Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller vägledning om hur du använder den utökade Apache Spark-historikservern för att felsöka och diagnostisera slutförda och köra Apache Spark-program.
Få åtkomst till Apache Spark-historikservern
Apache Spark-historikservern är webbanvändargränssnittet för slutförda och köra Spark-program. Du kan öppna Apache Spark-webbanvändargränssnittet (UI) från notebook-filen för förloppsindikatorn eller apache Spark-programinformationssidan.
Öppna Spark-webbgränssnittet från anteckningsboken med förloppsindikator.
När ett Apache Spark-jobb utlöses finns knappen för att öppna Spark-webbgränssnittet i åtgärdsalternativet Mer i förloppsindikatorn. Välj Spark-webbgränssnittet och vänta några sekunder. Sidan Spark-användargränssnitt visas.

Öppna Spark-webbgränssnittet från apache Spark-programinformationssidan
Spark-webbgränssnittet kan också öppnas via informationssidan för Apache Spark-programmet. Välj Övervaka till vänster på sidan och välj sedan ett Apache Spark-program. Informationssidan för programmet visas.

För ett Apache Spark-program vars status körs visar knappen Spark-användargränssnittet. Välj Spark-användargränssnitt så visas sidan Spark-användargränssnitt.

För ett Apache Spark-program som har avslutats kan statusen vara Stoppad, Misslyckad, Avbruten eller Slutförd. Knappen visar Spark-historikservern. Välj Spark-historikserver och sidan Spark-användargränssnitt visas.

Fliken Graph i Apache Spark-historikservern
Välj jobb-ID:t för det jobb som du vill visa. Sedan, välj Graph på verktygsmenyn för att få jobbgrafvyn.
Översikt
Du kan se en översikt över ditt jobb i det genererade jobbdiagrammet. Som standard visar diagrammet alla jobb. Du kan filtrera den här vyn efter jobb-ID.

Skärm
Som standard är förloppsvisningen markerad. Du kan kontrollera dataflödet genom att välja Läs eller Skriveti listrutan Visa .

Grafnoden visar färgerna som visas i heatmap-förklaringen.

Uppspelning
Om du vill spela upp jobbet väljer du Uppspelning. Du kan välja Stoppa när som helst för att stoppa. Aktivitetsfärgerna visar olika statusar när du spelar upp:
| Färg | Innebörd |
|---|---|
| Grönt | Lyckades: Jobbet har slutförts. |
| Orange | Återförsök: Instanser av uppgifter som misslyckades men som inte påverkar det slutliga resultatet av jobbet. Dessa uppdrag hade duplicerade eller återförsöksförekomster som kan lyckas senare. |
| Blått | Körs: Uppgiften körs. |
| Vitt | Väntar eller hoppats över: Aktiviteten väntar på att köras eller så har delsteget hoppats över. |
| Röd | Misslyckades: Aktiviteten misslyckades. |
Följande bild visar gröna, orange och blå statusfärger.

Följande bild visar gröna och vita statusfärger.

Följande bild visar röda och gröna statusfärger.

Anteckning
Apache Spark-historikservern tillåter uppspelning för varje slutfört jobb (men tillåter inte uppspelning för ofullständiga jobb).
Zooma
Använd musrullningen för att zooma in och ut på jobbdiagrammet, eller välj Zooma så att det passar för skärmen.

Verktygstips
Hovra över noden i grafen för att se verktygstipset när det finns misslyckade uppdrag och välj en fas för att öppna sidan för fasen.

På fliken jobbdiagram har faserna en knappbeskrivning och en liten ikon som visas om de har uppgifter som uppfyller följande villkor:
| Villkor | beskrivning |
|---|---|
| Dataskev | Dataläsningsstorlek > genomsnittlig dataläsningsstorlek för alla aktiviteter i den här fasen * 2 och dataläsningsstorlek > 10 MB. |
| Tidsförskjutning | Körningstid > genomsnittlig körningstid för alla uppgifter i det här steget gånger 2 och körningstid > 2 minuter. |
![]()
Beskrivning av grafnod
Jobbdiagramnoden visar följande information för varje steg:
- ID
- Namn eller beskrivning
- Totalt uppgiftsnummer
- Läsdata: summan av indatastorleken och shuffle-lässtorleken
- Dataskrivning: summan av utdatastorleken och shuffle-skrivstorleken
- Körningstid: tiden mellan starttiden för det första försöket och slutförandetiden för det senaste försöket
- Radantal: summan av indataposter, utdataposter, shuffle-läs-poster och shuffle-skriv-poster
- Förlopp
Kommentar
Som standardinställning visar jobbdiagramnoden information från det senaste försöket i varje steg (förutom exekveringstid för steg). Under uppspelningen visar grafnoden dock information om varje försök.
Datastorleken för läsning och skrivning är 1 MB = 1 000 KB = 1 000 * 1 000 byte.
Lämna feedback
Skicka feedback med problem genom att välja Ge oss feedback.

Gräns för stegnummer
För prestandaövervägande är diagrammet som standard endast tillgängligt när Spark-programmet har mindre än 500 steg. Om det finns för många steg misslyckas det med ett fel som det här:
The number of stages in this application exceeds limit (500), graph page is disabled in this case.
Som en lösning bör du använda den här Spark-konfigurationen för att öka gränsen innan du startar ett Spark-program:
spark.ui.enhancement.maxGraphStages 1000
Observera dock att detta kan orsaka dåliga prestanda för sidan och API:et, eftersom innehållet kan vara för stort för att webbläsaren ska kunna hämta och rendera.
Utforska fliken Diagnos i Apache Spark-historikservern
Om du vill komma åt fliken Diagnos väljer du ett jobb-ID. Välj sedan Diagnos på verktygsmenyn för att få jobbvyn Diagnos. Fliken Diagnos innehåller analys av dataförskjutning, tidsförskjutning och analys av executor-användning.
Kontrollera analys av dataförskjutning, tidsförskjutning och körningsanvändning genom att välja flikarna.

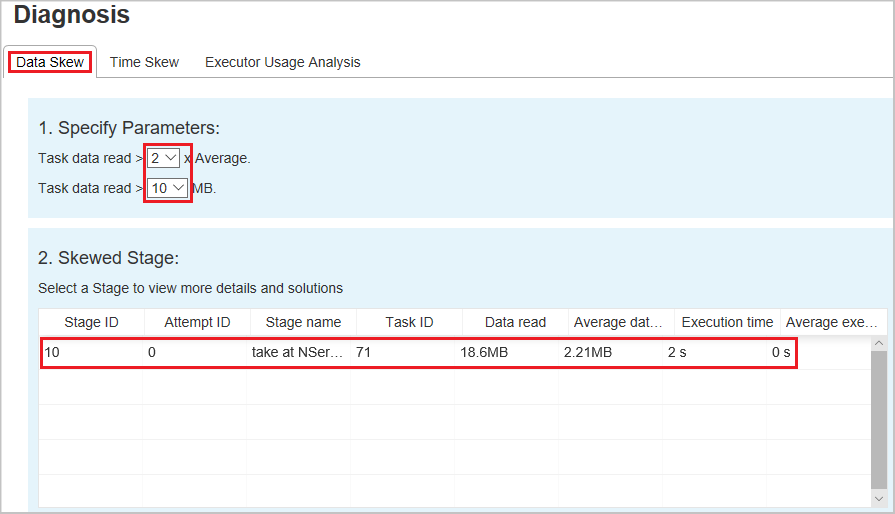
Dataskevning
När du väljer fliken Dataförskjutning visas motsvarande skeva uppgifter baserat på de angivna parametrarna.
Ange parametrar – I det första avsnittet visas parametrarna som används för att identifiera dataförskjutning. Standardregeln är: dataöverföring för uppgiften är mer än tre gånger den genomsnittliga dataöverföringen och dataöverföringen överstiger 10 MB. Om du vill definiera en egen regel för skeva uppgifter kan du välja dina parametrar. Avsnitten Skewed Stage och Skew Char uppdateras i enlighet med detta.
Skev fas – Det andra avsnittet visar faser, som har skeva uppgifter som uppfyller de villkor som tidigare angetts. Om det finns mer än en skev uppgift i en fas visar tabellen för skeva stadier bara den mest skeva uppgiften (till exempel den största datamängden vid datasnedvridning).
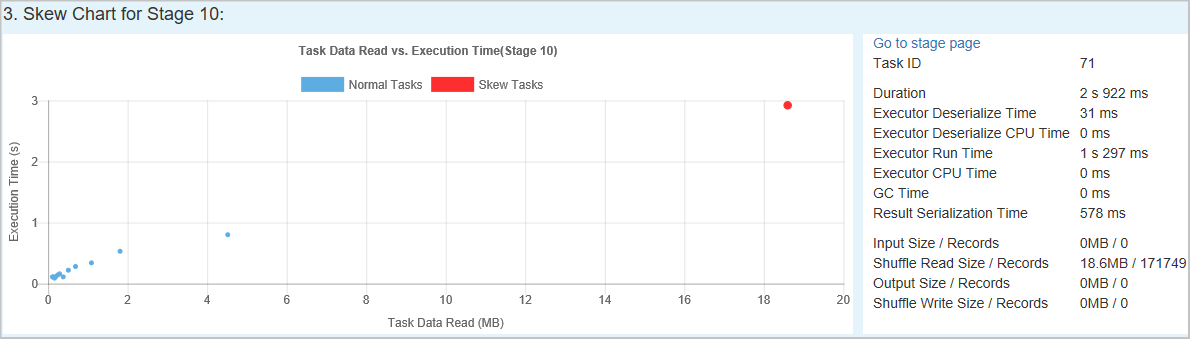
Skevningsdiagram – När en rad i skevhetstabellen har valts visar skevningsdiagrammet mer information om aktivitetsdistribution baserat på dataläsnings- och exekveringstid. De skeva uppgifterna är markerade i rött och de normala aktiviteterna är markerade i blått. Diagrammet visar upp till 100 exempelaktiviteter och aktivitetsinformationen visas i den högra nedre panelen.


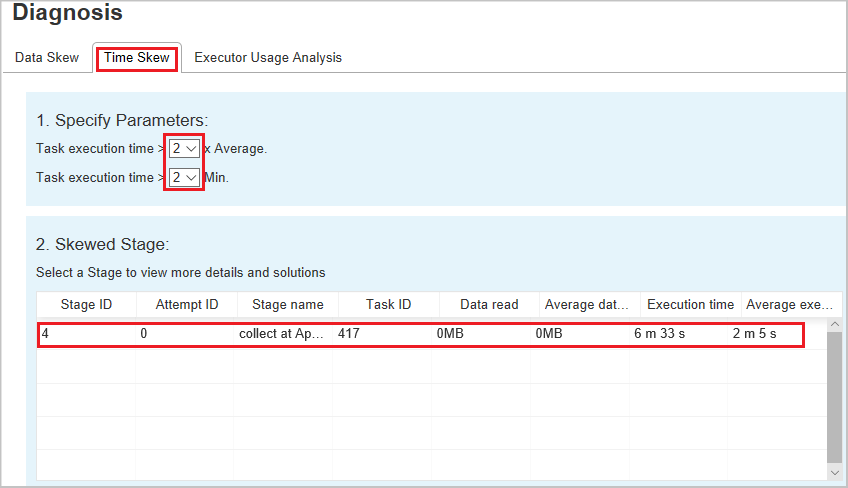
Tidsförskjutning
Fliken Tidsavvikelse visar uppgifter med tidsavvikelse baserat på utförandetid för aktiviteter.
Ange parametrar – I det första avsnittet visas parametrarna som används för att identifiera tidsförskjutning. Standardkriterierna för att identifiera tidsavvikelse är: uppgifters exekveringstid är större än tre gånger den genomsnittliga exekveringstiden och uppgifters exekveringstid är större än 30 sekunder. Du kan ändra parametrarna baserat på dina behov. Diagrammen Skewed Stage och Skew Chart visar motsvarande stadier och uppgifter precis som fliken Data Skew beskrevs tidigare.
Välj Tidsförskjutning och sedan visas filtrerat resultat i avsnittet Skev fas enligt parametrarna som anges i avsnittet Ange parametrar. Välj ett objekt i avsnittet Skevt steg , sedan utformas motsvarande diagram i avsnitt 3 och aktivitetsinformationen visas i den högra nedre panelen.

Användningsanalys för exekutor
Den här funktionen är föråldrad i Fabric nu. Om du fortfarande vill använda detta som en lösning öppnar du sidan genom att uttryckligen lägga till "/executorusage" bakom sökvägen "/diagnostic" i URL:en, så här:
