Så här kopierar du data med kopieringsaktivitet
I Datapipeline kan du använda aktiviteten Kopiera för att kopiera data mellan datalager som finns i molnet.
När du har kopierat data kan du använda andra aktiviteter för att transformera och analysera dem ytterligare. Du kan också använda aktiviteten Kopiera för att publicera transformerings- och analysresultat för Business Intelligence (BI) och programförbrukning.
För att kopiera data från en källa till ett mål utför tjänsten som kör aktiviteten Kopiera följande steg:
- Läser data från ett källdatalager.
- Utför serialisering/deserialisering, komprimering/dekomprimering, kolumnmappning och så vidare. Den utför dessa åtgärder baserat på konfigurationen.
- Skriver data till måldatalagret.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
Ett Microsoft Fabric-klientkonto med en aktiv prenumeration. Skapa ett konto utan kostnad.
Kontrollera att du har en Microsoft Fabric-aktiverad arbetsyta.
Lägga till en kopieringsaktivitet med hjälp av kopieringsassistenten
Följ de här stegen för att konfigurera kopieringsaktiviteten med hjälp av kopieringsassistenten.
Börja med kopieringsassistenten
Öppna en befintlig datapipeline eller skapa en ny datapipeline.
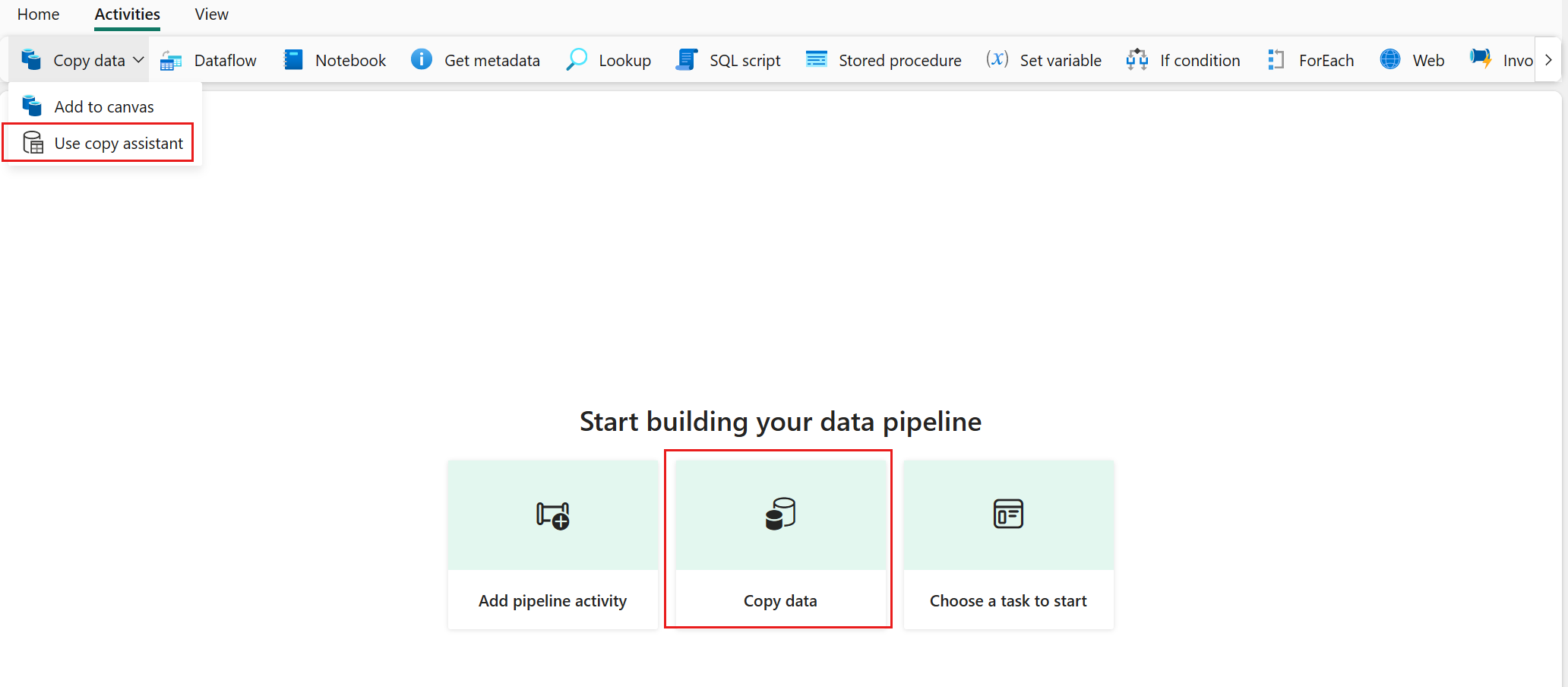
Välj Kopiera data på arbetsytan för att öppna verktyget Kopieringsassistenten för att komma igång. Eller välj Använd kopieringsassistenten i listrutan Kopiera data under fliken Aktiviteter i menyfliksområdet.

Konfigurera din källa
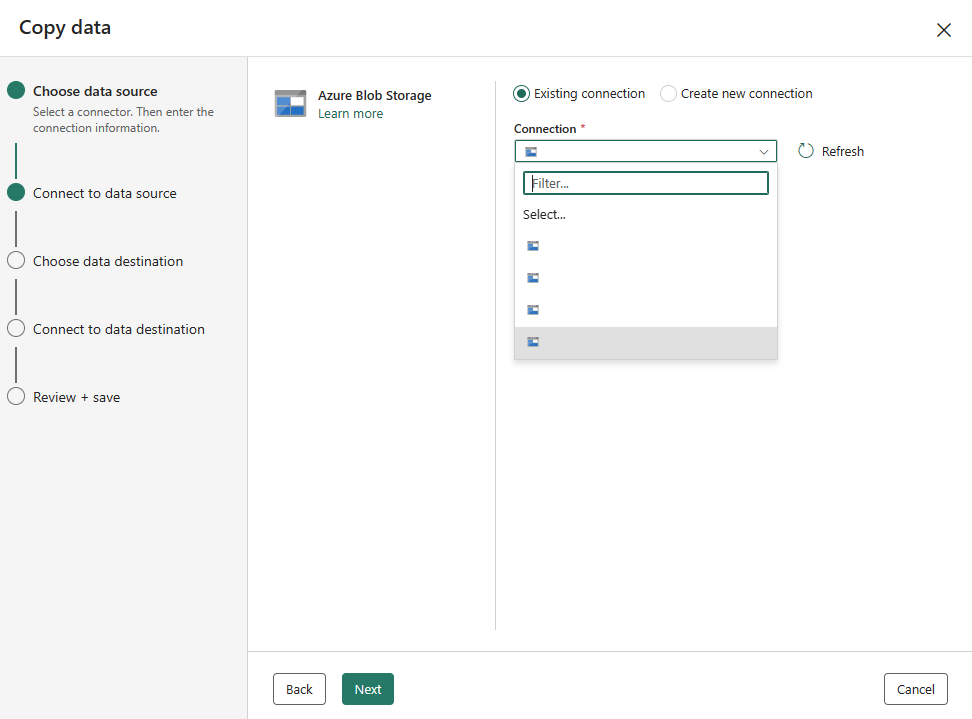
Välj en datakällatyp i kategorin. Du använder Azure Blob Storage som exempel. Välj Azure Blob Storage och välj sedan Nästa.
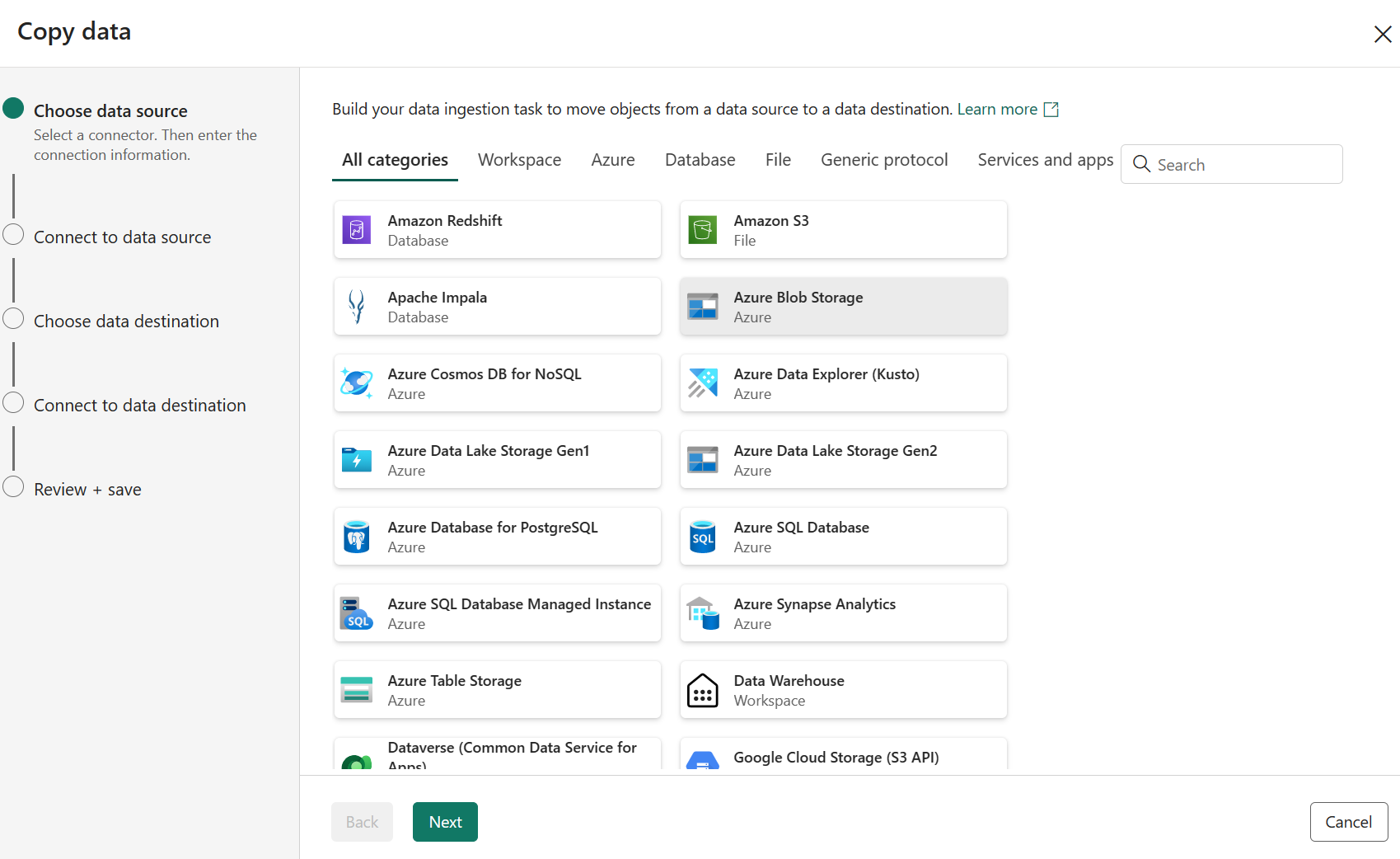
Skapa en anslutning till datakällan genom att välja Skapa ny anslutning.
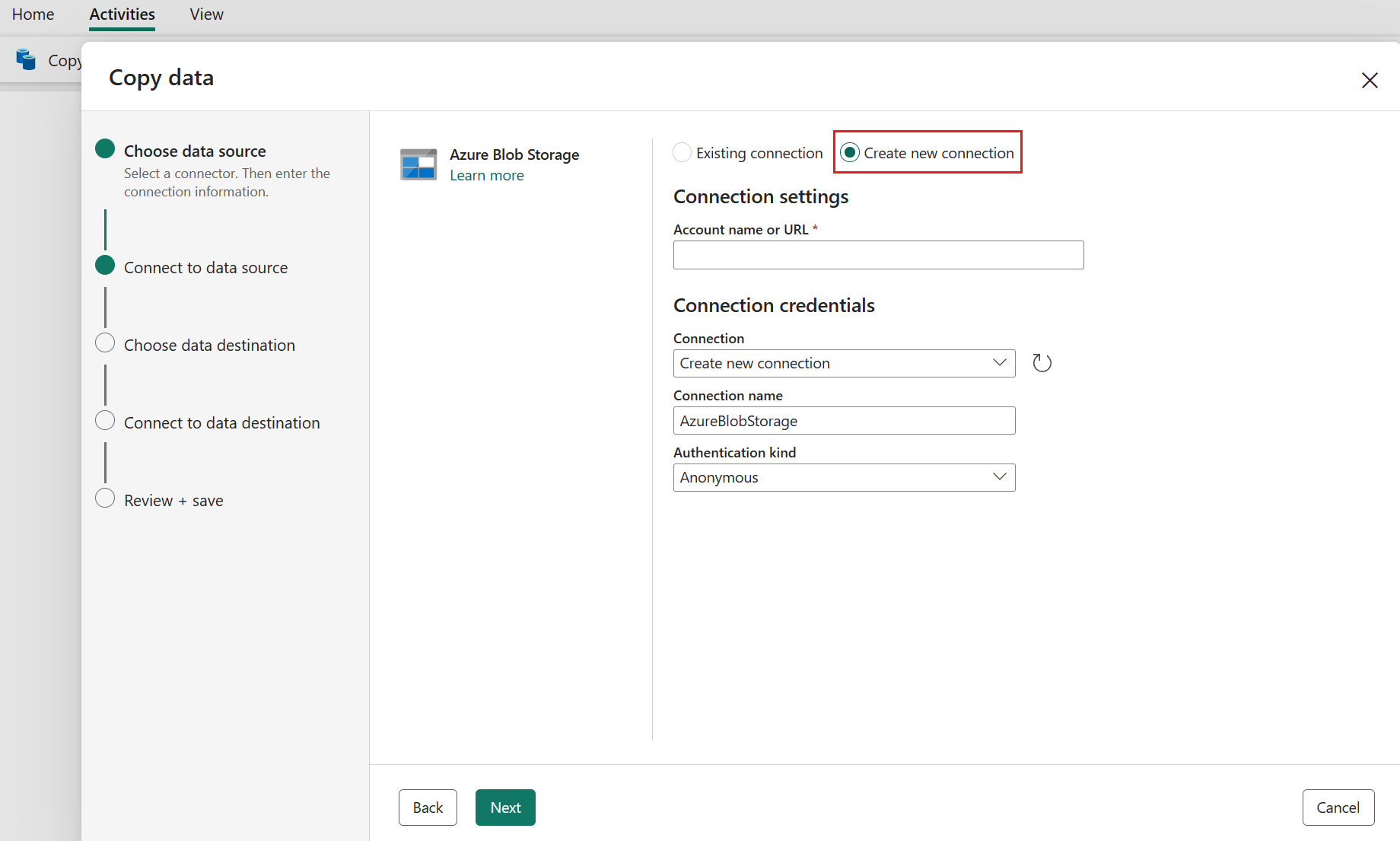
När du har valt Skapa ny anslutning fyller du i nödvändig anslutningsinformation och väljer sedan Nästa. Information om hur du skapar anslutningar för varje typ av datakälla finns i artikeln om varje anslutningsapp.
Om du har befintliga anslutningar kan du välja Befintlig anslutning och välja din anslutning i listrutan.
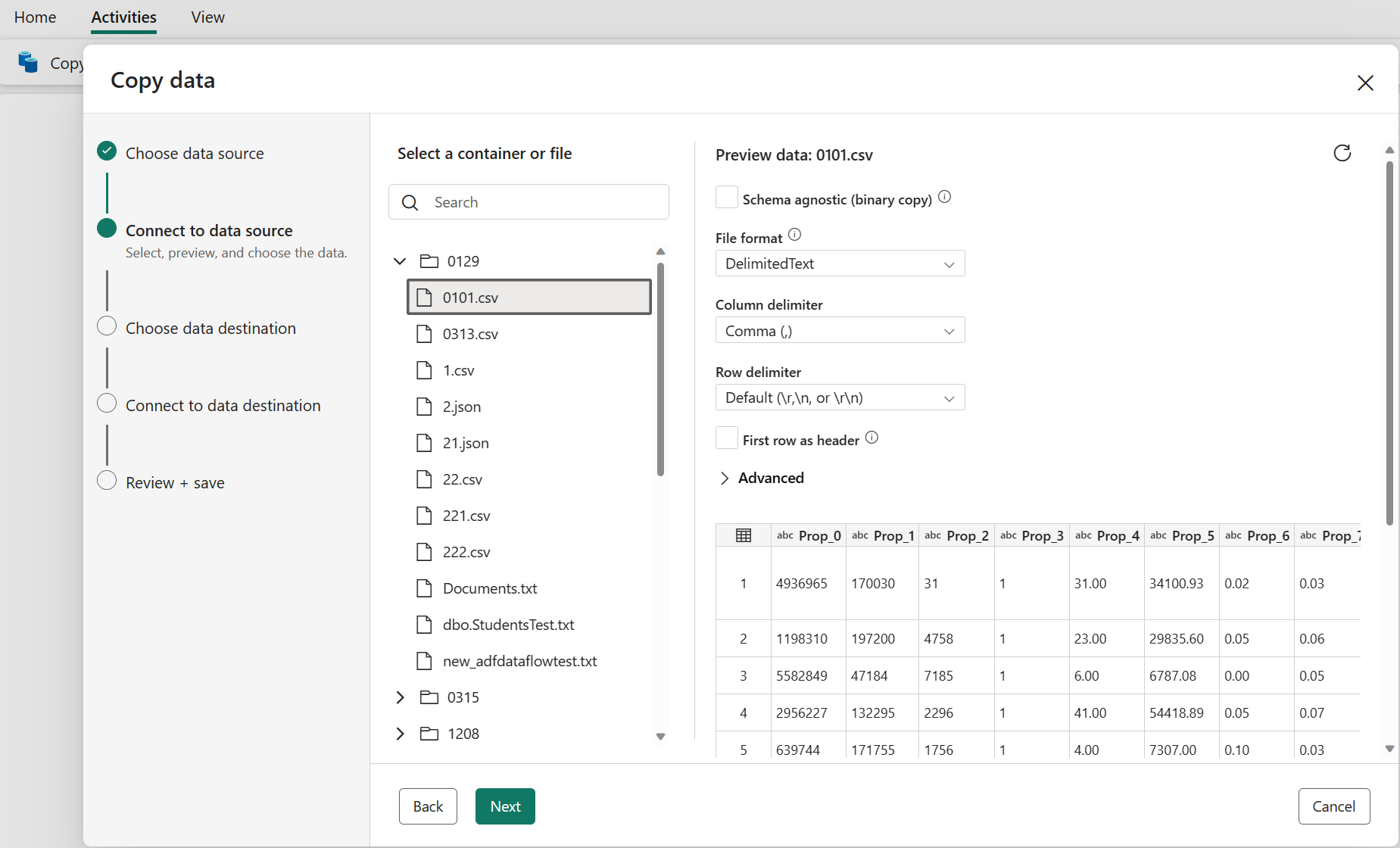
Välj den fil eller mapp som ska kopieras i det här källkonfigurationssteget och välj sedan Nästa.




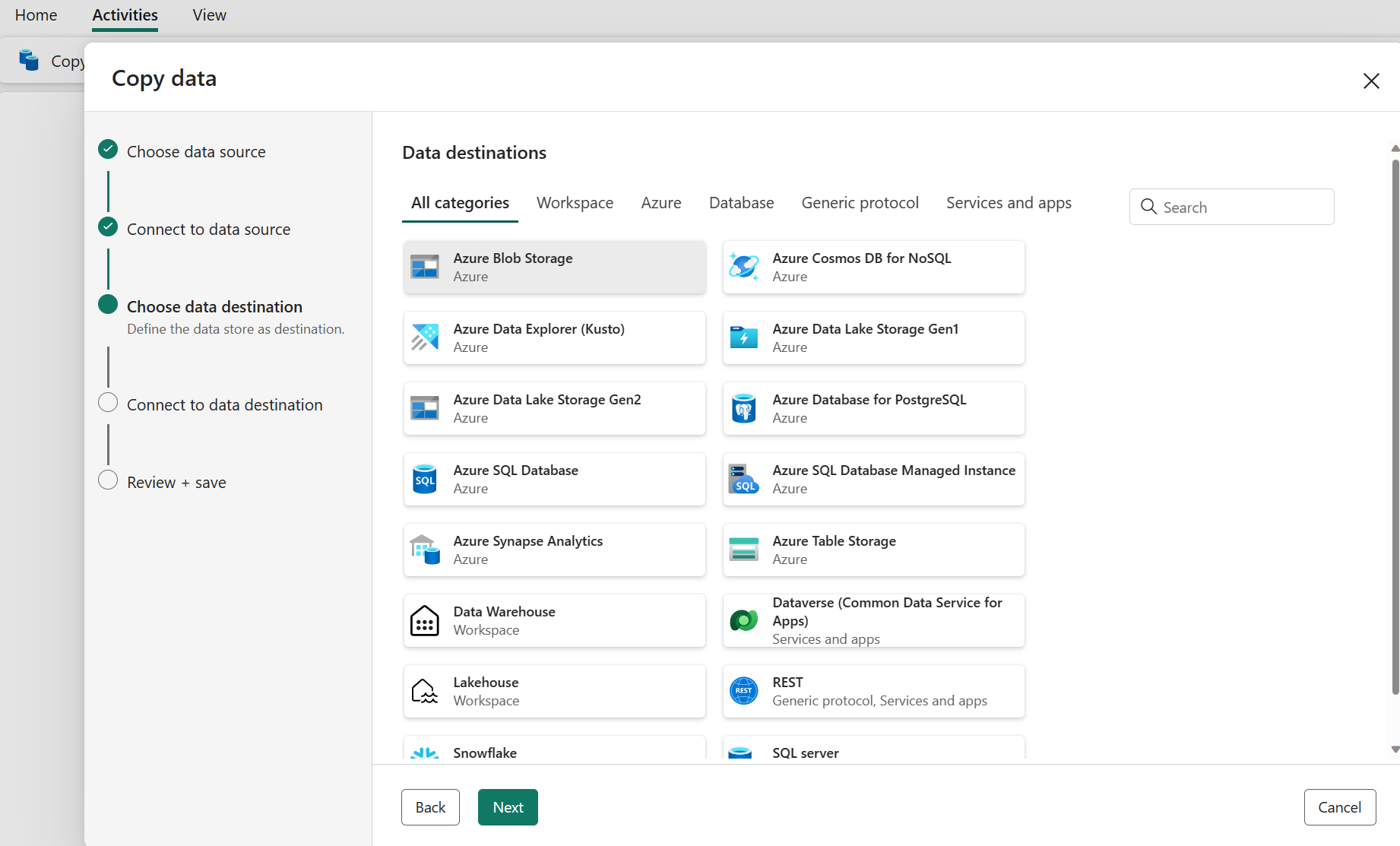
Konfigurera målet
Välj en datakällatyp i kategorin. Du använder Azure Blob Storage som exempel. Du kan antingen skapa en ny anslutning som länkar till ett nytt Azure Blob Storage-konto genom att följa stegen i föregående avsnitt eller använda en befintlig anslutning från listrutan för anslutning. Funktionerna i Testanslutning och Redigera är tillgängliga för varje vald anslutning.
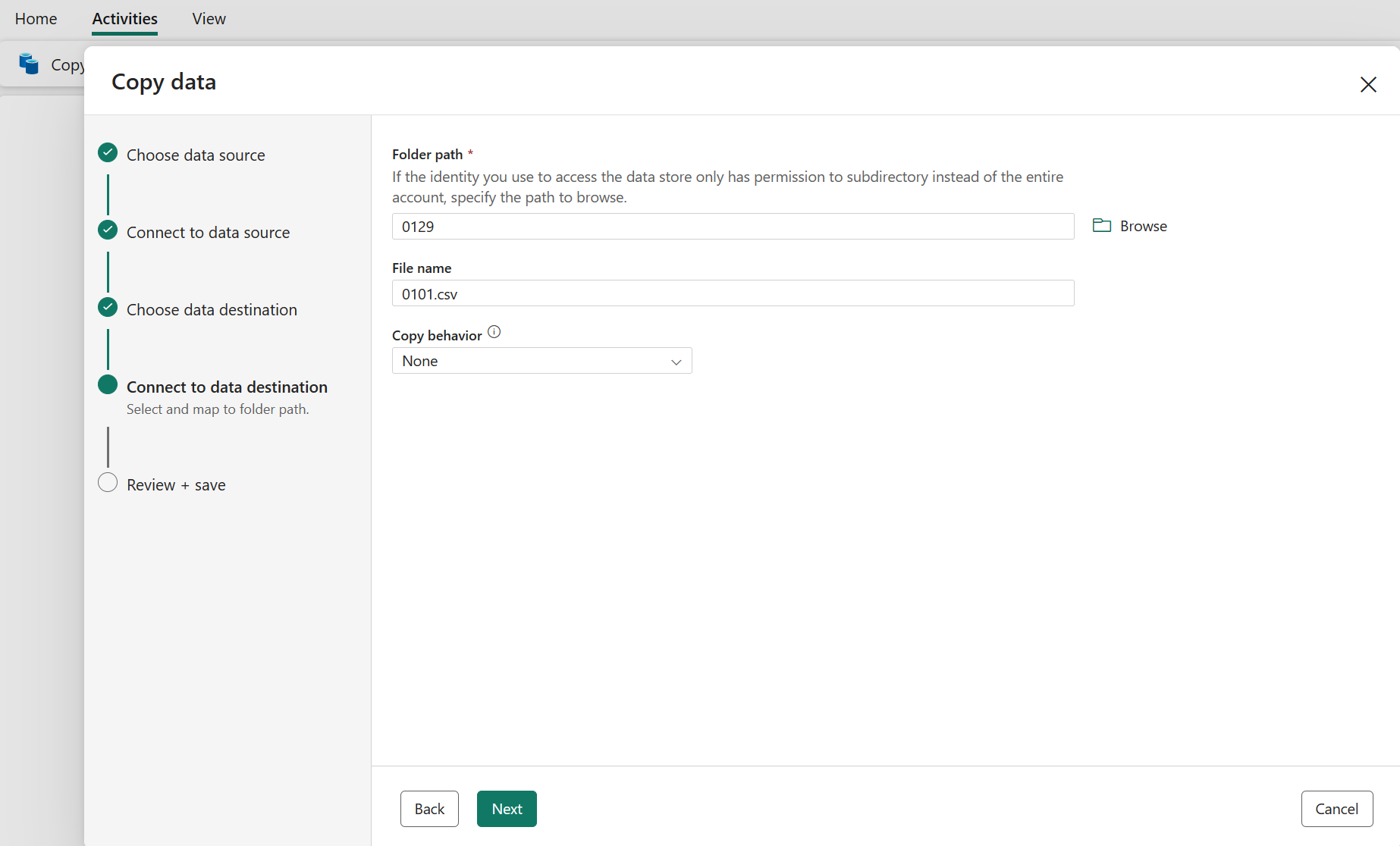
Konfigurera och mappa dina källdata till målet. Välj sedan Nästa för att slutföra målkonfigurationerna.
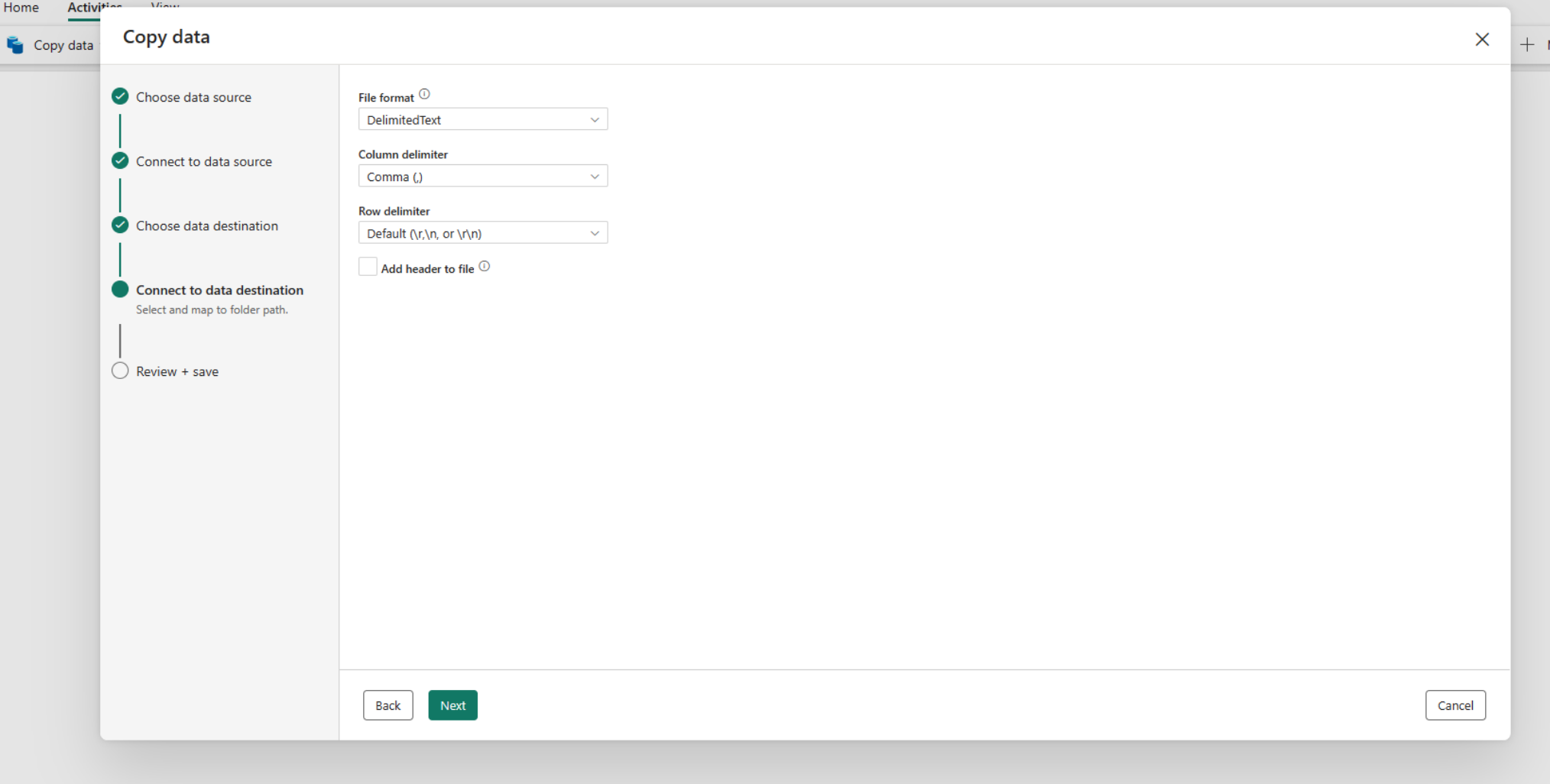
Kommentar
Du kan bara använda en enda lokal datagateway inom samma aktiviteten Kopiera. Om både källa och mottagare är lokala datakällor måste de använda samma gateway. Om du vill flytta data mellan lokala datakällor med olika gatewayer måste du kopiera med hjälp av den första gatewayen till en mellanliggande molnkälla i en aktiviteten Kopiera. Sedan kan du använda en annan aktiviteten Kopiera för att kopiera den från den mellanliggande molnkällan med hjälp av den andra gatewayen.



Granska och skapa kopieringsaktiviteten
Granska inställningarna för kopieringsaktiviteten i föregående steg och välj OK för att slutföra. Eller så kan du gå tillbaka till föregående steg för att redigera inställningarna om det behövs i verktyget.
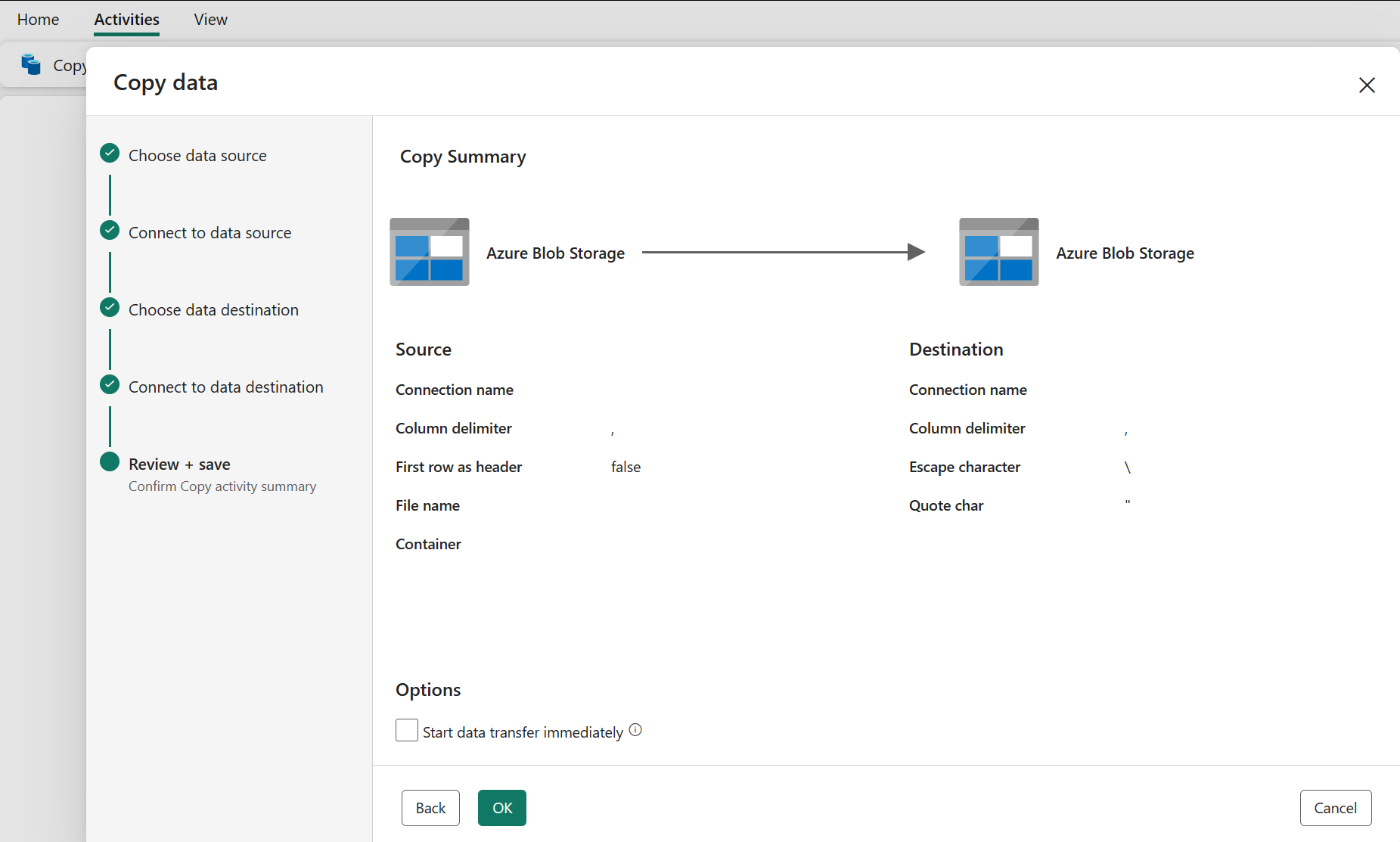

När kopieringsaktiviteten är klar läggs den sedan till i din datapipelinearbetsyta. Alla inställningar, inklusive avancerade inställningar för den här kopieringsaktiviteten, är tillgängliga under flikarna när den väljs.

Nu kan du antingen spara din datapipeline med den här enkla kopieringsaktiviteten eller fortsätta att utforma din datapipeline.
Lägga till en kopieringsaktivitet direkt
Följ de här stegen för att lägga till en kopieringsaktivitet direkt.
Lägga till en kopieringsaktivitet
Öppna en befintlig datapipeline eller skapa en ny datapipeline.
Lägg till en kopieringsaktivitet antingen genom att välja Lägg till pipelineaktivitet> aktiviteten Kopiera eller genom att välja Kopiera data>Lägg till på arbetsytan under fliken Aktiviteter.
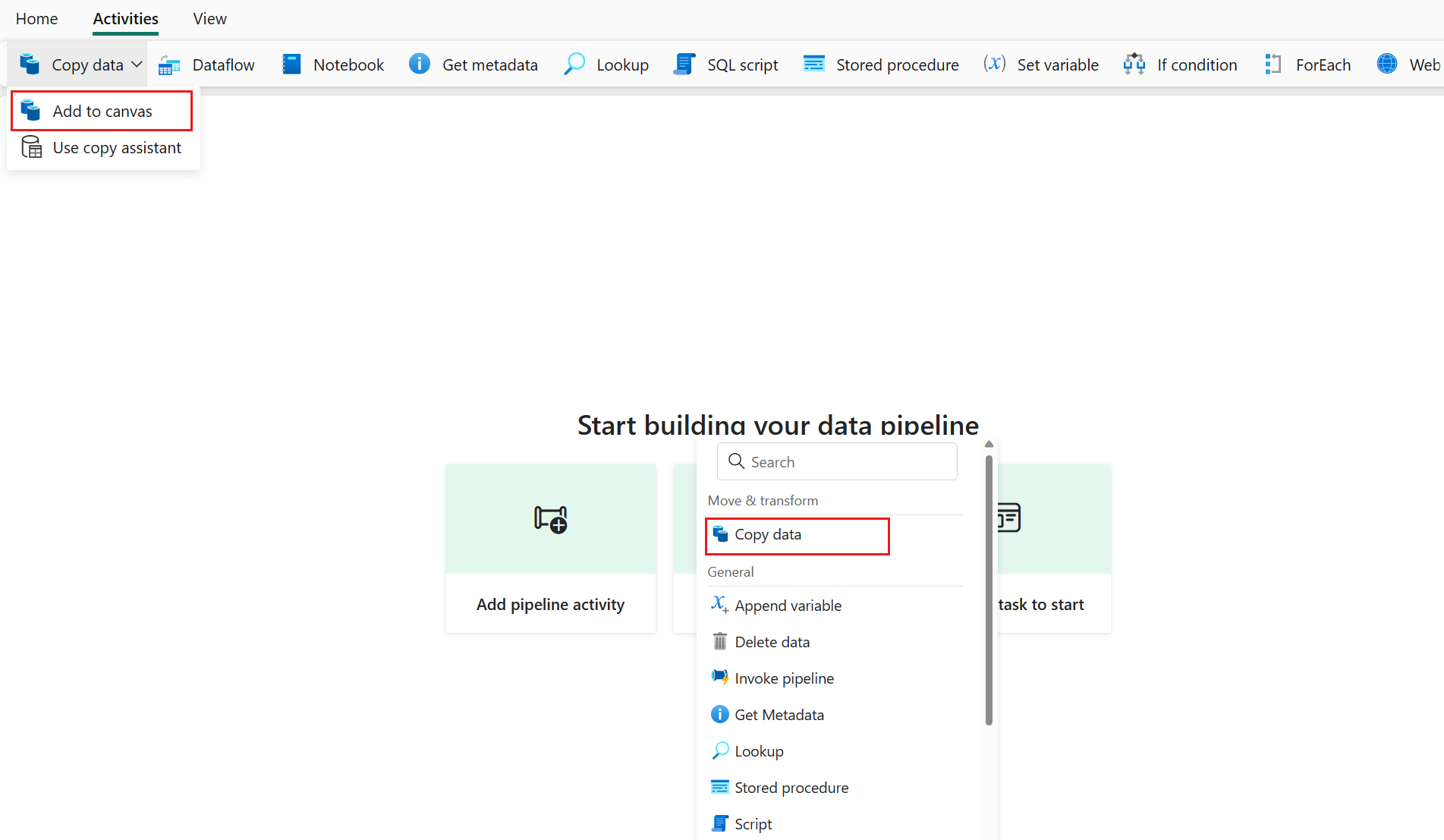

Konfigurera dina allmänna inställningar under fliken Allmänt
Information om hur du konfigurerar dina allmänna inställningar finns i Allmänt.
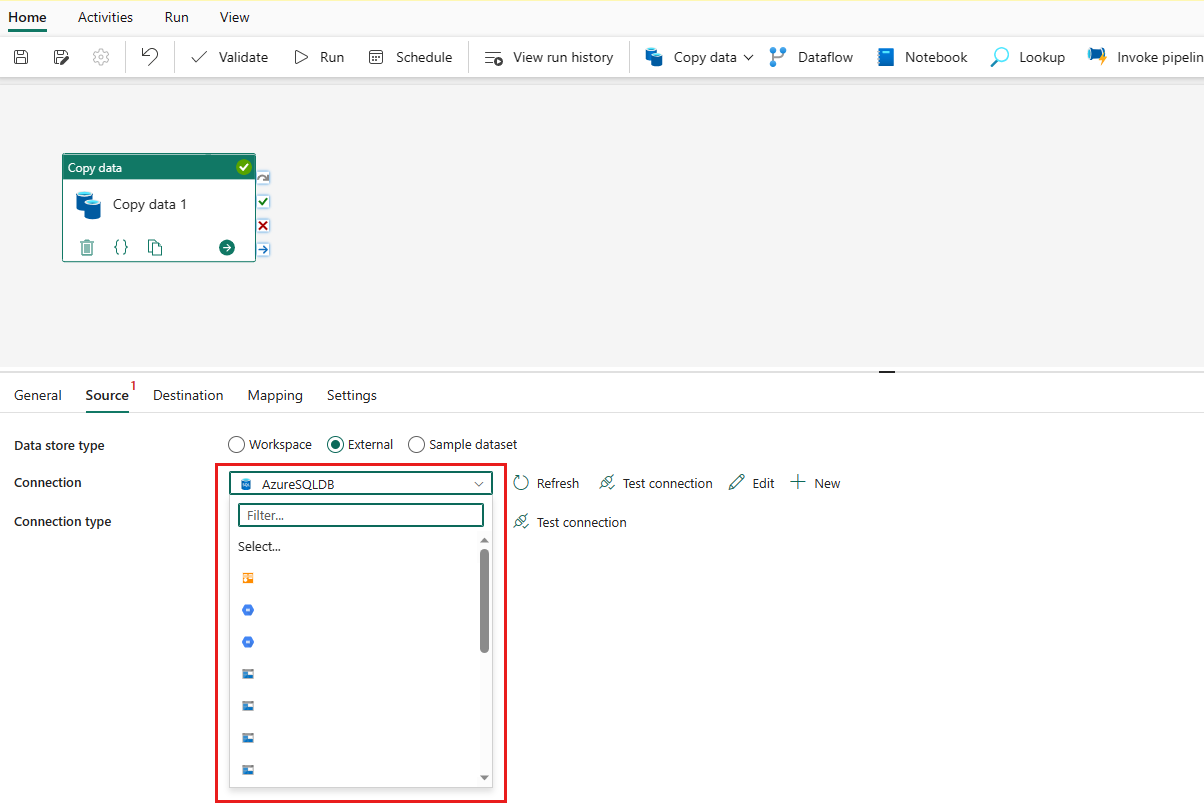
Konfigurera källan på källfliken
Välj + Ny bredvid Anslutningen för att skapa en anslutning till datakällan.
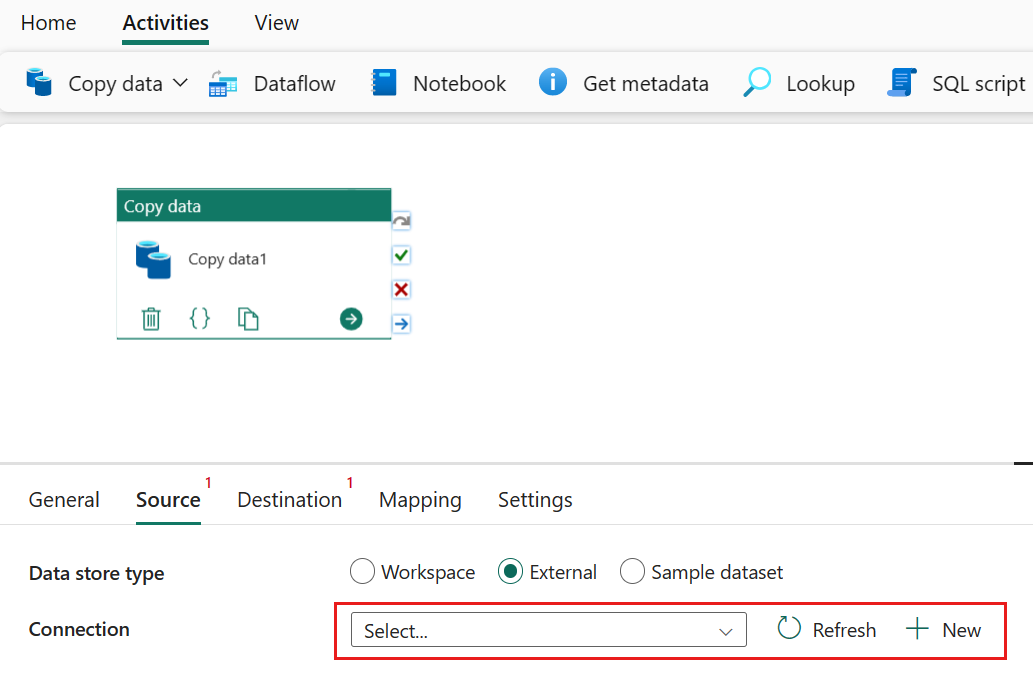
Välj datakälltypen i popup-fönstret. Du använder Azure SQL Database som exempel. Välj Azure SQL Database och välj sedan Fortsätt.
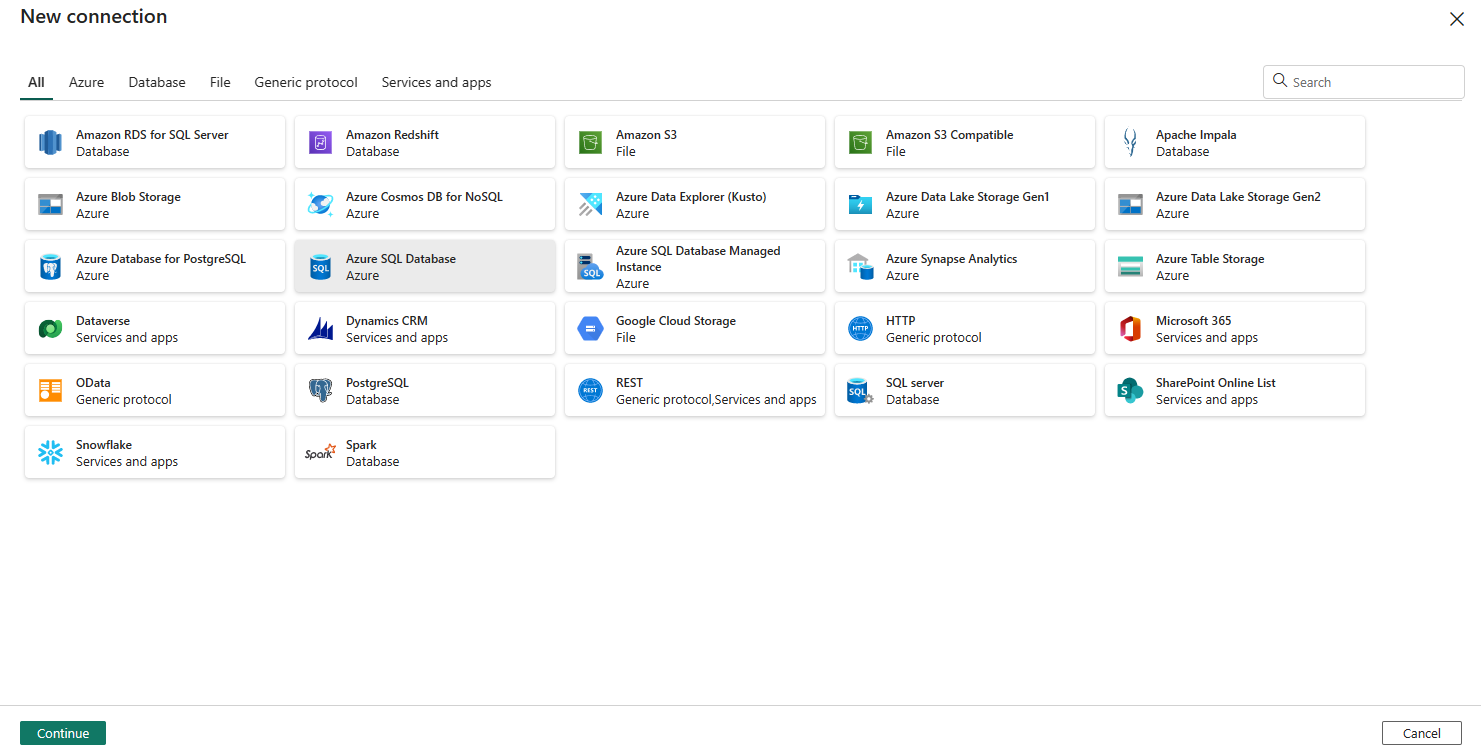
Den navigerar till sidan för att skapa anslutningen. Fyll i nödvändig anslutningsinformation på panelen och välj sedan Skapa. Information om hur du skapar anslutningar för varje typ av datakälla finns i artikeln om varje anslutningsapp.
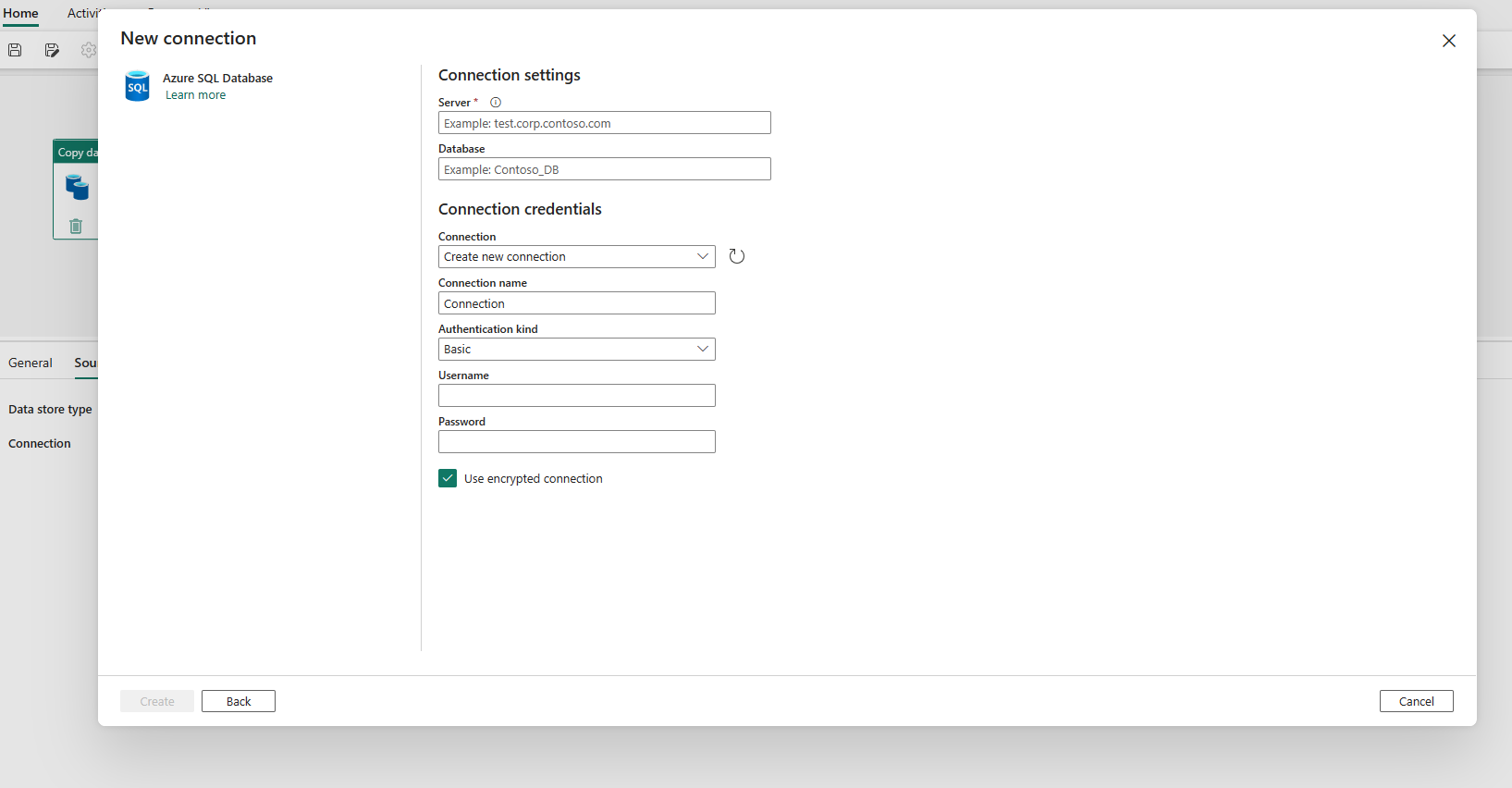
När anslutningen har skapats tar den dig tillbaka till datapipelinesidan. Välj sedan Uppdatera för att hämta anslutningen som du skapade i listrutan. Du kan också välja en befintlig Azure SQL Database-anslutning från listrutan direkt om du redan har skapat den tidigare. Funktionerna i Testanslutning och Redigera är tillgängliga för varje vald anslutning. Välj sedan Azure SQL Database i Anslutningstyp .
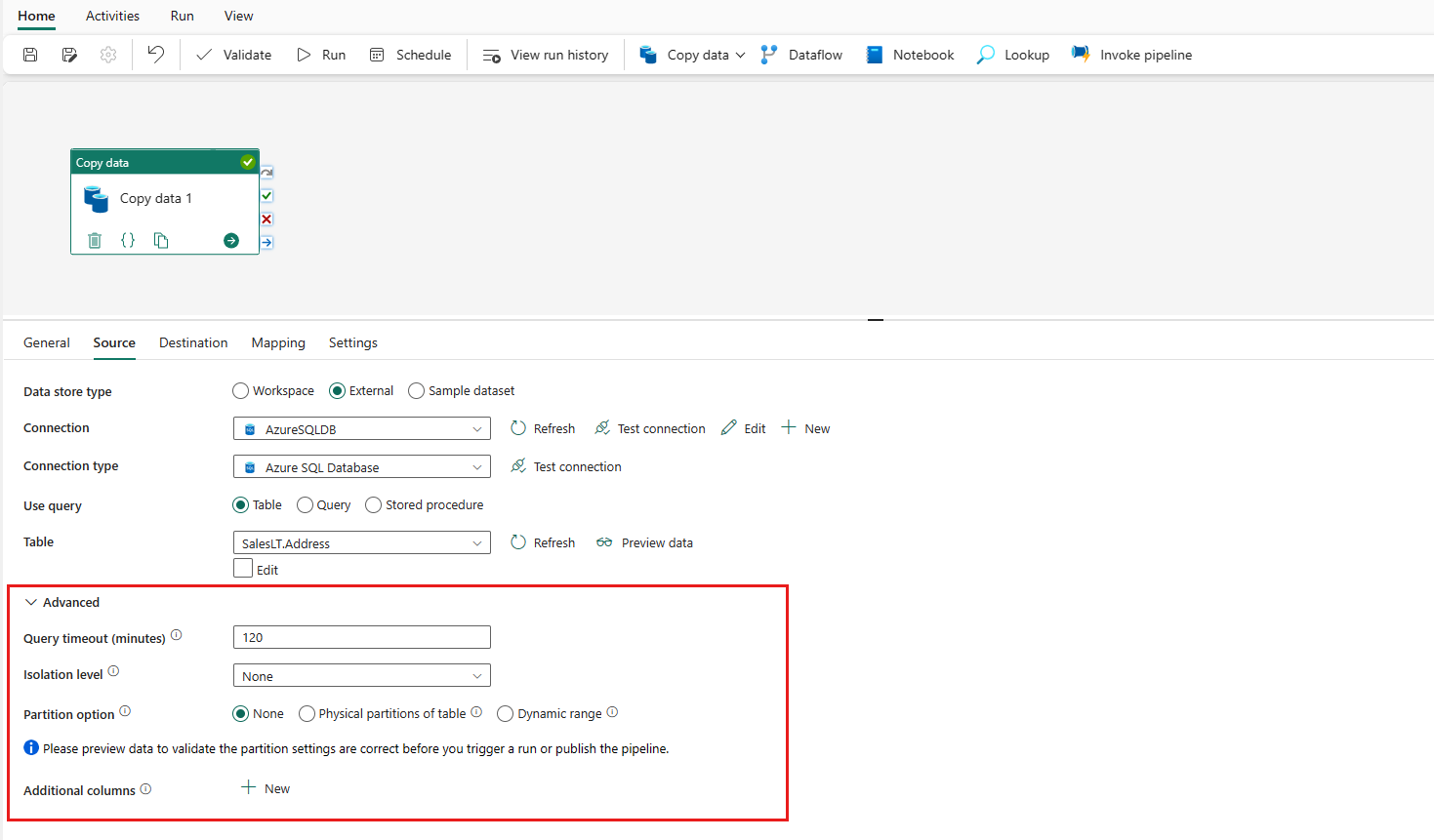
Ange en tabell som ska kopieras. Välj Förhandsgranska data för att förhandsgranska källtabellen. Du kan också använda fråga och lagrad procedur för att läsa data från din källa.
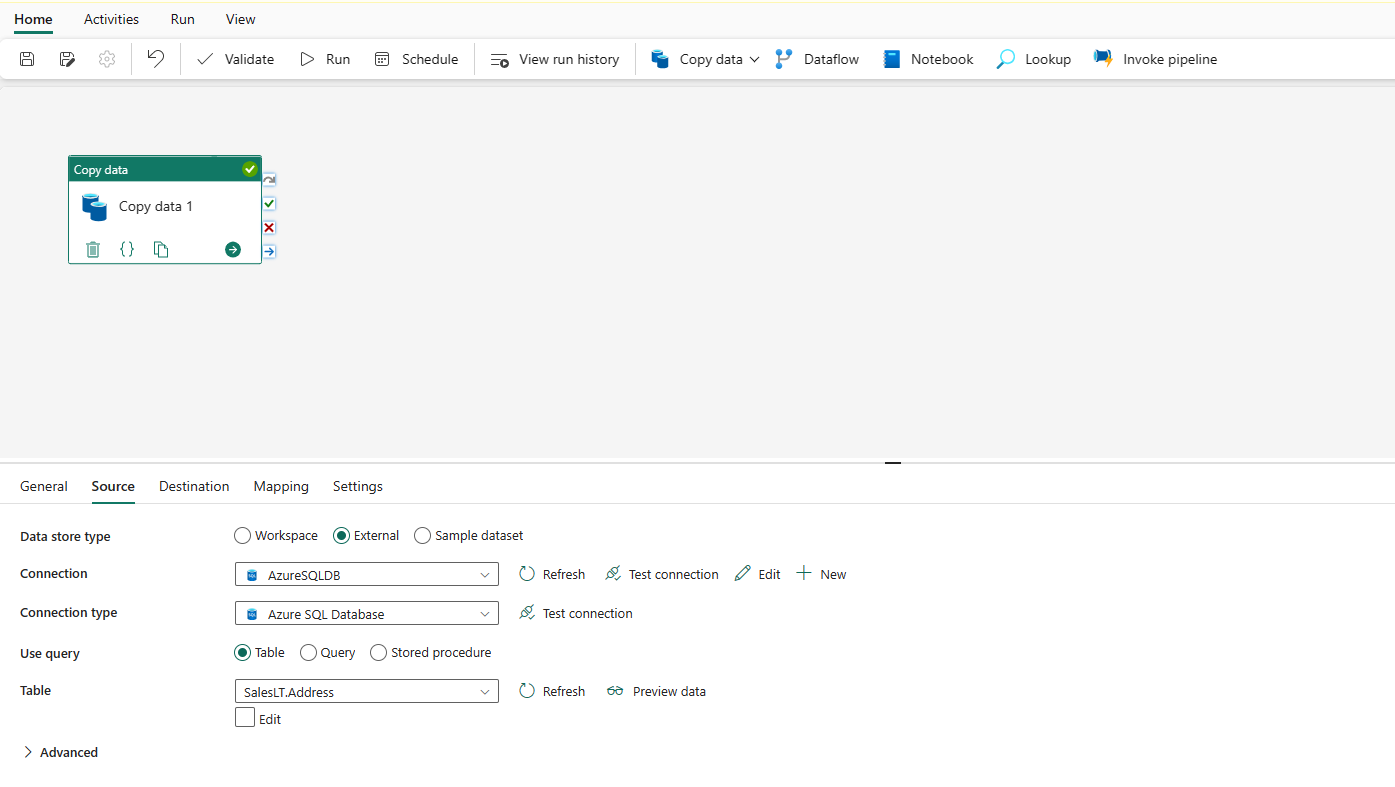
Expandera Avancerat för mer avancerade inställningar.






Konfigurera målet under målfliken
Välj måltyp. Det kan vara antingen ditt interna förstklassiga datalager från din arbetsyta, till exempel Lakehouse, eller dina externa datalager. Du använder Lakehouse som exempel.
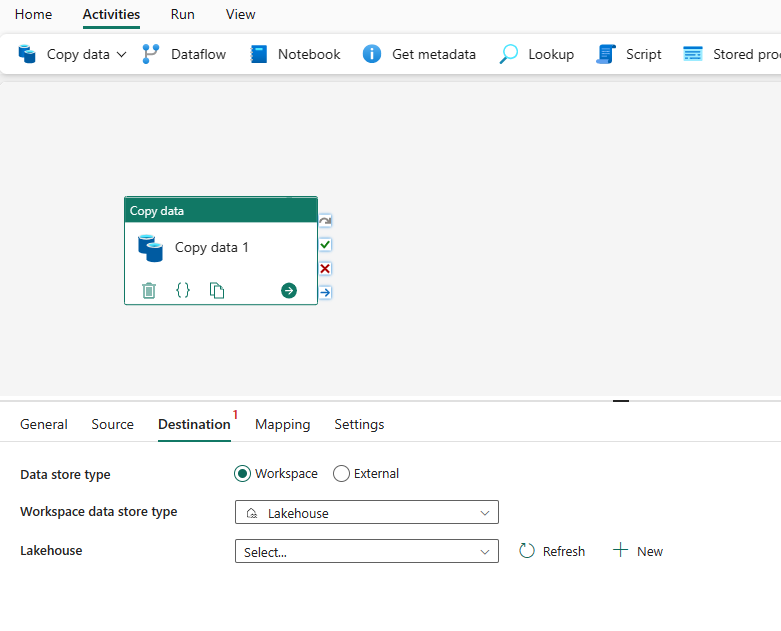
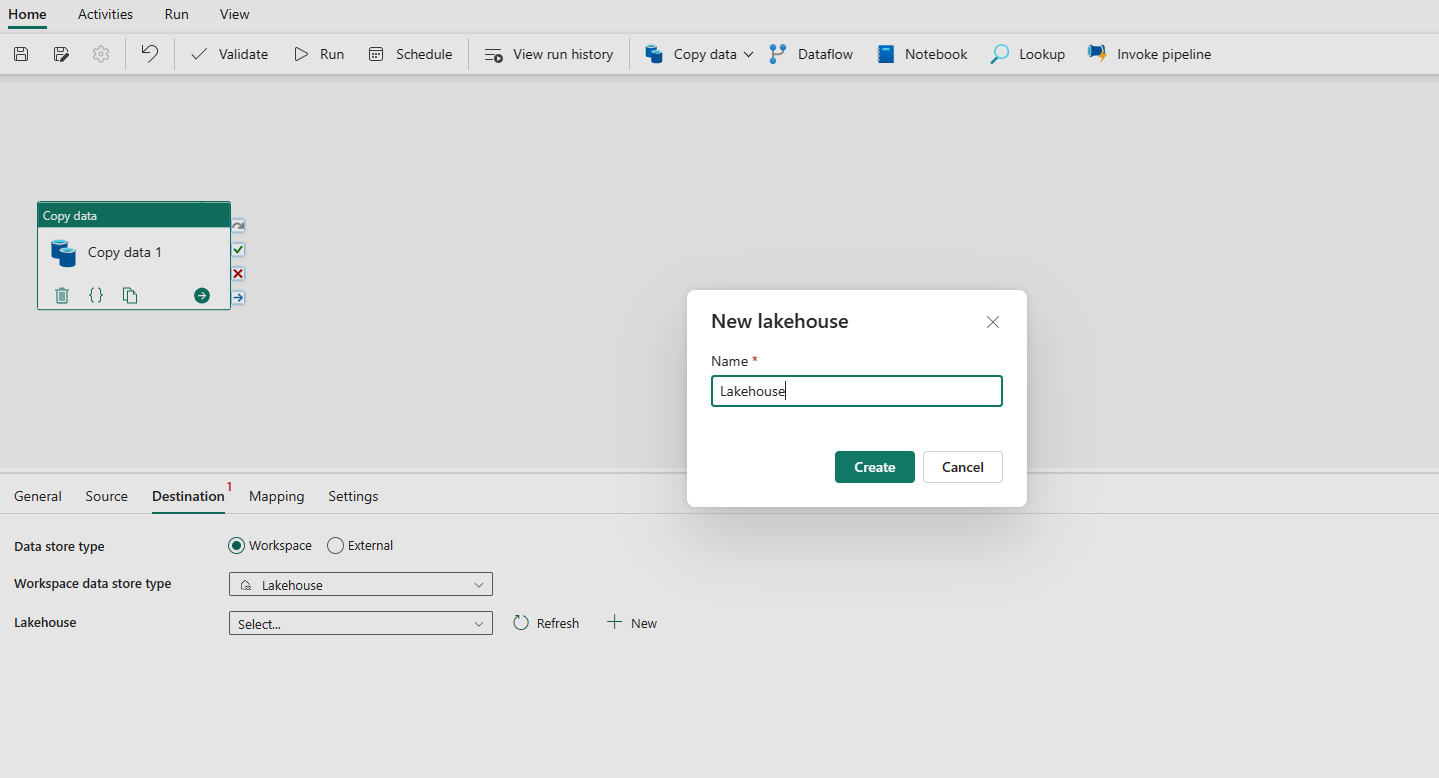
Välj att använda Lakehouse i datalagertypen Arbetsyta. Välj + Ny och navigerar till sidan För att skapa Lakehouse. Ange namnet på Lakehouse och välj sedan Skapa.
När anslutningen har skapats tar den dig tillbaka till datapipelinesidan. Välj sedan Uppdatera för att hämta anslutningen som du skapade i listrutan. Du kan också välja en befintlig Lakehouse-anslutning från listrutan direkt om du redan har skapat den tidigare.
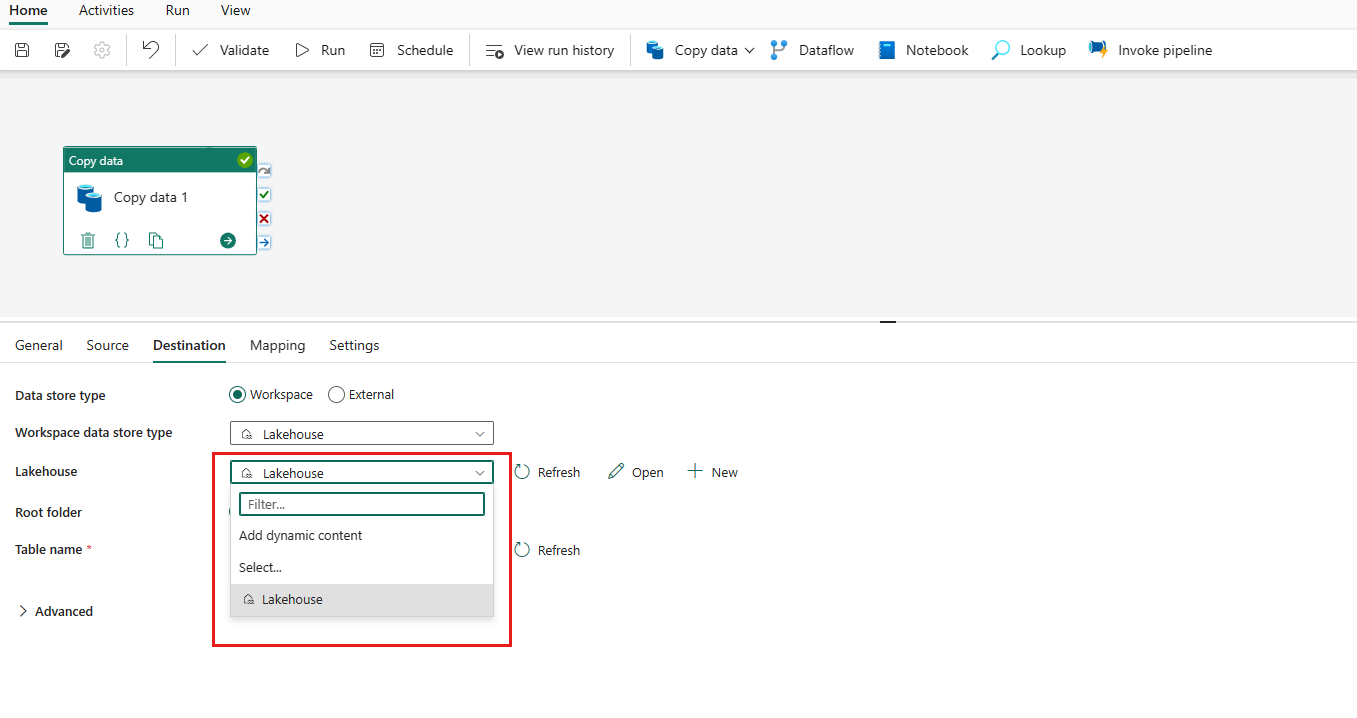
Ange en tabell eller konfigurera filsökvägen för att definiera filen eller mappen som mål. Välj Tabeller och ange en tabell för att skriva data.
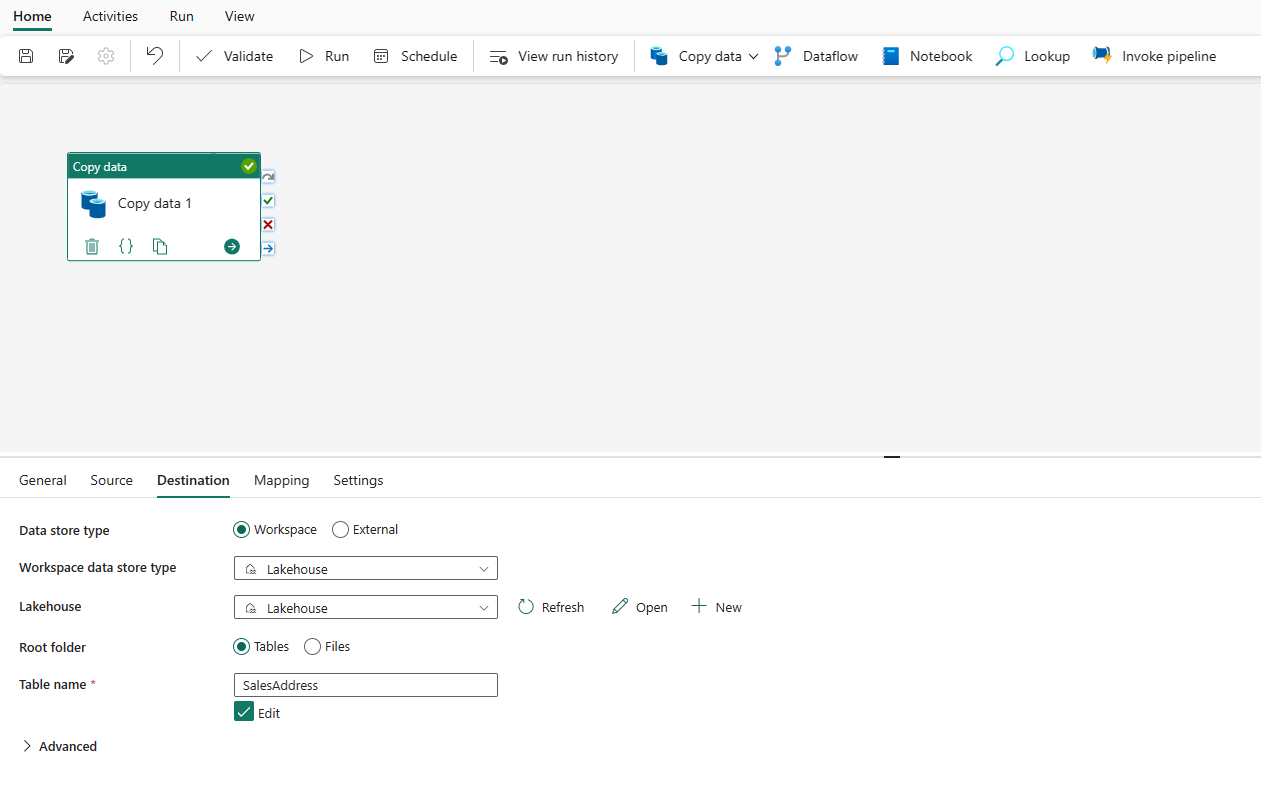
Expandera Avancerat för mer avancerade inställningar.
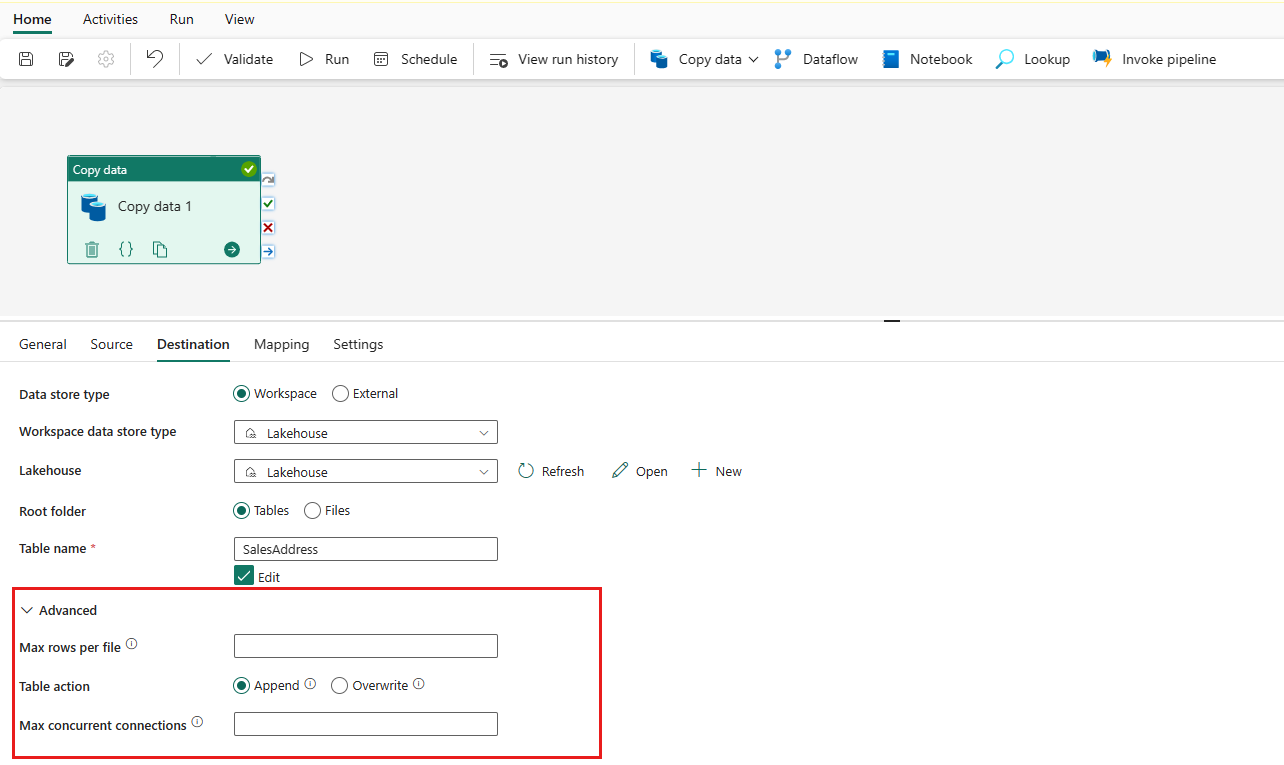





Nu kan du antingen spara din datapipeline med den här enkla kopieringsaktiviteten eller fortsätta att utforma din datapipeline.
Konfigurera dina mappningar under mappningsfliken
Om anslutningsappen som du använder stöder mappning kan du gå till fliken Mappning för att konfigurera mappningen.
Välj Importera scheman för att importera dataschemat.
Du kan se att den automatiska mappningen visas. Ange källkolumnen och målkolumnen. Om du skapar en ny tabell i målet kan du anpassa namnet på målkolumnen här. Om du vill skriva data till den befintliga måltabellen kan du inte ändra det befintliga målkolumnnamnet . Du kan också visa typen av käll- och målkolumner.
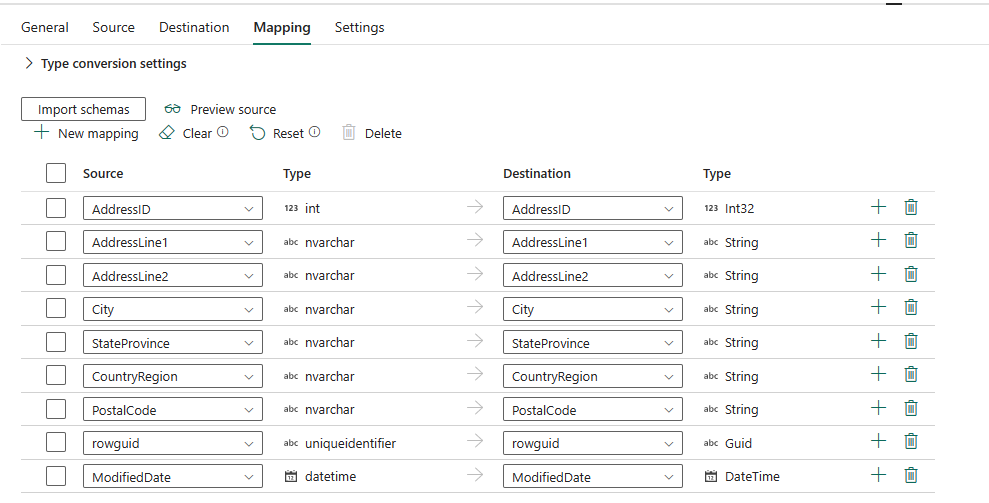


Dessutom kan du välja + Ny mappning för att lägga till ny mappning, välja Rensa för att rensa alla mappningsinställningar och välja Återställ för att återställa alla mappningskolumner för källa .
Konfigurera dina andra inställningar under fliken Inställningar
Fliken Inställningar innehåller inställningar för prestanda, mellanlagring och så vidare.

Se följande tabell för beskrivningen av varje inställning.
| Inställning | beskrivning | JSON-skriptegenskap |
|---|---|---|
| Intelligent dataflödesoptimering | Ange för att optimera dataflödet. Du kan välja mellan: • Automatisk • Standard • Balanserad • Maximalt När du väljer Auto tillämpas den optimala inställningen dynamiskt baserat på ditt källmålspar och datamönster. Du kan också anpassa dataflödet och det anpassade värdet kan vara 2–256 medan högre värde innebär fler vinster. |
dataIntegrationUnits |
| Grad av kopieringsparallellitet | Ange graden av parallellitet som datainläsningen skulle använda. | parallelCopies |
| Feltolerans | När du väljer det här alternativet kan du ignorera vissa fel som inträffat mitt i kopieringsprocessen. Till exempel inkompatibla rader mellan käll- och målarkiv, fil som tas bort under dataflytt osv. | • enableSkipIncompatibleRow • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Aktivera loggning | När du väljer det här alternativet kan du logga kopierade filer, överhoppade filer och rader. | / |
| Aktivera mellanlagring | Ange om data ska kopieras via ett mellanlagringslager. Aktivera endast mellanlagring för de fördelaktiga scenarierna. | enableStaging |
| Typ av datalager | När du aktiverar mellanlagring kan du välja Arbetsyta och Extern som datalagertyp. | / |
| För arbetsyta | ||
| Arbetsyta | Ange att du vill använda inbyggd mellanlagring. | / |
| För extern | ||
| Mellanlagringskontoanslutning | Ange anslutningen för en Azure Blob Storage eller Azure Data Lake Storage Gen2, som refererar till den instans av Storage som du använder som ett mellanlagringslager. Skapa en mellanlagringsanslutning om du inte har den. | anslutning (under externalReferences) |
| Lagringssökväg | Ange den sökväg som du vill innehålla mellanlagrade data. Om du inte anger någon sökväg skapar tjänsten en container för att lagra temporära data. Ange endast en sökväg om du använder Storage med en signatur för delad åtkomst eller om du behöver temporära data på en viss plats. | path |
| Aktivera komprimering | Anger om data ska komprimeras innan de kopieras till målet. Den här inställningen minskar mängden data som överförs. | enableCompression |
| Bevara | Ange om metadata/ACL:er ska bevaras under datakopian. | bevara |
Kommentar
Om du använder mellanlagrad kopia med komprimering aktiverat stöds inte tjänstens huvudnamnsautentisering för mellanlagring av blobanslutning.
Konfigurera parametrar i en kopieringsaktivitet
Parametrar kan användas för att styra beteendet för en pipeline och dess aktiviteter. Du kan använda Lägg till dynamiskt innehåll för att ange parametrar för dina egenskaper för kopieringsaktivitet. Nu ska vi ange Lakehouse/Data Warehouse/KQL Database som ett exempel för att se hur du använder den.
När du har valt Arbetsyta som datalagertyp och angett Lakehouse/Data Warehouse/KQL Database som datalagertyp för arbetsytan väljer du Lägg till dynamiskt innehåll i listrutan i Lakehouse, Data Warehouse eller KQL Database.
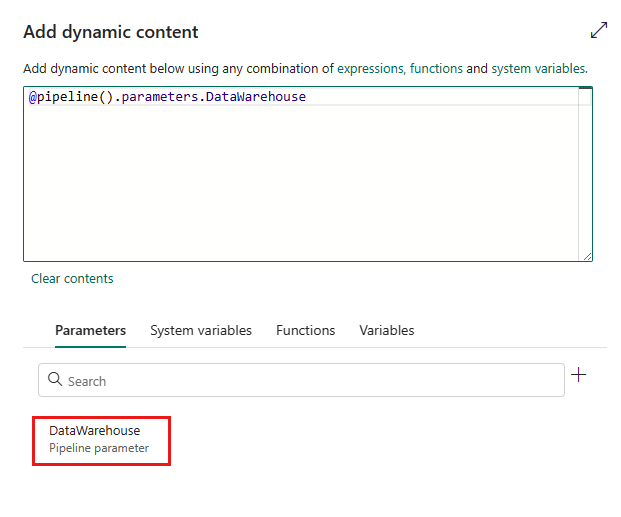
I popup-fönstret Lägg till dynamiskt innehåll går du till fliken Parametrar och väljer +.
Ange namnet på parametern och ge den ett standardvärde om du vill, eller så kan du ange värdet för parametern när du har valt Kör i pipelinen.

Observera att parametervärdet ska vara Lakehouse/Data Warehouse/KQL Database-objekt-ID. Om du vill hämta ditt Objekt-ID för Lakehouse/Data Warehouse/KQL Database öppnar du Lakehouse/Data Warehouse/KQL-databasen på arbetsytan och ID:t är efter
/lakehouses/eller/datawarehouses/i/databases/din URL.Lakehouse-objekt-ID:

Data Warehouse-objekt-ID:

KQL Database-objekt-ID:

Välj Spara för att gå tillbaka till fönstret Lägg till dynamiskt innehåll . Välj sedan parametern så att den visas i uttrycksrutan. Välj sedan OK. Du går tillbaka till pipelinesidan och kan se att parameteruttrycket har angetts efter Lakehouse-objekt-ID/:t Data Warehouse-objekt-ID/:t KQL Database-objekt-ID.