Använd aktiviteten Ta bort data för att söka efter data från en datakälla
Dataaktiviteten Ta bort infrastrukturresurser kan ta bort data från alla datakällor som stöds av Microsoft Fabric.
Du kan använda borttagningsaktiviteten i Data Factory för att ta bort filer eller mappar från alla lagringslager som stöds. Använd den här aktiviteten för att rensa eller arkivera filer när de inte längre behövs.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
- Ett klientkonto med en aktiv prenumeration. Skapa ett konto utan kostnad.
- En arbetsyta skapas.
Lägga till en uppslagsaktivitet i en pipeline med användargränssnittet
Utför följande steg för att använda en ta bort dataaktivitet i en pipeline:
Skapa aktiviteten
Skapa en ny pipeline på din arbetsyta.
Sök efter Ta bort data i fönstret Pipelineaktiviteter och välj den för att lägga till dem i pipelinearbetsytan.
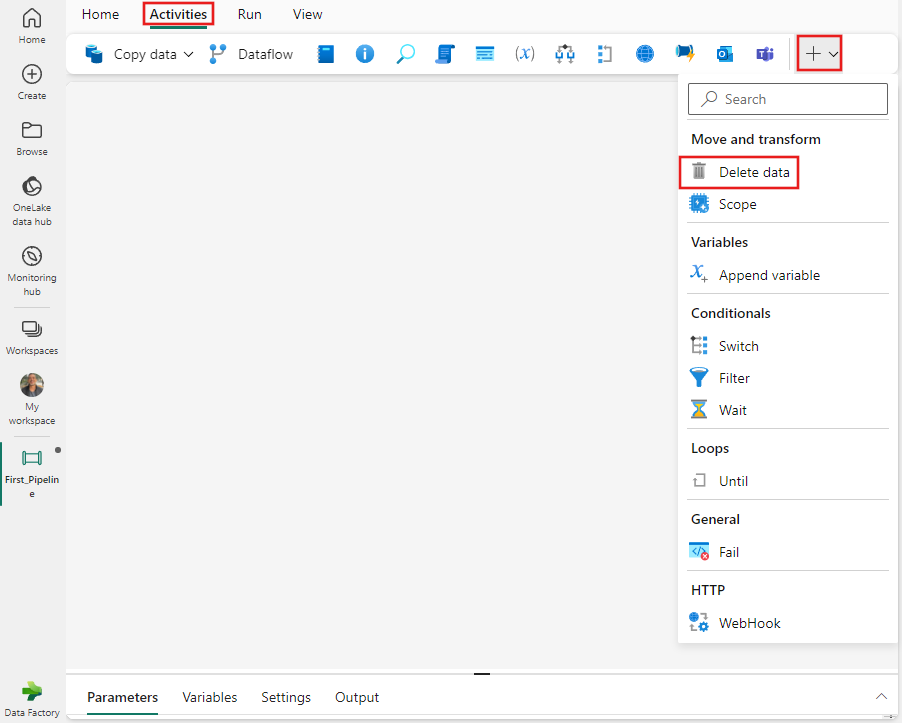
Välj den nya aktiviteten Ta bort data på arbetsytan om den inte redan är markerad.
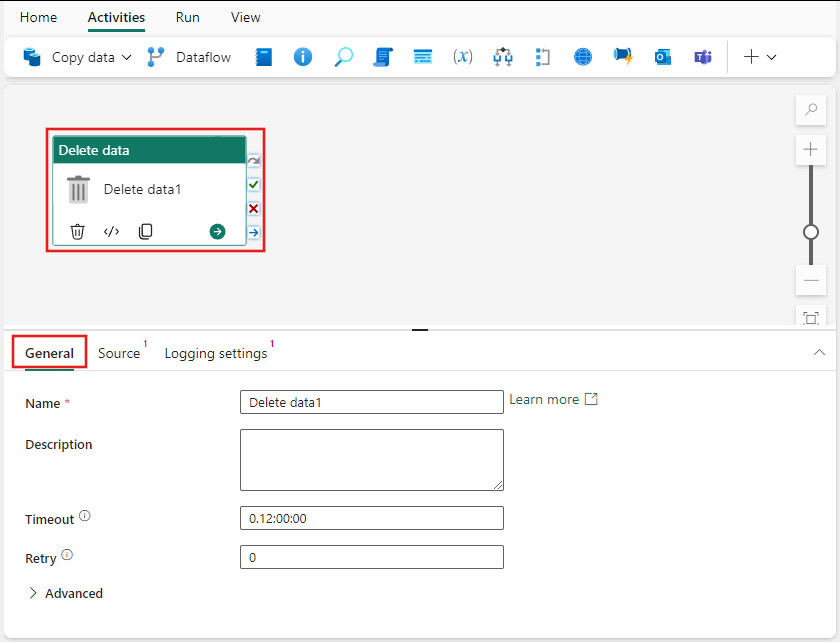
Se vägledningen allmänna inställningar för att konfigurera fliken Allmänna inställningar.
Välj en datakälla
Välj fliken Källa och välj en befintlig anslutning i listrutan Anslutning eller skapa en ny anslutning och ange dess konfigurationsinformation.
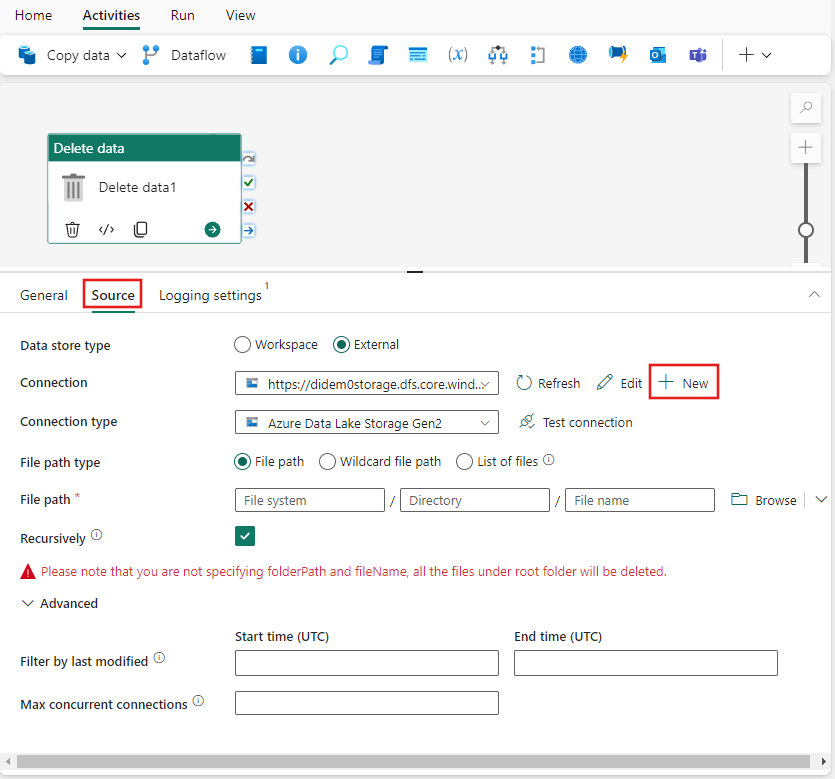
Exemplet i föregående bild visar en bloblagringsanslutning, men varje anslutningstyp har sin egen konfigurationsinformation som är specifik för den valda datakällan.
Datalager som stöds
Fabric stöder de datalager som anges i översiktsartikeln För anslutningsprogram . Alla källor som stöder dataaktiviteten Ta bort kan användas.
Exempel på hur du använder borttagningsaktiviteten
Ta bort specifika mappar eller filer
Arkivet har följande mappstruktur:
Rot/
Folder_A_1/
1.txt
2.txt
3.csv
Folder_A_2/
4.txt
5.csv
Folder_B_1/
6.txt
7.csv
Folder_B_2/
8.txt
Nu använder du aktiviteten Ta bort för att ta bort mappar eller filer genom att kombinera olika egenskapsvärden från datauppsättningen och borttagningsaktiviteten:
| folderPath | fileName | rekursiv | Output |
|---|---|---|---|
| Rot/Folder_A_2 | NULL | Falsk | Rot/ Folder_A_1/ 1.txt 2.txt 3.csv Folder_A_2/ Folder_B_1/ 6.txt 7.csv Folder_B_2/ 8.txt |
| Rot/Folder_A_2 | NULL | Sant | Rot/ Folder_A_1/ 1.txt 2.txt 3.csv |
| Rot/Folder_A_2 | *.Txt | Falsk | Rot/ Folder_A_1/ 1.txt 2.txt 3.csv Folder_A_2/ 5.csv Folder_B_1/ 6.txt 7.csv Folder_B_2/ 8.txt |
| Rot/Folder_A_2 | *.Txt | Sant | Rot/ Folder_A_1/ 1.txt 2.txt 3.csv Folder_A_2/ 5.csv Folder_B_1/ 7.csv Folder_B_2/ |
Spara och köra eller schemalägga pipelinen
- Växla till fliken Start överst i pipelineredigeraren och välj knappen Spara för att spara din pipeline.
- Välj Kör för att köra den direkt eller Schemalägg för att schemalägga den.
- Du kan också visa körningshistoriken här eller konfigurera andra inställningar.
