Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Använd notebook-aktiviteten för att köra notebooks du skapar i Microsoft Fabric som en del av dina Data Factory-pipelines. Med notebook-filer kan du köra Apache Spark-jobb för att hämta, rensa eller transformera dina data som en del av dina dataarbetsflöden. Det är enkelt att lägga till en Notebook-aktivitet i dina pipelines i Fabric, och den här guiden vägleder dig genom varje steg.
Förutsättningar
För att komma igång måste du uppfylla följande krav:
- Du måste ha åtkomst till en Microsoft Fabric tenant med en tilldelad kapacitet. Du kan försöka Fabric med en kostnadsfri utvärderingsversion.
- En Fabric arbetsyta som är tilldelad den kapaciteten.
- En notebook-fil skapas på din arbetsyta. Om du vill skapa en ny notebook-fil kan du läsa Så här skapar du Microsoft Fabric notebook-filer.
Skapa en notebook-aktivitet
Skapa en ny pipeline på din arbetsyta.
Sök efter Notebook i panelen Pipelineaktiviteter och välj den för att lägga till i pipeline-området.
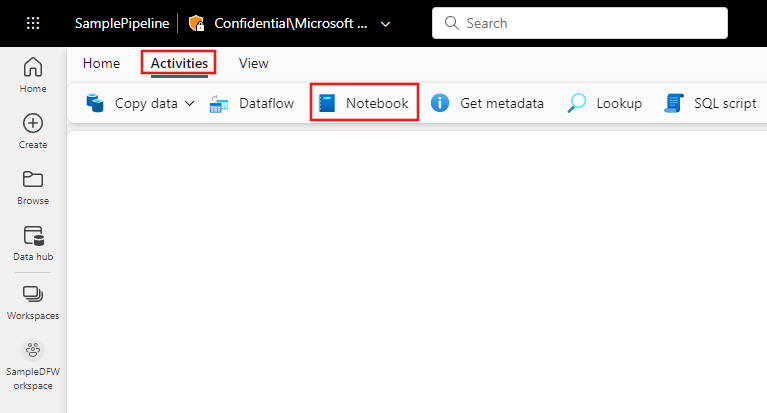
Välj den nya Notebook-aktiviteten på arbetsytan om den inte redan är markerad.
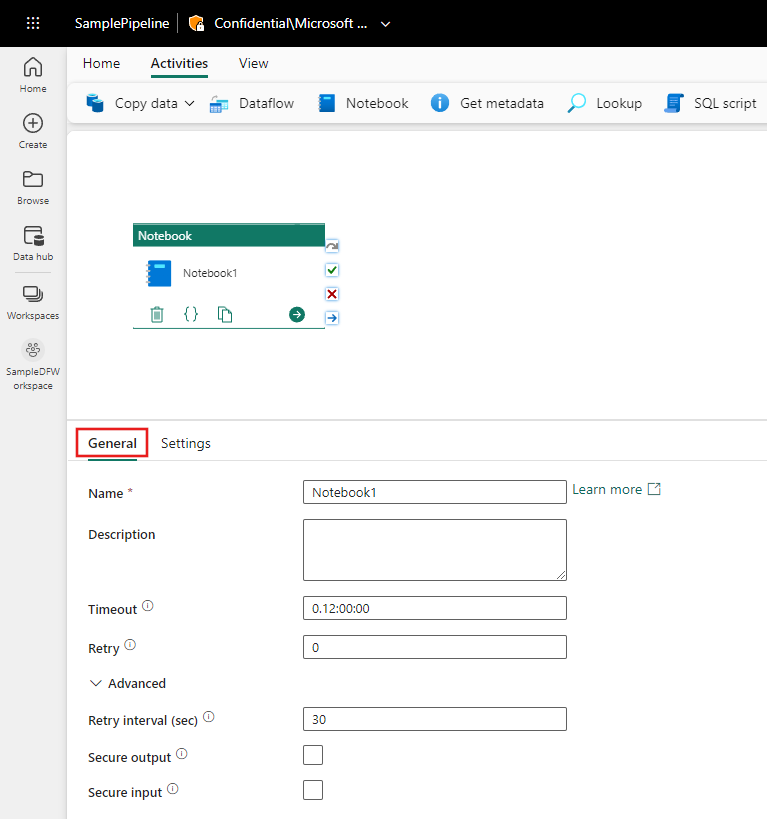
Se vägledningen allmänna inställningar för att konfigurera fliken Allmänna inställningar.
Konfigurera notebook-inställningar
Välj fliken Inställningar.
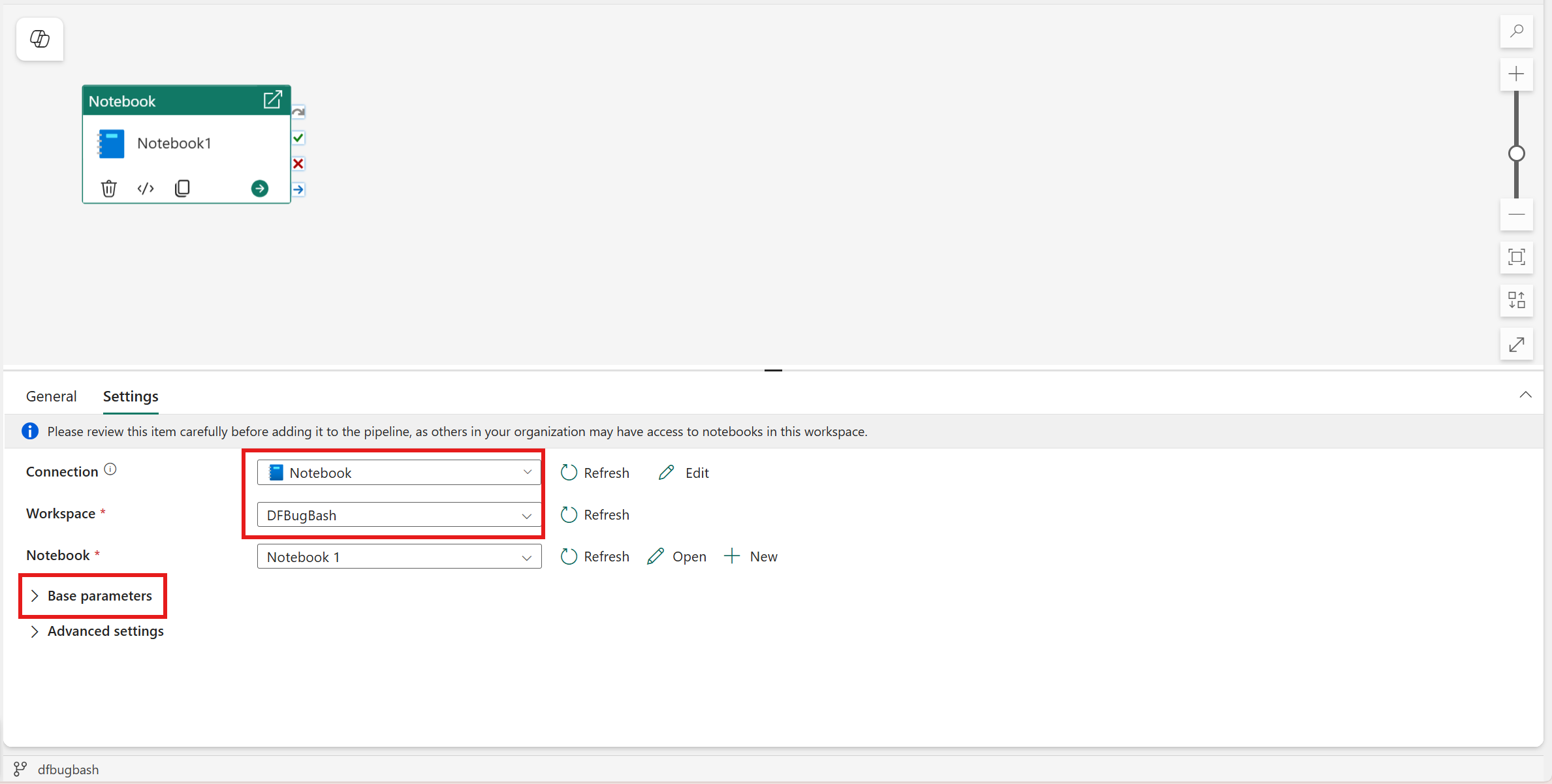
Under Anslutning väljer du autentiseringsmetoden för notebook-körningen och anger de autentiseringsuppgifter som krävs.
Välj en befintlig notebook-fil i listrutan Notebook och ange eventuella parametrar som ska skickas till notebook-filen.
Användning av Fabric arbetsyteidentitet (WI) i Notebook-aktiviteten
Skapa arbetsytans identitet
Du måste aktivera WI på din arbetsyta (det kan ta en stund att ladda). Skapa en identitet för arbetsytan i din Fabric-miljö. Observera att WI ska skapas på samma arbetsyta som pipelinen.
Se dokumentationen om arbetsyteidentitet.
Aktivera inställningar på klientorganisationsnivå
Aktivera följande klientinställning (den är inaktiverad som standard): Tjänsteprincipaler kan anropa Fabric offentliga API:er.
Du kan aktivera den här inställningen i administratörsportalen Fabric. Mer information om den här inställningen finns i artikeln aktivera autentisering med tjänstens huvudnamn för administratörs-API:er.
Bevilja arbetsytebehörigheter till arbetsyteidentiteten
Öppna arbetsytan, välj Hantera åtkomst och tilldela behörigheter till arbetsytans identitet. Deltagaråtkomst räcker för de flesta scenarier. Om din notebook inte finns på samma arbetsyta som din pipeline behöver du tilldela den WI som du skapade på din pipelines arbetsyta minst deltagaråtkomst till din notebooks arbetsyta.
Kolla in dokumenten på Ge användare åtkomst till arbetsytor.
Sätt sessionens etikett
För att minimera hur lång tid det tar att köra notebook-jobbet kan du ange en sessionstagg. Om du anger sessionstaggen instrueras Spark att återanvända alla befintliga Spark-sessioner, vilket minimerar starttiden. Valfritt godtyckligt strängvärde kan användas för sessionstaggen. Om det inte finns någon session skapas en ny med taggvärdet.
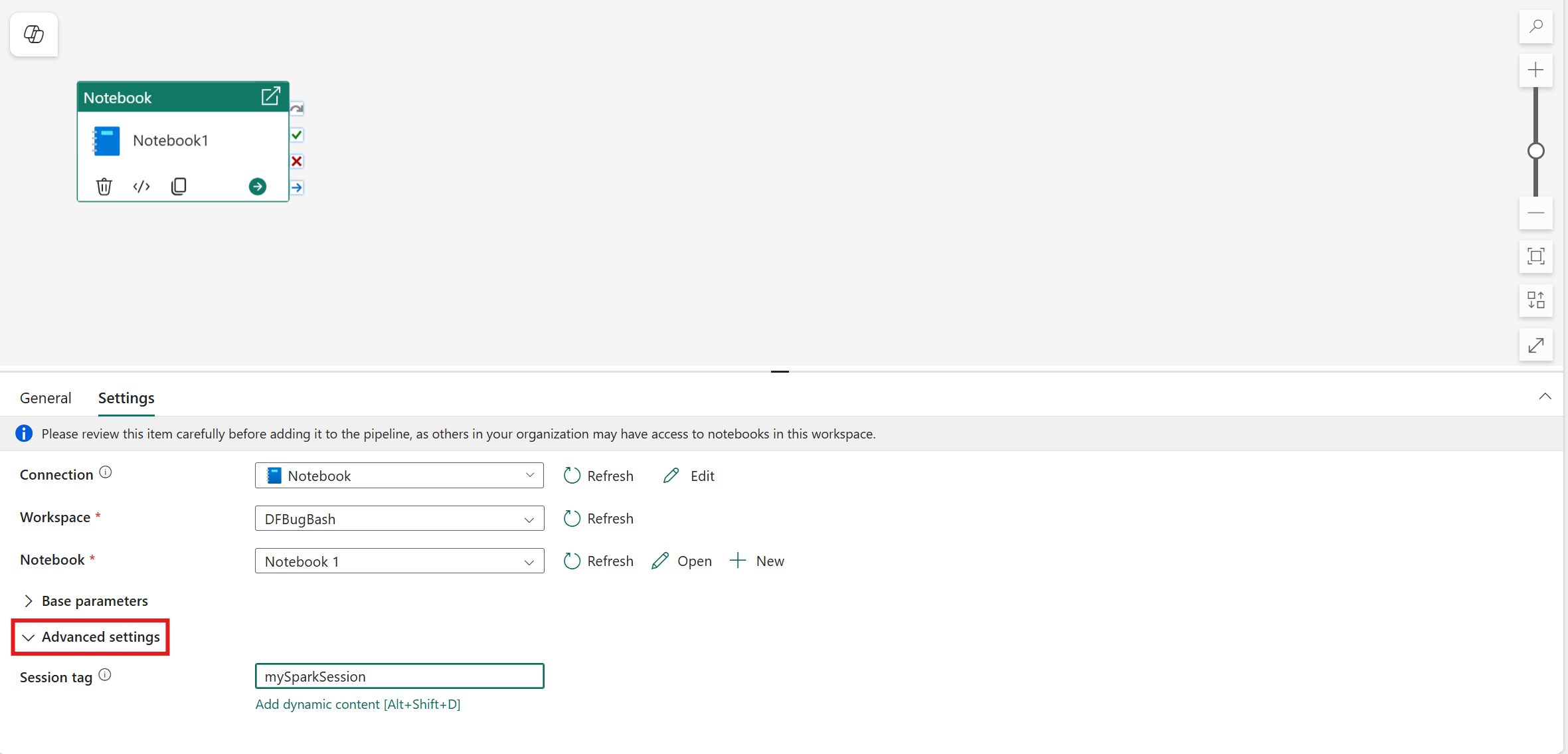
Anteckning
För att kunna använda sessionstaggen måste alternativet Hög samtidighet för pipeline som kör flera notebook-filer vara aktiverat. Det här alternativet finns i läget Hög samtidighet för Spark-inställningar under arbetsyteinställningarna

Spara och kör eller schemalägg pipelinen
Växla till fliken Start överst i pipelineredigeraren och välj knappen Spara för att spara din pipeline. Välj Kör för att köra den direkt eller Schemalägg för att schemalägga körningar vid specifika tidpunkter eller intervall. Mer information om pipelinekörningar finns i: schemalägga pipelinekörningar.

När du har kört kan du övervaka pipelinekörningen och visa körningshistoriken från fliken Utdata under arbetsytan.
Kända problemområden
- Användning av tjänstens huvudnamn för att köra en notebook-fil som innehåller Semantic Link-kod har funktionsbegränsningar och stöder endast en delmängd av semantiska länkfunktioner. Mer information finns i semantiska länkfunktioner som stöds . Om du vill använda andra funktioner rekommenderar vi att du manuellt autentiserar semantisk länk med tjänstens huvudnamn.