Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Testning hjälper till att säkerställa att koden fungerar som förväntat, men tiden och arbetet med att skapa tester tar tid från andra uppgifter, till exempel funktionsutveckling. Med den här kostnaden är det viktigt att extrahera maximalt värde från testningen. I den här artikeln beskrivs DevOps-testprinciper med fokus på värdet av enhetstestning och en strategi för skift-vänster-test.
Dedikerade testare brukade skriva de flesta tester och många produktutvecklare lärde sig inte att skriva enhetstester. Att skriva tester kan verka för svårt eller som för mycket arbete. Det kan finnas skepticism om huruvida en enhetsteststrategi fungerar, dåliga erfarenheter av dåligt skrivna enhetstester eller rädsla för att enhetstester kommer att ersätta funktionella tester.

För att implementera en DevOps-teststrategi bör du vara pragmatisk och fokusera på att skapa momentum. Även om du kan insistera på enhetstester för ny kod eller befintlig kod som kan omstruktureras på ett korrekt sätt, kan det vara bra för en äldre kodbas att tillåta ett visst beroende. Om viktiga delar av produktkoden använder SQL kan det vara en kortsiktig metod att tillåta enhetstester att vara beroende av SQL-resursprovidern i stället för att håna det lagret.
När DevOps-organisationer mognar blir det lättare för ledningen att förbättra processerna. Även om det kan finnas ett visst motstånd mot förändring, värdesätter agila organisationer förändringar som tydligt ger utdelning. Det bör vara enkelt att sälja visionen om snabbare testkörningar med färre fel, eftersom det innebär mer tid att investera i att generera nytt värde genom funktionsutveckling.
DevOps-testtaxonomi
Att definiera en testtaxonomi är en viktig aspekt av DevOps-testningsprocessen. En DevOps-testtaxonomi klassificerar enskilda tester efter deras beroenden och den tid de tar att köra. Utvecklare bör förstå rätt typer av tester som ska användas i olika scenarier och vilka tester olika delar av processen kräver. De flesta organisationer kategoriserar tester på fyra nivåer:
- L0 - och L1-tester är enhetstester eller tester som är beroende av kod i sammansättningen som testas och inget annat. L0 är en bred klass av snabba minnesinterna enhetstester.
- L2 är funktionella tester som kan kräva sammansättningen plus andra beroenden, till exempel SQL eller filsystemet.
- L3-funktionstester körs mot testbara tjänstdistributioner. Den här testkategorin kräver en tjänstdistribution, men kan använda stubs för nyckeltjänstberoenden.
- L4-tester är en begränsad klass av integreringstester som körs mot produktion. L4-tester kräver en fullständig produktdistribution.
Även om det skulle vara idealiskt för alla tester att köras hela tiden, är det inte möjligt. Teams kan välja var i DevOps-processen som ska köra varje test och använda strategier för skift-vänster eller skift-höger för att flytta olika testtyper tidigare eller senare i processen.
Till exempel kan förväntningarna vara att utvecklare alltid kör L2-tester innan de genomför, en pull-begäran misslyckas automatiskt om L3-testkörningen misslyckas och distributionen kan blockeras om L4-testerna misslyckas. De specifika reglerna kan variera från organisation till organisation, men om du framtvingar förväntningarna för alla team inom en organisation går alla mot samma mål för kvalitetsvisionen.
Riktlinjer för enhetstest
Ange strikta riktlinjer för L0- och L1-enhetstester. Dessa tester måste vara mycket snabba och tillförlitliga. Till exempel bör den genomsnittliga körningstiden per L0-test i en sammansättning vara mindre än 60 millisekunder. Den genomsnittliga körningstiden per L1-test i en sammansättning bör vara mindre än 400 millisekunder. Inget test på den här nivån får överstiga 2 sekunder.
Ett Microsoft-team kör över 60 000 enhetstester parallellt på mindre än sex minuter. Deras mål är att minska den här tiden till mindre än en minut. Teamet spårar körningstiden för enhetstester med verktyg som följande diagram och rapporterar buggar mot tester som överskrider den tillåtna tiden.
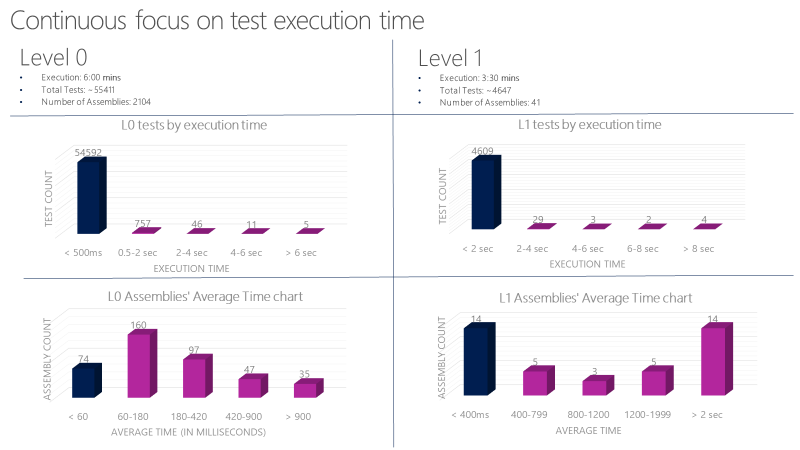
Riktlinjer för funktionstest
Funktionella tester måste vara oberoende. Huvudkonceptet för L2-tester är isolering. Korrekt isolerade tester kan köras tillförlitligt i valfri sekvens, eftersom de har fullständig kontroll över miljön de kör i. Tillståndet måste vara känt i början av testet. Om ett test skapade data och lämnade dem i databasen kan det skada körningen av ett annat test som förlitar sig på ett annat databastillstånd.
Äldre tester som behöver en användaridentitet kan ha anropat externa autentiseringsprovidrar för att hämta identiteten. Den här metoden medför flera utmaningar. Det externa beroendet kan vara otillförlitligt eller otillgängligt tillfälligt, vilket bryter testet. Den här metoden strider också mot principen för testisolering eftersom ett test kan ändra tillståndet för en identitet, till exempel behörighet, vilket resulterar i ett oväntat standardtillstånd för andra tester. Överväg att förhindra dessa problem genom att investera i identitetsstöd inom testramverket.
DevOps-testprinciper
För att hjälpa till att överföra en testportfölj till moderna DevOps-processer kan du formulera en kvalitetsvision. Teams bör följa följande testprinciper när de definierar och implementerar en DevOps-teststrategi.
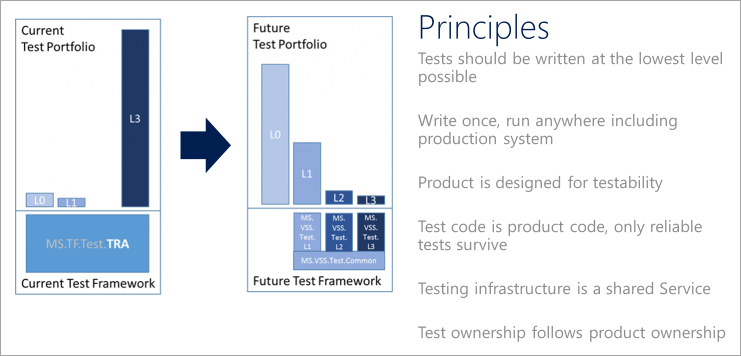
Flytta vänster för att testa tidigare
Det kan ta lång tid att köra tester. I takt med att projekten skalas ökar testnumren och typerna avsevärt. När testsviterna växer till att ta timmar eller dagar att slutföra kan de fördröjas längre tills de körs i sista möjliga stund. Kodkvalitetsfördelarna med testningen realiseras inte förrän långt efter att koden har bekräftats.
Långvariga tester kan också leda till fel som är tidskrävande att undersöka. Teams kan skapa en tolerans för fel, särskilt tidigt i sprintar. Den här toleransen undergräver värdet av testning som insikt i kodbaskvalitet. Långvariga tester i sista minuten ger också oförutsägbarhet till förväntningarna i slutet av sprinten, eftersom en okänd mängd teknisk skuld måste betalas för att få koden levererad.
Målet med att flytta testningen till vänster är att flytta kvaliteten uppströms genom att utföra testuppgifter tidigare i pipelinen. Genom en kombination av test- och processförbättringar minskar vänsterväxling både den tid det tar för tester att köras och effekten av fel senare i cykeln. Om du flyttar vänster ser du till att de flesta testerna slutförs innan en ändring sammanfogas till huvudgrenen.
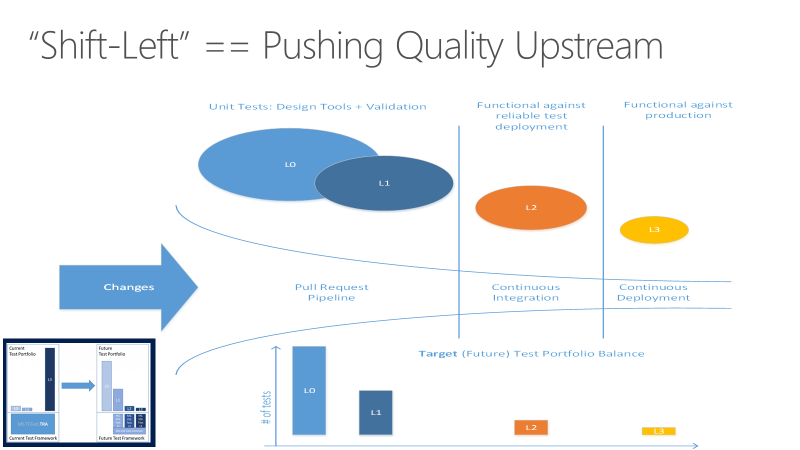
Förutom att flytta vissa testansvar tidigare i processen för att förbättra kodkvaliteten, kan teamen flytta andra testaspekter senare i DevOps-cykeln för att förbättra slutprodukten. Mer information finns i Förflyttning till höger för att testa i produktion.
Skrivtester på lägsta möjliga nivå
Skriv fler enhetstester. Prioritera tester med minst externa beroenden och fokusera på att köra de flesta tester som en del av bygget. Överväg ett parallellt byggsystem som kan köra enhetstester för en sammansättning så snart sammansättningen och associerade tester släpps. Det är inte möjligt att testa alla aspekter av en tjänst på den här nivån, men principen är att använda lättare enhetstester om de kan ge samma resultat som tyngre funktionella tester.
Sikta på testtillförlitlighet
Ett opålitligt test är organisatoriskt dyrt att underhålla. Ett sådant test fungerar direkt mot det tekniska effektivitetsmålet genom att göra det svårt att göra ändringar med tillförsikt. Utvecklare bör kunna göra ändringar var som helst och snabbt få förtroende för att inget har brutits. Håll en hög standard för tillförlitlighet. Avråder från att använda användargränssnittstester eftersom de tenderar att vara otillförlitliga.
Skriva funktionella tester som kan köras var som helst
Tester kan använda specialiserade integreringspunkter som utformats specifikt för att aktivera testning. En orsak till denna praxis är bristen på testbarhet i själva produkten. Tyvärr beror tester som dessa ofta på intern kunskap och använder implementeringsinformation som inte spelar någon roll ur ett funktionellt testperspektiv. Dessa tester är begränsade till miljöer som har de hemligheter och den konfiguration som krävs för att köra testerna, vilket vanligtvis utesluter produktionsdistributioner. Funktionella tester bör endast använda produktens offentliga API.
Utforma produkter för testbarhet
Organisationer i en mognande DevOps-process har en fullständig överblick över vad det innebär att leverera en kvalitetsprodukt i en molntakt. Att flytta balansen starkt till förmån för enhetstestning framför funktionell testning kräver att teamen gör design- och implementeringsval som stöder testbarhet. Det finns olika idéer om vad som utgör väl utformad och väl implementerad kod för testbarhet, precis som det finns olika kodningsformat. Principen är att design för testbarhet måste bli en primär del av diskussionen om design och kodkvalitet.
Behandla testkod som produktkod
Att uttryckligen ange att testkoden är produktkod gör det tydligt att kvaliteten på testkoden är lika viktig för leveransen som för produktkoden. Teams bör behandla testkoden på samma sätt som de behandlar produktkod och tillämpa samma vårdnivå på utformning och implementering av tester och testramverk. Den här ansträngningen liknar att hantera konfiguration och infrastruktur som kod. För att vara komplett bör en kodgranskning överväga testkoden och hålla den till samma kvalitetsnivå som produktkoden.
Använda delad testinfrastruktur
Sänk ribban för att använda testinfrastrukturen för att generera betrodda kvalitetssignaler. Visa testning som en delad tjänst för hela teamet. Lagra enhetstestkoden tillsammans med produktkoden och skapa den med produkten. Tester som körs som en del av byggprocessen måste också köras under utvecklingsverktyg som Azure DevOps. Om tester kan köras i alla miljöer från lokal utveckling till produktion har de samma tillförlitlighet som produktkoden.
Gör kodägare ansvariga för testning
Testkoden ska finnas bredvid produktkoden på en lagringsplats. För att kod ska testas vid en komponentgräns skickar du ansvar för testning till den person som skriver komponentkoden. Lita inte på att andra testar komponenten.
Fallstudie: Skift vänster med enhetstester
Ett Microsoft-team bestämde sig för att ersätta sina äldre testsviter med moderna DevOps-enhetstester och en skift-vänster-process. Teamet spårade framsteg i treveckorssprintar, som visas i följande diagram. Diagrammet täcker sprintar 78-120, som representerar 42 sprintar under 126 veckor, eller cirka två och ett halvt års ansträngning.
Teamet började med 27 000 äldre tester i sprint 78 och nådde noll äldre tester på S120. En uppsättning L0- och L1-enhetstester ersatte de flesta av de gamla funktionella testerna. Nya L2-tester ersatte några av testerna och många av de gamla testerna togs bort.
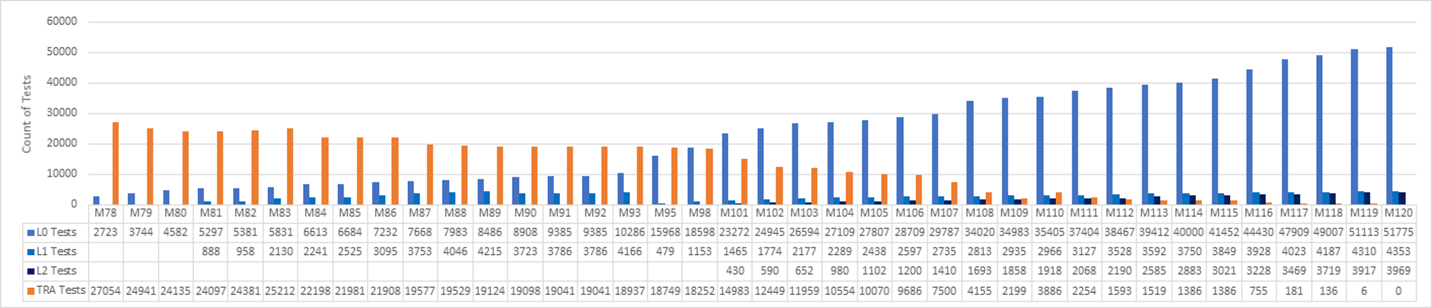
I en programvaruresa som tar över två år att slutföra finns det mycket att lära av själva processen. Sammantaget var försöket att helt göra om testsystemet under två år en massiv investering. Det var inte alla funktionsteam som utförde arbetet på samma gång. Många lag i organisationen investerade tid i varje sprint, och i vissa sprintar var det det mesta av vad laget gjorde. Även om det är svårt att mäta kostnaden för skiftet, var det ett icke-förhandlingsbart krav för lagets kvalitets- och prestationsmål.
Komma igång
I början lämnade teamet de gamla funktionella testerna, som kallas TRA-tester, ensamma. Teamet ville att utvecklarna skulle köpa in sig i idén att skriva enhetstester, särskilt för nya funktioner. Fokus låg på att göra det så enkelt som möjligt att skapa L0- och L1-tester. Teamet behövde utveckla den funktionen först och bygga upp momentum.
Föregående diagram visar hur antalet enhetstester började öka tidigt, eftersom teamet såg fördelen med att skriva enhetstester. Enhetstester var enklare att underhålla, snabbare att köra och hade färre fel. Det var enkelt att få stöd för att köra alla enhetstester i pull-begärandeflödet.
Teamet fokuserade inte på att skriva nya L2-tester förrän sprint 101. Under tiden sjönk TRA-testantalet från 27 000 till 14 000 från Sprint 78 till Sprint 101. Nya enhetstester ersatte några av TRA-testerna, men många togs helt enkelt bort, baserat på teamanalys av deras användbarhet.
TRA-testerna hoppade från 2100 till 3800 i sprint 110 eftersom fler tester upptäcktes i källträdet och lades till i diagrammet. Det visade sig att testerna alltid hade körts, men inte följdes upp korrekt. Detta var inte en kris, men det var viktigt att vara ärlig och omvärdera efter behov.
Snabbare
När teamet hade en kontinuerlig integreringssignal (CI) som var extremt snabb och tillförlitlig blev den en betrodd indikator för produktkvalitet. Följande skärmbild visar pull-begäran och CI-pipelinen i praktiken och den tid det tar att gå igenom olika faser.
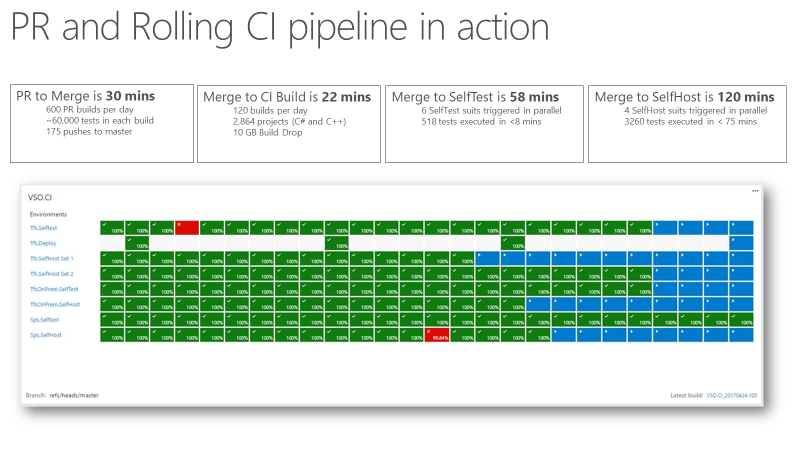
Det tar cirka 30 minuter att gå från pull-begäran till sammanslagning, vilket inkluderar att köra 60 000 enhetstester. Från kodsammanslagning till CI-version är cirka 22 minuter. Den första kvalitetssignalen från CI, SelfTest, kommer efter ungefär en timme. Sedan testas merparten av produkten med den föreslagna ändringen. Inom två timmar från Merge till SelfHost testas hela produkten och ändringen är redo att börja användas i produktion.
Använda mått
Teamet spårar en prestationstavla som i följande exempel. På en hög nivå spårar styrkortet två typer av mått: Hälsa eller skuld och hastighet.
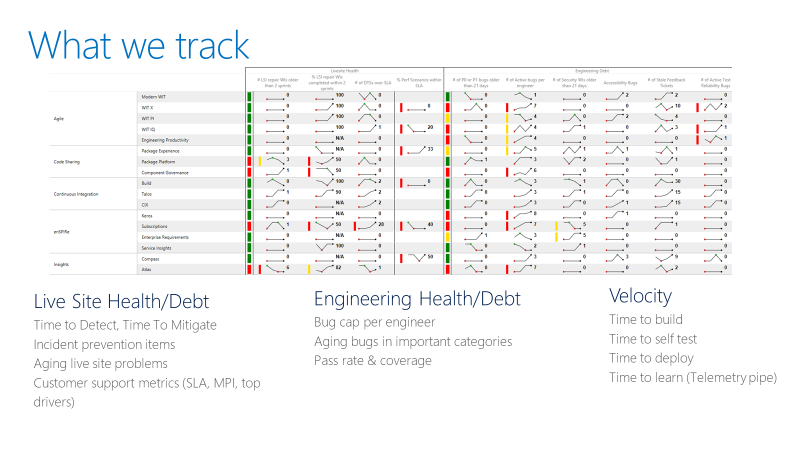
För hälsomått för livewebbplatser spårar teamet tiden för att identifiera, tid för att minimera och hur många reparationsobjekt ett team har. Ett reparationsobjekt är ett arbete som teamet identifierar i en realtidswebbplatss retrospektiv för att förhindra att liknande incidenter upprepas. Poängkortet registrerar också ifall teamen avslutar reparationsärendena inom en rimlig tidsram.
För tekniska hälsomått spårar teamet aktiva buggar per utvecklare. Om ett team har fler än fem buggar per utvecklare måste teamet prioritera att åtgärda buggarna innan den nya funktionsutvecklingen. Teamet spårar också åldrande buggar i särskilda kategorier som säkerhet.
Ingenjörshastighetsmått mäter hastighet i olika delar av CI/CD-pipeline (continuous integration and continuous delivery). Det övergripande målet är att öka hastigheten för DevOps-pipelinen: Börja från en idé, få koden till produktion och ta emot data tillbaka från kunderna.