Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Skift höger är praxis att flytta vissa tester senare i DevOps-processen för att testa i produktion. Testning i produktion använder verkliga distributioner för att verifiera och mäta ett programs beteende och prestanda i produktionsmiljön.
Ett sätt för DevOps-team att förbättra hastigheten är med en strategi för skift-vänster-test . Skift vänster push-överför de flesta tester tidigare i DevOps-pipelinen för att minska tiden för ny kod att nå produktion och fungera tillförlitligt.
Men även om många typer av tester, till exempel enhetstester, enkelt kan flyttas åt vänster, kan vissa klasser av tester inte köras utan att distribuera en del av eller hela lösningen. Distribution till en QA- eller mellanlagringstjänst kan simulera en jämförbar miljö, men det finns inget fullständigt substitut för produktionsmiljön. Team upptäcker att vissa typer av tester måste ske i produktion.
Testning i produktion ger:
- Den fullständiga bredden och mångfalden i produktionsmiljön.
- Den verkliga arbetsbelastningen för kundtrafik.
- Profiler och beteenden när produktionsefterfrågan utvecklas över tid.
Produktionsmiljön ändras hela tiden. Även om en app inte ändras förlitar sig den infrastruktur som den förlitar sig på ständigt. Testning i produktion validerar hälsotillståndet och kvaliteten för en viss produktionsdistribution och den ständigt föränderliga produktionsmiljön.
Det är särskilt viktigt att flytta rätten att testa i produktion i följande scenarier:
Distributioner av mikrotjänster
Mikrotjänstbaserade lösningar kan ha ett stort antal mikrotjänster som utvecklas, distribueras och hanteras oberoende av varandra. Att ändra testrätt är särskilt viktigt för dessa projekt, eftersom olika versioner och konfigurationer kan nå produktion på många sätt. Oavsett förproduktionstesttäckning är det nödvändigt att testa kompatibiliteten i produktionen.
Säkerställa kvalitet efter distribution
Att släppa till produktion är bara hälften av att leverera programvara. Den andra hälften säkerställer kvalitet i stor skala med en verklig arbetsbelastning i produktionen. Eftersom miljön hela tiden förändras görs aldrig ett team med testning i produktion.
Testdata från produktion är bokstavligen testresultatet från den verkliga kundarbetsbelastningen. Testning i produktion omfattar övervakning, redundanstestning och felinmatning. Den här testningen spårar fel, undantag, prestandamått och säkerhetshändelser. Testtelemetrin hjälper också till att identifiera avvikelser.
Distributionsnivåer
För att skydda produktionsmiljön kan team distribuera ändringar på ett progressivt och kontrollerat sätt med hjälp av nivåbaserade distributioner och funktionsflaggor. Det är till exempel bättre att fånga en bugg som hindrar en kund från att slutföra sitt köp när mindre än 1% av kunderna är på den distributionsnivån, än efter att ha bytt alla kunder samtidigt. Funktionsvärdet med identifierade fel måste överskrida nettoförlusterna för dessa fel, mätt på ett meningsfullt sätt för den aktuella verksamheten.
Den första nivån ska vara den minsta storlek som krävs för att köra standardintegreringssviten. Testerna kan likna dem som redan kördes tidigare i pipelinen mot andra miljöer, men testningen verifierar att beteendet är detsamma i produktionsmiljön. Den här nivån identifierar uppenbara fel, till exempel felkonfigurationer, innan de påverkar några kunder.
När den första nivån har verifierats kan nästa nivå breddas till att omfatta en delmängd av verkliga användare för testkörningen. Om allt ser bra ut kan distributionen gå igenom ytterligare nivåer och tester tills alla använder den. Fullständig distribution innebär inte att testningen är över. Spårning av telemetri är mycket viktigt för testning i produktion.
Felinsprutning
Team använder ofta felinmatning och kaosteknik för att se hur ett system beter sig under felförhållanden. Dessa metoder hjälper dig att:
- Verifiera att implementerade återhämtningsmekanismer faktiskt fungerar.
- Kontrollera att ett fel i ett undersystem finns i undersystemet och inte överlappar för att skapa ett större avbrott.
- Bevisa att reparationsarbetet för en tidigare incident har önskad effekt, utan att behöva vänta tills en annan incident inträffar.
- Skapa mer realistiska träningsövningar för live-platstekniker så att de bättre kan förbereda sig för att hantera incidenter.
Det är en bra idé att automatisera felinmatningsexperiment eftersom det är dyra tester som måste köras på ständigt föränderliga system.
Chaos Engineering kan vara ett effektivt verktyg, men bör begränsas till kanariemiljöer som har liten eller ingen kundpåverkan.
Redundanstestning
En form av felinmatning är redundanstestning för att stödja affärskontinuitet och haveriberedskap (BCDR). Teams bör ha redundansplaner för alla tjänster och undersystem. Planerna bör innehålla:
- En tydlig förklaring av hur tjänsten påverkas.
- En karta över alla beroenden när det gäller plattform, teknik och personer som utformar BCDR-planerna.
- Formell dokumentation om haveriberedskapsförfaranden.
- En takt för att regelbundet köra haveriberedskapstest.
Feltestning av kretsbrytare
En kretsbrytare avbryter en viss komponent från ett större system, vanligtvis för att förhindra att fel i komponenten sprids utanför dess gränser. Du kan avsiktligt utlösa kretsbrytare för att testa följande scenarier:
Om en reserv fungerar när kretsbrytaren öppnas. Återställningen kan fungera med enhetstester, men det enda sättet att veta om den fungerar som förväntat i produktionen är att mata in ett fel för att utlösa det.
Om kretsbrytaren har rätt känslighetströskel för att öppnas när den behöver det. Felinmatning kan tvinga svarstid eller koppla från beroenden för att observera brytpunktsresponsivitet. Det är viktigt att inte bara kontrollera att rätt beteende inträffar, utan att det sker tillräckligt snabbt.
Exempel: Testa en Redis-cache kretsbrytare
Redis Cache förbättrar produktprestandan genom att påskynda åtkomsten till vanliga data. Tänk dig ett scenario som tar ett icke-kritiskt beroende av Redis. Om Redis slutar fungera bör systemet fortsätta att fungera eftersom det kan återgå till att använda den ursprungliga datakällan för begäranden. Kontrollera att ett Redis-fel utlöser en kretsbrytare och att återställningen fungerar i produktion genom att regelbundet köra tester mot dessa beteenden.
Följande diagram visar tester för redis-kretsbrytarens återställningsbeteende. Målet är att se till att anrop i slutänden går till SQL när brytaren öppnas.
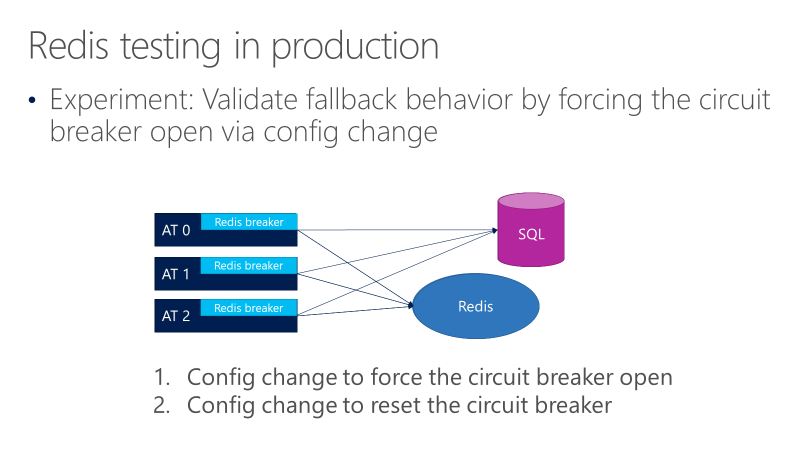
Föregående diagram visar tre AT:er, med brytarna framför anropen till Redis. Ett test tvingar kretsbrytaren att öppna genom en konfigurationsändring och kontrollerar sedan om anropen går till SQL. Ett annat test kontrollerar sedan den motsatta konfigurationsändringen genom att stänga kretsbrytaren för att bekräfta att anropen återgår till Redis.
Det här testet verifierar att återställningsbeteendet fungerar när brytaren öppnas, men det verifierar inte att kretsbrytarkonfigurationen öppnar brytaren när den ska. Att testa det beteendet kräver att faktiska fel simuleras.
En felagent kan introducera fel i anrop som går till Redis. Följande diagram visar testning med felinmatning.
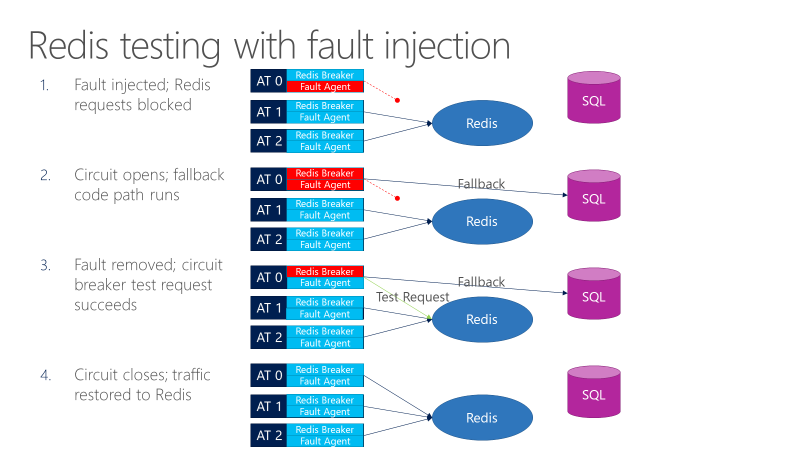
- Felinjektorn blockerar Redis-begäranden.
- Kretsbrytaren öppnas och testet kan se om reserven fungerar.
- Felet tas bort och kretsbrytaren skickar en testbegäran till Redis.
- Om begäran lyckas återgår anropen till Redis.
Ytterligare steg kan testa brytarens känslighet, om tröskelvärdet är för högt eller för lågt och om andra systemtimeouter stör kretsbrytarbeteendet.
I det här exemplet kan det orsaka en liveplatsincident (LSI) om brytaren inte öppnas eller stängs som förväntat. Utan felinmatningstestningen kan problemet gå oupptäckt, eftersom det är svårt att göra den här typen av testning i en labbmiljö.
Nästa steg
- [Skifttestning kvar med enhetstester]skift-vänster
- Vad är mikrotjänster?
- Köra ett redundanstest (haveriberedskapstest) till Azure
- Säkra distributionsmetoder
- Vad är övervakning?
- Vad är plattformsteknik?