versioner i SAP HANA-certifierade IaaS-plattformar. Se till att du tittar på informationen om den typ av virtuell dator som du planerar att använda för att få en fullständig lista över SAP HANA-versioner som stöds för den virtuella datorn.
Kör alla testfall som visas i guiden för prestandaoptimerade SAP HANA SR-scenarion eller kostnadsoptimerade SAP HANA SR-scenarion, beroende på ditt scenario. Du hittar guiderna i SLES för bästa praxis för SAP.
Följande tester är en kopia av testbeskrivningarna av SAP HANA SR Performance Optimized Scenario SUSE Linux Enterprise Server for SAP Applications 12 SP1 guide. För en uppdaterad version läser du även själva guiden. Kontrollera alltid att HANA är synkroniserat innan du startar testet och kontrollera att Pacemaker-konfigurationen är korrekt.
I följande testbeskrivningar antar PREFER_SITE_TAKEOVER="true" vi och AUTOMATED_REGISTER="false".
Kommentar
Följande tester är utformade för att köras i följd. Varje test beror på utgångstillståndet för föregående test.
Test 1: Stoppa den primära databasen på nod 1.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Kör följande kommandon som <hana sid>adm på
hn1-db-0noden:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker identifierar den stoppade HANA-instansen och redundansväxlar till den andra noden. När redundansväxlingen är klar stoppas HANA-instansen
hn1-db-0på noden eftersom Pacemaker inte automatiskt registrerar noden som HANA sekundär.Kör följande kommandon för att registrera
hn1-db-0noden som sekundär och rensa den misslyckade resursen:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 2: Stoppa den primära databasen på nod 2.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Kör följande kommandon som <hana sid>adm på
hn1-db-1noden:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker identifierar den stoppade HANA-instansen och redundansväxlar till den andra noden. När redundansväxlingen är klar stoppas HANA-instansen
hn1-db-1på noden eftersom Pacemaker inte automatiskt registrerar noden som HANA sekundär.Kör följande kommandon för att registrera
hn1-db-1noden som sekundär och rensa den misslyckade resursen:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 3: Krascha den primära databasen på nod 1.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Kör följande kommandon som <hana sid>adm på
hn1-db-0noden:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker identifierar den dödade HANA-instansen och redundansväxlar till den andra noden. När redundansväxlingen är klar stoppas HANA-instansen
hn1-db-0på noden eftersom Pacemaker inte automatiskt registrerar noden som HANA sekundär.Kör följande kommandon för att registrera
hn1-db-0noden som sekundär och rensa den misslyckade resursen:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 4: Krascha den primära databasen på nod 2.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Kör följande kommandon som <hana sid>adm på
hn1-db-1noden:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker identifierar den dödade HANA-instansen och redundansväxlar till den andra noden. När redundansväxlingen är klar stoppas HANA-instansen
hn1-db-1på noden eftersom Pacemaker inte automatiskt registrerar noden som HANA sekundär.Kör följande kommandon för att registrera
hn1-db-1noden som sekundär och rensa den misslyckade resursen.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 5: Krascha den primära platsnoden (nod 1).
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Kör följande kommandon som rot på
hn1-db-0noden:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker identifierar den avdödade klusternoden och stänger noden. När noden är inhägnad utlöser Pacemaker ett övertagande av HANA-instansen. När den inhägnade noden startas om startar Pacemaker inte automatiskt.
Kör följande kommandon för att starta Pacemaker, rensa SBD-meddelandena för
hn1-db-0noden, registrerahn1-db-0noden som sekundär och rensa den misslyckade resursen:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 6: Krascha den sekundära platsnoden (nod 2).
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Kör följande kommandon som rot på
hn1-db-1noden:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker identifierar den avdödade klusternoden och stänger noden. När noden är inhägnad utlöser Pacemaker ett övertagande av HANA-instansen. När den inhägnade noden startas om startar Pacemaker inte automatiskt.
Kör följande kommandon för att starta Pacemaker, rensa SBD-meddelandena för
hn1-db-1noden, registrerahn1-db-1noden som sekundär och rensa den misslyckade resursen:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Test 7: Stoppa den sekundära databasen på nod 2.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Kör följande kommandon som <hana sid>adm på
hn1-db-1noden:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker identifierar den stoppade HANA-instansen och markerar resursen som misslyckad på
hn1-db-1noden. Pacemaker startar automatiskt om HANA-instansen.Kör följande kommando för att rensa det misslyckade tillståndet:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 8: Krascha den sekundära databasen på nod 2.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Kör följande kommandon som <hana sid>adm på
hn1-db-1noden:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker identifierar den dödade HANA-instansen och markerar resursen som misslyckad på
hn1-db-1noden. Kör följande kommando för att rensa det misslyckade tillståndet. Pacemaker startar sedan automatiskt om HANA-instansen.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 9: Krascha den sekundära platsnoden (nod 2) som kör den sekundära HANA-databasen.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Kör följande kommandon som rot på
hn1-db-1noden:hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker identifierar den avdödade klusternoden och avgränsar noden. När den inhägnade noden startas om startar Pacemaker inte automatiskt.
Kör följande kommandon för att starta Pacemaker, rensa SBD-meddelandena för noden och rensa den misslyckade resursen
hn1-db-1:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 10: Kraschindexserver för primär databas
Det här testet är endast relevant när du har konfigurerat susChkSrv-kroken enligt beskrivningen i Implementera HANA-krokar SAPHanaSR och susChkSrv.
Resurstillståndet innan testet startas:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Kör följande kommandon som rot på
hn1-db-0noden:hn1-db-0:~ # killall -9 hdbindexserverNär indexservern avslutas identifierar susChkSrv-kroken händelsen och utlöser en åtgärd för att stänga noden "hn1-db-0" och initiera en uppköpsprocess.
Kör följande kommandon för att registrera
hn1-db-0noden som sekundär och rensa den misslyckade resursen:# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Resurstillståndet efter testet:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Du kan köra ett jämförbart testfall genom att orsaka att indexservern på den sekundära noden kraschar. Om indexservern kraschar identifierar susChkSrv-kroken förekomsten och initierar en åtgärd för att avgränsa den sekundära noden.