Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Tillägget Fabric Data Engineering Visual Studio (VS) Code har fullt stöd för create, read, update och delete (CRUD) jobbdefinitionsoperationer i Spark i Fabric. När du har skapat en Spark-jobbdefinition kan du ladda upp fler refererade bibliotek, skicka en begäran om att köra Spark-jobbdefinitionen och kontrollera körningshistoriken.
Skapa en Spark-jobbdefinition
Så här skapar du en ny Spark-jobbdefinition:
I VS Code Explorer väljer du alternativet Skapa Spark-jobbdefinition .

Ange de inledande obligatoriska fälten: namn, refererad lakehouse och standard lakehouse.
Begärandeprocesserna och namnet på den nyligen skapade Spark-jobbdefinitionen visas under rotnoden För Spark-jobbdefinition i VS Code Explorer. Under noden Namn på Spark-jobbdefinition visas tre undernoder:
- Filer: Lista över huvuddefinitionsfilen och andra refererade bibliotek. Du kan ladda upp nya filer från den här listan.
-
Lakehouse: Lista över alla lakehouses som refereras av den här Spark-jobbdefinitionen. Standard lakehouse är markerat i listan och du kan komma åt det via den relativa sökvägen
Files/…, Tables/…. - Kör: Lista över körningshistoriken för den här Spark-jobbdefinitionen och jobbstatusen för varje körning.

Ladda upp en huvuddefinitionsfil till ett refererat bibliotek
Om du vill ladda upp eller skriva över huvuddefinitionsfilen väljer du alternativet Lägg till huvudfil .

Om du vill ladda upp den biblioteksfil som huvuddefinitionsfilen refererar till väljer du alternativet Lägg till Lib-fil .

När du har laddat upp en fil kan du åsidosätta den genom att klicka på alternativet Uppdatera fil och ladda upp en ny fil, eller så kan du ta bort filen via alternativet Ta bort .

Skicka en körningsförfrågan
Så här skickar du en begäran om att köra Spark-jobbdefinitionen från VS Code:
Välj alternativet Kör Spark-jobb från alternativen till höger om namnet på den Spark-jobbdefinition som du vill köra.

När du har skickat begäran visas ett nytt Apache Spark-program i noden Körningar i explorer-listan. Du kan avbryta jobbet som körs genom att välja alternativet Avbryt Spark-jobb .
Skärmbild av VS Code Explorer med det nya Spark-programmet listat under noden "Runs" och visar var du hittar alternativet "Avbryt Spark-jobb".

Öppna en Spark-jobbdefinition i Fabric-portalen
Du kan öppna redigeringssidan för Spark-jobbdefinition i Infrastrukturportalen genom att välja alternativet Öppna i webbläsare .
Du kan också välja Öppna i webbläsaren bredvid en slutförd körning för att se detaljövervakarsidan för den körningen.

Felsöka Källkod för Spark-jobbdefinition (Python)
Om Spark-jobbdefinitionen skapas med PySpark (Python) kan du ladda ned .py skriptet för huvuddefinitionsfilen och den refererade filen och felsöka källskriptet i VS Code.
Om du vill ladda ned källkoden väljer du alternativet Felsöka Spark-jobbdefinition till höger om Spark-jobbdefinitionen.

När nedladdningen är klar öppnas källkodens mapp automatiskt.
Välj alternativet Lita på författarna när du uppmanas att göra det. (Det här alternativet visas bara första gången du öppnar mappen. Om du inte väljer det här alternativet kan du inte felsöka eller köra källskriptet. Mer information finns i Säkerhetsförtroende för Visual Studio Code-arbetsyta.)
Om du har laddat ned källkoden tidigare uppmanas du att bekräfta att du vill skriva över den lokala versionen med den nya nedladdningen.
Kommentar
I rotmappen för källskriptet skapar systemet en undermapp med namnet conf. I den här mappen innehåller en fil med namnet lighter-config.json vissa systemmetadata som behövs för fjärrkörningen. Gör INGA ändringar i den.
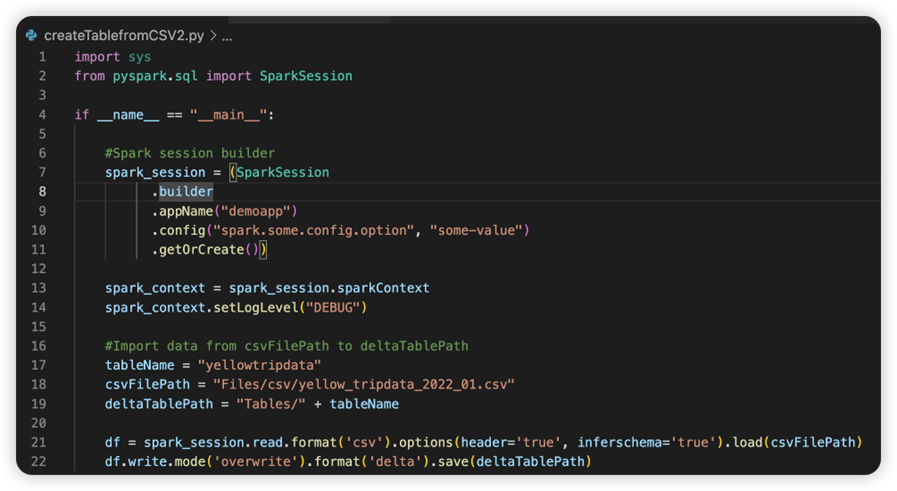
Filen med namnet sparkconf.py innehåller ett kodfragment som du behöver lägga till för att konfigurera SparkConf-objektet . Om du vill aktivera fjärrfelsökningen kontrollerar du att SparkConf-objektet har konfigurerats korrekt. Följande bild visar den ursprungliga versionen av källkoden.
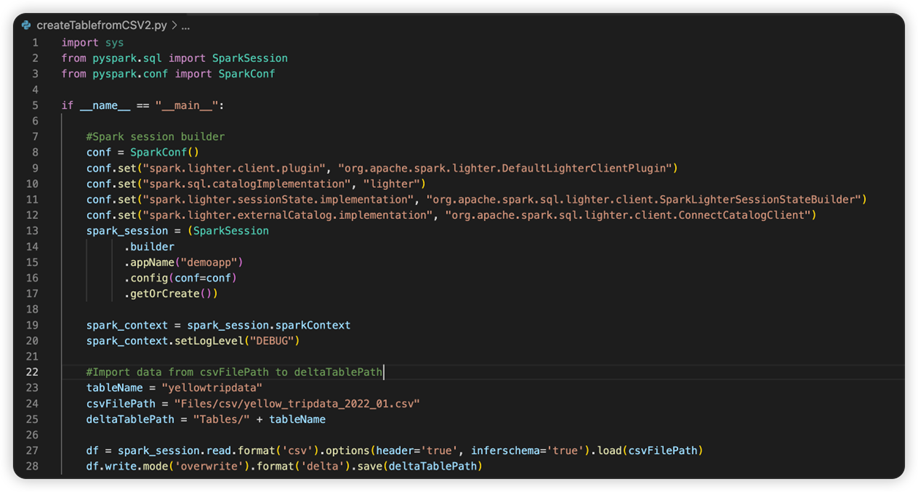
Nästa bild är den uppdaterade källkoden när du har kopierat och klistrat in kodfragmentet.
När du har uppdaterat källkoden med nödvändig konfiguration måste du välja rätt Python-tolk. Se till att välja den som är installerad från conda-miljön synapse-spark-kernel.



Redigera egenskaper för Spark-jobbdefinition
Du kan redigera detaljegenskaperna för Spark-jobbdefinitioner, till exempel kommandoradsargument.
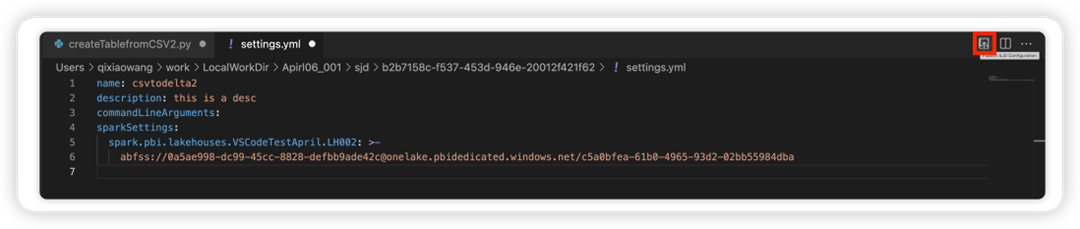
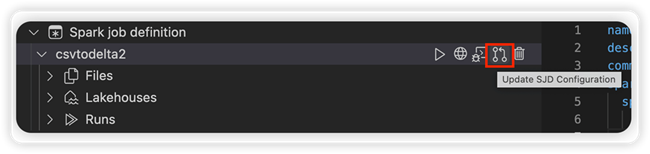
Välj alternativet Uppdatera SJD-konfiguration för att öppna en settings.yml fil. De befintliga egenskaperna fyller i innehållet i den här filen.
Uppdatera och spara filen .yml.
Välj alternativet Publicera SJD-egenskap i det övre högra hörnet för att synkronisera ändringen tillbaka till fjärrarbetsytan.