Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Fabric runtime erbjuder en sömlös integrering med Azure. Det ger en sofistikerad miljö för både datateknik och datavetenskapsprojekt som använder Apache Spark. Den här artikeln innehåller en översikt över de viktigaste funktionerna och komponenterna i Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 är en GA-körningsversion som innehåller följande komponenter och uppgraderingar som är utformade för att förbättra dina databehandlingsfunktioner:
- Apache Spark 3.5
- Operativsystem: Mariner 2.0 (Azure Linux 2.0)
- Java: 11
- Scala: 2.12.17
- Python: 3.11
- Delta lake: 3.2
- R: 4.4.1
Important
Den tidiga åtkomstversionen av Runtime 1.3 innehåller ett uppgraderat operativsystem från Mariner 2.0 (Azure Linux 2.0) till Mariner 3.0 (Azure Linux 3.0). Använd lanseringskanalen för tidig åtkomst för att testa dina arbetsbelastningar mot den här ändringen innan den blir standard. Den här valideringen är kritisk, särskilt om dina arbetsbelastningar har beroenden för paket på OS-nivå.
Tips
Fabric Runtime 1.3 har stöd för den interna körningsmotorn, vilket avsevärt kan förbättra prestandan utan mer kostnader. Om du vill aktivera den inbyggda exekveringsmotorn för alla jobb och notebooks i din miljö, går du till miljöinställningarna, väljer Spark-beräkning, går till fliken Acceleration och markerar Aktivera inbyggd exekveringsmotor. När du har sparat och publicerat tillämpas den här inställningen i hela miljön, så alla nya jobb och notebook-filer ärver automatiskt och drar nytta av de förbättrade prestandafunktionerna.
Integrera Runtime 1.3
Anmärkning
För information om alla tillgängliga Fabric-körningar och deras aktuella status, se Apache Spark Runtimes i Fabric.
Använd följande instruktioner för att integrera runtime 1.3 i din arbetsyta och använda dess nya funktioner:
Gå till fliken Arbetsyteinställningar i din Fabric-arbetsyta.
Gå till fliken Dataingenjör ing/vetenskap och välj Spark-inställningar.
Välj fliken Miljö.
Under fliken Körningsversioner expanderar du listrutan.
Välj 1.3 (Spark 3.5, Delta 3.2) och spara ändringarna. Den här åtgärden anger 1.3 som standardutföringsmiljö för din arbetsyta.
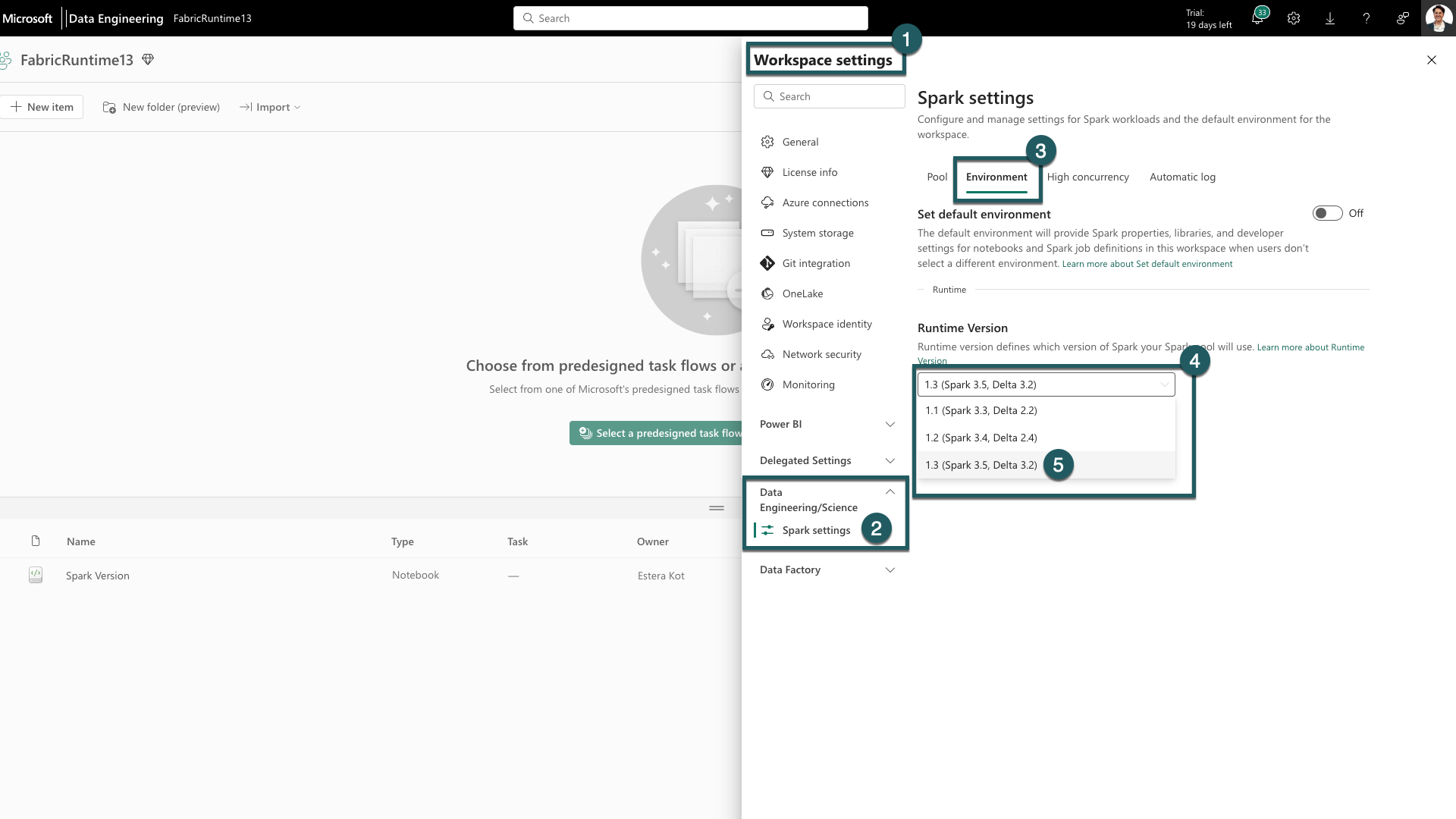

Nu kan du börja arbeta med de senaste förbättringarna och funktionerna som introducerades i Fabric Runtime 1.3 (Spark 3.5 och Delta Lake 3.2).
Läs mer om Apache Spark 3.5
Apache Spark 3.5.0 är den sjätte versionen i 3.x-serien. Den här versionen är en produkt av omfattande samarbete inom communityn med öppen källkod som hanterar mer än 1 300 problem som registrerats i Jira.
I den här versionen finns det en uppgradering av kompatibiliteten för strukturerad direktuppspelning. Dessutom breddar den här versionen funktionerna i PySpark och SQL. Den lägger till funktioner som SQL-sats för identifierare, namngivna argument i SQL-funktioner och inkluderingen av SQL-funktioner för HyperLogLog ungefärliga aggregeringar.
Andra nya funktioner omfattar användardefinierade tabellfunktioner i Python, förenkling av distribuerad träning via DeepSpeed och nya strukturerade strömningsfunktioner som vattenmärkesspridning och dropDuplicatesWithinWatermark-operationen.
Du kan kontrollera hela listan och detaljerade ändringar här: Spark Release 3.5.0.
Läs mer om Delta Spark
Delta Lake 3.2 markerar ett gemensamt åtagande att göra Delta Lake samverkande mellan format, enklare att arbeta med och mer högpresterande. Delta Spark 3.2 bygger på Apache Spark™ 3.5. Delta Spark-mavenartefakten har bytt namn från delta-core till delta-spark.
Du kan kontrollera hela listan och detaljerade ändringar här: https://docs.delta.io/index.html.
Komponenter och bibliotek
För uppdaterad information, en detaljerad lista över ändringar och specifika versionsanteckningar för Fabric-körningar, kontrollera och prenumerera på Spark Runtimes-versioner och -uppdateringar.
Anmärkning
EventHubConnector är inaktuell i Fabric Runtime 1.3 (Spark 3.5) och tas bort från framtida Fabric Runtime-versioner. Kunder uppmanas att använda Kafka Spark Connector i stället eftersom Event Hubs redan är Kafka-kompatibelt. Mer information om hur du använder Kafka Spark Connector med Event Hubs finns här: Självstudie om Event Hubs Kafka Spark
Relaterat innehåll
- Läs mer om Apache Spark Runtimes i Fabric – Översikt, Versionshantering, Stöd för flera körningsmiljöer och uppgradering av Delta Lake-protokollet
- Migreringsguide för Spark Core
- Migreringsguider för SQL, datauppsättningar och DataFrame
- Migreringsguide för strukturerad direktuppspelning
- Migreringsguide för MLlib (strojové učenie)
- Migreringsguide för PySpark (Python på Spark)
- Migreringsguide för SparkR (R on Spark)