Regelverk vid dataförening
När du ställer in regler för att förena dina data till en kundprofil bör du tänka på följande metodtips:
Balansera tiden för att förena kontra fullständig matchning. Att försöka fånga alla möjliga matchningar leder till många regler och att enandet tar lång tid.
Lägg till regler progressivt och spåra resultaten. Ta bort regler som inte förbättrar matchresultatet.
Deduplicera varje tabell så att varje kund representeras på en enda rad.
Använd normalisering för att standardisera variationer i hur data angavs, till exempel Street vs. St vs. St. vs. st.
Använd fuzzy-matchning strategiskt för att korrigera stavfel och fel som t.ex bob@contoso.com bob@contoso.cm. Fuzzy-matchningar tar längre tid att köra än exakta matchningar. Testa alltid för att se om den extra tid som spenderas på fuzzy-matchning är värd den extra matchningsfrekvensen.
Begränsa omfattningen av matchningar med exakt matchning. Se till att varje regel med fuzzy-villkor har minst ett exakt matchningsvillkor.
Matcha inte kolumner som innehåller kraftigt upprepade data. Se till att fuzzy-matchade kolumner inte har värden som upprepas ofta, till exempel ett formulärs standardvärde "Förnamn".
Prestanda för förenande
Varje regel tar tid att köra. Mönster som att jämföra varje tabell med alla andra tabeller eller försöka samla in alla möjliga postmatchningar kan leda till långa bearbetningstider för förening. Den returnerar också få, om ens några, matchningar över en plan som jämför varje tabell med en bastabell.
Det bästa sättet är att börja med en grundläggande uppsättning regler som du vet behövs, till exempel att jämföra varje tabell med din primära tabell. Din primära tabell bör vara den tabell som har de mest fullständiga och korrekta data. Den här tabellen ska sorteras högst upp i steget för att förena matchningsregler.
Lägg till flera regler progressivt och se hur lång tid det tar att köra ändringarna och om dina resultat förbättras. Gå till Inställningar>Systemstatus> och väljMatch för att se hur lång tid deduplicering och matchning tog för varje sammanslagningskörning.
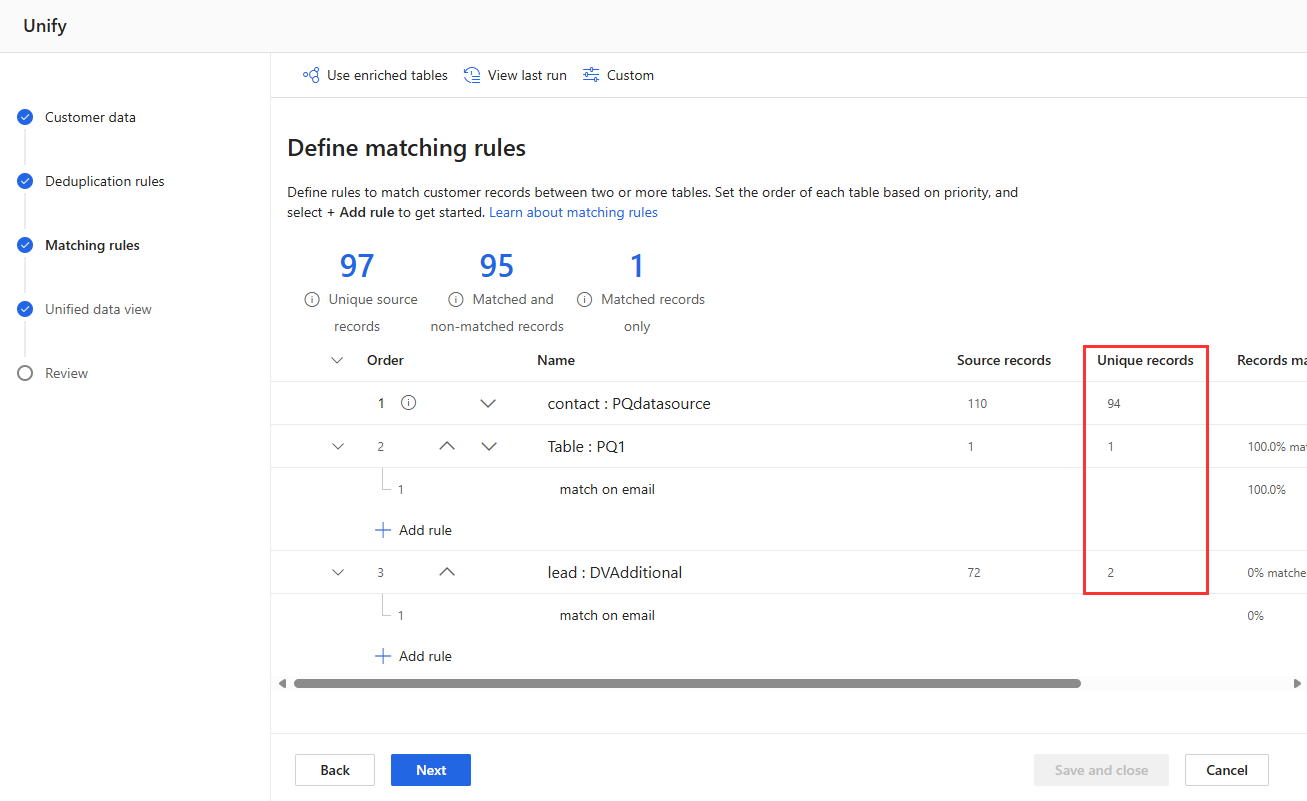
Visa regelstatistiken på sidorna Dedupliceringsregler och Matchningsregler för att se om antalet unika poster ändras. Om en ny regel matchar vissa poster och det unika antalet poster inte ändras, identifierar en tidigare regel dessa matchningar.
Deduplication
Använd dedupliceringsregler för att ta bort dubbletter av kundposter i en tabell så att en enda rad i varje tabell representerar varje kund. En bra regel identifierar en unik kund.
I det här enkla exemplet delar posterna 1, 2 och 3 antingen en e-postadress eller ett telefonnummer och representerar samma person.
| ID | Name | Telefon | |
|---|---|---|---|
| 1 | Person 1 | (425) 555-1111 | AAA@A.com |
| 2 | Person 1 | (425) 555-1111 | BBB@B.com |
| 3 | Person 1 | (425) 555-2222 | BBB@B.com |
| 4 | Person 2 | (206) 555-9999 | Person2@contoso.com |
Vi vill inte matcha med ett namn som matchar olika personer med samma namn.
Skapa regel 1 med hjälp av Namn och Telefon, som matchar post 1 och 2.
Skapa regel 2 med hjälp av Namn och E-post, som matchar post 2 och 3.
Kombinationen av Regel 1 och Regel 2 skapar en enskild matchningsgrupp eftersom de delar post 2.
Du bestämmer antalet regler och villkor som unikt identifierar dina kunder. De exakta reglerna beror på vilka data du har tillgängliga att matcha, kvaliteten på dina data och hur omfattande du vill att dedupliceringsprocessen ska vara.
Vinnare och alternativa poster
När regler har körts och dubblettposter har identifierats väljer dedupliceringsprocessen en "Vinnarrad". Raderna som inte vinner kallas "Varannan rad". Alternativa rader används i steget Sammanslagning av matchningsregler för att matcha poster från andra tabeller till vinnarraden. Rader matchas mot data i de alternativa raderna förutom på raden med kolumner.
När du har lagt till en regel i en tabell kan du konfigurera vilken rad som ska välj som vinnarrad via Sammanfogningsinställningar. Kopplingsinställningarna anges per tabell. Oavsett vilken sammanfogningsprincip som väljs används den första raden i dataordningen som utslagsfråga om det Dit finns ett oavgjort resultat för en vinnarrad.
Normalisering
Använd normalisering för att standardisera data för bättre matchning. Normalisering fungerar bra på stora mängder data.
De normaliserade data används bara för jämförelseändamål för att matcha kundregister mer effektivt. Det ändrar inte data i den slutliga enhetliga kundprofilen.
| Normalisering | Exempel |
|---|---|
| Siffror | Konverterar många Unicode-symboler som representerar tal till enkla tal. Exempel: ❽ och VIII. är båda normaliserade till talet 8. Obs! Symbolerna måste kodas i Unicode Point Format. |
| Symboler | Tar bort alla symboler och specialtecken. Exempel: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| Text till gemener | Konverterar versaler till gemener. Exempel: "THIS Is aN EXamplE" konverteras till "detta är ett example" |
| Typ – Telefon | Konverterar telefoner i olika format till siffror och tar hänsyn till variationer i hur landskoder och anknytningar presenteras. Exempel: +01 425.555.1212 = 1 (425) 555-1212 |
| Typ – Namn | Konverterar över 500 vanliga namnvarianter och titlar. Exempel: "debby" -> "deborah" "prof" och "professor" -> "Prof." |
| Typ – Adress | Konverterar vanliga adressdelar Exempel: "street" -> "st" och "northwest" -> "nw" |
| Typ – Organisation | Tar bort cirka 50 företagsnamn "bullerord" som "co", "corp", "corporation" och "ltd." |
| Unicode till ASCII | Konverterar Unicode-tecken till deras ASCII-motsvarighet i bokstäver Exempel: Tecknen à, á, â, À, Á, Â, Ã, Ä, Ⓐ och A konverteras till "a". |
| Tomt utrymme | Tar bort alla blanksteg |
| Aliasmappning | Gör att du kan ladda upp en anpassad lista med strängpar som sedan kan användas för att ange strängar som alltid ska betraktas som en exakt matchning. Använd aliasmapping när du har specifika dataexempel som du tycker borde matcha och som inte matchas med något av de andra normaliseringsmönstren. Exempel: Scott och Scooter, eller MSFT och Microsoft. |
| Anpassad överhoppning | Gör att du kan ladda upp en anpassad lista med strängar som sedan kan användas för att ange strängar som aldrig ska matchas. Anpassad förbikoppling är användbart när du har data med vanliga värden som ska ignoreras, till exempel ett dummy-telefonnummer eller ett dummy-e-postmeddelande. Exempel: Matcha aldrig telefonen 555-1212, eller test@contoso.com |
Exakt matchning
Använd precision för att avgöra hur nära två strängar ska vara för att betraktas som en matchning. Standardinställningen för precision kräver en exakt matchning. Alla andra värden möjliggör fuzzy-matchning för det villkoret.
Precision kan ställas in på låg (30 procent matchning), medium (60 procent matchning) och hög (80 procent matchning). Eller så kan du anpassa och ställa in precisionen i steg om 1 %.
Exakta matchningsvillkor
De exakta matchningsvillkoren körs först för att få en mindre uppsättning värden för fuzzy-matchningar. För att vara effektiva bör de exakta matchningsvillkoren ha en rimlig grad av unikhet. Om alla dina kunder till exempel bor i samma land/region skulle det inte hjälpa att begränsa omfattningen om du har en exakt matchning i landet/regionen.
Kolumner som fullständigt namn, e-post, telefon eller adressfält har god unikhet och är bra kolumner att använda som en exakt matchning.
Se till att kolumnen som du använder för ett exakt matchningsvillkor inte har några värden som upprepas ofta, till exempel standardvärdet "Förnamn" som avbildas av ett formulär. Customer Insights kan profilera datakolumner för att ge insikter om de vanligaste upprepade värdena. Du kan aktivera dataprofilering på Azure Data Lake-anslutningar (med Common Data Model eller Delta-format) och Synapse. Dataprofilen körs nästa gång datakällan uppdateras. Mer information finns i Dataprofilering.
Fuzzy-matchning
Använd fuzzy-matchning för att matcha strängar som är nära men som inte är exakta på grund av stavfel eller andra små variationer. Använd fuzzy-matchning strategiskt eftersom det är långsammare än exakta matchningar. Se till att det finns minst ett exakt matchningsvillkor i alla regler som har fuzzy-villkor.
Fuzzy-matchning är inte avsedd att samla in namnvarianter som Suzzie och Suzanne. Dessa varianter avbildas bättre med normaliseringsmönstret Typ: Namn eller den anpassade aliasmatchningen där kunder kan ange sin lista över namnvarianter som de vill betrakta som matchningar.
Du kan lägga till villkor i en regel, till exempel matchande FirstName och Telefon. Villkor inom en viss regel är "OCH"-villkor. Varje villkor måste matcha för att raderna ska matcha. Separata regler är "ELLER"-villkor. Om regel 1 inte matchar raderna jämförs raderna med regel 2.
Obs
Endast kolumner för datatypen sträng kan använda fuzzy-matchning. För kolumner med andra datatyper, till exempel heltal, dubbel eller datetime, är precisionsfältet skrivskyddat och inställt på den exakta matchningen.
Beräkningar för fuzzy-matchning
Fuzzy-matchningar bestäms genom att beräkna redigeringsavståndspoängen mellan två strängar. Om poängen uppfyller eller överskrider precisionströskeln betraktas strängarna som en matchning.
Redigeringsavståndet är antalet redigeringar som krävs för att omvandla en sträng till en annan, genom att lägga till, ta bort eller ändra ett tecken.
Till exempel har strängarna "Jacqueline" och "Jaclyne" ett redigeringsavstånd på fem när vi tar bort tecknen q, u, e, i och e och infogar y-tecknet.
För att beräkna poängen för redigeringsavstånd, använd den här formeln: (Basstränglängd – Redigera avstånd) / Basstränglängd.
| Bassträng | Jämförelsesträng | Poäng |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=.6 |
| fred@contoso.com | fred@contso.cm | (14-2)/14 = 0,857 |
| franklin | frank | (8-3) / 8 = 0,625 |