Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln visar hur du skapar anpassade Apache Spark-pooler i Microsoft Fabric för dina analysarbetsbelastningar. Med Apache Spark-pooler kan du skapa skräddarsydda beräkningsmiljöer baserat på dina krav, så att du får optimal prestanda och resursanvändning.
Ange de minsta och högsta noderna för automatisk skalning. Systemet hämtar och drar tillbaka noder när jobbets beräkningsbehov ändras, så skalning är effektivt och prestandan förbättras. Sparkpooler justerar antalet exekutorer automatiskt, så du behöver inte ange dem manuellt. Systemet ändrar körmotorens antal baserat på datavolym och arbetsberäkningsbehov, så att du kan fokusera på dina arbetsuppgifter i stället för prestandaoptimering och resurshantering.
Tips/Råd
När du konfigurerar Spark-pooler bestäms nodstorleken av kapacitetsenheter (CU) som representerar den beräkningskapacitet som tilldelats varje nod. Mer information om nodstorlekar och CU finns i avsnittet Alternativ för nodstorlek i den här guiden.
Förutsättningar
Om du vill skapa en anpassad Spark-pool kontrollerar du att du har administratörsåtkomst till arbetsytan. Kapacitetsadministratören aktiverar alternativet Anpassade arbetsytepooler i avsnittet Spark Compute i Inställningar för kapacitetsadministratör. Mer information finns i Spark-beräkningsinställningar för infrastrukturresurser.
Skapa anpassade Spark-pooler
Så här skapar eller hanterar du Spark-poolen som är associerad med din arbetsyta:
Gå till din arbetsyta och välj Arbetsyteinställningar.
Välj alternativet Data Engineering/Science för att expandera menyn och välj sedan Spark-inställningar.

Välj alternativet Ny pool. På skärmen Skapa pool namnger du Spark-poolen. Välj även Node-familjenoch välj en Node-storlek från de tillgängliga storlekarna (Small, Medium, Large, X-Largeoch XX-Large) baserat på beräkningskrav för dina arbetsbelastningar.
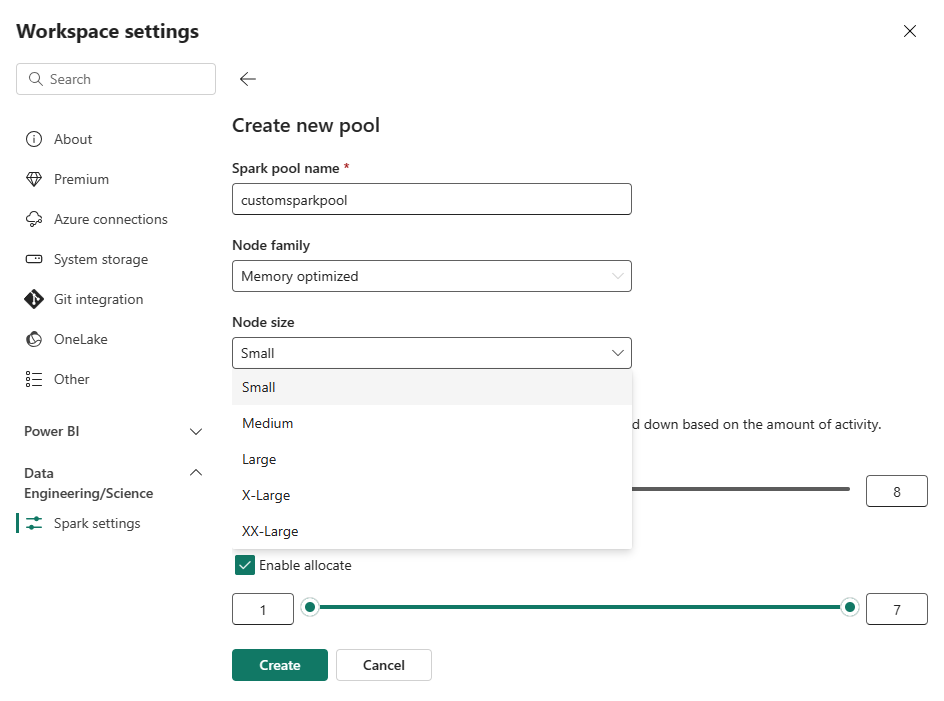
Du kan ange den minsta nodkonfigurationen för dina anpassade pooler till 1. Eftersom Fabric Spark ger återställningsbar tillgänglighet för kluster med en enda nod behöver du inte bekymra dig om jobbfel, förlust av session under fel eller över att betala för beräkning för mindre Spark-jobb.
Du kan aktivera eller inaktivera automatisk skalning för dina anpassade Spark-pooler. När autoskalning är aktiverat hämtar poolen dynamiskt nya noder upp till den maximala nodgräns som användaren har angett och drar sedan tillbaka dem efter jobbkörningen. Den här funktionen ger bättre prestanda genom att justera resurser baserat på jobbkraven. Du får justera storleken på noderna, som passar inom de kapacitetsenheter som köpts som en del av Fabric-kapacitetens SKU.

Du kan justera antalet executors med hjälp av ett skjutreglage. Varje exekverare är en Spark-process som kör uppgifter och lagrar data i minnet. Att öka exekutorerna kan förbättra parallelliteten, men det ökar också klustrets storlek och starttid. Du kan också välja att aktivera dynamisk körallokering för Spark-poolen, vilket automatiskt avgör det optimala antalet köre inom den användardefinierade maximala gränsen. Den här funktionen justerar antalet utförare baserat på datavolym, vilket resulterar i bättre prestanda och resursanvändning.



Dessa anpassade pooler har en standardlängd för autopaus på 2 minuter efter att inaktivitetsperioden hade upphört att gälla. När varaktigheten för autopaus har nåtts upphör sessionen att gälla och klustren är oallokerade. Du debiteras baserat på antalet noder och hur länge de anpassade Spark-poolerna används.
Obs
Anpassade Spark-pooler i Microsoft Fabric har för närvarande stöd för en maximal nodgräns på 200. När du konfigurerar automatisk skalning eller ställer in antalet manuella noder kontrollerar du att dina lägsta och högsta värden ligger kvar inom den här gränsen. Om den här gränsen överskrids resulterar det i valideringsfel när poolen skapas eller uppdateras.
Alternativ för nodstorlek
När du konfigurerar en anpassad Spark-pool väljer du mellan följande nodstorlekar:
| Nodstorlek | Kapacitetsenheter (CU) | Minne (Gigabyte) | Beskrivning |
|---|---|---|---|
| Liten | 4 | 32 | För lätta utvecklings- och testjobb. |
| Medel | 8 | 64 | För allmänna arbetsbelastningar och typiska operationer. |
| Stort | 16 | 128 | För minnesintensiva uppgifter eller stora databearbetningsjobb. |
| X-Large | 32 | 256 | För de mest krävande Spark-arbetsbelastningarna som behöver betydande resurser. |
Obs
En kapacitetsenhet (CU) i Microsoft Fabric Spark-pooler representerar den beräkningskapacitet som tilldelats varje nod, inte den faktiska förbrukningen. Kapacitetsenheter skiljer sig från virtuella kärnor (Virtual Core), som används i SQL-baserade Azure-resurser. CU är standardtermen för Spark-pooler i Fabric, medan VCore är vanligare för SQL-pooler. När du ändrar storlek på noder använder du CU för att fastställa den tilldelade kapaciteten för dina Spark-arbetsbelastningar.
Relaterat innehåll
- Läs mer i den offentliga dokumentationen för Apache Spark .
- Kom igång med administrationsinställningarna för Spark-arbetsytor i Microsoft Fabric.